Klasifikasi Kualitas Buah dengan Menggunakan Convolutional Neural Network (Studi Kasus: Dataset Fresh and Rotten Classification)
on
JNATIA Volume 2, Nomor 2, Februari 2024
Jurnal Nasional Teknologi Informasi dan Aplikasinya
p-ISSN: 2986-3929
Klasifikasi Kualitas Buah dengan Menggunakan Convolutional Neural Network (Studi Kasus: Dataset Fresh and Rotten Classification)
I Gede Diva Dwijayanaa1, I Putu Fajar Tapa Mahendraa2, Ivan Luis Simarmataa3, Gst. Ayu Vida Mastrika Giria4
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana, Bali
Jln. Raya Kampus UNUD, Bukit Jimbaran, Kuta Selatan, Badung, 08261, Bali, Indonesia 1dwijayanaigede@gmail.com 2ftapamahendra@gmail.com 3ivan_luis030602@protonmail.com
Abstract
This research aims to develop a deep learning model for fruit quality classification using Convolutional Neural Network (CNN) with the Fresh and Rotten Classification dataset. Two CNN models are compared, with the first model serving as the baseline and the second model resulting from parameter tuning based on the first model. The results indicate that increasing the number of epochs improves the model accuracy, as evidenced by the first model achieving 91% accuracy with 10 epochs and 93% accuracy with 15 epochs. Similar patterns are observed in the second model, with 87% accuracy at 10 epochs and 90% accuracy at 15 epochs. Despite the second model involving the addition of layers and parameters, its accuracy tends to be lower compared to the first model. The research emphasizes that increasing the number of epochs enhances model performance, while adding layers does not always lead to significant improvements, depending on the model's complexity and dataset characteristics. The first model, trained with 15 epochs, demonstrates the highest accuracy, approaching results from similar previous studies. This evaluation provides valuable insights for developing a CNN-based fruit classification model on the Fresh and Rotten Classification dataset.
Keywords: Fruit Classification, Rotten, Fresh, Convolutional Neural Network, Accuracy, Epochs
Mendeteksi kualitas buah dalam industri pangan merupakan hal yang utama, tidak hanya untuk menjaga kesehatan konsumen tetapi juga untuk mempertahankan stabilitas ekonomi dan mempertahankan praktik yang berkelanjutan. Dalam era teknologi canggih saat ini, kehadiran kecerdasan buatan, deep learning, dan machine learning dapat membantu mengatasi masalah ini. Data gambar dari buah-buahan dapat digunakan untuk membangun suatu alat yang mumpuni dalam mengklasifikasikan kualitas dari buah-buahan. Diantara arsitektur deep learning yang ada, Convolutional Neural Network (CNN) adalah metode yang terkenal dalam melaksanakan tugas yang menggunakan data gambar. CNN adalah arsitektur deep learning yang didesain untuk dapat mempelajari dan beradaptasi dengan fitur yang ada pada gambar. Alasan ini membuat metode ini sangat cocok dalam mendeteksi ciri dari busuknya suatu buah yang seringkali terlewat menggunakan pengamatan mata manusia. CNN dapat dilatih untuk mengenali perbedaan antara buah busuk dan buah segar, membantu mengurangi ketergantungan pada pengamatan manusia yang rentan terhadap subjektivitas dan kesalahan. Beberapa penelitian terdahulu telah menunjukkan potensi CNN dalam klasifikasi gambar, seperti penelitian Atul Sharma pada tahun 2021 yang mencapai 94% akurasi validasi dalam klasifikasi gambar menggunakan dataset cifar-10 keras[1]. Penelitian lain yang dilakukan oleh Nur Ibrahim, dkk pada tahun 2022 yang melakukan klasifikasi tingkat kematangan pucuk daun teh dengan pendekatan deep learning arsitektur VGG19 dan ResNet50 yang mendapatkan
akurasi terbaik dari model VGG19 yaitu sebesar 97,5% [2]. Penelitian terkait yang juga dilakukan oleh Parab pada tahun 2020 yang melakukan klasifikasi sel darah merah menggunakan metode CNN dimana model dapat mengklasifikasikan 9 kelas sel darah merah dengan akurasi sebesar 98,6% [3]. Dengan mempertimbangkan hasil penelitian terdahulu, penelitian ini bertujuan untuk mengembangkan model yang mampu mengklasifikasikan buah busuk dan buah segar dengan metode CNN. Melalui pendekatan ini, diharapkan dapat meningkatkan keamanan pangan dan memberikan kontribusi pada efisiensi operasional dalam industri pangan.
Metode yang akan digunakan dalam penelitian ini adalah Convolutional Neural Network untuk mengklasifikasi kelas buah busuk ataupun buah segar dengan arsitektur CNN yang disusun oleh penulis.
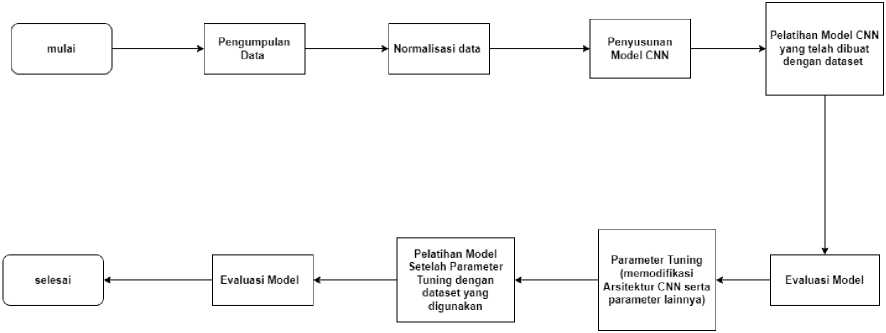
Gambar 1. Alur Penelitian
Pelaksanaan penelitian dimulai dengan pengumpulan data yaitu data gambar buah busuk dan buah segar dimana ada 7 kelas buah segar dan 7 kelas buah busuk. Selanjutnya data tersebut akan melalui pra pemrosesan untuk normalisasi data dan menyesuaikan ukuran gambar agar dapat digunakan untuk melatih model. Kemudian menyusun arsitektur CNN yang akan dilatih. Selanjutnya pelatihan model untuk dapat mengklasifikasikan kualitas buah dengan data gambar. Setelah model tersebut dilatih, akan dilakukan evaluasi pada model tersebut untuk mengetahui performa dari model yang telah dilatih. Selanjutnya model melalui parameter tuning yaitu memodifikasi parameter model dengan harapan model bisa menghasilkan performa yang lebih baik dari sebelumnya. Kemudian melatih kembali model yang telah melalui parameter tuning. Selanjutnya melakukan evaluasi model yang telah melalui proses parameter tuning.
Data yang digunakan dalam penelitian ini adalah data sekunder dari website kaggle. Dataset ini bernama Fresh and Rotten Classification. Dataset berisi data buah dengan 7 jenis buah yang dibagi menjadi kelas buah busuk dan kelas buah segar, jadi total kelas yang ada pada dataset adalah 14 kelas. Dataset telah dibagi menjadi data test dan data train. Data dalam bentuk citra RGB berjumlah 27,782 yang dibagi menjadi data test dan train. Data test memiliki 6,738 data gambar, sedangkan data train memiliki 21,044 data gambar. Dataset dapat diakses melalui situs https://www.kaggle.com/datasets/swoyam2609/fresh-and-stale-classification.

Gambar 2. Contoh Data Gambar Dari Masing-Masing Kelas
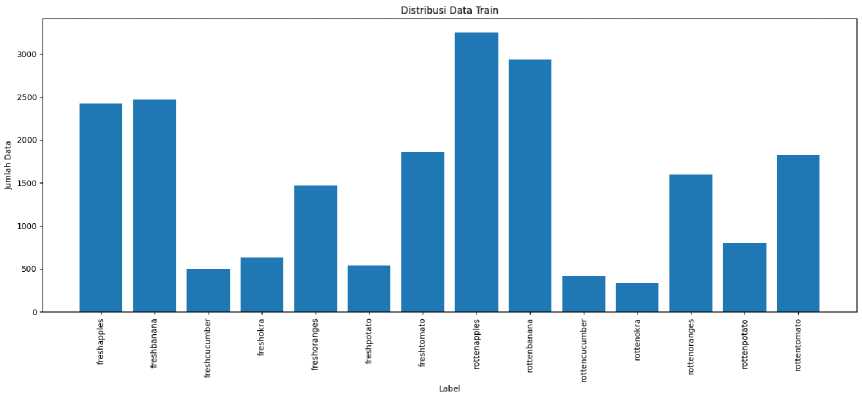
Gambar 3. Distribusi data train
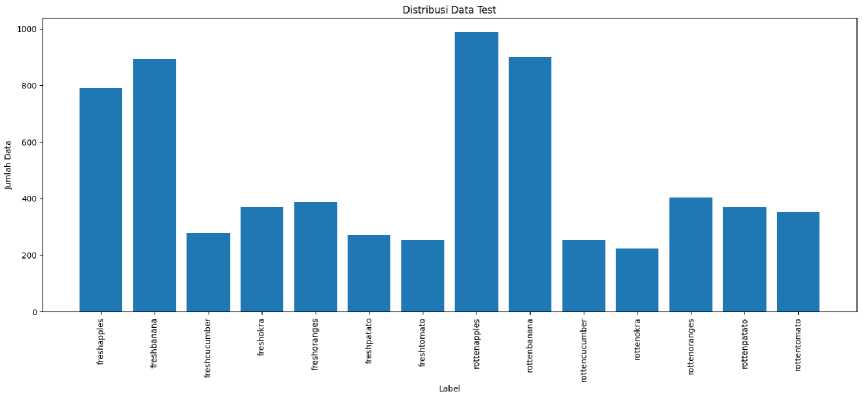
Gambar 4. Distribusi data test
Sebelum melakukan pelatihan model, setiap gambar pada data latih dan data uji harus melalui proses normalisasi dan resize terlebih dahulu. Normalisasi adalah proses pengubahan nilai piksel dalam gambar, yang semula berkisar antara 0 hingga 255, menjadi rentang antara 0
hingga 1. Dalam penelitian ini, normalisasi dilakukan dengan membagi setiap nilai piksel di data latih dan data uji dengan 255. Setelah normalisasi, seluruh gambar yang akan masuk ke dalam model harus melewati standarisasi ukuran dengan melalui proses rescale menjadi gambar berukuran 224 x 224 dengan 3 channel warna yaitu RGB.
Tahap selanjutnya adalah penyusunan model CNN. Setiap convolutional layer menggunakan fungsi aktivasi ReLu dan untuk output layer menggunakan fungsi aktivasi softmax untuk mengklasifikasikan lebih dari 2 kelas. Untuk susunan layer atau arsitektur model dapat dilihat pada gambar di bawah:
|
conv2d4input |
input: |
[(None, 224, 224, 3)] |
|
InputLayer |
output: |
[(None, 224, 224, 3)] |
|
conv2d_4 |
input: |
(None, 224, 224, 3) |
|
Conv2D |
output: |
(None, 222, 222, 64) |
|
max_pooling2d_4 |
input: |
(None, 222, 222, 64) |
|
MaxPooling2D |
output: |
(None, 111, 111, 64) |
|
conv2d-5 |
input: |
(None, 111, 111, 64) |
|
C□nv2D |
output: |
(None, 109, 109, 128) |
|
max_pooling2d_5 |
input: |
(None, 109, 109, 128) |
|
MaxPooling2D |
output: |
(None, 54, 54, 128) |
|
conv2d_6 |
input: |
(None, 54, 54, 128) |
|
Conv2D |
output: |
(None, 52, 52, 256) |
|
max_pooling2d_6 |
input: |
(None, 52, 52, 256) |
|
MaxPooling2D |
output: |
(None, 26, 26, 256) |
|
conv2d-7 |
input: |
(None, 26, 26, 256) |
|
Conv2D |
output: |
(None, 24, 24, 512) |
|
max_pooling2d_7 |
input: |
(None, 24, 24, 512) |
|
MaxPooling2D |
output: |
(None, 12, 12, 512) |
|
dropout-2 |
input: |
(None, 12, 12, 512) |
|
Dropout |
output: |
(None, 12, 12, 512) |
i
|
flatten_l |
input: |
(None, 12,12, 512) |
|
Flatten |
output: |
(None, 73728) |
|
dense_2 |
input: |
(None, 73728) |
|
Dense |
output: |
(None, 1024) |
|
dropout3 |
input: |
(None, 1024) |
|
Dropout |
output |
(None, 1024) |
|
dense_3 |
input: |
(None, 1024) |
|
Dense |
output: |
(None, 14) |
Gambar 5. Arsitektur Model CNN Pertama
Model dilatih dengan tambahan parameter sebagai berikut:
-
1. Jumlah epoch adalah 10 dan 15
-
2. Batch size 32
Evaluasi model menggunakan matriks akurasi, nilai precision, nilai recall, dan f1-score. Matriks akurasi adalah metrik evaluasi yang dapat dihasilkan dari data yang terdapat dalam confusion matrix. Confusion matrix adalah sebuah tabel yang dimanfaatkan untuk menilai kinerja model klasifikasi dalam konteks pengenalan pola. Tabel ini memberikan gambaran tentang sejauh mana model mampu mengklasifikasikan data secara benar dan menunjukkan seberapa sering model membuat kesalahan dalam mengklasifikasikan data. Berikut adalah rumus dari matriks akurasi, precision, recall, dan f1-score:
TP+ TN
TP + TN + FP + FN
TP
TP
p∙r
-
2.7. Parameter Tuning
Parameter tuning adalah langkah melakukan perubahan atau memodifikasi beberapa komponen dalam model dengan maksud untuk mencapai kinerja model yang optimal. Modifikasi model pertama menghasilkan model kedua. Berikut adalah arsitektur model kedua:
|
conv2d-input |
input: |
[(None, 224, 224, 3)] |
|
InputLayer |
output: |
[(None, 224, 224, 3)] |
|
coπv2d |
input: |
(None, 224, 224, 3) |
|
Conv2D |
output: |
(None, 222, 222, 64) |
|
maxjpooling2d |
input: |
(None, 222, 222, 64) |
|
MaxPooling2D |
output: |
(None, 111, 111, 64) |
|
conv2d_l |
input: |
(None, 111, 111, 64) |
|
Conv2D |
output: |
(None, 109, 109, 128) |
|
conv2d_2 |
input: |
(None, 109,109, 128) |
|
Conv2D |
output: |
(None, 107, 107, 128) |
|
max_pooling2d_l |
input: |
(None, 107,107, 128) |
|
MaxPoolingZD |
output: |
(None, 53, 53, 128) |
|
dropout |
input: |
(None, 53, 53, 128) |
|
Dropout |
output: |
(None, 53, 53, 128) |
|
conv2d-3 |
input: |
(None, 53, 53,128) |
|
Conv2D |
output: |
(None, 51, 51, 256) |
|
conv2d_4 |
input: |
(None, 51, 51, 256) |
|
Conv2D |
output: |
(None, 49,49, 256) |
|
max_pooling2d_2 |
input: |
(None, 49, 49, 256) |
|
MaxPoolingZD |
output: |
(None, 24, 24, 256) |
|
dιopoutl |
input: |
(None, 24, 24, 256) |
|
Dropout |
output: |
(None, 24, 24, 256) |
|
conv2d_5 |
input: |
(None, 24, 24, 256) |
|
Conv2D |
output: |
(None, 22, 22, 512) |
|
conv2d-6 |
input: |
(None, 22, 22, 512) |
|
Conv2D |
output: |
(None, 20, 20, 512) |
|
max_pooling2d_3 |
input: |
(None, 20, 20, 512) |
|
MaxPoolingZD |
output: |
(None, 10, 10, 512) |
|
dropout _2 |
input: |
(None, 10, 10, 512) |
|
Dropout |
output: |
(None, 10, 10, 512) |
|
flatten |
input: |
(None, 10,10, 512) |
|
Hatten |
output: |
(None, 51200) |
|
dense |
input: |
(None, 51200) |
|
Dense |
output: |
(None, 1024) |
|
dropout 3 |
input: |
(None, 1024) |
|
Dropout |
output: |
(None, 1024) |
|
dense_l |
input: |
(None, 1024) |
|
Dense |
output: |
(None, 14) |
Gambar 6. Arsitektur Model CNN Kedua
Pelatihan model pertama dilakukan sebanyak 2 kali dengan epoch yang berbeda yaitu dengan epoch 10 dan epoch 15. Data train yang telah melalui proses normalisasi dan resize digunakan untuk pelatihan model. Hasil dari pelatihan model pertama dengan epoch 10 yang telah diuji menggunakan data test adalah model mendapat akurasi sebesar 91%. Untuk detail hasil evaluasi model pertama dengan 10 epoch menggunakan precision, recall, dan f1-score dapat dilihat pada gambar confusion matrix dan tabel berikut:
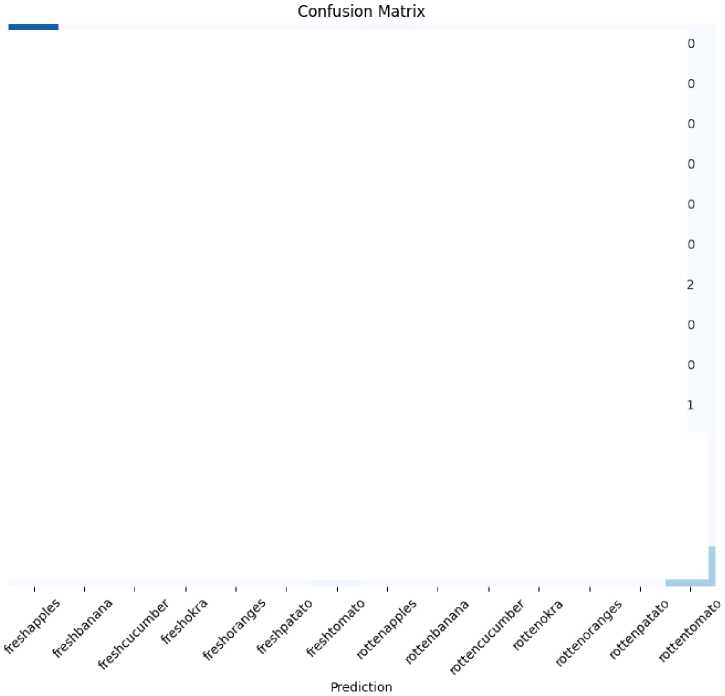
Gambar 7. Confusion Matrix Hasil Testing Model Pertama Epoch 10.
|
freshapples |
774 |
2 |
0 |
0 |
2 |
0 |
0 |
13 |
0 |
0 |
0 |
0 |
0 |
0 | |
|
freshbanana - |
0 |
889 |
0 |
0 |
0 |
0 |
0 |
1 |
2 |
0 |
0 |
0 |
0 |
0 | |
|
freshcucumber - |
0 |
0 |
163 |
62 |
0 |
0 |
0 |
0 |
0 |
52 |
2 |
0 |
0 |
0 | |
|
freshokra - |
0 |
0 |
36 |
267 |
0 |
0 |
0 |
0 |
0 |
41 |
26 |
0 |
0 |
0 | |
|
fresh oranges - |
0 |
0 |
0 |
0 |
386 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
0 |
0 | |
|
freshpatato - |
1 |
1 |
0 |
0 |
0 |
249 |
0 |
1 |
0 |
0 |
0 |
0 |
18 |
0 | |
|
(U <c |
freshtomato - |
0 |
0 |
0 |
0 |
0 |
0 |
252 |
1 |
0 |
0 |
0 |
0 |
0 |
2 |
|
∏3 S |
TOttenappIes - |
21 |
1 |
0 |
0 |
17 |
0 |
0 |
945 |
2 |
0 |
0 |
2 |
0 |
0 |
|
TOttenbanana - |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
4 |
890 |
0 |
0 |
0 |
6 |
0 | |
|
TOttencucumber - |
0 |
2 |
3 |
3 |
0 |
6 |
2 |
0 |
1 |
190 |
10 |
1 |
36 |
1 |
|
rottenokra - |
O |
O |
2 |
5 |
O |
6 |
O |
O |
1 |
44 |
114 |
1 |
50 |
1 |
|
TOttenoranges - |
2 |
O |
O |
O |
17 |
O |
O |
5 |
O |
O |
O |
379 |
O |
O |
|
TOttenpatato - |
O |
1 |
O |
O |
O |
72 |
1 |
1 |
O |
O |
O |
1 |
293 |
1 |
|
TOttentomato - |
1 |
O |
O |
O |
O |
1 |
31 |
O |
O |
O |
O |
2 |
O |
318 |
Tabel 1. Tabel Nilai Evaluasi Model Pertama Epoch 10
precision recall f1-score support
|
freshapples |
0,97 |
0,98 |
0,97 |
791 |
|
freshbanana |
0,99 |
1,00 |
0,99 |
892 |
|
freshcucumber |
0,80 |
0,58 |
0,67 |
279 |
|
freshokra |
0,79 |
0,72 |
0,76 |
370 |
|
freshoranges |
0,91 |
0,99 |
0,95 |
388 |
|
freshpatato |
0,75 |
0,92 |
0,82 |
270 |
|
freshtomato |
0,88 |
0,99 |
0,93 |
255 |
|
rottenapples |
0,97 |
0,96 |
0,96 |
988 |
|
precision recall f1-score support | ||||
|
rottenbanana |
0,99 |
0,99 |
0,99 |
900 |
|
rottencucumber 0,58 |
0,75 |
0,65 |
255 | |
|
rottenokra |
0,75 |
0,51 |
0,61 |
224 |
|
rottenoranges |
0,98 |
0,94 |
0,96 |
403 |
|
rottenpatato |
0,73 |
0,79 |
0,76 |
370 |
|
rottentomato |
0,98 |
0,90 |
0,94 |
353 |
|
accuracy |
0,91 |
6738 | ||
Dari tabel diatas dapat dilihat pada hasil testing model pertama yang dilatih dengan 10 epoch menghasilkan akurasi sebesar 0,91 dengan total data test adalah 6738. Nilai precision tertinggi didapat pada kelas freshbanana dan rottenbanana dengan nilai precision 0,99. Untuk nilai precision terendah didapat pada kelas rottencucumber dengan nilai 0,58. Nilai recall tertinggi pada kelas freshbanana dengan nilai 1,00. Nilai recall terendah didapat pada kelas rottenokra dengan nilai 0,51. Nilai f1-score tertinggi didapat pada kelas freshbanana dan rottenbanana dengan nilai 0,99. Nilai f1-score terendah dimiliki kelas rottenokra dengan nilai 0,61.
Hasil dari pelatihan model pertama dengan epoch 15 yang telah diuji menggunakan data test adalah model mendapat akurasi sebesar 93%. Untuk detail hasil evaluasi model pertama dengan 15 epoch menggunakan precision, recall, dan f1-score dapat dilihat pada gambar confusion matrix dan tabel berikut:
|
Confusion Matrix |
O | |||||||||||||
|
freshapples -I |
778 |
O |
O |
O |
2 |
O |
O |
11 |
O |
O |
O |
O |
O | |
|
freshbanana - |
1 |
887 |
O |
O |
O |
O |
O |
4 |
O |
O |
O |
O |
O |
O |
|
freshcucumber - |
2 |
O |
252 |
22 |
O |
1 |
O |
O |
O |
O |
2 |
O |
O |
O |
|
freshokra - |
1 |
O |
128 |
239 |
O |
O |
O |
O |
O |
2 |
O |
O |
O |
O |
|
freshoranges - |
O |
O |
O |
O |
385 |
O |
O |
2 |
O |
O |
O |
1 |
O |
O |
|
freshpatato - |
O |
1 |
O |
O |
O |
242 |
O |
O |
O |
4 |
O |
O |
23 |
O |
|
freshtomato - |
1 |
O |
O |
O |
O |
1 |
253 |
O |
O |
O |
O |
O |
O |
O |
|
rottenapples - |
8 |
O |
O |
O |
4 |
O |
1 |
975 |
O |
O |
O |
O |
O |
O |
|
rottenbanana - |
O |
O |
O |
O |
O |
O |
O |
2 |
898 |
O |
O |
O |
O |
O |
|
rottencucumber - |
O |
O |
44 |
6 |
O |
1 |
1 |
O |
4 |
182 |
13 |
O |
3 |
1 |
|
rottenokra - |
1 |
O |
30 |
28 |
O |
5 |
1 |
O |
O |
11 |
119 |
1 |
28 |
O |
|
TOttenoranges - |
O |
1 |
O |
O |
10 |
O |
O |
4 |
O |
O |
O |
388 |
O |
O |
|
TOttenpatato - |
O |
2 |
O |
O |
O |
37 |
O |
1 |
O |
O |
O |
O |
329 |
1 |
|
TOttentomato - |
1 |
O |
O |
2 |
O |
O |
24 |
O |
O |
O |
O |
2 |
2 |
322 |

Prediction
Gambar 8. Confusion Matrix Hasil Testing Model Pertama Epoch 15.
Tabel 2. Tabel Nilai Evaluasi Model Pertama Epoch 15
|
precision recall f1-score support | ||||
|
freshapples |
0,98 |
0,98 |
0,98 |
791 |
|
freshbanana |
1,00 |
0,99 |
0,99 |
892 |
|
freshcucumber |
0,56 |
0,90 |
0,69 |
279 |
|
freshokra |
0,80 |
0,65 |
0,72 |
370 |
|
freshoranges |
0,96 |
0,99 |
0,98 |
388 |
|
freshpatato |
0,84 |
0,90 |
0,87 |
270 |
|
freshtomato |
0,90 |
0,99 |
0,95 |
255 |
|
rottenapples |
0,98 |
0,99 |
0,98 |
988 |
|
rottenbanana |
1,00 |
1,00 |
1,00 |
900 |
|
rottencucumber 0,91 |
0,71 |
0,80 |
255 | |
|
rottenokra |
0,89 |
0,53 |
0,66 |
224 |
|
rottenoranges |
0,99 |
0,96 |
0,98 |
403 |
|
rottenpatato |
0,85 |
0,89 |
0,87 |
370 |
|
rottentomato |
0,99 |
0,91 |
0,95 |
353 |
|
accuracy |
0,93 |
6738 | ||
Dari tabel diatas dapat dilihat pada hasil testing model pertama yang dilatih dengan 15 epoch menghasilkan akurasi sebesar 0,93. Nilai precision tertinggi didapat pada kelas freshbanana dan rottenbanana dengan nilai precision 1,00. Untuk nilai precision terendah didapat pada kelas freshcucumber dengan nilai 0,56. Nilai recall tertinggi pada kelas rottenbanana dengan nilai 1,00. Nilai recall terendah didapat pada kelas rottenokra dengan nilai 0,53. Nilai f1-score tertinggi didapat pada kelas rottenbanana dengan nilai 1,00. Nilai f1-score terendah dimiliki kelas rottenokra dengan nilai 0,66.
Model kedua adalah hasil modifikasi dari model pertama dengan penambahan layer konvolusi pada setiap blok konvolusi dan penambahan layer dropout setelah maxpooling layer. Pelatihan model kedua dilakukan sebanyak 2 kali dengan epoch yang berbeda yaitu dengan epoch 10 dan epoch 15. Data train yang telah melalui proses normalisasi dan resize digunakan untuk pelatihan model. Hasil dari pelatihan model kedua dengan epoch 10 yang telah diuji menggunakan data test adalah model mendapat akurasi sebesar 87%. Akurasi yang didapat lebih kecil dari akurasi model pertama dengan epoch 10. Untuk detail hasil evaluasi model kedua dengan epoch 10 menggunakan precision, recall, dan f1-score dapat dilihat pada gambar confusion matrix dan tabel berikut:
Tabel 3. Tabel Nilai Evaluasi Model Kedua Epoch 10
|
precisionrecallf1-scoresupport | ||||
|
freshapples |
0,97 |
0,95 |
0,96 |
791 |
|
freshbanana |
1,00 |
0,95 |
0,97 |
892 |
|
freshcucumber 0,54 |
0,46 |
0,49 |
279 | |
|
freshokra |
0,60 |
0,74 |
0,66 |
370 |
|
freshoranges |
0,96 |
0,94 |
0,95 |
388 |
|
freshpatato |
0,84 |
0,69 |
0,76 |
270 |
|
freshtomato |
0,81 |
0,91 |
0,86 |
255 |
|
rottenapples |
0,91 |
0,96 |
0,93 |
988 |
|
rottenbanana |
0,93 |
1,00 |
0,96 |
900 |
|
rottencucumben0,72 |
0,52 |
0,60 |
255 | |
|
rottenokra |
0,58 |
0,48 |
0,52 |
224 |
|
rottenoranges |
0,94 |
0,92 |
0,93 |
403 |
|
rottenpatato |
0,72 |
0,81 |
0,77 |
370 |
|
rottentomato |
0,86 |
0,84 |
0,85 |
353 |
|
accuracy |
0,87 |
6738 | ||
OJ
∏3
freshapples -
freshbanana -
freshcucumber -
freshokra -
freshoranges -
Prediction
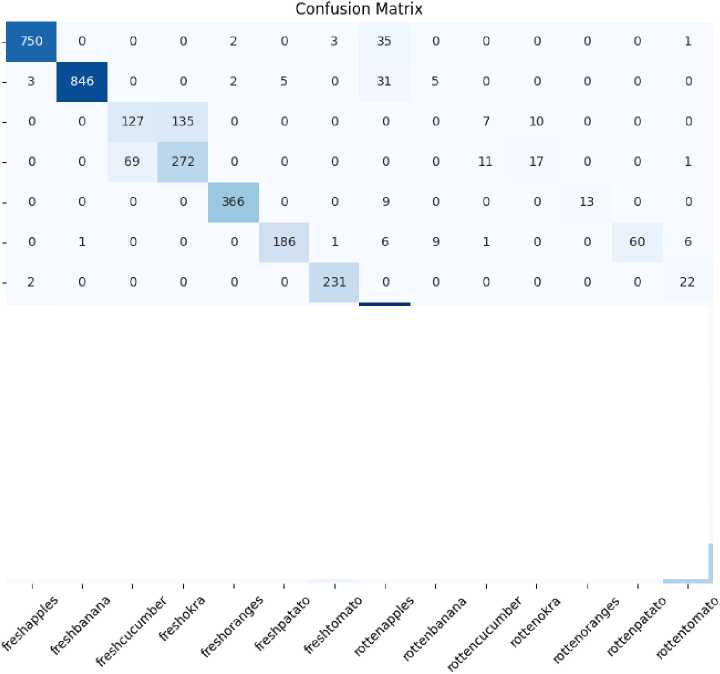
Gambar 9. Confusion Matrix Hasil Testing Model Kedua Epoch 10.
freshpatat□ -
freshtomato -
⅛
|
TOttenappIes - |
18 |
O |
O |
O |
6 |
O |
2 |
947 |
7 |
O |
O |
6 |
1 |
1 |
|
TOttenbanana - |
O |
O |
O |
O |
O |
O |
O |
O |
899 |
O |
O |
O |
1 |
O |
|
TOttencucumber - |
O |
O |
21 |
22 |
O |
1 |
O |
O |
9 |
132 |
49 |
1 |
15 |
5 |
|
rottenokra - |
1 |
O |
17 |
21 |
O |
3 |
O |
O |
7 |
33 |
107 |
O |
32 |
3 |
|
TOttenoranges - |
O |
O |
O |
O |
5 |
O |
3 |
14 |
4 |
O |
O |
371 |
3 |
3 |
|
TOttenpatato - |
O |
3 |
O |
O |
O |
26 |
1 |
3 |
28 |
O |
2 |
1 |
301 |
5 |
|
TOttentomato - |
1 |
O |
2 |
O |
O |
1 |
44 |
1 |
1 |
O |
O |
2 |
3 |
298 |
Dari tabel diatas dapat dilihat pada hasil testing model kedua yang dilatih dengan 10 epoch menghasilkan akurasi sebesar 0,87. Nilai precision tertinggi didapat pada kelas freshbanana dengan nilai precision 1,00. Untuk nilai precision terendah didapat pada kelas freshcucumber dengan nilai 0,54. Nilai recall tertinggi pada kelas rottenbanana dengan nilai 1,00. Nilai recall terendah didapat pada kelas freshcucumber dengan nilai 0,46. Nilai f1-score tertinggi didapat
pada kelas freshbanana dengan nilai 0,97. Nilai f1-score terendah dimiliki kelas freshcucumber dengan nilai 0,49.
Hasil dari pelatihan model kedua dengan epoch 15 yang telah diuji menggunakan data test adalah model mendapat akurasi sebesar 90%. Untuk detail hasil evaluasi model pertama
dengan 15 epoch menggunakan precision, confusion matrix dan tabel berikut:
recall, dan f1-score dapat
dilihat
pada
gambar
OJ
∏3
freshapples -
freshbanana -
freshcucumber -
freshokra -
freshoranges -
freshpatat□ -
freshtomato -
⅛
|
TOttenappIes - |
4 |
3 |
O |
O |
9 |
O |
O |
959 |
3 |
O |
O |
10 |
O |
O |
|
TOttenbanana - |
O |
O |
O |
O |
O |
O |
O |
O |
899 |
O |
O |
1 |
O |
O |
|
TOttencucumber - |
O |
1 |
8 |
21 |
O |
O |
1 |
1 |
5 |
141 |
59 |
1 |
16 |
1 |
|
rottenokra - |
O |
O |
2 |
30 |
O |
O |
6 |
O |
3 |
26 |
144 |
O |
11 |
2 |
|
TOttenoranges - |
O |
O |
O |
O |
9 |
O |
2 |
6 |
1 |
O |
O |
384 |
O |
1 |
|
TOttenpatato - |
O |
2 |
O |
O |
O |
40 |
1 |
2 |
16 |
O |
2 |
O |
301 |
6 |
|
TOttentomato - |
O |
O |
1 |
O |
O |
O |
45 |
3 |
1 |
O |
2 |
O |
O |
301 |
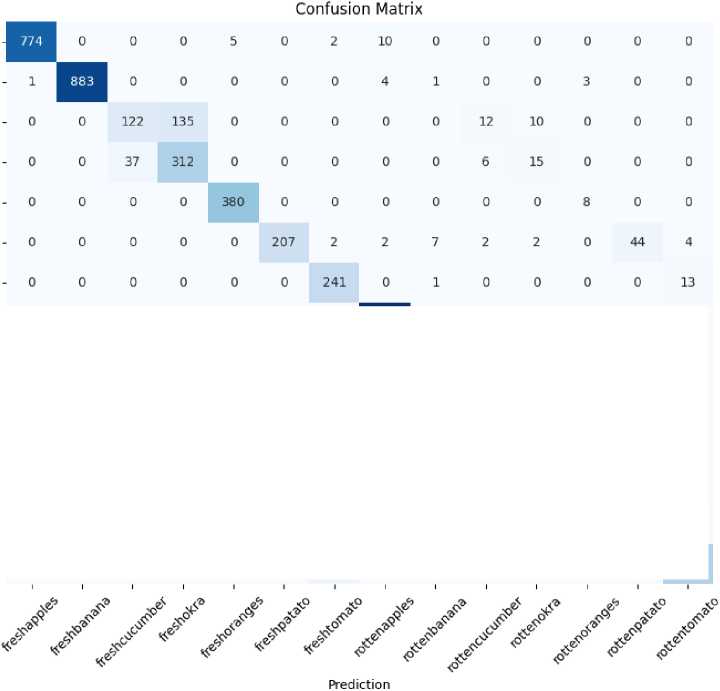
Gambar 10. Confusion Matrix Hasil Testing Model Kedua Epoch 15.
Tabel 4. Tabel Nilai Evaluasi Model Kedua Epoch 15
|
precisionrecallf1-scoresupport | ||||
|
freshapples |
0,99 |
0,98 |
0,99 |
791 |
|
freshbanana |
0,99 |
0,99 |
0,99 |
892 |
|
freshcucumber 0,72 |
0,44 |
0,54 |
279 | |
|
freshokra |
0,63 |
0,84 |
0,72 |
370 |
|
freshoranges |
0,94 |
0,98 |
0,96 |
388 |
|
freshpatato |
0,84 |
0,77 |
0,80 |
270 |
|
freshtomato |
0,80 |
0,95 |
0,87 |
255 |
|
rottenapples |
0,97 |
0,97 |
0,97 |
988 |
|
rottenbanana |
0,96 |
1,00 |
0,98 |
900 |
|
rottencucumber0,75 |
0,55 |
0,64 |
255 | |
|
rottenokra |
0,62 |
0,64 |
0,63 |
224 |
|
rottenoranges |
0,94 |
0,95 |
0,95 |
403 |
|
rottenpatato |
0,81 |
0,81 |
0,81 |
370 |
precisionrecallf1-scoresupport
rottentomato 0,92 0,85 0,88 353 accuracy 0,90 6738
Dari tabel diatas dapat dilihat pada hasil testing model kedua yang dilatih dengan epoch 15 menghasilkan akurasi sebesar 0,90. Akurasi yang didapat lebih kecil dari akurasi model pertama dengan epoch 15 bahkan lebih kecil dengan model pertama dengan epoch 10. Nilai precision tertinggi didapat pada kelas freshbanana dan freshapples dengan nilai precision 0,99. Nilai precision terendah didapat pada kelas rottenokra dengan nilai 0,62. Nilai recall tertinggi pada kelas rottenbanana dengan nilai 1,00. Nilai recalls terendah didapat pada kelas freshcucumber dengan nilai 0,44. Nilai f1-score tertinggi didapat pada kelas freshbanana dan freshapples dengan nilai 0,99. Nilai f1-score terendah dimiliki kelas freshcucumber dengan nilai 0,54.
Dari keempat percobaan diatas dapat diketahui bahwa banyaknya epoch pelatihan mempengaruhi peningkatan kinerja dari model. Berdasarkan data evaluasi yang telah didapat pada model pertama dan model kedua, pada epoch pelatihan 15 memiliki kinerja lebih baik dibandingkan dengan model yang dilatih pada epoch pelatihan 10. Berdasarkan data evaluasi diatas penambahan jumlah layer konvolusi belum tentu mempengaruhi peningkatan kinerja dari sebuah model. Model kedua yang memiliki lebih banyak layer konvolusi dan ditambah memiliki layer dropout menghasilkan hasil akurasi yang cenderung lebih kecil dibandingkan dengan model pertama yang memiliki layer lebih sedikit.
Model yang akan diintegrasi ke dalam aplikasi berbasis web adalah model pertama yang dilatih dengan epoch 15 yang mendapat akurasi sebesar 93%. Tampilan dari aplikasi berbasis website untuk integrasi model dapat dilihat pada gambar di bawah:
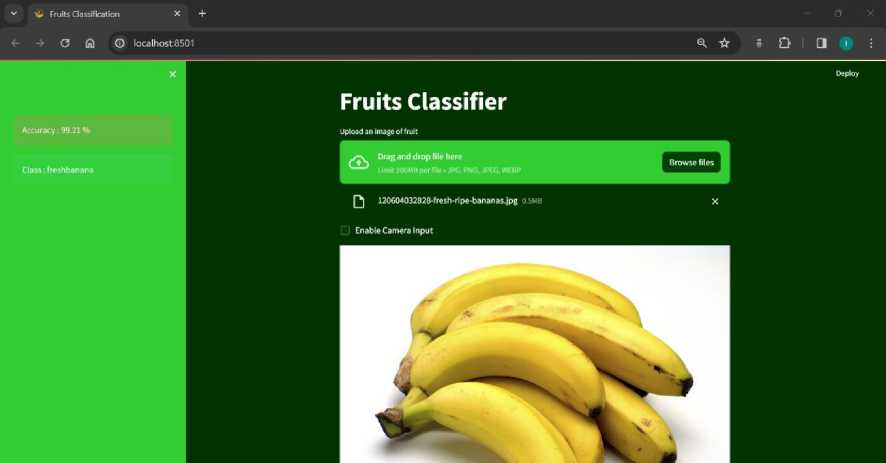
Gambar 11. Tampilan Website Fruits Classifier.
User dapat meng-input gambar dengan cara drag and drop atau dengan mencari data gambar di memori lokal. Kemudian hasil klasifikasi akan ditampilkan pada sidebar sebelah kiri dengan nama kelas dan juga akurasi yang didapatkan oleh model dalam mengklasifikasikan gambar tersebut. Selain upload file dari memori lokal, user juga bisa menggunakan fitur camera input dengan men-checklist ‘Enable Camera Input’. Web akan mengakses camera input pada device tersebut. Tampilan saat menggunakan fitur camera input dapat dilihat pada gambar di bawah:
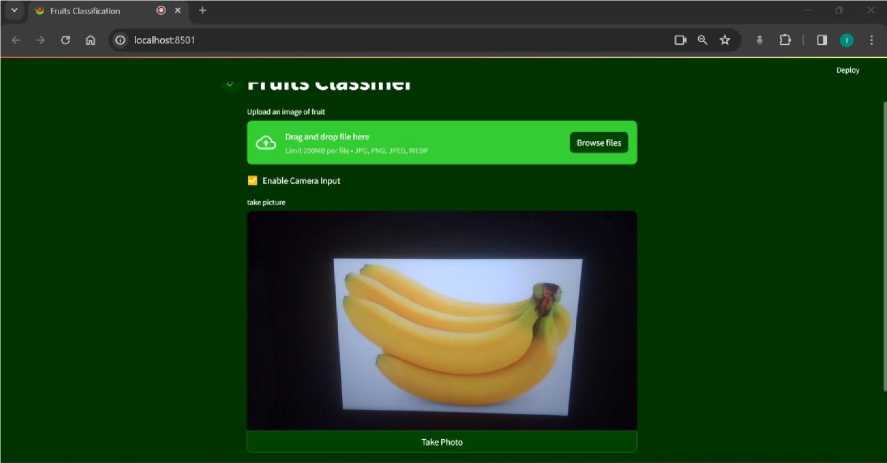
Gambar 12. Tampilan Website Fruits Classifier Fitur Camera Input.
Dengan mengklik tombol ‘Take Photo’ maka gambar akan langsung diproses kemudian diklasifikasikan.
Berdasarkan hasil evaluasi pelatihan model pertama dan model kedua, dapat disimpulkan bahwa, peningkatan jumlah epoch cenderung meningkatkan kinerja model, terlihat dari hasil model pertama dan kedua pada epoch 10 dan epoch 15 dimana hasil evaluasi meningkat pada epoch 15. Model kedua dengan penambahan layer konvolusi dan dropout yang lebih banyak, tidak selalu menghasilkan performa yang lebih baik dibandingkan dengan model dengan layer yang lebih sedikit seperti model pertama. Penambahan layer dropout dapat membantu mencegah overfitting, namun efektifitas dari layer dropout tergantung pada kompleksitas model dan karakteristik dataset. Pada penelitian ini model yang memiliki lebih sedikit layer dropout cenderung memiliki akurasi lebih tinggi yaitu pada model pertama. Pada penelitian ini, didapat akurasi terbaik dari model pertama dengan epoch 15 dengan nilai akurasi sebesar 93%. Hasil ini membuktikan bahwa model yang telah dibangun dan dilatih telah mendekati akurasi yang baik dari penelitian sejenis sebelumnya.
Daftar Pustaka
-
[1] A. Sharma, G. Phonsa. “Image Classification Using CNN”. Proceedings of the International Conference on Innovative Computing & Communication (ICICC) 2021, Available at SSRN: https://ssrn.com/abstract=3833453 or http://dx.doi.org/10.2139/ssrn.3833453
-
[2] N. Ibrahum, et al. “Klasifikasi Tingkat Kematangan Pucuk Daun Teh Menggunakan Metode Convolutional Neural Network”. ELKOMIKA: Jurnal Teknik Energi Elektrik, Teknik Telekomunikasi, & Teknik Elektronika, vol. 10, no. 1, p. 162-176, 2022
-
[3] M.A. Parab, N.D. Mehendale. “Red blood cell classification using image processing and CNN”. bioRxiv, 2020, Available at: https://doi.org/10.1101/2020.05.16.087239
-
[4] R.R. Allaam and A.T. Wibowo. “Klasifikasi Genus Tanaman Anggrek Menggunakan Metode Convolutional Neural Network (CNN)”. e-Proceeding of Engineering, vol. 8, no. 2, p. 11531189, 2021
-
[5] S.S. Nayak, “Fresh and Rotten Classification”, 07 June 2023. [Online]. Available: https://www.kaggle.com/datasets/swoyam2609/fresh-and-stale-classification. [Accessed on
08 October 2023]
Halaman ini sengaja dibiarkan kosong
442
Discussion and feedback