Clustering History Data Penjualan Menggunakan Algoritma K-Means
on
Majalah Ilmiah Teknologi Elektro, Vol. 20, No. 2, Juli - Desember 2021
DOI: https://doi.org/10.24843/MITE.2021.v20i02.P03 195
Clustering History Data Penjualan Menggunakan
Algoritma K-Means
Yogiswara Dharma Putra1, Made Sudarma2, Ida Bagus Alit Swamardika3
[Submission: 26-03-2021, Accepted: 07-05-2021]
Abstract— The company has a desire to develop an increase in its business so that it is not eroded by the very tight business competition. Company X is a company engaged in information technology and telecommunications. The amount of data on goods from the inventory carried out is still global, so grouping is needed. History of sales data becomes data that can be used in viewing the flow of goods movement from the most desirable to the least desirable. This is needed as the next reference for companies in making inventory to support sales and maintain customer satisfaction. This study uses a clustering method which is a method that can be used to see the level of sales that have been made based on the formed clusters. The K-Means algorithm is a suitable method to process sales history data because it has a fairly easy implementation, the time needed to run the process is relatively fast and easy to adapt than other clustering methods. The results of the application of the K-Means algorithm formed 3 clusters representing categories of high interest, interest, and least interest. In the most interested category there are 5 total items, in the interested category there are 4 total items, and 14 items less interested. These results are expected to help create quality goods to maintain product quality and customer satisfaction.
Keywords – Clustering, K-Means Algorithm, Sales
Intisari— Perusahaan memiliki keinginan dalam mengembangkan peningkatan usahanya agar tidak tergerus dalam persaingan bisnis yang sangat ketat. Perusahaan X merupakan sebuah perusahaan yang bergerak dalam bidang teknologi informasi dan telekomunikasi. Jumah data barang dari persediaan yang dilakukan masih bersifat global sehingga perlu adanya pengelompokkan. History data penjualan menjadi data yang dapat digunakan dalam melihat arus pergerakan barang dari yang paling diminati hingga kurang diminati. Hal itu diperlukan sebagai acuan berikutnya bagi perusahaan dalam melakukan persediaan barang untuk menunjang penjualan dan menjaga kepuasan dari pelanggan. Penelitian ini menggunakan sebuah metode clustering yang merupakan sebuah metode yang bisa digunakan dalam melihat tingkat penjualan yang telah dilakukan berdasarkan cluster yang terbentuk. Algoritma K-Means menjadi metode yang cocok dapat mengolah history data penjualan dikarenakan memiliki pengimplementasian yang cukup mudah, waktu yang dibutuhkan dalam menjalankan prosesnya cukup relatif cepat dan mudah untuk diadaptasikan dari pada metode clustering lainnya.
Hasil dari penerapan algortima K-Means terbentuk 3 cluster yang mewakili kategori sangat diminati, diminati dan kurang diminati. Pada kategori sangat diminati terdapat 5 jumlah item barang, kategori diminati terdapat 4 jumlah item barang dan kurang diminati terdapat 14 jumlah item barang. Hasil tersebut diharapkan dapat membantu dalam menciptakan barang yang berkualitas sehingga dapat menjaga kulitas produk serta kepuasan dari pelanggan.
Kata Kunci— Clustering, Algoritma K-Means, Penjualan
Setiap perusahaan dalam bidang perdagangan memiliki keinginan untuk mengembangkan usahanya dengan maksimal agar tidak tenggelam dalam persaingan bisnis yang berjalan sangat ketat. Banyak perusahaan yang melakukan berbagai cara agar tidak kalah dalam persaingan bisnis dengan menciptakan produk-produk terbaik untuk meningkatkan tingkat penjualan perusahaan. Perusahaan yang bergerak dalam bidang usaha dagang dan jasa bertujuan untuk dapat memperoleh laba dengan memanfaatkan sumber daya yang sudah dimiliki perusahaan.
Penelitian dilakukan pada sebuah perusahaan yang bergerak dalam bidang teknologi informasi dan komunikasi. Penelitian ini mengambil data objek pada perusahaan X dengan beberapa produk mulai dari laptop, komputer all in one, komputer desktop dan printer, kategori-kategori tersebut merupakan kebutuhan yang paling sering dibutuhkan oleh pelanggan perusahaan sehingga perlu adanya kemampuan untuk memperkirakan volume penjualan dari setiap produk yang dijual. Kepuasan pelanggan selalu menjadi prioritas agar dapat memenuhi kebutuhan pelanggan. Kebutuhan tersebut berdasarkan dari history penjualan yang sudah dilakukan sehingga dapat menjadi acuan dalam meningkatkan kualitas produk-produk berikutnya dalam melakukan perencanaan stok untuk menargetkan penjualan yang lebih baik sehingga mampu memberikan kepuasan bagi para pelanggan..
Data mining adalah sebuah proses yang dapat dilakukan untuk menemukan hubungan dari data yang belum diketahui oleh pengguna dengan menyajikannya dengan cara yang lebih mudah untuk dipahami agar dapat menjadi dasar dalam sebuah pengambilan keputusan [1][2].
Clustering adalah salah satu teknik dari data mining yang bertujuan untuk mengelompokkan data berdasarkan karakteristik kemiripan antara satu data dengan data lainnya [3]. Salah satu algoritma clustering yang dapat digunakan dalam mengelompokkan data berdasarkan karakteristik kemiripan adalah K-Means Clustering. Algoritma K-Means memiliki algoritma dengan mengelompokkan secara iteratif yang melakukan partisi data set ke dalam beberapa K cluster yang
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

sudah ditentukan diawal yang dapat diimplementasikan dan dijalankan dengan relatif cepat dan mudah beradaptasi [4].
Penelitian mengenai algoritma K-Means sudah banyak dilakukan oleh para peneliti-peneliti dalam menunjang kebutuhan dari berbagai bidang. Algoritma K-Means digunakan dalam penelitian ini dikarenakan memiliki pengimplementasian yang cukup mudah, waktu yang dibutuhkan dalam menjalankan prosesnya cukup relatif cepat dan mudah untuk diadaptasikan, maka penelitian mengenai clustering data penjualan ini diharapkan bisa membantu perusahaan X dalam proses manajemen stok dan melihat peluang dari penjualan sebelumnya yang dapat menghasilkan produk terbaik sehingga dapat menjaga kualitas produk serta kepuasan dari pelanggan.
-
A. Data Mining
Data mining dikenal sejak tahun 1990, Ketika pekerjaan dalam pemanfaatan data menjadi sangat penting dalam berbagai bidang, mulai dari bidang bisnis, akademik dan lainnya [5]. Data mining digunakan karena mulai banyaknya jumlah data yang tersimpan dalam basis data. Data mining juga disebut sebagai knowledge discovery in database (KDD) ataupun pattern recognition. Istilah KDD disebut sebagai penemuan pengetahuan data yang dimana tujuan utama dari data mining adalah memanfaatkan data dalam basis data sehingga dapat diolah dan menghasilkan informasi baru yang berguna [6].
Istilah pattern recognition disebut sebagai pengenalan pola yang mempunyai tujuan pengetahuan yang dicari dari dalam basis data yang berisikan banyak data [7]. Jadi, dapat diartikan data mining adalah sebuah proses yang menggunakan beberapa Teknik seperti statistik, matematik, kecerdasan buatan dan machine learning yang bertujuan untuk mengolah dan mengidentifikasi suatu informasi yang berguna dari berbagai himpunan data yang besar [8][9].
-
B. Clustering
Clustering merupakan sebuah proses dalam pembentukan kelompok-kelompok data yang berasal dari himpunan data yang belum diketahui kelas-kelasnya dan proses menentukan sebuah data termasuk dalam kelas-kelas tersebut [10][11]. Potensi dari menggunakan clustering adalah dapat digunakan mengetahui struktur-struktur yang berada dalam data dan dapat digunakan dalam berbagai aplikasi seperti, pengenalan pola, pengolahan gambar serta klasifikasi [12][13].
-
C. Algoritma K-Means
Algoritma K-Means merupakan metode non hierarki yang awalnya dapat mengambil sebagian banyak komponen data untuk dapat dijadikan pusat awal cluster. K-Means memiliki kemampuan dalam mengelompokkan data yang jumlahnya besar dengan waktu pemprosesan yang relative cukup cepat dan efisien. Namun, terdapat juga kelemahan dari K-Means yang diakibatkan dalam penentuan pusat awal cluster [14]. Hasil yang terbentuk dari algoritma K-Means ini sangat bergantung
pada pemilihan nilai pusat awal cluster. Tahapan dalam melakukan algoritma K-Means dijelaskan sebagai berikut [15]. 1. Menentukan K sebagai jumlah cluster yang akan dibentuk.
-
2. Menentukan k titik pusat awal cluster yang dilakukan secara acak. Penentuan pada awal centroid dilakukan secara acak dari data objek yang sudah tersedia sebanyak k cluster.
-
3. Menghitung jarak dari setiap data objek ke masing-masing centroid dari beberapa cluster yang ada dengan menggunakan metode perhitungan jarak Euclidean Distance.
-
4. Alokasikan masing-masing data objek ke dalam cluster dengan cara mengukur jarak kedekatan sifatnya terhadap titik pusat cluster.
-
5. Melakukan iterasi dan kemudian menentukan posisi centroid baru dengan menggunakan persamaan. Pusat cluster yang baru adalah nilai rata-rata dari semua objek data yang ada dalam cluster tertentu.
-
6. Ulangi proses perhitungan jika data objek masih berubah-ubah dan jika pusat cluster tidak berubah maka proses clustering algoritma K-Means dapat dikatakan selesai.
Metode Penelitian yang dilakukan akan menjelaskan tahapan penelitian dan objek penelitian yang akan dijelaskan sebagai berikut.
-
A. Tahapan Penelitian
Penelitian Clustering History Data Penjualan Menggunakan Algoritma K-Means dilakukan melalui beberapa tahapan yang terstruktur sehingga proses penelitian dapat dilakukan dengan lebih sistematis, terkontrol dan terarah. Gambar 1 menjelaskan bagaimana proses dilakukannya penerapan algoritma K-Means terhadap history data penjualan.
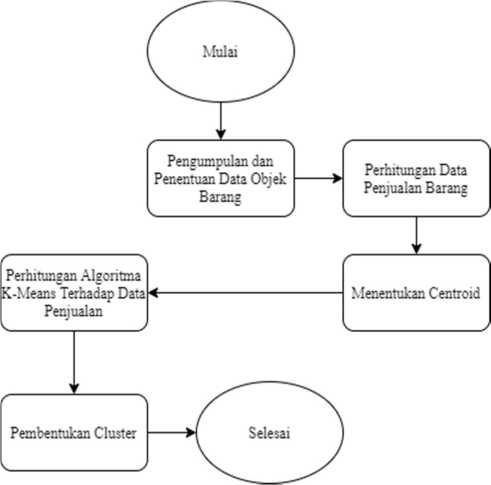
Gambar 1: Alur Proses Penerapan Algoritma K-Means Pada Data Penjualan
DOI: https://doi.org/10.24843/MITE.2021.v20i02.P03
Penjelasan dari tahapan penerapan algoritma K-Means yang dilkakukan adalah sebagai berikut.
-
• Pengumpulan dan penentuan data objek barang adalah tahap yang dilakukan untuk mengumpulkan data berupa data barang dari hasil penjulan seperti, laptop, komputer all in one, komputer desktop dan printer yang diambil antara tahun 2019-2020.
-
• Perhitungan data penjualan barang adalah proses perhitungan dari history penjualan yang telah dilakukan terlihat dari jumlah stok masuk, stok keluar dan sisa stok yang masih tersedia.
-
• Menentukan banyaknya cluster (k) dari jumlah dataset yang sudah dikumpulkan kemudian menentukan centroid yang biasanya dilakukan secara acak.
-
• Perhitungan algoritma K-Means terhadap data penjualan adalah melakukan perhitungan dengan menggunakan perhitungan jarak Euclidean Distance terhatap dataset yang sudah tersedia dengan centroid yang sudah ditentukan. Rumus yang digunakan dalam perhitungan jarak sebagai berikut.
d(xiuj} = J∑x^Uj) (1)
-
• Pembentukan cluster adalah setelah dilakukannya perhitungan maka dataset dikelompokkan berdasarkan kedekatan dengan centroid dan akan terbentuk clustercluster sesuai dengan jumlah cluster (k) yang ditentukan diawal.
-
B. Objek Penelitian
Objek penelitian adalah perusahaan X, sebuah perusahaan yang bergerak dalam bidang teknologi informasi dan telekomunikasi yang berlokasi di Provinsi Bali. Data diambil dari data history penjualan dengan dataset sebanyak 23 item barang yang termasuk dalam kategori laptop, komputer all in one, komputer desktop dan printer berdasarkan persediaan yang telah dilakukan dengan berbagai tipe dan jenis. Data berupa data kualitatif yang langsung dapat dihitung sebagai variable bilangan atau angka. Populasi data yang digunakan adalah data history penjualan dan data stok barang dari tahun 2019 sampai 2020.
Hasil dan pembahasan akan menjelaskan tahapan-tahapan dalam penerapan algoritma K-Means dari data history penjualan sehingga dapat membentuk sebuah cluster-cluster yang dapat mengkategorikan item barang dari data tersebut.
-
A. Perhitungan Algoritma K-Means
Langkah pertama dalam melakukan perhitungan dengan melakukan penentuan nilai centroid awal dan banyaknya cluster. Jumlah cluster ditentukan berdasarkan data penjualan yaitu diminati, cukup diminati dan kurang diminati. Data awal akan diolah ke dalam perhitungan algoritma K-Means memiliki 23 jenis barang sesuai kategori masing-masing barang yang
197
dapat dilihat pada Tabel 1 dan centroid awal (k) yang dapat diambil secara acak pada Tabel 2 sebagai berikut.
TABEL I
Data Penjualan
Yogiswara Dharma Putra: Clustering History Data Penjualan…
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

|
No |
Kategori |
Nama Barang |
Stok Masuk |
Stok Keluar |
Stok |
|
1 |
Laptop |
HP 240 G7 (I7, 4GB, 1TB, AMD 2GB, WIN10, 14IN) [6MC33PA] |
867 |
794 |
73 |
|
2 |
Laptop |
HP 240 G6 (i7, 4GB, 1TB, AMD 2GB, Win10, 14in) [4RK12PA] |
175 |
174 |
1 |
|
3 |
Laptop |
HP 240 G7 (I5, 4GB, 256GB SSD, AMD 2GB, WIN10, 14IN) [6MW37PA] |
124 |
124 |
0 |
|
4 |
Laptop |
HP Probook 430 G6 (I7, 8GB, 1TB, WIN10, 13.3IN) [4SP88AV] |
146 |
140 |
6 |
|
5 |
Laptop |
HP EliteBook 830 G5 (I7, 8GB, 1TB SSD, WIN10, 13.3IN) [2FZ84AV] |
65 |
32 |
33 |
|
6 |
PC AIO |
HP AIO 200 G3 (I3, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV35PA] |
897 |
806 |
91 |
|
7 |
PC AIO |
HP AIO 200 G3 (I5, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV36PA |
521 |
464 |
57 |
|
8 |
PC AIO |
HP AIO PROONE 600 G5 (I5, 8GB, 1TB HDD+256GB SSD, WIN10, 21.5IN) [6AE26AV-i5] |
891 |
793 |
98 |
|
9 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10PRO, 20IN) [5DD40PA] |
180 |
178 |
2 |
|
10 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10 PRO, 20IN) [5DD42PA] |
475 |
474 |
1 |
|
11 |
PC Dekstop |
HP PC 280 G4 MT (I5, 4GB, 1TB, NVIDIA 2GB, WIN10, 18.5IN) [2SJ42AV] |
163 |
109 |
54 |
|
12 |
PC Dekstop |
HP PC 280 G4 MT (I7, 8GB, 1TB, NVIDIA 2GB, WIN10, 20IN) [2SJ42AV] |
911 |
910 |
1 |
|
13 |
PC Dekstop |
HP PC 260 G3 DM (I3, 4GB, 1TB, WIN10, 18.5IN) [3XT51AV] |
993 |
962 |
31 |
|
14 |
PC Dekstop |
ACER VES2730 (I5, 8GB, 1TB, WIN10HOME, 18.5IN) |
80 |
35 |
45 |
|
15 |
PC Dekstop |
HP PC 280 G3 SFF (I3, 4GB, 1TB, WIN10, 19IN) [4LG46PA] |
432 |
425 |
7 |
|
16 |
Printer |
Epson EcoTank L3110 All-in-One Ink Tank Printer |
342 |
342 |
0 |
|
17 |
Printer |
EPSON PRINTER INKJET COLOR ECO TANK L5190 [C11CG85502] |
98 |
98 |
0 |
|
18 |
Printer |
EPSON EcoTank L3150 Wi-Fi All-in-One Ink Tank Printer |
125 |
117 |
8 |
|
19 |
Printer |
EPSON ECOTANK L1110 INK TANK PRINTER |
126 |
126 |
0 |
|
20 |
Printer |
EPSON L120 Ink Tank Printer |
19 |
18 |
1 |
|
21 |
Printer |
HP LaserJet Pro M402n |
9 |
4 |
5 |
|
22 |
Printer |
HP Laserjet M203d [G3Q50A] |
21 |
10 |
11 |
|
23 |
Printer |
HP Printer Laser 107w [4ZB78A] |
39 |
39 |
0 |
TABEL II
Centroid Awal
|
Centroid |
Stok Masuk |
Stok Keluar |
Stok |
|
C1 |
800 |
580 |
200 |
|
C2 |
500 |
450 |
300 |
|
C3 |
100 |
190 |
95 |
Selanjutnya dari tiga nilai centroid yang sudah ditentukan secara acak pada Tabel 2 dihitung jaraknya antara data awal dengan centroid menggunakan perhitungan jarak Euclidean Distance dan dikelompokkan berdasarkan kedekatannya sehingga nantinya akan terbentuk tiga cluster sesuai dengan jumlah centroid yang dibentuk. Pada iterasi 1 akan membentuk data seperti pada Tabel 3 sebagai berikut.
TABEL III
Iterasi 1
|
No |
Kategori |
Nama Barang |
Cluster | ||
|
1 |
2 |
3 | |||
|
1 |
Laptop |
HP 240 G7 (I7, 4GB, 1TB, AMD 2GB, WIN10, 14IN) [6MC33PA] |
257,7 |
551,9 |
976,5 |
|
2 |
Laptop |
HP 240 G6 (i7, 4GB, 1TB, AMD 2GB, Win10, 14in) [4RK12PA] |
771,4 |
520,8 |
121,3 |
|
3 |
Laptop |
HP 240 G7 (I5, 4GB, 256GB SSD, AMD 2GB, WIN10, 14IN) [6MW37PA] |
839,6 |
581,1 |
118,1 |
|
4 |
Laptop |
HP Probook 430 G6 (I7, 8GB, 1TB, WIN10, 13.3IN) [4SP88AV] |
811,8 |
554,8 |
112,0 |
|
5 |
Laptop |
HP EliteBook 830 G5 (I7, 8GB, 1TB SSD, WIN10, 13.3IN) [2FZ84AV] |
931,9 |
659,7 |
173,3 |
|
6 |
PC AIO |
HP AIO 200 G3 (I3, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV35PA] |
269,0 |
572,7 |
1007,3 |
Majalah Ilmiah Teknologi Elektro, Vol. 20, No. 2, Juli - Desember 2021
DOI: https://doi.org/10.24843/MITE.2021.v20i02.P03 199
|
7 |
PC AIO |
HP AIO 200 G3 (I5, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV36PA |
334,3 |
244,3 |
503,7 | ||||||||||||||
|
18 |
Printer |
EPSON EcoTank L3150 Wi-Fi All-in-One Ink Tank Printer |
840,7 |
580,3 |
116,3 | ||||||||||||||
|
8 |
PC AIO |
HP AIO PROONE 600 G5 (I5, 8GB, 1TB HDD+256GB SSD, WIN10, 21.5IN) [6AE26AV-i5] |
253,1 |
558,0 |
994,6 | ||||||||||||||
|
19 |
Printer |
EPSON ECOTANK L1110 INK TANK PRINTER |
836,9 |
578,7 |
117,5 | ||||||||||||||
|
20 |
Printer |
EPSON L120 Ink Tank Printer |
982,6 |
712,3 |
212,1 | ||||||||||||||
|
9 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10PRO, 20IN) [5DD40PA] |
765,0 |
515,0 |
123,3 |
21 |
Printer |
HP LaserJet Pro M402n |
997,7 |
726,0 |
225,8 | ||||||||
|
22 |
Printer |
HP Laserjet M203d [G3Q50A] |
983,6 |
711,7 |
213,8 | ||||||||||||||
|
23 |
Printer |
HP Printer Laser 107w [4ZB78A] |
954,9 |
686,6 |
188,5 | ||||||||||||||
|
10 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10 PRO, 20IN) [5DD42PA] |
395,6 |
301,0 |
479,7 | ||||||||||||||
|
Dari perhitungan iterasi 1 dihitung rata-rata nilai centroid-nya sehingga mendapatkan nilai centroid baru yang akan digunakan dalam perhitungan iterasi selanjutnya. Nilai rata-rata | |||||||||||||||||||
|
11 |
PC Dekstop |
HP PC 280 G4 MT (I5, 4GB, 1TB, NVIDIA 2GB, WIN10, 18.5IN) [2SJ42AV] |
805,6 |
538,9 |
110,5 |
pada iterasi 1 dapat dilihat pada Tabel 4 sebagai berikut. TABEL IV Centroid Baru | |||||||||||||
|
Nilai Rata-Rata |
Centroid |
Stok Masuk |
Stok Keluar |
Stok | |||||||||||||||
|
12 |
PC Dekstop |
HP PC 280 G4 MT (I7, 8GB, 1TB, NVIDIA 2GB, WIN10, 20IN) [2SJ42AV] |
401,0 |
685,5 |
1088,6 |
C1 |
915,5 |
864,75 |
50,75 | ||||||||||
|
C2 |
581,25 |
542,25 |
39 | ||||||||||||||||
|
C3 |
114,133 |
103,066 |
11,066 | ||||||||||||||||
|
13 |
PC Dekstop |
HP PC 260 G3 DM (I3, 4GB, 1TB, WIN10, 18.5IN) [3XT51AV] |
460,1 |
760,0 |
1182,2 |
Kemudian ulangi proses perhitungan algoritma K-Means seperti pada iterasi 1 sehingga mendapatkan anggota cluster yang tidak berubah maka iterasi dapat dikatakan berhenti atau sampai pada tahap terakhir. Pada penelitian ini iterasi berhenti pada iterasi 4 yang tidak terjadi perubahan pada anggota cluster yang ditunjukkan pada Tabel 5 sebagai berikut. TABEL V Iterasi 4 | |||||||||||||
|
14 |
PC Dekstop |
ACER VES2730 (I5, 8GB, 1TB, WIN10HOME, 18.5IN) |
916,2 |
643,2 |
164,1 | ||||||||||||||
|
15 |
PC Dekstop |
HP PC 280 G3 SFF (I3, 4GB, 1TB, WIN10, 19IN) [4LG46PA] |
443,5 |
301,8 |
416,2 |
No |
Kategori |
Nama Barang |
Cluster | ||||||||||
|
1 |
2 |
3 | |||||||||||||||||
|
1 |
Laptop |
HP 240 G7 (I7, 4GB, 1TB, AMD 2GB, WIN10, 14IN) [6MC33PA] |
75,4 |
564,5 |
1047,2 | ||||||||||||||
|
16 |
Printer |
Epson EcoTank L3110 All-in-One Ink Tank Printer |
553,5 |
355,8 |
301,2 | ||||||||||||||
|
2 |
Laptop |
HP 240 G6 (i7, 4GB, 1TB, AMD 2GB, Win10, 14in) [4RK12PA] |
1003,6 |
368,0 |
117,5 | ||||||||||||||
|
17 |
Printer |
EPSON PRINTER INKJET COLOR ECO TANK L5190 [C11CG85502] |
874,7 |
612,8 |
132,3 | ||||||||||||||
Yogiswara Dharma Putra: Clustering History Data Penjualan…
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

|
3 |
Laptop |
HP 240 G7 (I5, 4GB, 256GB SSD, AMD 2GB, WIN10, 14IN) [6MW37PA] |
1075,0 |
439,4 |
47,6 |
13 |
PC Dekstop |
HP PC 260 G3 DM (I3, 4GB, 1TB, WIN10, 18.5IN) [3XT51AV] |
138,7 |
768,3 |
1252,6 | ||||
|
14 |
PC Dekstop |
ACER VES2730 (I5, 8GB, 1TB, WIN10HOME, 18.5IN) |
1166,7 |
534,1 |
63,4 | ||||||||||
|
4 |
Laptop |
HP Probook 430 G6 (I7, 8GB, 1TB, WIN10, 13.3IN) [4SP88AV] |
1047,7 |
412,3 |
72,6 | ||||||||||
|
15 |
PC Dekstop |
HP PC 280 G3 SFF (I3, 4GB, 1TB, WIN10, 19IN) [4LG46PA] |
645,0 |
14,0 |
476,0 | ||||||||||
|
5 |
Laptop |
HP EliteBook 830 G5 (I7, 8GB, 1TB SSD, WIN10, 13.3IN) [2FZ84AV] |
1179,7 |
546,1 |
66,7 | ||||||||||
|
16 |
Printer |
Epson EcoTank L3110 All-in-One Ink Tank Printer |
767,6 |
132,1 |
354,0 | ||||||||||
|
6 |
PC AIO |
HP AIO 200 G3 (I3, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV35PA] |
58,9 |
597,0 |
1078,6 | ||||||||||
|
17 |
Printer |
EPSON PRINTER INKJET COLOR ECO TANK L5190 [C11CG85502] |
1111,6 |
476,1 |
16,9 | ||||||||||
|
7 |
PC AIO |
HP AIO 200 G3 (I5, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV36PA |
551,4 |
96,2 |
569,2 | ||||||||||
|
18 |
Printer |
EPSON EcoTank L3150 Wi-Fi All-in-One Ink Tank Printer |
1078,6 |
443,3 |
41,4 | ||||||||||
|
8 |
PC AIO |
HP AIO PROONE 600 G5 (I5, 8GB, 1TB HDD+256GB SSD, WIN10, 21.5IN) [6AE26AV-i5] |
74,6 |
585,1 |
1066,0 | ||||||||||
|
19 |
Printer |
EPSON ECOTANK L1110 INK TANK PRINTER |
1072,1 |
436,6 |
50,3 | ||||||||||
|
20 |
Printer |
EPSON L120 Ink Tank Printer |
1223,8 |
588,4 |
104,7 | ||||||||||
|
9 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10PRO, 20IN) [5DD40PA] |
997,2 |
361,6 |
123,7 | ||||||||||
|
21 |
Printer |
HP LaserJet Pro M402n |
1240,5 |
605,3 |
121,1 | ||||||||||
|
22 |
Printer |
HP Laserjet M203d [G3Q50A] |
1227,4 |
592,4 |
108,1 | ||||||||||
|
23 |
Printer |
HP Printer Laser 107w [4ZB78A] |
1194,9 |
559,5 |
76,2 | ||||||||||
|
10 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10 PRO, 20IN) [5DD42PA] |
581,2 |
59,7 |
541,2 | ||||||||||
|
Pada iterasi 4 dihitung nilai rata-rata centroid-nya dan mendapatkan hasil nilai centroid yang tidak berubah seperti pada Tabel 6 sebagai berikut. TABEL VI Centroid Terakhir | |||||||||||||||
|
11 |
PC Dekstop |
HP PC 280 G4 MT (I5, 4GB, 1TB, NVIDIA 2GB, WIN10, 18.5IN) [2SJ42AV] |
1055,6 |
424,5 |
80,9 | ||||||||||
|
Nilai Rata-Rata |
Centroid |
Stok Masuk |
Stok Keluar |
Stok | |||||||||||
|
12 |
PC Dekstop |
HP PC 280 G4 MT (I7, 8GB, 1TB, NVIDIA 2GB, WIN10, 20IN) [2SJ42AV] |
81,2 |
673,6 |
1157,7 | ||||||||||
|
C1 |
911,8 |
853 |
58,8 | ||||||||||||
|
C2 |
442,5 |
426,25 |
16,25 | ||||||||||||
|
C3 |
97,857 |
86 |
11,85714 | ||||||||||||
|
Majalah Ilmia DOI: https://d Grafik ter perhitungan |
h Teknologi Elektro, Vol. 20, No. 2, J oi.org/10.24843/MITE.2021.v20i02.P kahir yang dapat dilihat setelah algoritma K-Means menunjukkan cluster dari setiap item barang se agai berikut. |
uli - Desember 2021 03 201 | |||||||||||
|
melakukan hasil dari |
Printer |
Epson EcoTank L3110 All-in-One Ink Tank Printer | |||||||||||
|
pemb Gamb |
entukan ar 2 seb |
perti |
pada |
TABEL IX Cluster 3 | |||||||||
|
♦ Cl I 1200 1000 800 600 400 200 0 |
■ C2 ▲ C3 X Pusat Cl X Pus |
at C2 • Pusat |
C3 00 |
Cluster 3 | |||||||||
|
«' |
Kurang Diminati |
Laptop |
HP 240 G6 (i7, 4GB, 1TB, AMD 2GB, Win10, 14in) [4RK12PA] | ||||||||||
|
■ |
Laptop |
HP 240 G7 (I5, 4GB, 256GB SSD, AMD 2GB, WIN10, 14IN) [6MW37PA] | |||||||||||
|
500 1000 15 |
Laptop |
HP Probook 430 G6 (I7, 8GB, 1TB, WIN10, 13.3IN) [4SP88AV] | |||||||||||
|
Laptop |
HP EliteBook 830 G5 (I7, 8GB, 1TB SSD, WIN10, 13.3IN) [2FZ84AV] | ||||||||||||
|
Gambar 2: Grafik Cluster Data n hasil dari perhitungan algoritma K-M tersebut mewakili tingkat penjualan memiliki kategori sangat diminati, di ati yang dapat ditunjukkan pada t t. TABEL VII Cluster 1 | |||||||||||||
|
Berdasarka ketiga cluster barang yang kurang dimin sebagai beriku |
eans maka dari item minati dan abel 7,8,9 |
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10PRO, 20IN) [5DD40PA] | ||||||||||
|
PC Dekstop |
HP PC 280 G4 MT (I5, 4GB, 1TB, NVIDIA 2GB, WIN10, 18.5IN) [2SJ42AV] | ||||||||||||
|
PC Dekstop |
ACER VES2730 (I5, 8GB, 1TB, WIN10HOME, 18.5IN) | ||||||||||||
|
Cluster 1 | |||||||||||||
|
Sangat Diminati |
Laptop |
HP 240 G7 (I7, 4GB, 1TB, AMD 2GB, WIN10, 14IN) [6MC33PA] | |||||||||||
|
Printer |
EPSON PRINTER INKJET COLOR ECO TANK L5190 [C11CG85502] | ||||||||||||
|
PC AIO |
HP AIO 200 G3 (I3, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV35PA] | ||||||||||||
|
Printer |
EPSON EcoTank L3150 Wi-Fi All-in-One Ink Tank Printer | ||||||||||||
|
PC AIO |
HP AIO PROONE 600 G5 (I5, 8GB, 1TB HDD+256GB SSD, WIN10, 21.5IN) [6AE26AV-i5] |
Printer |
EPSON ECOTANK L1110 INK TANK PRINTER | ||||||||||
|
Printer |
EPSON L120 Ink Tank Printer | ||||||||||||
|
PC Dekstop |
HP PC 280 G4 MT (I7, 8GB, 1TB, NVIDIA 2GB, WIN10, 20IN) [2SJ42AV] | ||||||||||||
|
Printer |
HP LaserJet Pro M402n | ||||||||||||
|
Printer |
HP Laserjet M203d [G3Q50A] | ||||||||||||
|
PC Dekstop |
HP PC 260 G3 DM (I3, 4GB, 1TB, WIN10, 18.5IN) [3XT51AV] | ||||||||||||
|
Printer |
HP Printer Laser 107w [4ZB78A] | ||||||||||||
TABEL VIII Cluster 2
|
Cluster 2 | ||
|
Diminati |
PC AIO |
HP AIO 200 G3 (I5, 4GB, 1TB, WIN10, 21.5IN, 1 Year) [4FV36PA |
|
PC AIO |
HP AIO PROONE 400 G4 (I5, 4GB, 1TB, WIN10 PRO, 20IN) [5DD42PA] | |
|
PC Dekstop |
HP PC 280 G3 SFF (I3, 4GB, 1TB, WIN10, 19IN) [4LG46PA] | |
Yogiswara Dharma Putra: Clustering History Data Penjualan…
Cluster 1,2,3 menunjukkan hasil dari pembentukan cluster dari penerapan algoritma K-Means. Hasil tersebut memperlihatkan item barang yang memiliki tingkat penjualan berdasarkan dari data awal yang telah diolah. Pada cluster 1 memiliki 5 jumlah item barang, cluster 2 memiliki 4 jumlah item barang dan cluster 3 memiliki 14 item barang yang memperhitungkan history penjualan dari tahun 2019 sampai 2020. Stok masuk, stok keluar dan sisa stok yang tersedia menjadi faktor utama dalam penentuan dari item barang yang memiliki tingkat penjualan yang paling diminati, karena perhitungan dilakukan menggunakan data dua tahun penjualan
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

sehingga memperlihatkan dari jumlah barang yang masuk dan keluar.
Berdasarkan hasil yang didapatkan menggunakan algoritma K-Means pada 23 item data penjualan dari persediaan barang yang telah dilakukan dari tahun 2019 sampai 2020 dengan kategori barang laptop, komputer dan printer yang menghasilkan 3 cluster yang di interpretasikan sangat diminati, diminati dan kurang diminati. Dari 3 cluster yang terbentuk dengan titik centoid awal yaitu C1 (800, 580,200), C2 (500, 450, 300) dan C3 (100, 190, 95) maka proses akhir berhenti pada iterasi ke 4 yang mendapatkan data pada cluster 1 atau sangat diminati memiliki 5 barang, cluster 2 atau diminati memiliki 4 barang dan cluster 3 atau kurang diminati memiliki 14 barang yang memiliki titik centroid akhir yaitu C1 (911.8, 853, 58.8), C2 (442.5, 426.25, 16.25) dan C3 (97.85, 86, 11.85).
Referensi
-
[1] S. Samudi, S. Widodo, and H. Brawijaya, “The K-Medoids Clustering Method for Learning Applications during the COVID-19 Pandemic,” SinkrOn, vol. 5, no. 1, p. 116, 2020, doi: 10.33395/sinkron.v5i1.10649.
-
[2] A. Primandana, S. Adinugroho, and C. Dewi, “Optimasi Penentuan Centroid pada Algoritme K-Means Menggunakan Algoritme Pillar (Studi Kasus: Penyandang Masalah Kesejahteraan Sosial di Provinsi …,” … Teknol. Inf. dan Ilmu …, vol. 3, no. 11, pp. 10678–10683, 2020, [Online]. Available: http://j-ptiik.ub.ac.id/index.php/j-
ptiik/article/download/6748/3264.
-
[3] A. W. Oktavia Gama, I. K. Gede Darma Putra, and I. P. Agung Bayupati, “Implementasi Algoritma Apriori Untuk Menemukan Frequent Itemset Dalam Keranjang Belanja,” Maj. Ilm. Teknol. Elektro, vol. 15, no. 2, pp. 21–26, 2016, doi: 10.24843/mite.1502.04.
-
[4] S. S. Nagari and L. Inayati, “Implementation of Clustering Using K-Means Method To Determine Nutritional Status,” J. Biometrika dan Kependud., vol. 9, no. 1, p. 62, 2020, doi: 10.20473/jbk.v9i1.2020.62-68.
-
[5] S. Saefudin and D. Fernando, “Penerapan Data Mining Rekomendasi Buku Menggunakan Algoritma Apriori,” JSiI (Jurnal Sist. Informasi), vol. 7, no. 1, p. 50, 2020, doi: 10.30656/jsii.v7i1.1899.
-
[6] I. Parlina, W. Agus Perdana, W. Anjar, and L. M.Ridwan, “Memanfaatkan Algoritma K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Center,” Memanfaatkan Algoritm. K-Means Dalam Menentukan Pegawai Yang Layak Mengikuti Asessment Cent. Untuk Clust. Progr. Sdp, vol. 3, no. 1, pp. 87–93, 2018.
-
[7] M. S. Mustafa, M. R. Ramadhan, and A. P. Thenata, “Implementasi Data Mining untuk Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naive Bayes Classifier,” Creat. Inf. Technol. J., vol. 4, no. 2, p. 151, 2018, doi: 10.24076/citec.2017v4i2.106.
-
[8] H. Priyatman, F. Sajid, and D. Haldivany, “Klasterisasi Menggunakan Algoritma K-Means Clustering untuk Memprediksi Waktu Kelulusan Mahasiswa,” J. Edukasi dan Penelit. Inform., vol. 5, no. 1, p. 62, 2019, doi: 10.26418/jp.v5i1.29611.
-
[9] I. S. Melati, L. Linawati, and I. A. . Giriantari, “Knowledge Discovery Data Akademik Untuk Prediksi Pengunduran Diri Calon Mahasiswa,” Maj. Ilm. Teknol. Elektro, vol. 17, no. 3,
-
p. 325, 2018, doi: 10.24843/mite.2018.v17i03.p04.
-
[10] E. Ainun, W. Isti, and S. Fachri, “Implementasi Algoritma K - Means Clustering Tingkat Kepentingan Tagihan Rumah Sakit Di Pt Pertamina ( Persero ),” 2020.
-
[11] A. A. G. B. Ariana, I. K. G. Darma Putra, and L. Linawati, “Perbandingan Metode SOM/Kohonen dengan ART 2 pada Data Mining Perusahaan Retail,” Maj. Ilm. Teknol. Elektro, vol. 16, no. 2, p. 55, 2017, doi:
10.24843/mite.2017.v16i02p10.
-
[12] M. Pasek, A. Ariawan, N. P. Sastra, and I. M. Sudarma, “K-Mean s Clustering Dan Local Outlier Factor,” vol. 19, no. 1, 2020.
-
[13] N. G. Yudiarta, M. Sudarma, and W. G. Ariastina, “Penerapan Metode Clustering Text Mining Untuk Pengelompokan Berita Pada Unstructured Textual Data,” Maj. Ilm. Teknol. Elektro, vol. 17, no. 3, p. 339, 2018, doi: 10.24843/mite.2018.v17i03.p06.
-
[14] S. Butsianto and N. T. Mayangwulan, “Penerapan Data Mining Untuk Prediksi Penjualan Mobil Menggunakan Metode K-Means Clustering,” J. Nas. Komputasi dan Teknol. Inf., vol. 3, no. 3, pp. 187–201, 2020, doi: 10.32672/jnkti.v3i3.2428.
-
[15] G. Gustientiedina, M. H. Adiya, and Y. Desnelita, “Penerapan Algoritma K-Means Untuk Clustering Data Obat-Obatan,” J. Nas. Teknol. dan Sist. Inf., vol. 5, no. 1, pp. 17–24, 2019, doi: 10.25077/teknosi.v5i1.2019.17-24.
-
[16] Y. K. Siregar, “Analisis perbandingan algoritma,” vol. 2, no.
-
1, pp. 151–155, 2019.
-
[17] A. A. Rismayadi, N. N. Fatonah, dan Erfin Junianto, “Algoritma K-Means Clustering Untuk Menentukan Strategi Pemasaran Di CV. Integreet Konstruksi,” Jurnal Responsif, vol. 3, no. 1, pp. 30–36, 2021, [Online]. Available: http://ejurnal.ars.ac.id/index.php/jti/article/view/393.
-
[18] O. N. Pratiwi, “Analisa Perbandingan Algoritma K-Means, Decision Tree, Dan Naïve Bayes Untuk Sistem Pengelompokkan Siswa Otomatis,”Jurnal Ilmiah Teknologi Informasi Terapan., vol. II, no. 2, pp. 109–118, 2016.
-
[19] R. A. M. S. D. Yuhandri, “Perbandingan Algoritma K-Means Clustering Dengan Fuzzy C- Means Dalam Mengukur Tingkat Kepuasan Terhadap Televisi Dakwah Suaru TV,” Jurnal Teknologi dan Sistem Informasi Univrab, vol. 3, no. 1, pp. 10–21, 2018.
-
[20] M. Y. Rizki, S. Maysaroh, and A. P. Windarto, “Implementasi K-Means Clushtering Dalam Mengelompokkan Minat Membaca Penduduk Menurut Wilayah,” JUST IT Jurnal Sistem Informasi, Teknologi Informasi dan Komputer, vol. 11, no. 2, pp. 41–49, 2021, [Online]. Available: https://jurnal.umj.ac.id/index.php/just-it/article/view/5902.
-
[21] N. A. S. Damanik, Irianto, dan Dahriansah “Penerapan Metode Clustering Dengan Algoritma K-Means Tindakan Kejahatan Pencurian di Kabupaten Asahan.,”J-Com (Journal of Computer) vol. 1, no. 1, pp. 7–14, 2021, [Online]. Available: http:// jurnal.stmikroyal.ac.id/index.php/j-com
ISSN 1693 – 2951
Yogiswara Dharma Putra: Clustering History Data Penjualan…
Discussion and feedback