Prediksi Partisipasi Pemilih dalam Pemilu Presiden 2014 dengan Metode Support Vector Machine
on
JURNAL ILMIAH MERPATI VOL. 7, NO. 3 DESEMBER 2019
p-ISSN: 2252-3006
e-ISSN: 2685-2411
Prediksi Partisipasi Pemilih dalam Pemilu Presiden 2014 dengan Metode Support Vector Machine
I Putu Arya Putra Wibawa, I Ketut Adi Purnawan, Desy Purnami Singgih Putri, Ni Kadek Dwi Rusjayanthi
Program Studi Teknologi Informasi, Fakultas Teknik, Universitas Udayana Bukit Jimbaran, Bali,
Indonesia, telp. (0361) 701806
e-mail: aryaputrawibawa@gmail.com, adipurnawan@unud.ac.id, desysinggihputri@gmail.com, dwi.rusjayanthi@unud.ac.id
Abstrak
Pemilihan umum merupakan proses dalam memilih seseorang yang mewakili rakyat untuk menduduki sebuah kursi pemerintahan. Pemilu di Indonesia dilaksanakan sejak Tahun 1955 silam dan pemilihan umum untuk memilih anggota badan eksekutif yang melibatkan suluruh masyarakat umum diselenggarakan sejak Tahun 2004. Jumlah partisipasi pemilih yang semakin tinggi dapat menjadi ukuran keberhasilan diadakannya suatu pemilu. Prediksi partisipasi pemilih dilakukan serangkaian proses untuk menemukan pola dan pengetahuan dari sekumpulan data menggunakan ilmu data mining. Prediksi pada penelitian yang dilakukan bertujuan untuk mengetahui partisipasi masyarakat di Kecamatan Denpasar Barat. Metode support vector machine digunakan dalam sistem prediksi partisipasi pemilih dalam pemilu yang menggunakan dataset dari Daftar Pemilih Tetap Pemilu Tahun 2014 di Kecamatan Denpasar Barat Provinsi Bali. Pengujian tingkat akurasi dari metode Support Vector Machine menggunakan parameter input C dan fungsi kernel. Hasil akurasi tertinggi yang didapat dalam memprediksi partisipasi pemilih sebesar 97.50% menggunakan fungsi kernel RBF pada nilai parameter C sebanyak 5.
Kata kunci: Support Vector Machine, Data Mining, Prediksi Partisipasi Pemilih
Abstract
Election is the process of choosing someone who represents the people to occupy a seat of government. Elections in Indonesia have been held since 1955 and elections to elect members of the executive board involving all general public have been held since 2004. Increasingly high turnout can be a measure of the success of an election. Prediction of voter participation is carried out a series of processes to find patterns and knowledge from a set of data using data mining science. Predictions in the research conducted aimed to determine community participation in the District of West Denpasar. The support vector machine method is used in a prediction system for voter participation in elections using a dataset from the 2014 Permanent Voter List in the Denpasar Barat District, Bali Province. Testing the accuracy of the Support Vector Machine method using C input parameters and kernel functions. The highest accuracy results obtained in predicting voter participation of 97.50% using the RBF kernel function on the C parameter value of 5.
Keywords: Support Vector Machine, Data Mining, Voter Participation Prediction
Perkembangan ilmu pengetahuan dapat mempengaruhi hampir seluruh kegiatan manusia menjadi lebih praktis ditandai dengan munculnya teknologi [1]. Teknologi saat ini perkembangannya sangat pesat dan semua orang membutuhkan media untuk berhubungan dengan orang-orang di sekitar [2]. Perkembangan teknologi memberikan rasa nyaman dan akses tanpa batas kepada siapa pun dengan menggunakan teknologi informasi [3]. Teknologi informasi dapat dimanfaatkan diberbagai bidang diantaranya bidang politik. Politik sering kali berkaitan dengan pemimpin negara yang memimpin suatu negara. Indonesia merupakan negara yang menganut asas demokrasi, sehingga dalam memilih pimpinan negara melalui
pemilu. Pemilu merupakan sebuah proses untuk mewujudkan negara yang berdemokrasi melalui pemungutan suara dari rakyat secara demokrasi untuk memilih para pemimpin negara. Indonesia melaksanakan pemilu pertama kali setelah merdeka pada Tahun 1955, dan pada pemilu Tahun 2014 adalah pemilu ke-11 [4]. Pemilihan secara umum untuk memilih anggota legislatif dilaksanakan mulai tahun 2004.
Pemilu dilakukan setiap 5 tahun sekali yang diikuti oleh seluruh Warga Negara Indonesia sebagai bentuk proses demokrasi [5]. Keikutsertaan warga negara dibutuhkan untuk menggunakan hak suaranya dalam memilih pemimpin negara pada pemilu. Jumlah Partisipasi pemilih yang semakin meningkat dalam pemilu dapat menjadi tolak ukur keberhasilan diadakannya pemilu serta menjadi cerminan proses demokrasi yang telah dilaksanakan. Prediksi partisipasi pemilih dapat ditentukan dengan beberapa tahapan proses untuk mendapatkan pola atau pengetahuan dari sekumpulan ide atau data menggunakan ilmu data mining [6]. Algoritma-algoritma yang dapat digunakan dalam klasifikasi data mining antara lain neural network, decision tree, naïve bayes, dan support vector machine [6]. Penelitian yang menggunakan metode SVM untuk pemilihan beasiswa untuk siswa SMK menjelaskan metode SVM dapat digunakan dalam kasus tersebut dengan tingkat keakurasian mencapai 85,82% [7]. Metode SVM digunakan untuk memprediksi dalam penelitian untuk menghitung ketepatan waktu kelulusan mahasiswa dengan tingkat akurasi prediksi 80,55% [8]. SVM menjadi algoritma yang memiliki akurasi yang cukup tinggi dalam memprediksi suatu permasalahan berdasarkan beberapa penelitian yang telah berhasil menerapkannya.
Penulis memilih metode SVM sebagai metode yang digunakan untuk memprediksi partisipasi pemilih dalam pemilu. Perbedaan dari penelitian sebelumnya dengan penelitian yang dilakukan adalah data yang digunakan yaitu pada daerah Kecamatan Denpasar Barat dan parameter uji. Prediksi partisipasi pemilih dalam pemilu dilakukan dengan metode support vector machine sesuai dengan permasalahan yang dihadapi sebelumnya. Penelitian prediksi partisipasi pemilih dalam pemilu memiliki dua label yaitu berpartisipasi dan tidak partisipasi.
Pengumpula data pada penelitian ini menggunakan metodologi observasi langsung dan kuesioner yang disebar pada tempat yang menjadi daerah sempel data. Pengumpulan data dari narasumber dilakukan secara acak pada setiap kelurahan dan desa di Kecamatan Denpasar Barat. Data sekunder dari penelitian ini didapat dari jurnal ilmiah dan buku yang telah terbit. Penyebaran kuesioner untuk mendapat data DPT yang berusia paling rendah 17 tahun per tahun 2018 sampai usia diatas 55 tahun.
Metode yang digunakan dalam membangun sistem prediksi partisipasi pemilih dalam pemilu menggunakan metode SVM. Tahapan yang dilakukan pada metode SVM adalah proses klasifikasi pada data DPT yang ada pada kecamatan Denpasar Barat, menjadi dua buah kelas target sebagai output prediksi yaitu kelas berpartisipasi dan tidak berpartisipasi. SVM digunakan untuk mencari bidang pembatas hyperplane terbaik sebagai pemisah dua pettern yang berbeda.
Sistem prediksi partisipasi pemilih dalam pemilu dibuat berdasarkan konsep klasifikasi pada data mining. Proses yang terdapat terbagi menjadi proses pelatihan data, pengujian data serta prediksi. Data yang digunakan dalam proses pelatihan dan pengujian sebelumnya melewati preprocessing data untuk menghindari noise yang dapat menggangu saat proses klasifikasi berlangsung. Penelitian ini menggunakan data daftar pemilih tetap (DPT) dari daerah Kecamatan Denpasar Barat. Data karakteristik DPT yang dibagi menjadi 7 kategori digunakan dalam penelitian ini. Kategori usia, jenis kelamin, pendidikan, status pernikahan, pekerjaan, tempat lahir dan tingkat motivasi. Data DPT berjumlah 215 data digunakan untuk proses latih data dan proses uji, dengan membagi data menjadi 155 data untuk proses latih dan 64 data untuk proses uji. Gambaran umum penelitian prediksi partisipasi pemilih dalam pemilu dengan metode SVM pada Gambar 1.
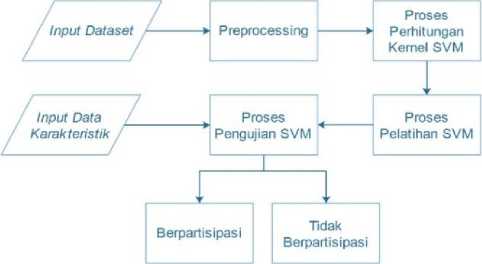
Gambar 1. Gambaran Umum Sistem
Alur proses yang dijalankan saat melakukan prediksi partisipasi pemilih pada pemilu diawali dengan memasukkan data input sebagai data latih dan uji. Data yang telah dimasukkan selanjutnya diubah menjadi bentuk biner yang bernilai 0/1 yang disebut tahap preprocessing data. Data dalam bentuk biner digunakan sebagai data latih yang berjumlah 151 data dalam proses pembelajaran SVM. Hasil dari pelatihan SVM disimpan sebagai model pengetahuan baru yang digunakan dalam proses prediksi. Proses selanjutnya dilakukan pengujian untuk melihat performa dari metode SVM. Pengujian menggunakan 64 data uji yang telah dalam bentuk biner. Proses prediksi partisipasi dilakukan setelah melewati tahap pengujian dan pelatihan data. Data yang digunakan dalam proses prediksi adalah data karakteristik DPT yang terdiri dari kategori usia, jenis kelamin, pendidikan, tempat lahir, status pernikahan, pekerjaan, dan tingkat motivasi yang ingin diprediksi. Proses prediksi dilakukan untuk melihat partisipasi dari DPT yang ikut serta dalam pemilu. Output dari prediksi yang telah dilakukan berupa informasi keterangan apakah karakteristik DPT yang diprediksi, berpartisipasi atau tidak berpartisipasi.
-
2.2 Preprocessing Data
Preprocessing adalah proses mempersiapkan data mentah untuk digunakan pada proses transformasi data ke bentuk format data yang diperlukan oleh pemakai [9]. Dataset yang digunakan adalah data yang didapatkan langsung dari setiap DPT daerah Kecamatan Denpasar Barat. Prepocessing data memiliki beberapa proses diantaranya perubahan data tekstual menjadi bentuk biner. Preprocessing data yang dilakukan terhadap 7 kategori untuk merubah bentuk nilai setiap data menjadi bentuk biner. Data yang sesuai dengan masukan data DPT diberi nilai 1 dan data yang tidak sesuai diberi nilai 0. Setiap kategori memiliki pembagian atribut data seperti data usia dibagi menjadi empat atribut yaitu 17-25 tahun, 26-43 tahun, 44-55 tahun dan usia diatas 55 tahun. Kategori jenis kelamin memiliki dua atribut yaitu laki-laki dan perempuan. Kategori status pernikahan memiliki tiga atribut yaitu belum menikah, sudah menikah dan pernah menikah. Kategori pekerjaan memiliki enam atribut berbeda yaitu siswa atau mahasiswa, ibu rumah tangga (IRT), pegawai negeri, pegawai swasta, wiraswasta, dan tidak bekerja. Kategori tingkat pendidikan memiliki 5 atribut yaitu SD, SMP, SMA, Diploma dan Sarjana. Kategori motivasi memiliki empat atribut yaitu tingkat motivasi kurang baik (<58), Cukup (58-68), Baik (69-80) dan sangat baik (81-100). Kategori tempat lahir yang dibagi menjadi dua atribut yaitu kota Denpasar atau Luar Denpasar. Data sebelum dan sesudah terkonversi dalam bentuk biner dapat dilihat pada Tabel 1 dan Tabel 2.
Tabel 1. Contoh Data DPT sebelum preprocessing
|
No |
Usia |
Jenis Kelamin |
Pendidikan |
Ket. |
|
1 |
51 Tahun |
Laki-laki |
Sekolah |
Tidak Berpartisipasi |
|
2 |
18 Tahun |
Laki-laki |
Sekolah |
Berpartisipasi |
|
3 |
22 Tahun |
Perempuan |
Tidak Sekolah |
Tidak Berpartisipasi |
|
4 |
44 Tahun |
Perempuan |
Sekolah |
Berpartisipasi |
|
5 |
55 Tahun |
Laki-laki |
Tidak Sekolah |
Berpartisipasi |
Tabel 2. Contoh Data Setelah Preprocessing
|
No |
Usia |
Jenis Kelamin |
Pendidikan |
Ket. | ||
|
17-35 Tahun |
36-55 Tahun |
Tidak Sekolah |
Sekolah | |||
|
1 |
0 |
1 |
1 |
0 |
1 |
-1 |
|
2 |
1 |
0 |
1 |
0 |
1 |
1 |
|
3 |
1 |
0 |
0 |
1 |
0 |
-1 |
|
4 |
0 |
1 |
0 |
0 |
1 |
1 |
|
5 |
0 |
1 |
1 |
1 |
0 |
1 |
Klasifikasi adalah proses pengelompokan suatu ide, data atau kelompok baru ke dalam sebuah kelompok yang memiliki kesamaan dengan salah satu karakteristik kelas [10]. Proses klasifikasi meliputi proses pelatihan dan pengujian data. Dataset untuk proses latih dan uji menggunakan data dari DPT Kecamatan Denpasar Barat yang dilanjutkan ke tahap prediksi. Data dari DPT yang diprediksi diolah dan dibandingkan dengan hasil pelatihan yang telah tersimpan. Proses pelatihan bertujuan untuk membuat sebuah model machine learning yang dapat memprediksi pemilih pada pemilu. Pengujian dilakukan untuk melihat performa dari model SVM yang telah dibuat. Output dari hasil klasifikasi dalam sistem prediksi partisipasi dalam pemilu yaitu label berpartisipasi atau tidak berpartisipasi.
Kajian pustaka adalah sekumpulan teori dasar yang digunakan dalam suatu penelitian. Kajian pustaka digunakan sebagai kerangka teoritis atau rasional pada suatu penelitian. Kajian pustaka dijadikan landasan dalam implementasi metode SVM dalam Prediksi Partisipasi Pemilih dalam Pemilu Presiden di Tahun 2014.
Pemilu atau pemilihan umum memiliki arti sebagai sebuah proses untuk menentukan orang-orang yang menduduki kursi Dewan Perwakilan Rakyat, Dewan Perwakilan Rakyat Daerah, Presiden dan Wakil Presiden serta Dewan Perwakilan Daerah [11]. Pemilu diiadakan sebagai lambang sebuah demokrasi yang ada pada suatu negara yang para pemimpinnya dipilih dari suara rakyatnya. Pemilu menurut Ali Moetopo mengatakan bahwa pemilu merupakan sebuah sarana yang digunakan oleh rakyat untuk menjalankan kedaulatannya yang sesuai dengan UUD 1945. Pemilu sesungguhnya sebuah lembaga domokrasi yang digunakan untuk memilih wakil rakyat yang sama-sama bertugas dengan pemerintah menjalankan negara.
Peraturan KPU No 26 Tahun 2013 Pasal 6 menyatakan ada 4 jenis pemilih pada pemilu. Jenis pemilih yang dimaksud adalah Daftar Pemilih Tetap (DPT), Daftar Pemilih Khusus (DPK), Daftar Pemilih Tetap Tambahan (DPTb), Daftar Pemilih Khusus Tambahan (DPKTb). DPT merupakan Warga Negara Indonesia yang telah memenuhi syarat sebagai pemilih yang memiliki hak dalam memberikan suara di TPS dalam Pemilu [4]. DPT tidak berpartisipasi merupakan DPT yang terdaftar yang tidak menggunakan hak pilihnya saat pemilu berlansung.
Data mining adalah suatu metode dalam mengolah data yang digunakan untuk mendapat sebuah pola atau pengetahuan baru yang dapat digunakan untuk mengambil keputusan [12]. Data mining secara analogi dapat dinamakan dengan “knowledge minings from data” atau penambangan pengetahuan dari suatu data. Mining merupakan sebuah kata yang menggolongkan proses menemukan kumpulan kecil dari bongkahan berguna dari raw material seperti yang terlihat pada ilustrasi Gambar 2.
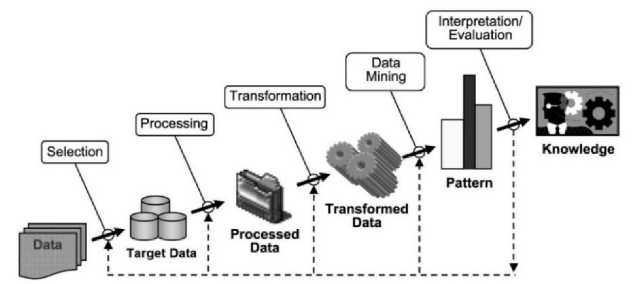
Gambar 2 Tahapan Data mining
Kenneth Collier (1998) kemudian mendeskripsikan lima tahapan data mining atau knowledge discovery antara lain seleksi data, data preprocessing, transformasi data, data mining, interpretasi dan evaluasi.
-
3.3 Support Vector Machine
Support Vector Machine atau SVM diperkenalkan oleh Oser, Guyon dan Vapnik Tahun 1992. SVM merupakan metode klasifikasi yang bermodel supervised learning [13]. SVM dapat digunakan untuk mengenali pola berdasarkan teori statistik [14]. Problem yang sering terjadi dalam dunia nyata adalah problem yang bersifat non-linear, dan tidak selalu bersifat linear classifier. Problem non-linear dapat diatasi dengan trik kernel yang memuat ruang dimensi rendah ke dimensi yang lebih tinggi. SVM merupakan sebuah usaha untuk menemukan Hyperplane terbaik dalam memisahkan dua kelas pada input space [15]. Pattern merupakan dua kelas yang dapat dinotasikan dengan +1 dan -1. Garis pemisah atau hyperplane didapat dengan mengukur margin hyperplane serta mencari titik maksimalnya. Margin adalah jarak antara hyperplane dengan data terdekat dari masing-masing kelas [15]. Support Vector ditentukan dari jarak data terdekat dengan Hyperlane. Hyperplane adalah suatu fungsi yang bersifat linier yang dapat memecahkan masalah tertentu [16]. SVM dapat menjamin kemampuan generalisasi yang tinggi untuk data yang akan datang [13]. Proses pencarian hyperplane biasanya muncul permasalahan baru yang sulit dipecahkan disebut Quadratic Programming.
Hyperplane yang digunakan dalam proses pengklasifikasian data training menjadi dua buah kelas. Klasifikasi data menjadi dua kelas diGambarkan dengan perumpamaan lingkaran dan persegi sebagai dua kelas yang berbeda seperti Gambar 3.
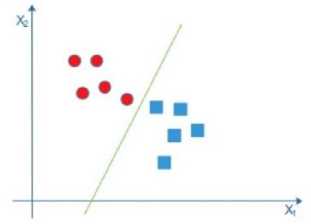
Gambar 3 Hyperplane klasifikasi data menjadi dua kelas
Bidang pembatas yang berada diantara kelas lingkaran dan kotak merupakan garis pemisah untuk dua kelas berbeda. Batasan yang ada dari data kedua kelas dicari margin pemisah hyperplane-nya agar memberikan margin yang maksimal untuk generalisasi yang lebih baik pada metode klasifikasi. Gambar 4 menampilkan cara mencari hyperplane pemisah antar kelas.
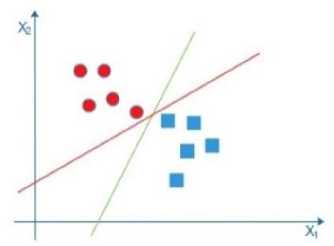
Gambar 4 Mencari Hyperplane Pemisah Antar Kelas
Margin yang maksimal antara data dengan bidang pembatas dapat menghasilkan hypeplane yang baik. Pattern yang memiliki jarak yang dekat dengan bidang pembatas diukur untuk mendapatkan margin yang maksimal. Pattern yang memiliki kedekatan tersebut yang disebut sebagai support vector dapat dilihat seperti Gambar 5.

Gambar 5 Jarak Terdekat Dengan Masing-masing Kelas
Margin Z2 yang disebut sebagai support vector merupakan hasil dari metode SVM. SVM memiliki karakteristik antara lain perlunya pelatihan data untuk menyimpan hasil dari support vector yang digunakan lagi pada proses pengujian. Memisahkan Pemisahan data yang terdistribusi dapa dilakukan SVM yang bersifat linier atau non-linear. Permasalahan yang ada pada dunia nyata cenderung jarang yang bersifat linear, tetapi bersifat non-linear. SVM digunakan dalam mengatasi problem non-linear menggunakan fungsi kernel. Memilih jenis kernel dan parameter yang dibutuhkan harus tepat sesuai dengan studi kasus yang digunakan agar mendapat kinerja SVM yang lebih baik.
SVM pada proses pembelajaran dalam menemukan titik-titik support vector hanya bergantung pada dot product dari data yang sudah ditransformasikan pada ruang baru yang berdimensi lebih tinggi. Fungsi kernel harus memenuhi teorama Mercer yang menyatakan bahwa matrik kernel bersifat positive semi-definite [17]. Fungsi kernel yang umum digunakan dalam aplikasi dapat dilihat pada Persamaan 1 sampai dengan 4.
-
1. Kernel Linier
-
2. Polynomial
-
3. Radial Basis Function (RBF)
-
4. Sigmoid
K Cr, y) = tanh(σCr.y) + c)(4)
Bagian hasil dan pembahasan membahas capaian dari penelitian. Hasil dibagi menjadi hasil perfoma akurasi dan pembahasan sistem. Hasil dan pembahasan disajikan dalam bentuk deskripsi, grafik maupun Gambar.
-
4.1 Antarmuka Sistem

Gambar 6 Tampilan Beranda Aplikasi
Gambar 6 merupakan tampilan antarmuka Sistem Prediksi Partisipasi Pemilih dalam Pemilu dengan Metode SVM. Antarmuka sistem dirancang berbasis desktop dilengkapi dengan empat macam fitur dalam memprediksi partisipasi pemilih. Fitur yang terdapat pada antarmuka sistem adalah fitur pelatihan, fitur prediksi, fitur input data DPT dan fitur Daftar DPT.
4.2 Fitur Pelatihan

Gambar 7 Form Pelatihan Data
Fitur pelatihan digunakan dalam proses pelatihan data training dan testing. Form pelatihan menampilkan data latih yang digunakan, lalu menentukan nilai dari parameter C dan kernel yang digunakan. Proses pelatihan dijalankan saat menekan tombol latih. Proses uji dijalankan pada form Pelatihan data. Data yang digunakan untuk proses uji menggunakan data DPT yang telah ditentukan sebagai Data uji. Prose pengujian dilakukan dengan menekan tombol uji pada form Pelatihan Data. Hasil yang dihasilkan berupa grafik partisipasi setiap kategori dari Data DPT. Form Pelatihan Data memuat tingkat partisipasi dari seluruh Data DPT yang digunakan dalam sistem dan terdapat persentase akurasi prediksi yang ditampilkan pada hasil dari proses uji.
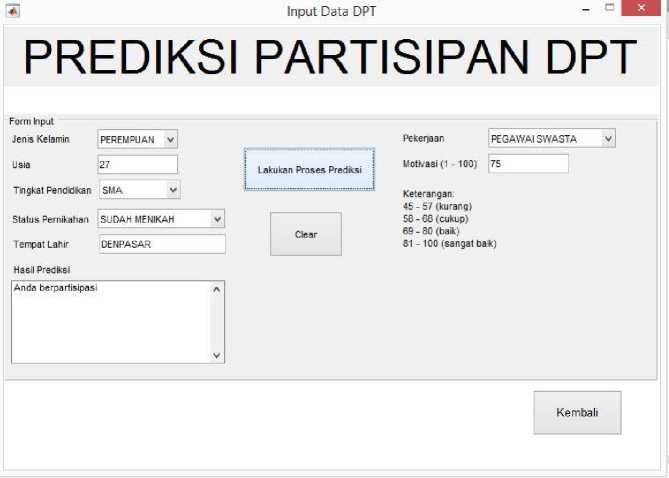
Input data karakteristik DPT untuk digunakan pada proses prediksi. Data masukan dalam proses prediksi partisipasi menggunakan data baru yang berbeda. Tahap prediksi pada sistem menggunakan data akhir hasil proses pelatihan sebelumnya. Hasil dari proses prediksi yang ditampilkan adalah prediksi partisipasi dan tidak berpartisipasi. Tampilan input data karakteristik yang diprediksi dapat dilihat pada Gambar 8.
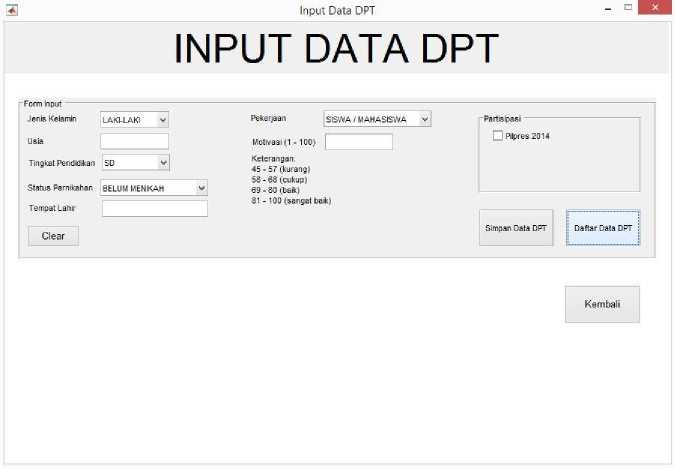
Gambar 9 Form Input Data DPT
Gambar 9 merupakan form input data DPT yang digunakan untuk memasukkan data DPT. Data DPT yang dimasukan adalah data jenis kelamin yang memiliki dua pilihan yaitu laki-laki dan perempuan. Data usia dapat dimasukan secara manual sesuai dengan usia dari setiap DPT, serta pada kolom tempat lahir dan motivasi juga dapat diisi manual oleh pengguna. Pengguna dapat memilih salah satu pilihan yang tersedia pada kolom kategori status pernikahan, tingkat pendidikan, dan pekerjaan untuk diisi sesuai dengan data yang diprediksi.
Pengguna dapat memberikan centang pada Pilpres Tahun 2014 jika data DPT yang dimasukkan berpatisipasi atau dibiarkan kosong jika tidak berpartisipasi. Pengguna yang telah selesai memasukkan semua data pada setiap kolom dapat menyimpan data tersebut dengan menekan tombol simpan data DPT. Data tersimpan secara otomatis pada database sistem. Data yang sudah disimpan dapat dilihat pada Daftar Data DPT. Pengguna dapat mengakses Daftar Data DPT dengan mengklik tombol Daftar Data DPT dan langsung menuju pada tampilan Daftar Data DPT.
Daftar Data DPT
Daftar Data DPT
DAFTAR DATA DPT
51 SARJANA
22 SARJANA
25 DIPLOMA
5? SARJANA
klungkung p. swas≡a
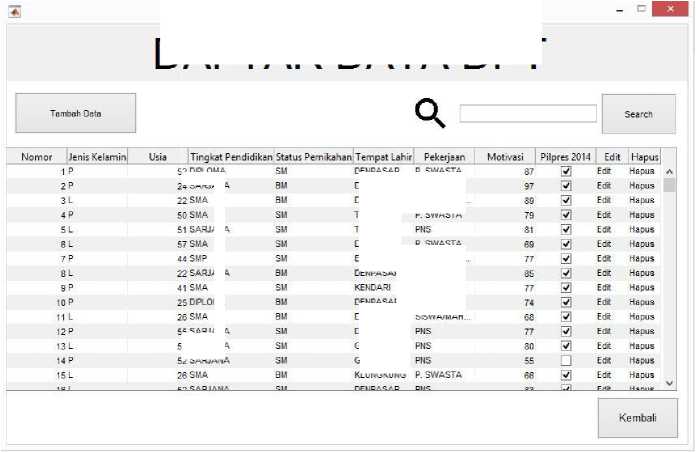
Gambar 10 Form Daftar Data DPT
52 DIPLOMA
24 SARJANA
55 SARJANA
56 SARJANA
DENPASAR P. SWASTA
DENPASAR P. SWASTA
DENPASAR
TABANAN
TABANAN
SISWAflJAH...
P. SWASTA
DENPASAR R. SWASIA
BANYUWANGI WIRASWAS...
DENPASAR
DENPASAR
DENPASAR
DENPASAR
GRESIK
GIANYAR
P. SWASTA
P. SWASTA
P. SWASTA
SISWAflJAH
Gambar 10 merupakan tampilan dari form daftar data DPT. Pengguna dapat melihat informasi data DPT yang telah tersimpan serta pengguna dapat melakukan aksi terhadap setiap data tersebut. Data yang telah tersimpan dapat dihapus dan diubah dengan memanfaatkan fungsi hapus dan edit pada bagian kanan dari setiap data yang ada. Data yang dihapus terlebih dulu dikonfirmasi dengan pesan peringatan sebelum dihapus. Fungsi edit data yang memungkinkan pengguna mengubah data yang sebelumnya telah tersimpan pada form daftar data DPT. Pengguna dapat mengubah isi dari setiap data yang ada sebelumnya.
Hasil pengujian sistem dengan menggunakan fungsi kernel linear, polynomial dan RBF menampilkan tingkat akurasi yang berbeda. Pengujian dengan data yang berjumlah 64 data memiliki tingkat akurasi rata-rata tertinggi adalah 97.50% dengan kernel RBF dan pengujian data dengan kernel linear memiliki tingkat akurasi yang paling rendah yaitu 93,67%. Hasil pengujian data dapat dilihat pada Tabel 3.
Tabel 3 Hasil Akurasi Setiap Kernel
|
No |
Nilai C |
Linear |
Polynomial |
RBF |
|
1 |
0,1 |
95,93% |
95,07% |
96,56% |
|
2 |
0,3 |
95,39% |
96,17% |
97,26% |
|
3 |
0,5 |
95,15% |
96,27% |
96,64% |
|
4 |
0,9 |
94,22% |
96,71% |
97,26% |
|
5 |
1 |
95,93% |
96,17% |
96,64% |
|
6 |
3 |
94,45% |
95,62% |
96,95% |
|
7 |
5 |
95,15% |
96,64% |
97,50% |
|
8 |
10 |
93,67% |
96,87% |
96,79% |
Perbedaan tingkat akurasi disebabkan adanya penggunaan jenis kernel yang berbeda pada setiap proses uji. Pengujian dengan data diacak cenderung lebih tinggi tingkat akurasinya pada kernel RBF serta memiliki kedekatan dengan data DPT yang digunakan sebagai sampel data. Kernel linear memiliki tingkat akurasi yang lebih rendah dari kernel yang lain karena semakin besar nilai parameter C dapat menambah toleransi kesalahan yang didapat pada saat proses klasifikasi dimana kernel linear mengontrol trade off antar frekuensi kesalahan C yang menyebabkan pengurangan vector pendukung dan kurang cocok digunakan untuk kumpulan data yang besar. Kernel RBF dan Polynomial memiliki karakteristik yang hampir mirip satu dengan yang lainnya. Kernel polynomial memiliki nilai akurasi yang optimal pada C 0,9 dan 10, karena memiliki ruang toleransi matrik yang besar mengakibatkan nilai akurasi meningkat. Serta kinerja kernel pada tingkat toleransi yang besar menjadi sangat baik dalam proses klasifikasi data, namum saat nilai C rendah yaitu 0,1 kernel polynomial cenderung memiliki tingkat akurasi yang rendah dikarenakan pembatasan nilai toleransi yang kecil. Kernel RBF memiliki nilai akurasi yang paling tinggi diantara tiga kernel yang digunakan. Nilai akurasi dari kernel RBF cenderung berubah-ubah pada setiap nilai C yang digunakan. Kernel RBF mendapat nilai akurasi terbaik dengan parameter C bernilai 5 dan mendapat akurasi terendah pada nilai C 0,1. Klasifikasi yang dilakukan dengan metode SVM memiliki akurasi rata-rata sebesar 96%. Perbaikan data dapat dilakukan untuk mengurangi noise yang dapat mengurangi performa dan akurasi dari metode SVM saat digunakan.
Simpulan yang dihasilkan berdasarkan penelitian yang telah dilakukan yaitu metode SVM dapat diimplementasikasi dalam sistem prediksi partisipasi pemilih dalam pemilu. Penerapan metode SVM pada sistem mampu memberikan tingkat akurasi mencapai 96%, dari 3 jenis kernel yang digunakan yaitu linear, polynomial dan RBF. Kernel yang digunakan secara berbeda-beda pada metode Support Vector Machine berpengaruh pada tingkat akurasi. Akurasi paling baik dari 3 jenis kernel yaitu menggunakan kernel RBF sebesar 97,50% dari 64 data uji dengan nilai parameter C terbaik adalah 5. Pengembangan penelitian bisa dilakukan dengan menambahkan record data untuk mendapatkan nilai akurasi yang lebih baik. Perbandingan metode SVM dengan metode klasifikasi lainnya dapat dilakukan pada penelitian berikutnya. Penelitian dapat dikembangkan menggunakan data dari derah lain yang dapat digunakan untuk mengetahui karakteristik pemilih secara lebih luas.
Daftar Pustaka
-
[1] N. M. Ardika, N. Piarsa, and A. Sasmita, “Telegram Bot Integration with Face
Recognition as Smart Home Features”, International Jurnal of Computer Applications, Vol 182, No 13, 2018.
-
[2] P. R. Nurbhawa, I K. G. D. Putra, N. Gunantara. “Sistem Pendukung Keputusan untuk
Penentuan Lokasi BTS PT. Smartfren menggunakan Metode Fuzzy-AHP,” Jurnal Ilmiah Teknologi Elektro, Vol. 16, No. 3, 2017.
-
[3] N. K. A. Wirdiani, N. N. T. Anggra, and A. A. K. O. Sudana, “Application of Android
based Ear Biometrics Indetification”, International Journal of Computer Applications, Vol 172, No 10, 2017.
-
[4] L. Agustino and M.A Yusoff, “Pemilihan Umum dan Perilaku Pemilih: Analisis Pemilih
Presiden 2009 Di Indonesia,” Jurnal Enam Bulanan, vol. 5, No 1,p. 416, 2009.
-
[5] H. Khoiril, and F. Azzah, “Pemilu Presiden 2019: Antara Kontestasi Politik dan
Persaingan Pemicu Perpecahan Bangsa,” Scientific Journals UNNES Seminar Nasional Hukum, Vol 4, No 3, 2018
-
[6] S. Nurhayati, K. Kusrini, and E. T. Luthfi, “Prediksi Mahasiswa Drop Out Menggunakan
Metode Support Vector Machine,” Jurnal Ilmiah Sistem Informasi dan Teknik Informatika, Vol 5, No 1, 2015
-
[7] Lukman, “Penerapan Algoritma Support Vector Machine (SVM) dalam Pemilihan
Beasiswa: Studi Kasus SMK YAPIMDA,” Faktor Exacta, Vol. 9, No. 1, 49-57, 2016.
-
[8] A. Pratama, R. C. Wihandika, and D. E. Ratnawati, “Implementasi Algoritme Support
Vector Machine (SVM) untuk Prediksi Ketepatan Waktu Kelulusan Mahasiswa”, Jurnal Pembangunan Teknologi Infromasi dan Ilmu Komputer, Vol 2. No 4, 2018
-
[9] D. J. Haryanto, L. Muflikhah, and M. A. Fauzi, “Analisis Sentimen Review Barang
Berbahasa Indonesia dengan Metode Support Vector Machine dan Query Expansion” Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol 2, No 9, 2018.
-
[10] A. F. Indriani and M. A. Muslim, “SVM Optimization Based on PSO and AdaBoost to
Increasing Accuracy of CKD Diagnosis,” Lontar Komputer, Vol. 10, No. 2, 2019
-
[11] W. Nugroho, “Politik Hukum Pasca Putusan Mahkamah Konstitusi atas Pelaksanaan
Pemilu dan Pemilukada di Indonesia Legal policy Post-Constitutional Court Decision on the Organisation of General Elections and Local Election in Indonesia,” Jurnal Konstitusi, Vol 13, No. 3, 481-502, 2016.
-
[12] H. Sulastri, A. I. Gufroni. “Penerapan Data Mining Pengelompokan Penderita
Thalasaemia,” Jurnal Nasional Teknologi dan Sistem Informasi, Vol 03, No 2, 2017.
-
[13] A. R. Chrismanto, and Y. Lukito. “Identifikasi Komentar Spam pada Instagram,”
LONTAR KOMPUTER: Jurnal Ilmiah Teknologi Informasi, Vol.8, No. 3, 2017
-
[14] K. N. Setiawan and I. M. S. Putra, “Klasifikasi Citra Mammogram Menggunakan Metode
K-Means, GLCM, dan Support Vector Machine (SVM),” Jurnal Ilmiah Merpati, Vol 6, No 1, 18, 2018.
-
[15] Eko P. “Data Mining - Mengolah Data Menjadi Informasi Menggunakan Matlab”, Ed. I,
Yogyakarta, 2014, 124.
-
[16] I. G. S. Suyoga, I. P. E. N. Kencana, and I. K. G. Sukarsa, “Penggolongan Uang Kuliah
Tunggal Menggunakan Support Vector Machine,” OJS Unud E-Jurnal Matematika, Vol 6, No 4, 2017
-
[17] R. Munawarah, O. Seosanto, and M. R. Faisal, “Penerapan Metode Support Vector
Machine pada Diagnosa Hepatitis”, Jurnal Ilmu Komputer, Vol 4, No 1, 2016.
Prediksi Partisipasi Pemilih dalam Pemilu Presiden 2014
dengan Metode Support Vector Machine (I Putu Arya Putra Wibawa)
192
Discussion and feedback