ESTIMASI CVAR PADA PORTOFOLIO SAHAM MENGGUNAKAN METODE GJR-EVT DENGAN PENDEKATAN D-VINE COPULA
on
E-Jurnal Matematika Vol. 11(2), Mei 2022, pp. 127-139
DOI: https://doi.org/10.24843/MTK.2022.v11.i02.p372
ISSN: 2303-1751
ESTIMASI CVAR PADA PORTOFOLIO SAHAM MENGGUNAKAN METODE GJR-EVT DENGAN PENDEKATAN D-VINE COPULA
Dery Maulana1§, Komang Dharmawan 2, I Gusti Ayu Made Srinadi 3
1Program Studi Matematika, Fakultas MIPA – Universitas Udayana[Email: derymaulana119@gmail.com]
2Program Studi Matematika, Fakultas MIPA – Universitas Udayana [Email: k.dharmawan@unud.ac.id]
3Program Studi Matematika, Fakultas MIPA – Universitas Udayana [Email: srinadi@unud.ac.id ]
§Corresponding Author
ABSTRACT
Risk measure using Conditional Value at Risk can be calculate if values that exceeds the p-quantile is known in VaR. The models used to accommodate characteristics of the stock portfolio in this research are EVT-GARCH-D-vine copula and EVT-GJR-D-vine copula so the performance of these two models can be compared. A comparison of the performance of the EVT-GARCH-D-vine copula and EVT-GJR-D-vine copula models can be seen from the Kupiec test backtesting process. Exceeded value Kupiec Test on CVaR 99% is 2, CVaR 95% is 6, and CVaR 90% is 13 for AR(1)-GARCH-t(1,1)-GPD and CVaR 99% is 3, CVaR 95% is 7, and CVaR 90% is 13 for AR(1)-GJR-t(1,1)-GPD. The Kupiec test describes the estimated risk value of CVaR running well with the value of the entire model above the significant level of α = 0.05 so as to provide a conclusion of risk estimates considered feasible.
Keywords: CVaR, D-vine copula, EVT, GJR-GARCH
1. PENDAHULUAN
Manajemen risiko perlu dilakukan oleh investor dalam investasi saham. Nilai risiko dalam portofolio saham yang telah ditetapkan investor perlu diketahui secara mendalam. Hal ini bertujuan untuk menghindari risiko kerugian pada masa yang akan datang.
Terdapat istilah umum yang dikenal dalam finansial yaitu high risk, high return. Jika investor ingin memperoleh return yang tinggi maka semakin tinggi juga risiko yang muncul. Istilah tersebut juga berkaitan dengan pengertian volatilitas. Volatilitas dalam finansial berarti pergerakan yang tidak menentu suatu aset finansial. Semakin tinggi volatilitas maka semakin tinggi risiko ataupun return yang terjadi pada aset finansial tersebut.
Volatilitas asimetris, yaitu pergerakan volatilitas yang tidak searah dengan return terjadi pada beberapa kasus finansial. Pergerakan volatilitas turun ketika return naik, dalam contoh kasus disebut leverage effect. Metode kasus tersebut ialah metode Glosen, Jagannathan, dan Runkle GARCH (GJR-GARCH) (Brooks, 2008).
EVT dapat meramalkan terjadinya kejadian
ekstrem pada data berekor gemuk (fat tail) yang umum terjadi pada data finansial. Danielsson (2011) keberadaan ekor gemuk pada data dapat dilihat pada QQ plot yang mengikuti distribusi normal standar. Semakin banyak nilai quantile yang menjauh dari garis maka indikasi ekor gemuk pada data semakin besar.
Perilaku antaraset finansial dapat diketahui dengan melihat kebergantungan antaraset finansial sebagai langkah untuk melakukan diversifikasi. Kebergantungan antaraset finansial pada portofolio yang tersusun dari beberapa aset finansial harus dianalisis karena kebergantungan ini akan memberikan informasi terkait pengukuran risiko suatu portofolio. Data yang berdistribusi normal merupakan asumsi yang diperlukan untuk mengetahui kebergantungan antarpeubah acak yang diukur menggunakan korelasi linier. Danielsson (2011) sebagian besar data finansial tidak berdistribusi normal, terindikasi berekor gemuk pada distribusinya, serta memiliki kebergantungan taklinier. Kebergantungan antarpeubah acak pada data finansial kurang cocok jika menggunakan korelasi linier maka
salah satu alternatifnya pada kasus data finansial yaitu menggunakan pendekatan copula.
Value at risk (VaR) salah satu metode yang digunakan untuk mengukur risiko pada data finansial. Ukuran risiko menggunakan VaR dapat dikatakan baik jika kondisi kemonotonan, subaditivitas, positif homogen, invarian terhadap translasi terjaga. Jumlahan antara dua risiko tidak selalu kurang dari atau sama dengan dua risiko yang dijumlahkan atau biasa disebut subaditivitas dalam beberapa kasus estimasi risiko pada VaR tidak terjaga.
Conditional value at risk (CVaR) menjadi solusi karena dapat mengakomodasi masalah subaditivitas yang tidak dapat terjaga pada VaR. Sehingga CVaR dikatakan pengukuran risiko yang lebih koheren dari pada VaR (Alexander et al, 2006).
Prosedur pengujian validitas suatu model risiko adalah Backtesting. Backtesting merupakan suatu metode untuk menguji seberapa baik model risiko yang telah diestimasi. Uji Kupiec adalah metode yang menguji banyaknya frekuensi kerugian pada ekor kiri distribusi (Kichen, 2017).
Penelitian ini merupakan pengembangan penelitian Sudina (2019) dengan memperluas ruang lingkup melibatkan struktur dekomposisi D-vine copula dan membandingkan hasilnya dengan estimasi CVaR yang dilakukan Sudina (2019). Dalam membandingkan kinerja AR(1)-GARCH(1,1) dan AR(1)-GJR(1,1), Sudina (2019) menggunakan backtesting dengan metode V-test. Hasil yang diperoleh ialah model AR(1)-GJR(1,1) lebih baik karena secara umum nilai statistik K1 ,V2, dan V model AR(1)-GJR(1,1) lebih kecil daripada model AR(1)-GARCH(1,1).
Pergerakan harga saham domestik market cenderung serupa karena dipengaruhi oleh global market. Portofolio saham yang baik salah satu cirinya memiliki pergerakan harga saham yang tidak saling memengaruhi. Penelitian ini menggunakan portofolio saham mencakup global market yang berada di Asia, yaitu indeks saham Dow Jones Jepang, Dow Jones Singapura, dan Dow Jones Taiwan.
Log return merupakan salah satu model yang umum digunakan dalam analisis data finansial. Menurut Danielsson (2011) return adalah perubahan relatif pada harga aset finansial pada interval waktu tertentu. Berikut penjabaran dari log return :
Definisi 1 Return (Danielsson, 2011) Jika St menyatakan log return aset pada periode ke-t didefinisikan sebagai berikut:
rt = 1°g (⅛) = 1°g St — 1°gSt-ι
(1)
rt merupakan return pada waktu ke-t, St merupakan nilai aset pada periode waktu ke-t, St-1 merupakan nilai aset pada periode waktu ke-(t — 1)
Secara matematis model GARCH(p, q^) dapat ditulis sebagai berikut:
£t = otzt
p a
σ? = ω + ∑ alε2-l + ∑ βjσt-j i=i j=i
ω adalah komponen konstanta, merupakan galat/eror pada waktu ke-t,
(2)
εt σt
merupakan deviasi standar pada waktu ke-t, zt adalah variabel peubah acak IID dengan rataan nol dan varians satu, ai adalah parameter ARCH, εt-t merupakan kuadrat galat/eror pada waktu t — 1,i = 1,2, ...,p,βj adalah parameter GARCH, σt-j adalah varians dari kuadrat galat pada waktu t — j, j = 1,2,..., q.
McNeil (2005) menyatakan pemodelan volatilitas pada return akan bersifat stasioner jika return dari aset mengikuti proses autoregresif orde pertama atau AR(1) dengan
Rt = φRt-ι + εt, ∣φ∣<1
(3)
Parameter φ merupakan parameter AR(I) yang mana jika φ = 1 maka proses mengikuti random walk yang menyebabkan nilai return tidak stasioner sehingga nilai dari φ harus tetap kurang dari satu.
Zivot (2008) menghitung efek asimetris pada return dengan cara menghitung korelasi
antara kuadrat return dan return aset periode sebelumnya. Secara matematis ditulis sebagai berikut
pada dapat
∑n v"2,v
t = 1 't tt-1
cor(rf,rt-1) =
(4)
√(∑t=ι(rt2)2rt2-ι
Salah satu contoh efek asimetris adalah ketika nilai korelasi pada Persamaan (4) mengarah bernilai negatif. Nilai yang negatif pada korelasi return kuadrat dan return akan menyebabkan nilai volatilitas berkurang. Prinsip memodelkan volatilitas yang baik ialah
Secara matematis model GJR-
GARCH(p, q) dapat ditulis sebagai berikut: εt = σtzt p?
σt =ω + ∑Jaεt-i+ Yiε2-iLt-i) + ∑ βjσ2-j
(⅛ι<0
L (0,εt-i>0
Sesuai dengan parameter GARCH(p, qj parameter pembeda pada model GJR-
GARCH (p, qj adalah
γt sebagai parameter efek asimetris.
Definisi 2 Ekor Gemuk (Danielsson, 2011) Peubah acak dikatakan memiliki ekor gemuk apabila terdapat titik ekstrem yang lebih banyak daripada peubah acak yang mengikuti distribusi normal standar.
Identifikasi awal pada EVT ialah melihat keberadaan nilai ekstrem pada QQ plot. Nilai yang menjauh dari garis bantu pada QQ plot diasumsikan sebagai nilai ekstrem pada data. Langkah selanjutnya dilakukan metode Peak Over Threshold (POT). POT diawali dengan menentukan ambang batas p. Ambang batas p adalah batas yang ditentukan dari fungsi distribusi peubah acak. POT mengasumsikan peubah acak berdistribusi IID. Chaves-Demoulin (1999) dalam Zuhara et al (2012) menyarankan untuk memilih ambang batas p sebesar 10% dari total data amatan. Karena fungsi distribusi yang tidak diketahui pada Yx dari {x1, x2, ., xn}, maka akan sulit mengestimasi Yμ(x) secara langsung. Kesulitan ini dapat diatasi dengan menggunakan pendekatan GPD.
Definisi 3 Fungsi Distribusi Generalized Pareto Distribution (GPD) (Franke et al.,
2011) menyatakan GPD sebagai berikut:
Gξ,β(y) = 1-(1 + ξy)
{y > 0 ,jika ξ > 0,
[0≤y≤ -(|)],jika ξ<0, dan
Gξ,β (y) = 1 - e ^ untuk y = 0,jika ξ = 0. ξ merupakan skala bentuk dan β skala
(6)
(7)
parameter > 0
Definisi 4 Copula (Franke, 2011) Copula berdimensi n adalah fungsi distribusi berdimensi n dengan fungsi marginal uniform standar [0,1].
Pada analisis data finansial, memodelkan kebergantungan tak linier antarpeubah acak penyusun portofolio harus ditransformasikan menjadi distribusi uniform standar [0,1] seperti Definisi 4. Dalam proses transformasi distribusi
uniform standar [0,1] dapat menggunakan metode probability integral transformation. Danielsson (2011) menyatakan bahwa metode probability integral transformation dapat mengidentifikasi kebergantungan antarpeubah acak dari hasil transformasinya. Sehingga data return aset saham yang sudah ditransformasi ke bentuk distribusi uniform standar [0,1] dapat digunakan untuk memodelkan struktur kebergantungan antarpeubah acak menggunakan fungsi copula.
Definisi 5 Archimedean Copula (Cherubini et
al., 2004) Fungsi archimedean copula
C: [0,1]d → [0,1] diberikan oleh
C(x, ...,Xn∙,φ) = φ-1(φ(Xι) + ∙∙∙ + φ(xj), ,«>
xl ∈ [0,1]d (8)
Generator copula C adalah fungsi φ(xi), dengan i = 1,..., n yang dipetakan pada rentangan [0,1] pada [0, ∞] sedemikian
sehingga φ(1) = 0 dan φ(0) = ∞. Nilai
generator φ(X[) pada setiap jenis archimedean copula berbeda. Berikut tabel yang menjelaskan perbedaan antara Clayton copula, Gumbel copula, dan Frank copula.
D-vine copula merupakan bagian dari reguler vine copula yang terbentuk dari vine copula.
Definisi 6 D-vine dan C-vine (Kurowicka & Cooke, 2007)
-
a. D-vine memenuhi syarat pada saat masing-
masing node pada tree Tj memiliki drajat paling banyak dua.
-
b. C-vine memenuhi syarat pada saat masing-masing node pada tree Tj memiliki node unik yang disebut akar (root).
Pada penelitian ini selanjutnya penulis akan memakai struktur D-vine copula karena memiliki struktur yang lebih sederhana.
Langkah simulasi return ini perlu dilakukan untuk mengestimasi nilai CVaR pada subbab berikutnya. Data simulasi x1,x2,x3 diperoleh dari invers fungsi distribusi kumulatif sehingga diperoleh kembali komponen barisan independen dengan mean nol dan varians satu (zit) dengan i = 1,2,3. Selanjutnya zit digunakan pada Persamaan (3) yang merupakan proses AR(1) sehingga diperoleh return hasil simulasi D-vine copula yang stasioner.
Definisi 7 (VaR) dan (CVaR) (Klugman et al., 2008 dalam Sudina, 2019)
Diberikan F(X) adalah fungsi distribusi
kerugian dari peubah acak X, sehingga berlaku F (π p) = Pr(X ≤ πp) = p. Invers dari fungsi distribusi D adalah F-1(p) = inf(πp ∈
-
1: F(πp) ≥p) ,0 < p < 1 atau disebut juga sebagai fungsi kuantil dari distribusi F. VaR dan CVaR didefinisikan sebagai:
-
1. Value at Risk (VaR) dari peubah acak X pada tingkat kepercayaan 100p% adalah p-kuantil dari fungsi distribusi F dan dapat dinyatakan sebagai
-
VaRp(X) = πp = F~1(p) (9)
-
2. Conditional Value at Risk (CVaR) dari peubah acak X pada tingkat kepercayaan 100p% merupakan ekspektasi kerugian apabila diketahui besar kerugian yang melebihi p-kuantil dari distribusi F.
CVaRp(X) = E (x∖x> VaRp(X)) (10)
Berdasarkan 2 definisi tersebut, Conditional Value at Risk (CVaR) merupakan metode untuk menghitung risiko yang melebih VaR.
Backtesting merupakan metode untuk menguji suatu model risiko yang terbentuk. Backtesting mampu melihat pergerakan estimasi risiko secara riil pada data return sehingga pengujian dapat terlihat secara langsung. Salah satu metode turunan dari backtesing yang umum digunakan pada data finansial adalah uji Kupiec yang dapat menguji banyaknya frekuensi kerugian pada ekor kiri distribusi (Kichen, 2017).
Jenis data yang digunakan pada penelitian ini adalah data kuantitatif, merupakan data sekunder berupa harga penutupan harian yaitu indeks saham Dow Jones Jepang (DJJP), Dow Jones Singapura (DJSG), dan Dow Jones Taiwan (DJTA) dalam mata uang USD periode 22 April 2013 hingga 10 Februari 2021 sebanyak 2039 data saham harian. Data tersebut dapat diakses melalui situs website www.investing.com.
Langkah-langkah dalam mengestimasi nilai CVaR portofolio menggunakan metode GJR-EVT dengan pendekatan D-vine copula yaitu sebagai berikut :
-
1. Menghitung return indeks saham DJJP, DJSG, dan DJTA.
-
2. Melihat karakteristik data pada statistik
deskriptif return indeks saham DJJP,
DJSG, dan DJTA.
-
3. Memeriksa stasioneritas pada masing-
masing return indeks saham menggunakan
uji formal augmented Dickey-Fuller (ADF).
-
4. Melakukan uji Ljung-Box untuk mengetahui keberadaan sifat autokorelasi pada residual data return.
-
5. Melakukan uji ARCH Lagrange multipler untuk mengetahui sifat heteroskedastisitas pada residual return.
-
6. Memodelkan volatilitas portofolio indeks saham menggunakan model GARCH(1,1).
-
7. Memeriksa efek autokorelasi dan heteroskedastisitas pada data residual.
-
8. Plot kuantil-kuantil (Plot QQ) untuk mengetahui keberadaan ekor gemuk pada data residual model GARCH(1,1).
-
9. Menentukan threshold sebesar 10% dari keseluruhan data sebagai data ekstrem.
-
10. Mengestimasi parameter Generalized Pareto Distribution (GPD) menggunakan maximum likelihood estimator.
-
11. Melakukan transformasi seragam [0,1] pada masing-masing marginal
menggunakan probability integral
transformation.
-
12. Memodelkan distribusi seragam [0,1] dari residual GARCH(1,1) dengan pendekatan D-vine copula.
-
13. Melakukan estimasi parameter D-vine copula.
-
14. Melakukan simulasi return menggunakan dekomposisi D-vine copula.
-
15. Menghitung CVaR 90%, CVaR 95%, dan CVaR 99%.
-
16. Mengulangi langkah 6 sampai 15 menggunakan model GJR(1,1).
-
17. Melakukan validasi model EVT-GJR(1,1)-Dvine copula dengan Uji Kupiec.
Identifikasi data meliputi pergerakan data historis, perhitungan nilai return, dan uji asumsi klasik pada data return. Secara visual yang terlihat pada Gambar 1 bahwa pergerakan harga indeks saham DJJP, DJSG, dan DJTA memiliki fluktuasi perubahan harga yang cukup signifikan.
Gambar 1. Plot Closing Price Indeks Saham DJJP, DJSG, dan DJTA
Plot pada waktu awal hingga menuju tahun 2015 menunjukkan tren naik pada harga saham. Kemudian turun secara drastis hingga menyentuh titik terendah pada akhir 2015 hingga pergerakan nilai saham kembali naik dan menyentuh all time high pada kisaran tahun 2021.
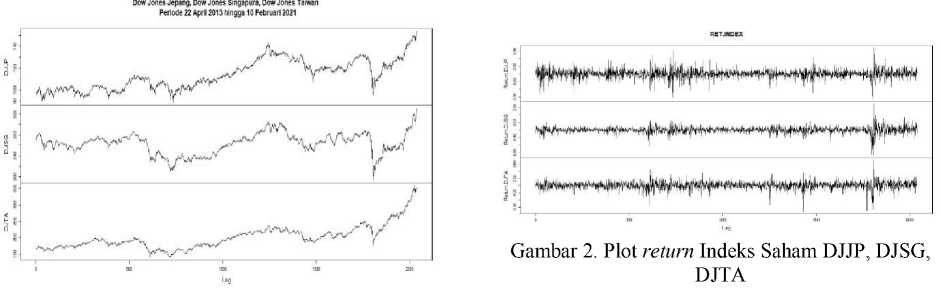
Gambar 2 menunjukkan plot return indeks saham DJJP, DJSG, dan DJTA sebanyak 2037 data. Nilai return tersebut diperoleh dari perhitungan sesuai pada Persamaan (1). Selanjutnya nilai return tersebut digunakan untuk proses estimasi risiko. Identifikasi data dilanjutkan pada tahap uji asumsi klasik pada Tabel 1. Kondisi stasioner, autokorelasi, dan heteroskedastisitas pada data finansial harus
dipenuhi agar dapat dilanjutkan pada tahan pemodelan volatilitas pada subbab selanjutnya.
Tabel 1. Uji Asumsi Klasik pada Data Return
|
Taraf Signifikan a = 0,05 |
p-value Return | ||
|
DJJP |
DJSG |
DJTA | |
|
Uji ADF |
0,01 |
0,01 |
0,01 |
|
Uji Ljung-Box |
4,106× 10—7 |
2,861× 10—7 |
0,001414 |
|
Uji ARCH-LM |
< 2,2× 10—16 |
< 2,2× 10—16 |
< 2,2× 10—16 |
Identifikasi data stasioner pada return indeks saham menggunakan uji ADF dengan hipotesis nol terdapat akar unit pada residual data return menunjukkan nilai yang kurang dari taraf signifikan a = 0,05. Nilai p — value = 0,01 pada ketiga data return. Sehingga cukup bukti untuk menolak hipotesis nol yang mengartikan bahwa return DJJP, DJSG, dan DJTA tidak memiliki akar unit pada residual sehingga return DJJP, DJSG, dan DJTA stasioner.
Hasil dari uji ADF ini sejalan dengan pernyataan Tsay (2013) differencing ordo pertama atau log return sering kali bersifat stasioner daripada harga saham itu sendiri. Sehingga log return baik digunakan untuk analisis deret waktu yang memerlukan asumsi stasioner. Selanjutnya akan diidentifikasi sifat autokorelasi pada data. Korelasi antaramatan pada periode waktu sekarang dan waktu sebelumnya disebut Autokorelasi. Asumsi autokorelasi pada data finansial sangat
diperlukan untuk mengetahui seberapa acak data amatan. Efek Autokorelasi dapat dideteksi dengan uji Ljung-Box pada Tabel 1.
Nilai p — value indeks saham DJJP, DJSG, dan DJTA berturut-turut 4,106× 10-7, 2,861× 10-7, 0,001414 menunjukkan p — value ketiga indeks saham DJJP, DJSG, dan DJTA kurang dari taraf signifikan a = 0,05 dengan hipotesis nol residual data tidak memiliki korelasi sehingga dalam hal ini cukup bukti untuk menolak hipotesis nol yang berarti terdapat autokorelasi pada return indeks saham DJJP, DJSG, dan DJTA.
Kemudian akan diidentifikasi sifat heteroskedastisitas pada data indeks saham DJJP, DJSG, dan DJTA. Suatu keadaan yang terdapat perbedaan varians pada residual data amatan disebut heteroskedastisitas. Pada Tabel 1 sifat heteroskedastisitas diuji dengan uji ARCH-LM. Hasil dari uji tersebut menunjukkan p — value DJJP, DJSG, dan DJTA berturut-turut < 2,2× 10-16, < 2,2× 10-16,
dan < 2,2× 10-16 kurang dari taraf signifikan a = 0,05 dengan hipotesis nol residual data tidak terdapat efek ARCH sehingga cukup bukti untuk menolak hipotesis nol yang berarti indeks saham DJJP, DJSG, dan DJTA bersifat heteroskedastisitas.
Tabel 2. Korelasi Return Kuadrat Periode ke-t dan Return Pada Periode t-1
|
DJJP |
DJSG |
DJTA | |
|
cor(r?, rt—i) |
-0,1270446 |
-0,04969777 |
-0,175283 |
Nilai cor(r^,rt-1) yang negatif mengindikasikan terdapat efek asimetris pada indeks saham DJJP, DJSG, dan DJTA. Hal ini bersesuaian dengan penjelasan pada tinjauan pustaka GJR. Sehingga leverage effect perlu diestimasi pada pemodelan volatilitas pada
subbab berikutnya menggunakan GJR-GARCH.
Karena GARCH(1,1) tidak dapat mengestimasi keberadaan leverage effect maka pada pemodelan volatilitas akan menggunakan model tambahan sebagai pembanding yaitu GJR-GARCH(1,1) karena pada perhitungannya GJR-GARCH(1,1) dapat mengestimasi nilai leverage effect. Danielsson (2011)
menggunakan inovasi distribusi normal dan student-t pada galat model heteroskedastisitas. Tetapi berdasarkan identifikasi data pada Subbab sebelumnya yang mengindikasikan data tidak berdistribusi normal maka pemodelan volatilitas akan menggunakan inovasi distribusi student-t.
Tabel 3. Estimasi Parameter Model AR(1) GARCH-t(1,1)
|
Parameter Optimal (a = 0,05) |
AR(1)-GARCH-t(1,1) | |||||
|
DJJP |
DJSG |
DJTA | ||||
|
Estimasi |
Galat baku |
Estimasi |
Galat Baku |
Estimasi |
Galat baku | |
|
h |
0,000537 |
0,000162 |
0,000313 |
0,000131 |
0,000777 |
0,000180 |
|
φ1 |
-0,136856 |
0,022443 |
0,060357 |
0,022630 |
0,035587 |
0,021261 |
|
ω |
0,000005 |
0,000004 |
0,000001 |
0,000001 |
0,000002 |
0,000002 |
|
a1 |
0,114901 |
0,018998 |
0,090766 |
0,013633 |
0,049026 |
0,023194 |
|
βl |
0,852918 |
0,030963 |
0,899398 |
0,012727 |
0,930946 |
0,029119 |
|
shape |
5,160093 |
0,673173 |
5,947752 |
0,683992 |
4,934189 |
0,500964 |
|
LogLikelihood |
6553,233 |
7344,827 |
6718,311 | |||
|
Kriteria Informasi | ||||||
|
AIC |
-6,4283 |
-7,2055 |
-6,5904 | |||
|
BIC |
-6,4118 |
-7,1890 |
-6,5738 | |||
Tabel 4. Estimasi Parameter Model AR(1)-GJR-t(1,1)
|
Parameter Optimal (a = 0,05) |
AR(1)-GJR-t(1,1) | ||||||
|
DJJP |
DJSG |
DJTA | |||||
|
Estimasi |
Galat baku |
Estimasi |
Galat baku |
Estimasi |
Galat baku | ||
|
h |
0,000379 |
0,000163 |
0,000219 |
0,000130 |
0,000680 |
0,000183 | |
|
φ1 |
-0,125362 |
0,022460 |
0,058855 |
0,022604 |
0,041968 |
0,021580 | |
|
ω |
0,000005 |
0,000001 |
0,000001 |
0,000000 |
0,000003 |
0,000001 | |
|
ai |
0,018947 |
0,007585 |
0,027164 |
0,003391 |
0,009360 |
0,001750 | |
|
β1 |
0,850119 |
0,014270 |
0,919073 |
0,009589 |
0,923510 |
0,009634 | |
|
/1 |
0,167759 |
0,028957 |
0,085149 |
0,017185 |
0,067750 |
0,015101 | |
|
shape |
5,502333 |
0,622112 |
6,322190 |
0,805663 |
5,218537 |
0,603388 | |
|
LogLikelihood |
6570,853 |
7355,325 |
6726,714 | ||||
|
Kriteria Informasi | |||||||
|
AIC |
-6,4446 |
-7,2149 |
-6,5977 | ||||
|
BIC |
-6,4253 |
-7,1955 |
-6,5783 | ||||
Untuk menjaga kondisi stasioner pada pemodelan volatilitas, model AR(1) juga digunakan pada data return dengan perhitungan yang bersesuaian pada Persamaan (3). Model volatilitas akan bernilai baik jika kondisi stasioner dapat terjaga dan varians bernilai
positif.. Estimasi parameter AR(1)-GARCH(1,1) dan AR(1)-GJR(1,1) dengan inovasi distribusi student-t disingkat AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) digunakan maximum likelihood estimator. Tabel 4 dan Tabel 5 berikut secara berturut-
turut menjelaskan estimasi parameter GARCH-t(1,1) dan AR(1)-GJR-t(1,1) menggunakan aplikasi R 4.0.3.
Tabel 3 menjelaskan estimasi parameter dari AR(1)-GARCH-t(1,1) yang menunjukkan bahwa kondisi stasioner tetap terjaga. Hal ini dapat ditunjukkan oleh penjumlahan parameter ARCH (a) dan parameter GARCH (β) untuk masing-masing indeks saham berlaku α1 + β1 < 1. Selanjutnya kondisi positif pada varians model AR(1)-GARCH-t(1,1) juga dapat dipertahankan. Hal ini dapat dilihat dari sifat GARCH-t(1,1) jika ω > 0, α1 > 0, dan β1 > 0 maka varians model positif. Kondisi stasioner juga dapat terjaga pada estimasi parameter model AR(1)-GJR-t(1,1) pada Tabel 4 dengan penjelasan yang sama pada model AR(1)-GARCH-t(1,1). Hal yang menjadi pembeda ialah kondisi positif varians pada model AR(1)-GJR-t(1,1) dapat tercapai jika ω > 0, α1 > 0, dan β1 > 0, dan α1 + γ1 ≥ 0. Terlihat pada
Tabel 4 seluruh sifat yang menjadi syarat model AR(1)-GJR-t(1,1) memiliki kondisi varians yang positif terpenuhi. Karena model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) dapat menjaga kondisi stasioner dan varians positif maka secara karakteristik estimasi parameter model volatilitas berjalan dengan baik.
Estimasi parameter dari model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) juga dapat dilihat pada kriteria informasi yang menampilkan nilai dari Akaike Information Criterion (AIC) dan Bayesian Information Criterion (BIC). Kriteria informasi ini menunjukkan hasil yang kecil pada seluruh indeks saham sehingga dapat dikatakan estimasi parameter memiliki kinerja yang baik.
Lebih lanjut akan dilakukan uji formal pada residual model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) untuk mengetahui seberapa efektif model bekerja. Uji autokorelasi, uji heteroskedastisitas akan dilakukan kembali pada standar residual AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1).
Tabel 5. Uji Formal Ljung-Box dan ARCH-LM pada Standar Residual AR(1)-GARCH-t(1,1) dan
AR(1)-GJR-t(1,1)
|
Taraf signifikan |
p-value residual | |||||
|
AR(1)-GARCH-t(1,1) |
AR(1)-GJR-t(1,1) | |||||
|
a = 0,05 |
DJJP |
DJSG |
DJTA |
DJJP |
DJSG |
DJTA |
|
Uji Ljung-Box |
0,7631 |
0,07773 |
0,05874 0,8045 |
0,1486 |
0,05417 | |
|
Uji ARCH- LM |
0,547 |
0,1785 |
0,9877 |
0,3556 |
0,5031 |
0,9946 |
Hasil uji formal pada Tabel 5 menunjukkan uji Ljung-Box dengan p — value untuk seluruh indeks saham lebih dari taraf signifikan a = 0,05 dengan hipotesis nol terdapat korelasi pada data. Sehingga tidak cukup bukti untuk menolak hipotesis nol yang berarti model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) untuk seluruh indeks saham tidak bersifat autokorelasi.
Selanjutnya untuk uji ARCH-LM menunjukkan p — value untuk seluruh indeks saham melebihi taraf signifikan α = 0,05 dengan hipotesis nol tidak terdapat efek ARCH. Sehingga cukup bukti untuk menolak hipotesis nol yang memiliki arti terdapat efek ARCH pada residual data. Hasil ini menunjukkan bahwa efek heteroskedastisitas telah diatasi dengan baik pada model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1).
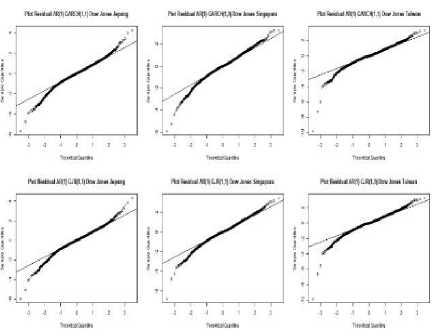
Gambar 3. QQ Plot Residual Model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1)
Residual model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) yang terlihat pada Gambar 3 masih terdapat masalah yang muncul. Pada Gambar 3 ada beberapa data quantile yang bergerak keluar dari garis bantu. Data quantile yang bergerak tidak sesuai dengan distribusi normal ini dinamakan sebagai nilai ekstrem yang mengindikasikan keberadaan ekor gemuk pada data.
Keberadaan nilai ekstrem penyebab ekor gemuk yang terindikasi pada Gambar 3 perlu dimodelkan agar estimasi risiko tidak underestimated. Extreme Value Theorm (EVT) akan digunakan untuk memodelkan ekor gemuk pada residual AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1). Langkah awal untuk memodelkan ekor gemuk adalah identifikasi menggunakan metode POT diawali dengan menentukan ambang batas μ. Sebanyak 203 data ekor kiri residual GARCH-t(1,1) diambil sebagai data ekstrem yang diperoleh dari 10% dari 2038 total data. Dua ratus tiga data ekor kiri residual AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) akan dimodelkan menggunakan GPD sebagai solusi pemodelan ekor gemuk. Estimasi parameter GPD menggunakan likelihood estimator (MLE) diberikan pada Tabel 6.
Tabel 6. Estimasi Parameter Model GPD
|
Parameter |
AR(1)-GARCH-t(1,1) |
AR(1)-GJR-t(1,1) | ||||
|
DJJP |
DJSG |
DJTA |
DJJP |
DJSG |
DJTA | |
|
μ |
-1,21404 |
-1,2518 |
-1,2154 |
-1,22323 |
-1,235 |
-1,2182 |
|
Excess |
203 |
203 |
203 |
203 |
203 |
203 |
|
β |
0,79428 |
0,66533 |
0,61991 |
0,76676 |
0,66428 |
0,6063 |
|
ξ |
-0,05251 |
0,04322 |
0,17491 |
-0,03366 |
0,03374 |
0,1654 |
Perbedaan antara distribusi Pareto II dan distribusi Pareto adalah karakteristik distribusi Pareto memiliki nilai ekor yang lebih gemuk.
Gambar 4. Plot Pencar Residual Model AR(1)-GARCH-t(1,1)

Gambar 5. Plot Pencar Residual Model AR(1)-GJR-t(1,1)
Pada analisis data finansial, memodelkan kebergantungan tak linier antarpeubah acak penyusun portofolio dengan metode copula harus ditransformasikan menjadi distribusi uniform standar [0,1] seperti Definisi 2.9. Metode probability integral transformation digunakan pada proses transformasi distribusi uniform standar [0,1] dapat menggunakan. Berikut Plot distribusi uniform standar [0,1] dari model AR(1)-GARCH-t(1,1)-GDP dan AR(1)-GJR-t(1,1)-GDP.
Hasil estimasi parameter GPD pada Tabel 6 menunjukkan nilai ξ residual data DJJP model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1) memiliki nilai yang negatif. Hal ini menunjukkan bahwa residual model dari data DJJP dengan nilai di bawah μ akan mengikuti distribusi Pareto II. Selanjutnya nilai ξ lebih besar dari nol ditunjukkan pada residual sisanya sehingga data residual yang memiliki nilai lebih kecil dari μ akan mengikuti distribusi Pareto.

Gambar 6. Plot Pencar residual Transformasi
Uniform [0,1] AR(1)-GARCH-t(1,1)-GDP
Gambar 7. Plot Pencar residual Transformasi
Tabel 8. Nilai Spearman (ρ) Residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] dan Residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1]
|
Spearm an (P) |
Residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] |
Residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1] | ||||
|
DJJP |
DJSG |
DJTA |
DJJP |
DJSG |
DJT | |
|
DJJP |
1 |
0,2781294 |
0,3134437 |
1 |
0,2920061 |
0,301 |
|
DJSG |
0,2781294 |
1 |
0,4071472 |
0,2920061 |
1 |
0,397 |
|
DJTA |
0,3134437 |
0,4071472 |
1 |
0,3012252 |
0,3975560 |
1 |
Uniform [0,1] AR(1)-GJR-t(1,1)-GDP
Karena plot pencar pada Gambar 6 dan Gambar 7 hanya menampilkan kebergantungan data antarsaham secara visual maka diperlukan analisis lebih lanjut guna mengetahui aset saham yang paling berpengaruh pada portofolio. Nilai Kendall (t) dan Spearman (p) akan digunakan untuk mengetahui aset saham yang memiliki nilai kebergantungan terkecil yang selanjutnya akan digunakan sebagai node penyusun copula multivariat.
Tabel 7. Nilai Kendall (τ) Residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] dan Residual
AR(1)-GJR-t(1,1)-GPD Uni- form [0,1]
|
Nilai Kend all (t) |
Residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] |
Residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1] | ||||
|
DJJP |
DJSG |
DJTA |
DJJP |
DJSG |
DJTA | |
|
DJJP |
1 |
0,1905755 |
0,2152622 |
1 |
0,2001470 |
0,2071 |
|
DJSG |
0,1905755 |
1 |
0,2833870 |
0,2001470 |
1 |
0,2765 |
|
DJTA |
0,2152622 |
0,2833870 |
1 |
0,2071134 |
0,2765248 |
1 |
Tabel 7 dan Tabel 8 menunjukkan nilai Kendall (t) dan Spearman (p) secara bivariat pada setiap aset indeks saham. Nilai terkecil ditunjukkan DJJP dengan nilai Kendall (t) dan 0,1905755 pada DJSG dan 0,2152622 pada DJTA untuk residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1]. Hasil serupa ditunjukkan pada residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1]. Nilai terkecil berada pada DJJP dengan nilai Kendall (t) 0,2920061 pada DJSG dan 0,3012252 pada DJTA. Nilai Spearman (p) pada Tabel 8 juga menunjukkan nilai terkecil berada pada DJJP. Nilai residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] dan AR(1)-GJR-t(1,1)-GPD Uniform [0,1] DJJP yang kecil pada kebergantungan bivariat pada DJSG dan DJTA menjadikan data DJJP sebagai node penyusun copula multivariat.
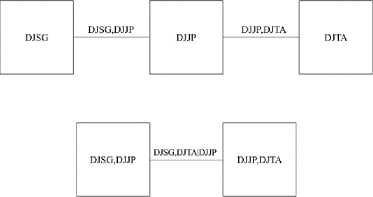
Gambar 8. Dekomposisi D-vine Copula Indeks saham DJJP, DJSG, dan DJTA
Tabel 9. Estimasi Parameter D-vine Copula pada Residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] dan Residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1]
|
Residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] |
Residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1] | ||||||
|
Tree |
Edge |
Family |
Parameter |
Tree |
Edge |
Family |
Parameter |
|
1 |
DJSG,DJJP |
Clayton |
0,49 (0,04) |
1 |
DJSG,DJJP |
Clayton |
0,51 (0,04) |
|
DJJP,DJTA |
Clayton |
0,74 (0,04) |
DJJP,DJTA |
Clayton |
0,75 (0,04) | ||
|
2 |
DJSG,DJTA| DJJP |
Clayton |
0,29 (0,03) |
2 |
DJSG,DJTA| DJJP |
Clayton |
0,25 (0,03) |
|
Type: D-vine |
logLik: 314,76 |
AIC: -623,52 |
BIC: -606,66 |
Type: D-vine |
logLik: 321,27 |
AIC: -636,53 |
BIC: -619,67 |
|
Tree |
Edge |
Family |
Parameter |
Tree |
Edge |
Family |
Parameter |
|
1 |
DJSG,DJJP |
Gumbel |
1,36 (0,03) |
1 |
DJSG,DJJP |
Gumbel |
1,37 (0,03) |
|
DJJP,DJTA |
Gumbel |
1,56 (0,03) |
DJJP,DJTA |
Gumbel |
1,54 (0,03) | ||
|
2 |
DJSG,DJTA| DJJP |
Gumbel |
1,22 (0,02) |
2 |
DJSG,DJTA| DJJP |
Gumbel |
1,20 (0,02) |
|
Type: D-vine |
logLik: 403,3 |
AIC: -800,6 |
BIC: -783,74 |
Type: D-vine |
logLik: 391,78 |
AIC: -777,56 |
BIC: -760,7 |
|
Tree |
Edge |
Family |
Parameter |
Tree |
Edge |
Family |
Parameter |
|
1 |
DJSG,DJJP |
Frank |
2,46 (0,17) |
1 |
DJSG,DJJP |
Frank |
2,53 (0,16) |
|
DJJP,DJTA |
Frank |
3,64 (0,17) |
DJJP,DJTA |
Frank |
3,53 (0,16) | ||
|
2 |
DJSG,DJTA| DJJP |
Frank |
1,96 (0,16) |
2 |
DJSG,DJTA| DJJP |
Frank |
1,82 (0,16) |
|
Type: D-vine |
logLik: 391,62 |
AIC: -777,23 |
BIC: -760,37 |
Type: D-vine |
logLik: 382,3 |
AIC: -758,6 |
BIC: -741,74 |
Berdasarkan struktur dekomposisi D-vine copula pada Gambar 8, selanjutnya akan dilakukan estimasi parameter D-vine copula menggunakan maximum likelihood estimator (MLE). Hasil estimasi parameter D-vine copula disajikan pada Tabel 9.
Kolom tree dan edge pada Tabel 9 merupakan susunan dekomposisi D-vine copula berdasarkan Gambar 8. Edge menunjukkan copula bivariat yang memodelkan kebergantungan penyusun dari D-vine copula. Tree dua menjelaskan copula bivariat bersyarat yang memodelkan copula bivariat DJSG, DJJP dengan DJTA, DJJP.
Nilai log likelihood pada setiap family estimasi parameter D-vine copula menjadi penentu jenis family copula terbaik dalam memodelkan kebergantungan antarsaham DJJP, DJSG, DJTA yang selanjutnya diterapkan pada kriteria AIC dan BIC. Nilai AIC dan BIC terkecil dapat dilihat pada family Gumbel copula dengan nilai AIC = -800,6, BIC = -783,74 pada residual AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] dan AIC = -777,56, BIC = -760,7 pada residual AR(1)-GJR-t(1,1)-GPD Uniform [0,1]. Nilai karakteristik
Gumbel copula baik digunakan untuk mengetahui kebergantungan antaraset finansial penyusun portofolio. Karakteristik Gumbel copula yang berfokus pada uppertail copula mengindikasikan kebergantungan copula pada risiko keuntungan. Semakin besar parameter pada Gumbel copula maka semakin besar kebergantungan risiko keuntungan pada aset finansial. Parameter Gumbel copula yang telah diestimasi selanjutnya digunakan sebagai struktur kebergantungan pada portofolio indeks saham DJJP, DJSG, dan DJTA untuk mengestimasi risiko menggunakan CVaR.
Setelah mengakomodasi sifat dan karakteristik pada data return indeks saham DJJP, DJSG, dan DJTA menggunakan AR(1)-GARCH-t(1,1)-GPD Uniform [0,1] dan AR(1)-GJR-t(1,1)-GPD Uniform [0,1], simulasi perlu data return perlu dilakukan dengan pendekatan D-vine copula. Hal ini dilakukan untuk memperoleh data return DJJP, DJSG, dan DJTA dengan struktur D-vine copula.
Tabel 10. Estimasi Value at Risk dan Conditional Value at Risk pada Simulasi Return AR(1)- GARCH-t(1,1) dan AR(1)-GJR-t(1,1)
|
Tingkat Kepercayaan (1-O |
Family Copula |
VaR |
CVaR | ||
|
Sim Return AR(1)-GARCH-t(1,1)-GPD |
Sim Return AR(1)-GJR-t(1,1)-GPD |
Sim Return AR(1)-GARCH-t(1,1)-GPD |
Sim Return AR(1)-GJR-t(1,1)-GPD | ||
|
90% |
Gumbel |
0,01098082 |
0,009845107 |
0,01729718 |
0,01546754 |
|
95% |
Gumbel |
0,01429846 |
0,01341453 |
0,02209712 |
0,01956534 |
|
99% |
Gumbel |
0,02502447 |
0,02208237 |
0,03780831 |
0,03052013 |
Tabel 11. Estimasi Kerugian Maksimum Satu Hari ke Depan Menggunakan CVaR
|
Tingkat Kepercayaan (I -O |
Family Copula |
CVaR (%) | |
|
Sim Return AR(1)-GARCH-t(1,1)-GPD |
Sim Return AR(1)-GJR-t(1,1)-GPD | ||
|
90% |
Gumbel |
$ 1729 |
$ 1546 |
|
95% |
Gumbel |
$ 2221 |
$ 1956 |
|
99% |
Gumbel |
$ 3780 |
$ 3052 |
Tabel 12. Uji Kupiec pada Estimasi Risiko Value at Risk
|
1 - a |
Family Copula |
CVaR (%) | |||||
|
Sim Return AR(1)-GARCH-t(1,1)-GPD |
Exceeded value |
p-value a = 0,05 |
Sim Return AR(1)-GJR-t(1,1)-GPD |
Exceeded value |
p-value a = 0,05 | ||
|
90% |
Gumbel |
0,01729718 |
13 |
0,9999742 |
0,01546754 |
13 |
0,999963 |
|
95% |
Gumbel |
0,02209712 |
6 |
1 |
0,01956534 |
7 |
1 |
|
99% |
Gumbel |
0,03780831 |
2 |
1 |
0,03052013 |
3 |
1 |
Langkah pertama yang dilakukan ialah membangkitkan bilangan acak sebanyak 2037 data berdasarkan estimasi parameter D-vine copula pada Tabel 9. Bilangan acak yang berjumlah 2037 tersebut kemudian ditransformasikan ke bentuk invers model AR(1)-GARCH-t(1,1)-GPD dan AR(1)-GJR-t(1,1)-GPD sehingga diperoleh bilangan acak IID zit dengan mean nol dan varians satu. Galat baku (εit) pada simulasi return berdasarkan Persamaan (2) diperoleh dari zit dikalikan dengan standar deviasi σit dari model AR(1)-GARCH-t(1,1) dan AR(1)-GJR-t(1,1). Setelah mendapat nilai galat baku (εit), langkah selanjutnya dapat dilanjutkan untuk simulasi return berdasarkan Persamaan (3) untuk mendapatkan nilai simulasi return yang stasioner.
Berdasarkan Tabel 10 terlihat setiap CVaR bernilai lebih besar dari nilai VaR. Hal ini menandakan setiap estimasi risiko pada CVaR
memiliki tingkat kerugian yang lebih dari VaR. Hal ini bersifat baik dalam berinvestasi karena model CVaR dikatakan memiliki kinerja yang lebih baik dalam mengestimasi risiko. Nilai CVaR pada simulasi return AR(1)-GJR-t(1,1) berturut-turut pada tingkat kepercayaan sebesar 90%, 95%, dan 99% adalah 0,01546754, 0,01956534, 0,03052013. Hal ini mengartikan jika seorang investor menginvestasikan uangnya sebesar $ 100.000 pada indeks saham DJJP, DJSG, dan DJTA menggunakan model simulasi return AR(1)-GJR-t(1,1) dengan pendekatan D-vine copula maka kerugian maksimum yang akan timbul pada satu hari perdagangan ke depan ialah 1,54% pada tingkat kepercayaan 90%, 1,95% pada tingkat kepercayaan 95%, dan 3,05% pada tingkat kepercayaan 99% dari total nilai investasi. Berikut Tabel 11 dapat menggambarkan kerugian maksimum menggunakan CVaR.
Tabel 12 menjelaskan Uji Kupiec pada estimasi risiko CVaR 99%, 95%, dan 90% dengan nilai exceeded value berturut-turut 2, 6, 13 untuk simulasi Return AR(1)-GARCH-t(1,1)-GPD dan 3, 7, 13 untuk simulasi Return AR(1)-GJR-t(1,1)-GPD. Semakin banyak nilai yang melewati ambang batas (exceeded value) pada uji Kupiec mengindikasikan buruknya model estimasi risiko. Sebaliknya, jika exceeded value pada uji Kupiec sedikit maka estimasi risiko dapat dikatakan baik. Hasil dari uji Kupiec juga dapat dilihat dari nilai p — value untuk seluruh uji Kupiec bernilai kurang dari taraf signifikan a = 0,05. Hal ini mengartikan bahwa CVaR baik digunakan dalam mengestimasi risiko.
VaR dan CVaR dapat mengestimasi risiko pada portofolio saham DJJP, DJSG, dan DJTA. Estimasi risiko menggunakan CVaR memiliki nilai yang lebih baik daripada VaR dengan nilai berturut-turut pada tingkat kepercayaan sebesar 90% sebesar 0.01546754, 95% sebesar 0.01956534, dan 99% sebesar 0.03052013 dengan periode perdagangan satu hari ke depan.
Uji Kupiec untuk CVaR digunakan pada proses backtesting guna mengetahui kelayakan estimasi risiko. Exceeded value Uji Kupiec pada CVaR 99% bernilai 2, CVaR 95% bernilai 6, dan CVaR 90% bernilai 13 untuk simulasi Return AR(1)-GARCH-t(1,1)-GPD dan CVaR 99% bernilai 3, CVaR 95% bernilai 7, dan CVaR 90% bernilai 13 untuk simulasi Return AR(1)-GJR-t(1,1)-GPD. Uji Kupiec menjelaskan estimasi nilai risiko CVaR berjalan baik dengan nilai seluruh model berada di atas taraf signifikan a = 0,05 sehingga memberikan simpulan estimasi risiko dinilai layak digunakan. Penelitian ini diharapkan dapat menjadi referensi dalam mengestimasi portofolio aset saham.
Penelitian struktur kebergantungan Penelitian struktur kebergantungan dengan D-vine copula yang dilakukan pada penelitian ini hanya pada kasus triviat dengan 3 data saham.
Pada penelitian selanjutnya diharapkan memiliki contoh kasus pada data saham yang lebih dari 3 data saham. Pemodelan risiko pada penelitian ini hanya menggunakan CVaR dan VaR. Penelitian selanjutnya diharapkan dapat memperluas estimasi risiko menggunakan model lain contohnya LVaR dan TVaR.
DAFTAR PUSTAKA
Aas, K., Czado, C., Frigessi, A., & Bakken, H.
-
(2009) . Pair-copula constructions of multiple dependence. Insurance:
Mathematics and economics, 44(2), 182
198.
Alexander, S., Coleman, T. F., & Li, Y. (2006). Minimizing CVaR and VaR for a portfolio of derivatives. Journal of Banking & Finance, 30(2), 583-605.
Brockwell, P. J., Davis, R. A., & Calder, M. V. (2002). Introduction to time series and forecasting (Vol. 2, pp. 3118-3121). New York: springer.
Brooks, C. (2008). RATS Handbook to accompany introductory econometrics for finance. 3rd ed. Cambridge Books.
Cherubini, U., Luciano, E., & Vecchiato, W. (2004). Copula methods in finance. 2nd ed. John Wiley & Sons.
Danielsson, J. (2011). Financial risk forecasting: The theory and practice of forecasting market risk with implementation in R and Matlab (Vol. 588). John Wiley & Sons.
Duan, J., Gauthier, G., Simonato, J., &
Sasseville, C. (2006). Approximating the GJR-GARCH and EGARCH option pricing models analytically. Journal of
Computational Finance, 9(3), 41.
Franke, J., (2011). Statistics of Finansial
Markets: An Introduction. Third Edition. London: Springer-VerlagBerlin Heidenberg.
Hastaryta, R., & Effendie, A. R. (2006).
Estimasi Value-At-Risk dengan Pendekatan Extreme Value Theory-Generalized Pareto Distribution (Studi Kasus IHSG 1997 2004). BIMIPA, 16(2), 1-6.
Kichen, N. N. (2017). Estimasi Value at Risk (VaR)Portofolio Multivariat Menggunakan Metode GARCH Student t-EVT-Vine
Copula (Doctoral dissertation, Universitas Gadjah Mada).
Klugman, S. A., Panjer, H. H., & E.Willmot, G. (2008). Loss Models from Data to Decisions. Third Edition. Canada: John Wiley & Sons, Inc.
Kurowicka, D., & Cooke, R. M. (2007).
Sampling algorithms for generating joint uniform distributions using the vine-copula method. Computational statistics &
data analysis, 51(6), 2889-2906.
McNeil, A. J. (2005). Estimating value-at risk: a point process approach. Quantitative
Finance, 5(2), 227-234.
Pintari, H. O., & Subekti, R. (2018). Penerapan Metode GARCH-Vine Copula untuk Estimasi Value at Risk (VaR) pada Portofolio. Jurnal Fourier, 7(2), 63-77.
Sudina, N. W. U. Y. A., Dharmawan, K., & Sumarjaya, I. W (2019). Estimasi Nilai Conditional Value at Risk (CVaR) Portofolio Menggunakan Metode Evt GJR-Vine Copula. E-Jurnal Matematika 8(1), pp.15-26
Sugiyarto. (2019). Jurnal Matematika (Vol. 6) Yogyakarta: Universitas Ahmad Dahlan.
Sumarjaya, I. W. (2013). Memodelkan Ketergantungan dengan Kopula. Jurnal Matematika, 3(1), 34-42.
Tsay, R. S. (2013). Multivariate time series analysis: with R and finansial applications. 3rd ed. John Wiley & Sons.
Tsay, R. S. (2014). An introduction to analysis of financial data with R. 3rd ed. John Wiley & Sons.
Zivot, E. (2009). Practical issues in the analysis of univariate GARCH models. In Handbook of financial time series (pp. 113-155). Springer, Berlin, Heidelberg.
Zuhara, U., Akbar, M. S., & Haryono, H.
-
(2012) . Penggunaan Metode VaR (Value at Risk) dalam Analisis Risiko Investasi Saham dengan Pendekatan Generalized Pareto Distribution (GPD). Jurnal Sains dan Seni ITS, 1(1), D56-D61.
139
Discussion and feedback