Pengelolaan Barang Milik Negara Menggunakan Sistem Pendukung Keputusan Berbasis C5.0
on
Majalah Ilmiah Teknologi Elektro, Vol.22, No.1, Jan-Juni 2023
DOI: https://doi.org/10.24843/MITE.2023.v22i01.P16
125
Pengelolaan Barang Milik Negara Menggunakan Sistem Pendukung Keputusan Berbasis C5.0
Pande Made Sutawan1, Made Sudarma2, Nyoman Gunantara3
[Submission:31-01-2023, Accepted: 03-03-2023]
Abstract — The recording of State Property at Udayana University on SIMAK-BMN has been carried out well, but the recorded State Property data only supports the preparation of balance sheets, lists of goods, reports of goods and control cards. The amount of data that is increasing every year has not been utilized optimally. The large amount of data at Udayana University and the superiority of K-Means in data grouping makes it possible to group data at the preprocessing stage using K-Means, then forming decision tree rules using C5.0 which is a refinement of the ID3 and C4.5 algorithms. The variables used in the formation of the decision tree are conditions, useful life and warranty period. The results of the study show that the decision tree rules that are formed are first checking the useful life, secondly checking good and other than good conditions, thirdly checking damaged conditions, namely lightly damaged and heavily damaged, and fourthly checking the warranty period. The recommendations generated by the decision support system are 2,894 preserved items, 1,397 deleted items, 112 maintained items with guarantees and 18 maintained items without warranty, out of a total of 4,421 items. The accuracy obtained is 97.69% calculated using the confusion matrix.
Keywords : State property; K-Means; C5.0
Intisari — Pencatatan Barang Milik Negara di Universitas Udayana pada SIMAK-BMN sudah dilakukan dengan baik, namun data Barang Milik Negara yang tercatat baru mendukung penyusunan neraca, daftar barang, laporan barang dan kartu kontrol. Jumlah data yang setiap tahun semakin meningkat belum dimanfaatkan secara maksimal. Jumlah data yang besar di Universitas Udayana dan keunggulan K-Means dalam pengelompokan data memungkinkan pengelompokan data pada tahapan preprocessing dilakukan dengan K-Means, selanjutnya pembentukan aturan pohon keputusan menggunakan C5.0 yang merupakan penyempurnaan dari algoritma ID3 dan C4.5. Variabel yang digunakan dalam pembentukan pohon keputusan yakni kondisi, masa manfaat dan masa garansi. Hasil dari penelitian menunjukkan bahwa aturan pohon keputusan yang terbentuk yaitu pertama pengecekan masa manfaat, kedua pengecekan kondisi baik dan selain baik, ketiga pengecekan kondisi rusak yaitu rusak ringan dan rusak berat, dan keempat pengecekan masa garansi. Rekomendasi yang dihasilkan sistem pendukung keputusan yaitu 2894 barang pertahankan, 1397 barang hapus, 112 barang pelihara dengan garansi dan 18 barang
pelihara tanpa garansi dari total 4421 barang. Akurasi yang diperoleh 97,69% dihitung menggunakan confusion matrix.
Kata Kunci —Barang Milik Negara; K-Means; C5.0
Pemeliharaan dan penghapusan termasuk pengelolaan Barang Milik Negara yang diatur dalam Peraturan Pemerintah. Penguasaan kekayaan negara dalam rangka pengamanan administrasi memerlukan suatu sistem [1]. Pemerintah telah mengembangkan SIMAK-BMN (Sistem Informasi Manajemen dan Akuntasi Barang Milik Negara), sistem ini berfungsi untuk penatausahaan BMN. SIMAK-BMN menghasilkan data transaksi pengelolaan BMN.
Universitas Udayana sebagai unit pengguna SIMAK-BMN, dengan Barang Milik Negara yang tercatat lebih dari sepuluh triliun, salah satu aset terbesar adalah peralatan dan mesin. Pencatatan Barang Milik Negara pada Universitas Udayana sesuai dengan Peraturan Pemerintah sudah dilakukan dengan baik. Pada aset peralatan dan mesin penghapusan barang masih ditentukan berdasarkan usulan, belum dilakukan identifikasi barang yang layak dilakukan penghapusan. Penyusunan anggaran untuk pemeliharaan juga dilakukan copy paste anggaran sebelumnya, belum dilakukan identifikasi jumlah barang yang akan dipelihara.
Jumlah data yang setiap tahun meningkat belum dimanfaatkan secara maksimal. Proses identifikasi barang untuk penghapusan dan pemeliharaan dilakukan dengan data mining. Data mining memeriksa data besar dalam data warehouse untuk menemukan hubungan kecenderungan yang berarti pola dengan menggunakan teknik pengenalan pola [2][3][4][5][6][7][8][9][10][11][12][13][14]. Penelitian ini menggunakan algoritma data mining K-Means dan C5.0. Jumlah data yang besar dan hasil penelitian sebelumnya yang menunjukkan kemampuan K-Means diaplikasikan dalam berbagai objek seperti daerah rawan tindak kriminalitas [15], status gizi balita [16], loyalitas pelanggan [17], dan keaktifan siswa [18] menjadi latar belakang pemilihan K-Means pada proses preprocessing karena keunggulannya dalam mengelompokkan objek besar dan tangguh dalam berbagai jenis data dalam mengelompokkan data menjadi beberapa kelompok yang memiliki kesamaan karakteristik [17][19][18]. Kumpulan data yang besar dan dapat menghasilkan akurasi yang baik seperti penelitian yang dilakukan sebelumnya tentang deteksi dini mahasiswa drop out [20], penilaian kinerja pegawai negeri sipil [12], dan pemilihan jurusan siswa [4]

menjadi latar belakang pemilihan C5.0 memproses data menjadi pohon keputusan untuk masukan dalam pengambilan keputusan [2][4][21].
-
A. Pengelolaan Barang Milik Negara
Peraturan yang mengatur pengelolaan Barang Milik Negara adalah Peraturan Pemerintah Nomor 28 Tahun 2020. Penghapusan dan pemeliharaan termasuk dalam pengelolaan BMN. Pemerintah telah mengembangkan SIMAK-BMN (Sistem Informasi Manajemen dan Akuntasi Barang Milik Negara) untuk mendukung pengelolaan BMN[1].
-
B. Data Mining
Data mining adalah proses penggalian informasi yang berguna dari basis data besar [3]. Data mining juga sering disebut Knowledge Discovery in Database (KDD) yang merupakan kegiatan pengumpulan data yang menggunakan data historis untuk menemukan pengetahuan, informasi, keteraturan, pola atau hubungan-hubungan dalam data besar [13][3][2][17][7][11][12][22][23][15][14].

Gambar 1: Tahapan-tahapan dalam proses KDD
Gambar 1 merupakan tahapan penggunaan data mining dalam proses KDD.
-
a. Mempelajari domain aplikasi, untuk mengetahui dan menggali pengetahuan dan tujuan yang relevan dari aplikasi
-
b. Membuat kumpulan data target
-
c. Membersihkan dan melakukan preprocessing data
-
d. Pengurangan dan transformasi data, dengan menemukan dan memilih fitur yang berguna, pengurangan dimensi atau variable, representasi invariant
-
e. Memilih fungsi data mining, antara lain summarization, klasifikasi, regresi, asosiasi, clustering
-
f. Memilih algoritma penambangan
-
g. Evalusi pola dan presentasi pengetahuan, melalui visualisasi, transformasi, menghilangkan pola yang berlebihan, dan lain-lain
-
h. Penggunaan pengetahuan yang ditemukan[8].
-
C. Preprocessing
Tahapan preprocessing merupakan salah satu tahapan data mining. Langkah ini cocok digunakan dalam data mining untuk mengolah data yang besar dan beragam, preprocessing dapat meminimalisir data dengan banyak noise yaitu kesalahan yang terjadi secara acak atau karena variasi yang terjadi dalam pengukuran variabel [8].
-
D. Algoritma K-Means
K-Means merupakan algoritma data mining untuk pengelompokan (cluster) data menjadi beberapa cluster berdasarkan jarak, kriteria, kondisi atau karakteristik [17][16][15][18]. Dalam satu kelompok data harus memiliki jarak terpendek, kriteria, kondisi atau karakteristik yang sama atau hampir sama. Algoritma K-Means dapat mengelompokkan objek yang mirip menjadi satu [19]. Algoritma ini menggunakan sistem partisi dalam mengelompokkan objek ke dalam k kluster [6]. Jumlah k kluster sebelumnya harus ditentukan [24].
-
E. Algoritma C5.0
Penyempurnaan dari algoritma ID3 dan C4.5 membentuk algoritma baru yaitu C5.0 [2][21][12][25][26][27][20][28].
Pada C5.0 gain ratio digunakan dalam pemilihan atributnya [4][21]. C5.0 membuat pohon dengan jumlah variabel cabang per node. Pohon yang dihasilkan algoritma C5.0 mirip dengan pohon algoritma C4.5 dalam menghitung entropy dan gain. Algoritma C4.5 berhenti sampai perhitungan gain, sedangkan algoritma C5.0 melanjutkan dengan menghitung gain ratio menggunakan gain dan entropy yang ada [21].
Tahapan pada penelitian ini yaitu identifikasi masalah, pengumpulan data, preprocessing dan pembentukan pohon keputusan. Identifikasi masalah bertujuan untuk mengetahui permasalah yang ada. Setelah masalah diidentifikasi selanjutnya pengumpulan data. Data yang dikumpulkan selanjutnya diolah untuk menentukan data yang akan digunakan untuk preprocessing menggunakan algoritma K-Means, preprocessing dilakukan karena keberagaman data dan jumlah data yang besar. Tujuan preprocessing yaitu mengelompokkan data menjadi data set sesuai dengan format yang dibutuhkan untuk analisis. Setelah data set didapatkan selanjutnya pembentukan pohon keputusan menggunakan algoritma C5.0.
-
A. Data Barang Milik Negara
Hasil pengumpulan data berupa aset peralatan dan mesin tahun perolehan 2016 s.d. 2021 sebanyak 4421 unit. Aset peralatan dan mesin dibagi menjadi 3 kategori yakni personal komputer, printer, dan LCD.
TABEL I
PEROLEHAN BARANG MILIK NEGARA
|
No. |
Tahun Perolehan |
Kategori | ||
|
Personal Komputer (unit) |
Printer (unit) |
LCD (unit) | ||
|
1 |
2016 |
363 |
123 |
166 |
|
2 |
2017 |
356 |
168 |
150 |
|
3 |
2018 |
375 |
144 |
114 |
|
4 |
2019 |
546 |
203 |
244 |
|
5 |
2020 |
575 |
176 |
103 |
|
6 |
2021 |
436 |
147 |
32 |
|
Tahun Perolehan |
Baik |
Rusak Ringan |
Rusak Berat | |
|
1 |
2016 |
599 |
31 |
22 |
|
2 |
2017 |
577 |
67 |
30 |
|
3 |
2018 |
575 |
40 |
18 |
|
4 |
2019 |
926 |
37 |
30 |
|
5 |
2020 |
814 |
24 |
16 |
|
6 |
2021 |
575 |
29 |
7 |
Kondisi barang dari jumlah total perolehan pada setiap tahunnya lebih banyak dalam kondisi baik. Persentase kondisi baik tertinggi yaitu pada tahun 2020 sedangkan persentase rusak ringan dan rusak berat tertinggi pada tahun 2017.
Perolehan personal komputer, printer, dan LCD berbeda setiap tahun. Jumlah perolehan personal komputer tertinggi pada tahun 2020 sebanyak 575 unit. Jumlah perolehan printer tertinggi pada tahun 2019 sebanyak 203 unit dan jumlah perolehan LCD tertinggi pada tahun 2019 sebanyak 244 unit. Jumlah perolehan berbeda setiap tahunnya dikarenakan kebutuhan terhadap barang dan alokasi anggaran.
• ••»•• Baik
-■•- Rusak Ringan
Rusak Berat
700
600
'⊂ 500
Σ2 400
⅞ 300
200
100
0

201620172018201920202021
Tahun
• •■*•• Personal Komputer
-«- Printer
LCD
Gambar 2: Grafik Perolehan Barang Milik Negara
Pada Gambar 2 terlihat bahwa jumlah perolehan personal komputer lebih banyak dibandingkan printer dan LCD, namun dari tahun ketahun jumlah perolehan untuk personal komputer, printer, dan LCD fluktuatif dimana terjadi peningkatan dan penurunan.
TABEL II
KONDISI BARANG MILIK NEGARA
|
No. |
Kondisi |
Gambar 3: Grafik Kondisi Barang Milik Negara
Pada Gambar 3 terlihat bahwa kondisi barang dari tahun 2016 s.d. 2021 lebih banyak dalam kondisi baik dibandingkan kondisi rusak ringan maupun rusak berat. Kondisi baik lebih banyak karena barang masih tergolong perolehan baru.
Barang Milik Negara selanjutnya dilakukan pengelompokan, pengelompokan dilakukan berdasarkan tahun, merk, dan kondisi (rusak berat, rusak ringan, dan baik) untuk setiap barang. Pengelompokan ini dilakukan untuk membentuk data set yang digunakan dalam proses preprocessing. Proses preprocessing dilakukan terhadap kondisi barang untuk menentukan cluster yang digunakan sebagai data latih.
B. Preprocessing
Preprocessing data menggunakan atribut kondisi yakni baik, rusak ringan, dan rusak berat. Proses uji coba jumlah cluster menggunakan Software RapidMiner Studio 9.10.001. RapidMiner software yang bersifat terbuka yang dapat melakukan analisis terhadap data mining [6][29]. Uji coba berbagai jumlah cluster mulai dari 2 hingga 5 cluster. Uji coba bertujuan untuk menentukan jumlah cluster terbaik sebagai dasar pembangunan sistem pendukung keputusan.
TABEL III
HASIL UJI COBA JUMLAH CLUSTER

|
No. |
Jumlah Cluster |
Davies Bouldin |
|
1 |
2 |
0,233 |
|
2 |
3 |
0,312 |
|
3 |
4 |
0,404 |
|
4 |
5 |
0,453 |
Penentuan jumlah cluster terbaik ditentukan berdasarkan nilai Davies Bouldin, semakin kecil nilainya maka semakin baik. Hasil uji coba berbagai jumlah cluster menunjukkan bahwa nilai Davies Bouldin paling kecil terdapat pada jumlah cluster 2.
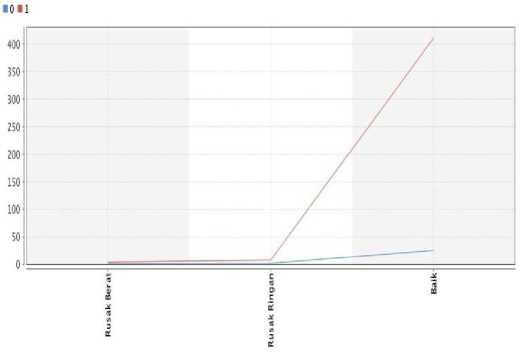
Gambar 4: Cluster model dengan 2 cluster
Gambar 4: menunjukkan bahwa cluster_0 (biru) memiliki centroid rata-rata lebih rendah daripada cluster_1 (merah). Jadi cluster_0 (biru) ditempatkan di cluster prioritas rendah untuk pemeliharaan/penghapusan sementara cluster_1 (merah) ditempatkan di cluster prioritas tingggi untuk pemeliharaan/penghapusan.
TABEL IV
HASIL CLUSTER
|
Kategori |
Th. |
Merk |
Kondisi |
C | ||
|
R B |
R R |
B | ||||
|
Personal Komputer |
2016 |
HP |
3 |
10 |
305 |
c_1 |
|
Samsung |
0 |
2 |
5 |
c_0 | ||
|
Apple |
0 |
1 |
3 |
c_0 | ||
|
Wacom |
0 |
0 |
2 |
c_0 | ||
|
Asus |
2 |
4 |
26 |
c_0 | ||
|
2017 |
HP |
2 |
7 |
175 |
c_0 | |
|
Intel |
5 |
8 |
141 |
c_0 | ||
|
Lenovo |
0 |
1 |
2 |
c_0 | ||
|
Acer |
0 |
1 |
2 |
c_0 | ||
|
Asus |
2 |
0 |
4 |
c_0 | ||
|
Logitech |
1 |
1 |
4 |
c_0 | ||
|
2018 |
HP |
3 |
8 |
362 |
c_1 | |
|
Logitech |
2 |
0 |
0 |
c_0 | ||
|
2019 |
HP |
12 |
6 |
456 |
c_1 | |
|
Apple |
0 |
0 |
5 |
c_0 | ||
|
Lenovo |
4 |
8 |
43 |
c_0 | ||
|
Logitech |
2 |
4 |
6 |
c_0 | ||
|
2020 |
Samsung |
1 |
2 |
17 |
c_0 | |
|
HP |
4 |
8 |
521 |
c_1 | ||
|
Asus |
1 |
0 |
4 |
c_0 | ||
|
Apple |
0 |
0 |
17 |
c_0 | ||
|
2021 |
Apple |
0 |
1 |
6 |
c_0 | |
|
Dell |
0 |
0 |
15 |
c_0 | ||
|
HP |
0 |
7 |
407 |
c_1 | ||
|
Printer |
2016 |
HP |
5 |
8 |
64 |
c_0 |
|
Epson |
3 |
3 |
32 |
c_0 | ||
|
Fujitsu |
0 |
0 |
2 |
c_0 | ||
|
Brother |
0 |
0 |
4 |
c_0 | ||
|
Canon |
0 |
0 |
2 |
c_0 | ||
|
2017 |
HP |
3 |
12 |
76 |
c_0 | |
|
Epson |
2 |
8 |
37 |
c_0 | ||
|
Canon |
8 |
8 |
14 |
c_0 | ||
|
2018 |
Epson |
3 |
6 |
62 |
c_0 | |
|
HP |
0 |
3 |
37 |
c_0 | ||
|
Brother |
0 |
0 |
8 |
c_0 | ||
|
Canon |
1 |
4 |
20 |
c_0 | ||
|
2019 |
Epson |
2 |
0 |
131 |
c_0 | |
|
HP |
2 |
2 |
50 |
c_0 | ||
|
Canon |
3 |
3 |
10 |
c_0 | ||
|
2020 |
HP |
1 |
1 |
26 |
c_0 | |
|
Epson |
1 |
5 |
124 |
c_0 | ||
|
Brother |
0 |
0 |
6 |
c_0 | ||
|
Zebra |
0 |
0 |
5 |
c_0 | ||
|
Canon |
0 |
2 |
5 |
c_0 | ||
|
2021 |
Epson |
4 |
7 |
68 |
c_0 | |
|
HP |
0 |
2 |
23 |
c_0 | ||
|
Canon |
1 |
1 |
9 |
c_0 | ||
|
Panasonic |
0 |
2 |
7 |
c_0 | ||
|
Brother |
0 |
3 |
20 |
c_0 | ||
|
LCD |
2016 |
HP |
0 |
0 |
1 |
c_0 |
|
NEC |
10 |
7 |
118 |
c_0 | ||
|
BENQ |
0 |
0 |
3 |
c_0 |
|
Sony |
0 |
2 |
8 |
c_0 | ||
|
INFOCUS |
1 |
1 |
4 |
c_0 | ||
|
Viewsonic |
0 |
0 |
5 |
c_0 | ||
|
Epson |
0 |
0 |
2 |
c_0 | ||
|
Panasonic |
0 |
0 |
1 |
c_0 | ||
|
Microvision |
0 |
0 |
3 |
c_0 | ||
|
2017 |
Panasonic |
0 |
3 |
19 |
c_0 | |
|
BENQ |
3 |
8 |
58 |
c_0 | ||
|
Sony |
1 |
2 |
3 |
c_0 | ||
|
Epson |
1 |
2 |
9 |
c_0 | ||
|
Viewsonic |
0 |
4 |
19 |
c_0 | ||
|
Microvision |
2 |
1 |
8 |
c_0 | ||
|
NEC |
0 |
1 |
6 |
c_0 | ||
|
2018 |
HP |
0 |
0 |
2 |
c_0 | |
|
BENQ |
2 |
2 |
9 |
c_0 | ||
|
Microvision |
4 |
7 |
43 |
c_0 | ||
|
NEC |
1 |
3 |
14 |
c_0 | ||
|
Epson |
0 |
5 |
9 |
c_0 | ||
|
Viewsonic |
2 |
2 |
9 |
c_0 | ||
|
2019 |
Microvision |
3 |
7 |
183 |
c_0 | |
|
NEC |
2 |
5 |
27 |
c_0 | ||
|
BENQ |
0 |
1 |
4 |
c_0 | ||
|
Epson |
0 |
1 |
6 |
c_0 | ||
|
Panasonic |
0 |
0 |
3 |
c_0 | ||
|
Sony |
0 |
0 |
2 |
c_0 | ||
|
2020 |
NEC |
3 |
2 |
27 |
c_0 | |
|
Microvision |
5 |
3 |
52 |
c_0 | ||
|
Epson |
0 |
1 |
5 |
c_0 | ||
|
Infocus |
0 |
0 |
2 |
c_0 | ||
|
Panasonic |
0 |
0 |
2 |
c_0 | ||
|
Sony |
0 |
0 |
1 |
c_0 | ||
|
2021 |
Microvision |
2 |
4 |
16 |
c_0 | |
|
Viewsonic |
0 |
2 |
8 |
c_0 |
Keterangan:
RB = Rusak Berat
RR = Rusak Ringan
B = Baik
C = Cluster
Hasil cluster_0 sebanyak 80 jenis barang dan cluster_1 sebanyak 5 jenis barang. Perbedaan anggota cluster yang signifikan dipengaruhi oleh barang dengan kondisi baik yang
memiliki selisih jauh dengan yang lainnya. Barang dengan kondisi baik yang tinggi atau lebih dari 300 unit dikelompokkan menjadi satu cluster yaitu pada cluster_1.
Penentuan jumlah cluster setelah uji coba yang digunakan pada tahapan preprocessing untuk membangun sistem pendukung keputusan yaitu jumlah cluster 2. Data latih diambil secara acak dari cluster_0, cluster_0 dipilih karena jumlah barang lebih banyak dan jarak antar kondisi tidak terlalu jauh.
-
C. Sistem Pendukung Keputusan Berbasis C5.0
Variabel yang digunakan dalam pembentukan pohon keputusan yakni kondisi, masa manfaat, dan masa garansi barang. Masa manfaat ditentukan 4 tahun dihitung mundur dari tahun 2022 dan masa garansi untuk barang merk HP 3 tahun sedangkan barang selain merk HP 1 tahun dihitung dari tahun perolehan. Jumlah data yang digunakan sebagai data latih pembentukan pohon keputusan sebanyak 940 yang diambil secara acak dari cluster_0.
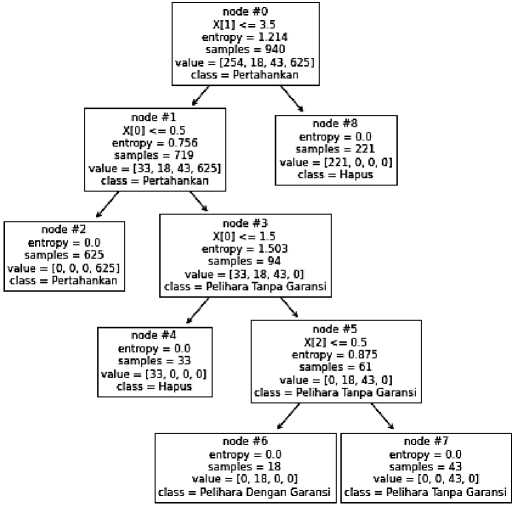
Gambar 5: Pohon keputusan berbasis C5.0
Hasil pohon keputusan menunjukkan bahwa pada node #0 sebagai root selanjutnya dibuatkan pohon keputusan dengan dilakukan proses pengecekan masa manfaat artinya jika masa manfaat barang lebih dari 4 tahun maka direkomendasikan untuk Hapus pada node #8 sebanyak 221 dan jika masa maanfaat kurang dari 4 tahun maka node #1 dilakukan proses pengecekan Kondisi artinya jika kondisi baik maka direkomendasikan untuk Pertahankan node #2 sebanyak 625 dan jika kondisi selain baik maka node #3 dilakukan proses pengecekan Kondisi selain baik artinya jika rusak berat maka direkomendasikan untuk Hapus node #4 sebanyak 33 dan jika rusak rusak ringan maka node #5 dilakukan proses pengecekan garansi artinya jika masih dalam masa garansi direkomendasikan Pelihara Dengan Garansi node #6 sebanyak

18 dan jika melebihi masa garansi maka direkomendasikan Pelihara Tanpa Garansi node #7 sebanyak 43.
Aturan pohon keputusan yang terbentuk pertama pengecekan masa manfaat, kedua pengecekan kondisi baik dan selain baik, ketiga pengecekan kondisi rusak yaitu rusak berat dan rusak ringan dan keempat pengecekan masa garansi.
TABEL V
PERBANDINGAN HASIL KEPUTUSAN
|
Label |
Pohon Keputusan C5.0 | ||||||
|
P |
H |
PDG |
PTG |
P |
H |
PDG |
PTG |
|
2894 |
1397 |
46 |
84 |
2894 |
1397 |
112 |
18 |
Keterangan:
P = Pertahankan
H = Hapus
PDG = Pelihara Dengan Garansi
PTG = Pelihara Tanpa Garansi
Keseluruhan data sebanyak 4421 yang digunakan sebagai data uji didapatkan perbandingan antara label dan rekomendasi sistem bahwa pohon keputusan berbasis C5.0 pada rekomendasi Pertahankan dan Hapus jumlah data yang dihasilkan sama, namun terdapat perbedaan pada rekomendasi Pelihara Dengan Garansi dan Pelihara Tanpa Garansi berbeda. Perbedaan ini terjadi pada pengecekan keempat yaitu pengecekan masa garansi.
Output dari sistem pendukung keputusan berbasis C5.0 yang dibangun berbasis web dapat memberikan rekomendasi barang untuk Pertahankan artinya barang dalam kondisi baik dan kurang dari masa maanfaat. Hapus artinya barang sudah dalam kondisi rusak berat atau melebihi masa manfaat. Pelihara Tanpa Garansi artinya barang dalam kondisi rusak ringan dan garansi barang sudah melebihi masa garansi. Pelihara Dengan Garansi artinya barang dalam kondisi rusak ringan dan masih dalam masa garansi.
Akurasi yang diperoleh sistem ini sebesar 97,69% dihitung menggunakan confusion matrix dengan data uji keseluruhan data.
Pengelolaan Barang Milik Negara menggunakan sistem pendukung keputusan berbasis C5.0 didapatkan hasil 2894 barang Pertahankan, 1397 barang Hapus, 112 barang Pelihara Dengan Garansi, dan 18 barang Pelihara Tanpa Garansi.
Aturan pohon keputusan yang terbentuk pertama pengecekan masa manfaat, kedua pengecekan kondisi baik dan selain baik, ketiga pengecekan kondisi rusak yaitu rusak berat dan rusak ringan dan keempat pengecekan masa garansi. Perbandingan label dan rekomendasi mendapatkan hasil yang sama pada rekomendasi Pertahankan dan Hapus, sedangkan Pelihara Dengan Garansi dan Pelihara Tanpa Garansi mendapatkan hasil yang berbeda. Perbedaan ini dipengaruhi oleh variabel masa garansi.
Sistem pendukung keputusan berbasis C5.0 dapat direkomendasikan untuk digunakan sebagai metode pengelolaan Barang Milik Negara khususnya penghapusan dan pemeliharaan.
Referensi
R. Indonesia, “Peraturan Pemerintah Republik Indonesia Nomor 28 Tahun 2020 tentang Perubahan atas Peraturan Pemerintah Nomor 27 Tahun 2014 tentang Pengelolaan Barang Milik Negara/Daerah.” 2020.
-
D. P. Utomo, P. Sirait, and R. Yunis, “Reduksi Atribut Pada Dataset Penyakit Jantung dan Klasifikasi Menggunakan Algoritma C5.0,” JURNAL MEDIA INFORMATIKA BUDIDARMA, vol. 4, no. 4, pp. 994–1006, 2020, doi: DOI 10.30865/mib.v4i4.2355.
R. Yanto and H. D. Kesuma, “Pemanfaatan Data Mining Untuk Penempatan Buku Di Perpustakaan Menggunakan Metode Association Rule,” Jatisi, vol. 4, no. 1, pp. 1–10, 2017.
-
A. S. Sunge and F. L. Devi, “Analisis Pemilihan Jurusan Siswa dengan Metode Klasifikasi C5.0 (Studi Kasus: SMK Ma’Arif NU Al -Mawardi Bekasi),” SIGMA – Jurnal Teknologi Pelita Bangsa, vol. 10, no. 4, p. 8, 2020.
P. H. Simbolon, “Implementasi Data Mining Pada Sistem Persediaan Barang Menggunakan Algoritma Apriori (Studi Kasus: Srikandi Cash Credit Elektronic dan Furniture),” Jurnal Riset Komputer (JURIKOM), vol. 6, no. 4, pp. 401–406, 2019.
-
F. L. Sibuea and A. Sapta, “Pemetaan Siswa Berprestasi Menggunakan Metode K-Means Clustering,” Jurnal Teknologi dan Sistem Informasi, vol. 4, no. 1, pp. 85–92, 2017.
-
F. Rahmawati and N. Merlina, “Metode Data Mining Terhadap Data Penjualan Sparepart Mesin Fotocopy Menggunakan Algoritma Apriori,” PIKSEL, vol. 6, no. 1, pp. 9–20, 2018, doi: 10.33558/piksel.v6i1.1390.
-
E. Prasetyowati, Data Mining Pengelompokan Data untuk Informasi dan Evaluasi. 2017.
M. S. Mustafa, M. R. Ramadhan, and A. P. Thenata, “Implementasi Data Mining untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier,” citec, vol. 4, no. 2, pp. 151–162, 2017, doi: 10.24076/citec.2017v4i2.106.
-
D. Listriani, A. H. Setyaningrum, and F. Eka, “Penerapan Metode Asosiasi Menggunakan Algoritma Apriori Ppada Aplikasi Analisa Pola Belanja Konsumen (Studi Kasus Toko Buku Gramedia Bintaro),” J. Teknik inform., vol. 9, no. 2, pp. 120–127, 2018, doi: 10.15408/jti.v9i2.5602.
B. L. Lesmana, “Analisis Pola Penjualan Obat Dan Alat Kesehatan Di Apotek THS Pematangsiantar Dengan Menggunakan Algoritma Apriori,” Seminar Nasional Matematika dan Terapan 2019, vol. 1, pp. 652–657, 2019.
P. W. Kastawan, D. M. Wiharta, and M. Sudarma, “Implementasi Algoritma C5.0 pada Penilaian Kinerja Pegawai Negeri Sipil,” JTE, vol. 17, no. 3, pp. 371–376, 2018, doi: 10.24843/MITE.2018.v17i03.P11.
-
E. Buulolo, Data Mining untuk Perguruan Tinggi. 2020.
-
H. D. Anggraeni, R. Saputra, and B. Noranita, “Aplikasi Data Mining Analisis Data Transaksi Penjualan Obat Menggunakan Algoritma Apriori (Studi Kasus di Apotek Setya Sehat Semarang),” JMASIF, vol. 4, no. 7, pp. 1–8, 2013, doi: 10.14710/jmasif.4.7.1-8.
-
Y. Aswan, S. Defit, and G. W. Nurcahyo, “Algoritma K-Means Clustering dalam Mengklasifikasi Data Daerah Rawan Tindak Kriminalitas (Polres Kepulauan Mentawai),” JSisfotek, vol. 3, no. 4, pp. 245–250, 2021, doi: 10.37034/jsisfotek.v3i4.73.
W. M. P. Dhuhita, “Clustering Menggunakan Metode K-Means untuk menentukan Status Gizi Balita,” Jurnal Informatika, vol. 15, no. 2, pp. 160–174, 2015.
-
C. D. O. Soleman, N. Pramaita, and M. Sudarma, “Classification Of Loyality Customer Using K-Means Clustering, Studi Case: PT. Sucofindo (Persero) Denpasar Branch,” International Journal of Engineering and Emerging Technology, vol. 5, no. 2, pp. 160–167, 2020.
M. Triandini, S. Defit, and G. W. Nurcahyo, “Data Mining dalam Mengukur Tingkat Keaktifan Siswa dalam Mengikuti Proses Belajar pada SMP IT Andalas Cendekia,” jidt, vol. 3, no. 3, pp. 167–173, 2021, doi: 10.37034/jidt.v3i3.120.
-
A. Solichin and K. Khairunnisa, “Klasterisasi Persebaran Virus Corona (Covid-19) Di DKI Jakarta Menggunakan Metode K-Means,” FIJ, vol. 5, no. 2, pp. 52–59, 2020, doi: 10.21111/fij.v5i2.4905.
U. S. Aesyi, A. R. Lahitani, T. W. Diwangkara, and R. T. Kurniawan, “Deteksi Dini Mahasiswa Drop Out Menggunakan C5.0,” JISKa, vol. 6, no. 2, pp. 113–119, 2021, doi: 10.14421/jiska.2021.6.2.113-119.
R. Pratiwi, M. N. Hayati, and S. Prangga, “Perbandingan Klasifikasi Algoritma C5.0 dengan Classification and Regression Tree (Studi Kasus: Data Sosial Kepala Keluarga Masyarakat Desa Teluk Baru Kecamatan Muara Ancalong Tahun 2019),” Jurnal Ilmu Matematika dan Terapan, vol. 14, no. 2, pp. 267–278, 2020.
-
[22] I. B. P. Jayawiguna, I. B. A. Swamardika, and M. Sudarma, “Comparison of Model Prediction for Tile Production in Tabanan Regency with Orange Data Mining Tool,” International Journal of Engineering and Emerging Technology, vol. 5, no. 2, pp. 72–76, 2020.
-
[23] J. Eska, “Penerapan Data Mining Untuk Prediksi Penjualan Wallpaper Menggunakan Algoritma C4.5,” JURTEKSI (Jurnal Teknologi dan Sistem Informasi), vol. 2, no. 2, pp. 9–13, 2016, doi:
10.31227/osf.io/x6svc.
-
[24] R. R. Putra and C. Wadisman, “Implementasi Data Mining Pemilihan Pelanggan Potensial Menggunakan Algoritma K-Menas,” Journal of Information Technology and Computer Science, vol. 1, no. 1, pp. 72– 77, 2018, doi: DOI : https://doi.org/10.31539/intecoms.v1i1.141.
-
[25] M. Hassoon, M. S. Kouhi, M. Zomorodi-Moghadam, and M. Abdar, “Rule Optimization of Boosted C5.0 Classification Using Genetic Algorithm for Liver disease Prediction,” in 2017 International Conference on Computer and Applications (ICCA), Doha, United Arab Emirates, Sep. 2017, pp. 299–305. doi:
10.1109/COMAPP.2017.8079783.
-
[26] J. Guo, H. Liu, Y. Luan, and Y. Wu, “Application of Birth Defect Prediction Model Based on C5.0 Decision Tree Algorithm,” in 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Halifax, NS, Canada, Jul. 2018, pp. 1867–1871. doi: 10.1109/Cybermatics_2018.2018.00310.
-
[27] K. Auliasari, M. Kertaningtyas, and D. Wilis Lestarining Basuki, “Analisis Penentuan Resiko Kredit Menggunakan Algoritma C.5.0,” J-TIT, vol. 8, no. 1, pp. 28–33, 2021, doi: 10.25047/jtit.v8i1.218.
-
[28] U. S. Aesyi, T. W. Diwangkara, and R. T. Kurniawan, “Diagnosa Penyakit Disk Hernia dan Spondylolisthesis Menggunakan Algoritma C5,” Telematika, vol. 16, no. 2, pp. 81–86, 2020, doi:
10.31315/telematika.v16i2.3181.
-
[29] N. Agustiani, D. Suhendro, and W. Saputra, “Penerapan Data Mining Metode Apriori Dalam Implementasi Penjualan Di Alfamart,” Prosiding Seminar Nasional Riset Dan Information Science (SENARIS) 2020, vol. 2, pp. 300–304, 2020.

[HALAMAN INI SENGAJA DIKOSONGKAN]
ISSN 1693 – 2951
Made Sutawan: Pengelolaan Barang Milik Negara …
Discussion and feedback