Analisa Sentiment Untuk Opini Alumni Perguruan Tinggi
on
Majalah Ilmiah Teknologi Elektro, Vol. 18, No. 2, Mei - Agustus 2019
DOI: https://doi.org/10.24843/MITE.2019.v18i02.P11 227
Analisa Sentiment Untuk Opini Alumni Pada Perguruan Tinggi
I Komang Dharmendra1, Komang Oka Saputra 2, Nyoman Pramaita 3
[Submission: 09-04-2019, Accepted: 30-06-2019]
Abstract— Opinion is one of the most important parts in decision making, in processing opinions require a thorough analysis process. Especially text-based opinion, where opinion in the form of opinions do not have a definite value limit for the input. Sentiment Analysis as a branch of knowledge from Text mining can be applied in the opinion analysis process in the form of text. Where opinions will be classified into 3 types of opinions, namely positive opinions, neutral opinions and negative opinions. This study grouped opinions from university graduated students using the SVM and NBC algorithms which in this study were divided into 3 main components, namely the input component, opinion grouping system, and output components.Opinion to be processed is data in the form of a * .csv format opinion file, which then conducts a grouping of opinions. Then the system produces output in the form of 3 types of opinions, namely, positive opinions, neutral opinions and negative opinions. In general, the accuracy results show the differences in the accuracy of each sentiment. From the test results generally shows the accuracy with the highest accuracy value in the NBC algorithm reaching 94.45 while the highest accuracy rate in the SVM algorithm reaches 75.76%.
Intisari— Opini merupakan salah satu bagian terpenting dalam pengambilan keputusan, dalam pengolahan opini memerlukan proses analisa yang menyeluruh. Terutama opini yang berbasis teks, dimana opini berupa pendapat tidak memiliki batasan nilai pasti untuk masukan yang diberikan. Sentiment Analysis sebagai cabang ilmu dari Text mining bisa diterapkan dalam proses analisa opini yang berupa teks. Dimana opini akan diklasifikasikan menjadi 3 jenis opini, yaitu opini positif, opini netral dan opini negative. Penelitian ini melakukan pengelompokan opini dari alumni Perguruan Tinggi dengan menggunakan algoritma SVM dan NBC dimana dalam penelitian ini dibagi menjadi 3 komponen utama yaitu komponen input, sistem pengelompokan opini, serta komponen output. Opini yang akan diolah merupakan data berupa file opini format *.csv, yang selanjutnya melakukan proses pengelompokan terhadap opini. Kemudian sistem menghasilkan output berupa 3 jenis opini yaitu, opini positif, opini netral dan opini negative. Dari hasil pengujian secara umum menunjukkan akurasi dengan nilai akurasi tertinggi pada algoritma NBC mencapai 94,45%, sedangkan tingkat akurasi tertinggi pada algoritma SVM mencapai 75,76%. Kata Kunci— Opini, Sentiment Analysis, SVM, NBC.
Dalam dunia pendidikan peranan sekolah tinggi memegang peranan yang penting, sebagai jenjang tingkat lanjut setelah Sekolah Menengah Atas, sekolah tinggi perlu terus melakukan peningkatan mutu dan kualitas sekolah tinggi itu sendiri. Seorang pimpinan yang memiliki wewenang mengambil keputusan tertinggi, memerlukan data pendukung dalam pengambilan setiap keputusan yang berupa data asli (fakta) ataupun opini[1]. Salah satu komponen sekolah tinggi yang bisa memberikan opini adalah para mahasiswa yang akan menyelesaikan pendidikan di sekolah tinggi, karena opini yang disampaikan dari mahasiswa tersebut adalah hal yang dialami selama menempuh pendidikan.
Opini atau orientasi opini adalah salah satu bagian penting dalam pengambilan keputusan[2]. analisis opini dari sumber terkait sangat mempengaruhi bagaimana pengambilan sebuah keputusan. Salah satunya adalah pengukuran tingkat kepuasan layanan yang dilakukan pada perguruan tinggi yang dilakukan secara rutin oleh pihak penyelenggara pendidikan. Diantaranya yang dilakukan melalui opini yang sengaja dikumpulkan dengan meminta mahasiswa yang baru selesai menyelesaikan masa studi untuk mengisi kuisioner.
Sentiment Analysis merupakan salah satu metode yang umum digunakan untuk melakukan proses ekstraksi dan klasifikasi opini. Pada analisis sentiment dilakukan untuk mengetahui sifat pada dokumen, kalimat atau fitur entitas / aspek, apakah bersifat positif, negatif atau netral dengan mengelompokkan polaritas pada teks yang terdapat didalam kalimat. Berbagai macam algoritma dapat diterapkan dalam melakukan sentiment analysis. Seperti yang dilakukan oleh Esther Irawati Setiawan, dimana dalam penelitianya menerapkan 3 algoritma yaitu Baseline, Naïve Bayes, dan Maximum Entropy [3]. Sedangkan Noviah Dwi Putranti dan Edi Winarko dalam penelitianya yang berjudul Analisis Sentimen Twitter untuk Teks Berbahasa Indonesia dengan Maximum Entropy dan Support Vector Machine menerapkan dua algoritma yaitu Entropy dan Support Vector Machine dalam melakukan proses analisi sentimen [4].
Berdasarkan pemaparan penjelasan latar belakang tersebut maka penelitian ini dilakukan untuk dapat mengelompokkan opini ke dalam tiga jenis sentiment. Sistem ini akan dibangun berdasarkan pengelompokkan parameter opini yang diperoleh dengan menggunakan algoritma Naïve Bayes Classification dan Support Vector Machines. Sistem ini nantinya diharapkan dapat membantu penggunanya untuk menemukan kategori sentiment apa yang terkandung dalam sebuah opini. Perlu diperhatikan juga bahwa dataset yang digunakan adalah data yang dibangun sendiri dengan melibatkan doktor pada bidang linguistik (sastra Indonesia).
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

-
a. Sentiment Analysis
Sentiment analysis atau opinion mining mengacu pada bidang yang luas dari pengolahan bahasa alami, komputasi linguistik dan text mining. Secara umum, bertujuan untuk menentukan attitude pembicara atau penulis berkenaan dengan topik tertentu[5]. Attitude penilaian atau evaluasi pembicara, pernyataan afektif (pernyataan emosional penulis saat menulis) atau komunikasi emosional dimaksud (efek emosional yang penulis inginkan terhadap pembaca)
Tugas dasar dalam analisis sentimen adalah mengelompokkan polaritas dari teks yang ada dalam dokumen, kalimat, atau fitur / tingkat aspek - apakah pendapat yang dikemukakan dalam dokumen, kalimat atau fitur entitas / aspek bersifat positif, negatif atau netral. Lebih lanjut sentiment analysis dapat menyatakan emosional sedih, gembira, atau marah[6].
-
b. Naïve Bayes Classifier
Sebuah bayes classifier adalah classifier probabilistik sederhana berdasarkan penerapan teorema Bayes (dari statistik Bayesian) dengan asumsi independen (naif) yang kuat[7]. Sebuah istilah yang lebih deskriptif untuk model probabilitas yang digaris bawahi adalah "model fitur independen". Dalam terminologi sederhana, sebuah NBC mengasumsikan bahwa kehadiran (atau ketiadaan) fitur tertentu dari suatu kelas tidak berhubungan dengan kehadiran (atau ketiadaan) fitur lainnya. Sebagai contoh, buah mungkin dianggap apel jika merah, bulat, dan berdiameter sekitar 4 inchi. Bahkan jika fitur ini bergantung satu sama lain atau atas keberadaan fitur lain. Sebuah NBC menganggap bahwa seluruh sifat-sifat berkontribusi mandiri untuk probabilitas bahwa buah ini adalah apel.
Sebuah keuntungan dari NBC adalah bahwa NBC memerlukan sejumlah kecil data pelatihan untuk mengestimasi parameter (rata-rata dan varian dari variabel) yang diperlukan untuk klasifikasi. Karena variabel diasumsikan independen, hanya varian dari variabel-variabel untuk setiap kelas yang perlu ditentukan dan bukan keseluruhan covariance matrix.
-
c. Support Vector Machines
Support Vector Machine (SVM) juga merupakan suatu teknik yang relatif baru dikenalkan tahun 1995 untuk melakukan prediksi, baik dalam kasus klasifikasi maupun regresi, yang sangat populer belakangan ini. SVM berada dalam satu kelas dengan Artificial Neural Network (ANN) dalam hal fungsi dan kondisi permasalahan yang bisa diselesaikan[8]. Keduanya masuk dalam kelas supervised learning[9]. Baik para ilmuwan maupun praktisi telah banyak menerapkan teknik ini dalam menyelesaikan permasalahan nyata dalam kehidupan sehari-hari. Terbukti dalam banyak implementasi, SVM memberi hasil yang lebih baik dari ANN, terutama dalam hal solusi yang dicapai. ANN menemukan solusi berupa local optimal sedangkan SVM menemukan solusi yang global optimal. Tidak heran apabila menjalankan ANN solusi dari setiap training selalu berbeda. Hal ini disebabkan solusi local optimal yang dicapai tidak selalu sama. SVM selalu mencapi solusi yang sama untuk setiap running.
Dalam teknik ini, dilakukan fungsi pemisah (classifier) yang optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda.
Metode Penelitian
Dalam melakukan analisa sentiment opini alumni dengan
Referensi
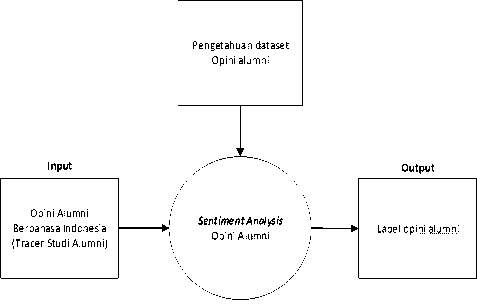
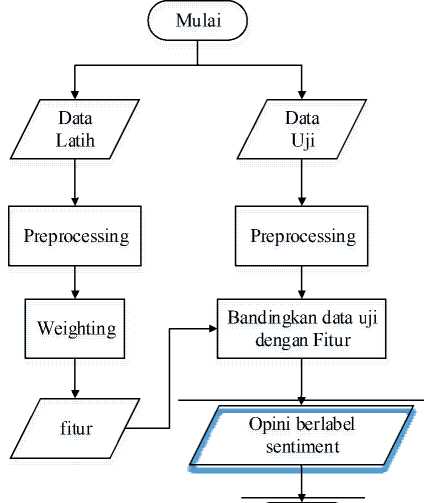
Gambar 1. Blok diagram sistem analisa sentiment opini alumni
menggunakan algoritma Support Vector Machines dan Naïv e Bayes Classification ini memiliki 3 komponen utama yaitu komponen input, analisa sentimen, dan komponen output yaitu opini dengan label opini yang dapat dilihat pada Gambar 1.
masukan (input data) berupa kalimat opini berbahasa Indonesia, yang selanjutnya sistem melakukan proses pengelompokan opini dengan mengggunakan algoritma Support Vector Machines dan Naïve Bayes Classification. Kemudian sistem menghasilkan output berupa opini dengan label jenis yaitu 1) positif, 2) negatif, dan 3) netral. Selanjutnya alur lebih detail dari pembuatan analisa opini ini memiliki beberapa tahapan yang dapat dilihat pada Gambar 2.
Terdapat beberapa proses yang sangat penting yaitu akuisisi data, preprocessing, dan proses sentiment analysis menggunakan algoritma Naïve Bayes Classification dan Support Vector Machines.
Pada akusisi data dilakukan perapian data dengan cara mengubah struktur bahasa dan kata-kata yang digunakan sehingga sesuai dengan kaedah Bahasa Indonesia tanpa merubah makna dan isi dari opini. Dalam preprocessing secara umum proses yang dilakukan adalah case folding, tokenizing dan filtering dan stemming. Contoh opini yang digunakan dan diolah menggunakan preprocessing ditunjukkan oleh tabel 1.
Majalah Ilmiah Teknologi Elektro, Vol. 18, No. 2, Mei - Agustus 2019 DOI: https://doi.org/10.24843/MITE.2019.v18i02.P0X
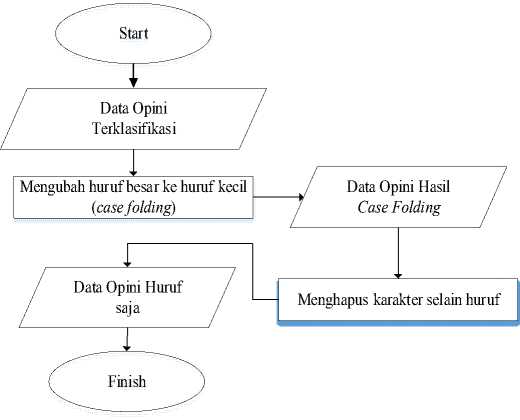
Gambar 3 Flowchart Proses Case Folding
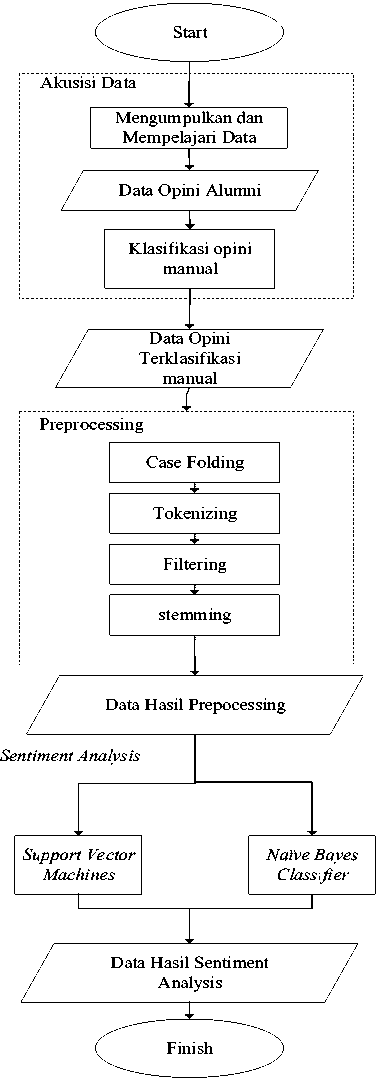
Gambar 2 Flowchart Proses Sentiment Analysis
-
a) Case Folding
Opini yang telah dibersihkan pada tahap sebelumnya kemudian semua karakternya diubah menjadi huruf kecil. Selain itu karakter selain huruf “a” hingga “z‟ akan dihapus. Hal ini karena karakter selai huruf tersebut dianggap sebagai delimiter, termasuk angka dan tanda baca[10].
-
b) Tokenizing
Opini yang telah diolah pada tahap sebelumnya harus dipecah menjadi token/kata. Sebuah opini dipecah menjadi token dengan menggunakan karakter whitespace sebagai pemecahnya. Hasil token-token ini yang selanjutnya akan disimpan menjadi fitur pada masing-masing kelas.
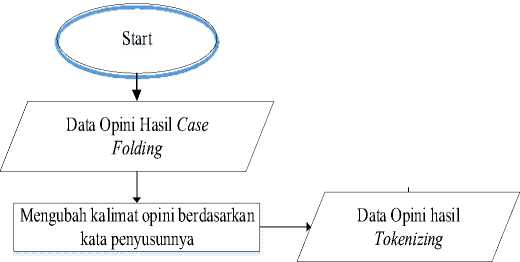
Gambar 4 Flowchart Proses Tokenizing
-
c) Filtering
Tahap filtering dilakukan dengan mengambil kata-kata yang dianggap penting setelah tokenizing selesai. Hal ini dilakukan dengan menghapus stopword atau kata-kata tidak deskriptif yang bukan merupakan kata unik yang mencirikan suatu kategori tertentu[11]. Proses ini dilakukan berdasarkan stoplist yang berisi stopword yang telah ditentukan sebelumnya. Kemudian kata yang terdapat pada opini akan dibandingkan dengan daftar stopword, jika terdapat kata-kata yang berada dalam stopword maka kata tersebut akan dihapus dari opini. Kata-kata yang termasuk ke dalam stopword dihilangkan karena terlalu sering muncul dalam dokumen dan bukan merupakan pembeda yang baik dalam proses penggalian teks
I Komang Dharmendra dkk: Analisa Sentiment Untuk Opini…
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

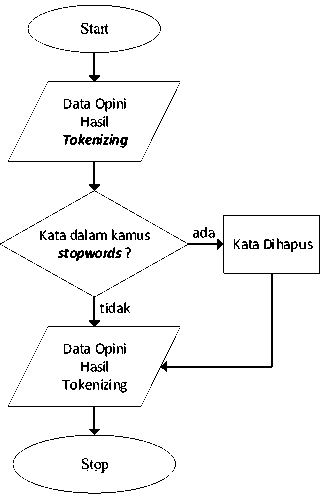
Gambar 5 Flowchart Proses Filtering
-
d) stemming
Stemming adalah proses pengembalian bentuk kata dasar dari suatu kata berimbuhan[12]. Proses ini akan menghilangkan awalan, akhiran, sisipan dan confixes (kombinasi dari awalan dan akhiran). Proses ini memiliki banyak fariasi sesuai domain bahasa yang digunakan, karena imbuhan tiap bahasa berbeda-beda. Proses stemming pada penelitian ini menggunakan library Sastrawi sehingga tidak perlu lagi melakukan pengecekan setiap kata untuk mendapatkan kata dasarnya karena teks berbahasa Indonesia[13]. berbeda dengan stemming pada teks berbahasa Inggris, pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan, namun pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks.
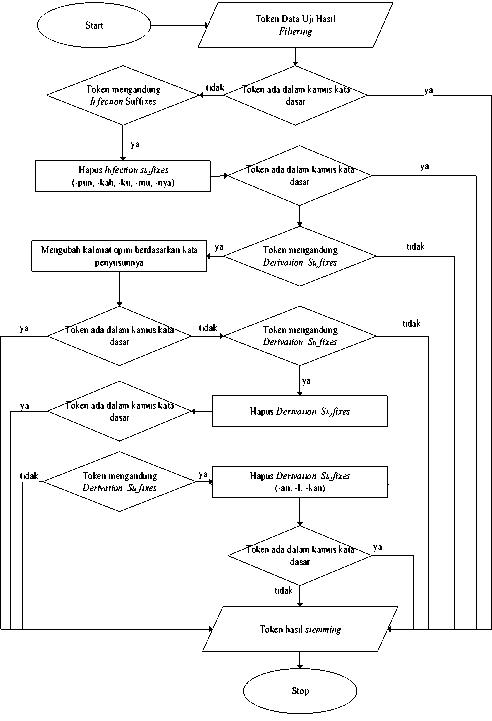
Gambar 6 Flowchart Proses Stemming
Tahapan sentiment analysis dilakukan dalam dua jenis analisa, yaitu dengan analisa algoritma Naïve Bayes Classification dan algoritma Support Vector Machines. Dari analisa data akan menghasilkan opini sentiment yang telah memiliki label sentiment.
A. Analisa Sentiment Menggunakan Naïve Bayes Classification
Tabel 1
Contoh prepocessing opini
|
Tahapan |
Contoh Prepocessing |
|
Kalimat Asli |
Ruang kelas dalam kondisi baik, dan selalu dibersihkan setelah selesai untuk dipakai oleh kelas selanjutnya |
|
Case Folding |
ruang kelas dalam kondisi baik dan selalu dibersihkan setelah selesai untuk dipakai oleh kelas selanjutnya |
|
Tokenizing |
ruang | kelas | dalam | kondisi | baik | dan | selalu | dibersihkan | setelah | selesai | untuk | dipakai | oleh | kelas | selanjutnya |
|
Filtering |
ruang | kelas | kondisi | baik | dibersihkan | setelah | selesai | dipakai | kelas | selanjutnya |
|
Stemming |
ruang | kelas | kondisi | baik | bersih | selesai | pakai | kelas | lanjut |
DOI: https://doi.org/10.24843/MITE.2019.v18i02.P0X
Pada tahap klasifikasi, data uji yang telah melewati tahap prepocessing akan dilanjutkan dengan melakukan proses analisa sentiment dengan menggunakan algoritma Naïve Bayes Classification dengan menggunakan data latih dari opini yang telah diberikan label opini.
Gambar 7 Flowchart Naïve Bayes Classification
-
B. Analisa Sentiment Support Vector Machines
Pada tahap klasifikasi ini, data uji yang telah melewati tahap prepocessing akan dilanjutkan dengan melakukan proses analisa sentiment dengan menggunakan algoritma Support Vector Machines dengan menggunakan data latih dari opini yang telah diberikan label opini.
Pada tahap awal dari penelitian dilakukan penumpulan data opini alumni yang didapatkan dari halaman website www.alumni.stikom-bali.ac.id yang dimana para mahasiswa yang akan lulus diwajibkan untuk mengisi kuisioner lulusan yang berisikan opini yang harus diinputkan berupa kalimat tentang pendapat para mahasiswa terhadap kampus selama para mahasiswa kuliah.
Jumlah opini yang digunakan adalah opini mahasiswa yang lulus pada bulan Desember 2017 yang berjumlah 331 opini, dengan menggunakan perhitungan. Opini yang terkumpul kemudian diklasifikasikan secara manual oleh doktor pada bidang linguistik (sastra Indonesia). Untuk pengujian data digunakan ratio 80:20 mengacu pada Pareto principle[14]. Dengan menggunakan empat datalatih dengan jumlah berbeda, data pertama berjumlah 150 opini, data kedua 150 opini, data ketiga 225 opini, dan 300 opini, dan data uji mencapai 66 opini.
Dari tahap pengujian dengan menggunakan 75 data latih yang dilakukan maka didapatkan hasil pengujian analisa opini. Tabel 1 merupakan jumlah opini yang berhasil dianalisa
231 dengan menggunakan total 66 opini yang dibagi menjadi 3 katagori, yaitu positif, negatif, dan netral.
C Mulai
Data Data
Latih Uji
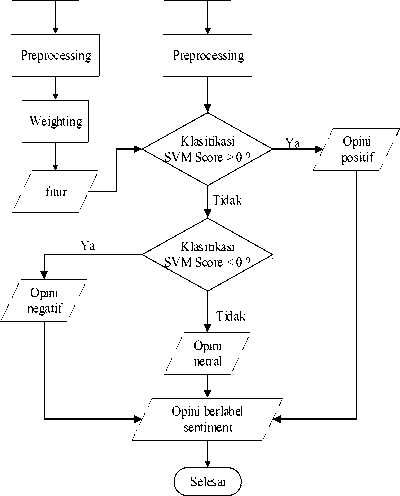
Gambar 8 Flowchart Support Vector Machines
Tabel II
Keberhasilan Analisa Opini Dengan 75 Data Latih
|
positive |
negative |
neutral |
Total | |
|
NBC tanpa Sastrawi |
21 |
20 |
22 |
63 |
|
NBC Sastrawi |
18 |
22 |
20 |
60 |
|
SVM tanpa Sastrawi |
15 |
14 |
21 |
50 |
|
SVM Sastrawi |
15 |
13 |
21 |
49 |
Pegujian untuk algoritma NBC dan SVM dengan menggunakan stemming sastrawi dan tanpa menggunakan stemming sastrawi didapatkan bahwa proses sentiment analis pada algoritma NBC tanpa menggunakan stemming sastrawi menunjukkan tingkat akurasi tertinggi mencapai 95,45 % dengan 63 opini yang berhasil dianalisa dari 66 opini. Tingkat akurasi terendah dicapai pada algoritma SVM dengan menggunakan stemming sastrawi, dengan tingkat akurasi mencapai 74,24% dengan 49 opini yang berhasil dianalisa dari 66 opini
Dari tahap pengujian dengan menggunakan 150 data latih yang dilakukan maka didapatkan hasil pengujian analisa opini. Tabel 2 merupakan jumlah opini yang berhasil dianalisa dengan menggunakan total 66 opini yang dibagi menjadi 3 katagori, yaitu positif, negatif, dan netral.
I Komang Dharmendra dkk: Analisa Sentiment Untuk Opini…
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

Tabel III
Keberhasilan Analisa Opini Dengan 150 Data Latih
|
positive |
negative |
neutral |
Total | |
|
NBC tanpa Sastrawi |
21 |
21 |
21 |
63 |
|
NBC Sastrawi |
19 |
22 |
18 |
59 |
|
SVM tanpa Sastrawi |
17 |
15 |
18 |
50 |
|
SVM Sastrawi |
17 |
14 |
17 |
48 |
Pegujian untuk algoritma NBC dan SVM dengan menggunakan stemming sastrawi dan tanpa menggunakan stemming sastrawi didapatkan bahwa proses sentiment analis pada algoritma NBC tanpa menggunakan stemming sastrawi menunjukkan tingkat akurasi tertinggi mencapai 95,45 % dengan 63 opini yang berhasil dianalisa dari 66 opini. Tingkat akurasi terendah dicapai pada algoritma SVM dengan menggunakan stemming sastrawi, dengan tingkat akurasi mencapai 74,24% dengan 48 opini yang berhasil dianalisa dari 66 opini.
Dari tahap pengujian dengan menggunakan 225 data latih yang dilakukan maka didapatkan hasil pengujian analisa opini.
Tabel 3 merupakan jumlah opini yang berhasil dianalisa dengan menggunakan total 66 opini yang dibagi menjadi 3 katagori, yaitu positif, negatif, dan netral.
Tabel IV
Keberhasilan Analisa Opini Dengan 225 Data Latih
|
Positive |
negative |
neutral |
Total | |
|
NBC tanpa Sastrawi |
20 |
20 |
22 |
62 |
|
NBC Sastrawi |
18 |
20 |
21 |
59 |
|
SVM tanpa Sastrawi |
15 |
9 |
20 |
44 |
|
SVM Sastrawi |
16 |
8 |
19 |
43 |
Pengujian untuk algoritma NBC dan SVM dengan menggunakan stemming sastrawi dan tanpa menggunakan stemming sastrawi didapatkan bahwa proses sentiment analis pada algoritma NBC tanpa menggunakan stemming sastrawi menunjukkan tingkat akurasi tertinggi mencapai 93,94 % dengan 62 opini yang berhasil dianalisa dari 66 opini. Tingkat akurasi terendah dicapai pada algoritma SVM dengan menggunakan stemming sastrawi, dengan tingkat akurasi mencapai 65,15% dengan 43 opini yang berhasil dianalisa dari 66 opini.
Dari tahap pengujian dengan menggunakan 300 data latih yang dilakukan maka didapatkan hasil pengujian analisa opini. Tabel 4 merupakan jumlah opini yang berhasil dianalisa dengan menggunakan total 66 opini yang dibagi menjadi 3 katagori, yaitu positif, negatif, dan netral.
Tabel V
Keberhasilan Analisa Opini Dengan 300 Data Latih
|
positive |
negative |
neutral |
Total | |
|
NBC tanpa Sastrawi |
21 |
20 |
22 |
63 |
|
NBC Sastrawi |
18 |
20 |
21 |
59 |
|
SVM tanpa Sastrawi |
17 |
14 |
19 |
50 |
|
SVM Sastrawi |
13 |
17 |
17 |
47 |
Pegujian untuk algoritma NBC dan SVM dengan menggunakan stemming sastrawi dan tanpa menggunakan stemming sastrawi didapatkan bahwa proses sentiment analis pada algoritma NBC tanpa menggunakan stemming sastrawi menunjukkan tingkat akurasi tertinggi mencapai 95,45 % dengan 63 opini yang berhasil dianalisa dari 66 opini. Tingkat akurasi terendah dicapai pada algoritma SVM dengan menggunakan stemming sastrawi, dengan tingkat akurasi mencapai 71,21% dengan 47 opini yang berhasil dianalisa dari 66 opini.
Berdasarkan hasil pengujian pada tabel 2, tabel 3, tabel 4, dan tabel 5 maka dapat dibangun grafik tingkat akurasi. Grafik tingkat akurasi dapat dilihat pada gambar 9 yeng menunjukkan bahwa algoritma NBC menunjukkan kinerja yang lebih baik dibandingkan dengan algoritma SVM dengan nilai akurasi pengujian yang lebih tinggi.
TingkatAkurasi Pengujian
|
80 70 60 50 40 30 20 10 0 |
Illl NBC tanpa |
III NBC |
III SVM tanpa |
Illl SVM |
|
Sastrawi |
Sastrawi |
Sastrawi |
Sastrawi | |
|
75 data |
95,45 |
90,91 |
75,76 |
74,24 |
|
150 data |
95,45 |
89,39 |
75,76 |
72,73 |
|
225 data |
93,94 |
89,39 |
66,67 |
65,15 |
|
300 data |
95,45 |
89,39 |
75,76 |
71,21 |
■ 75 data ■ 150 data ■ 225 data ■ 300 data
Gambar 9 Grafik Tingkat Akurasi Analisa Opini Alumni
Berdasarkan hasil uji coba yang telah dilakukan dapat diambil beberapa kesimpulan sebagai berikut:
-
1. Dari hasil pengujian secara umum menunjukkan akurasi dengan nilai akurasi tertinggi pada algoritma NBC mencapai 94,45%, sedangkan tingkat akurasi tertinggi pada algoritma SVM mencapai 75,76%.
-
2. Dari hasil pengujian didapatkan kinerja algoritma NBC menunjukkan kinerja yang lebih baik, dengan tingkat akurasi tertinggi pada setiap pengujian dibandingkan dengan algoritma SVM.
-
3. Pengujian dengan pengunaan stemming sastrawi menunjukkan penurunan akurasi dibandingkan dengan pengujian tanpa menggunakan stemming sastrawi.
-
4. Algoritma NBC dan SVM mampu dengan baik digunakan untuk melakukan analisa opini dengan data opini berupa kalimat.
Majalah Ilmiah Teknologi Elektro, Vol. 18, No. 2, Mei - Agustus 2019 DOI: https://doi.org/10.24843/MITE.2019.v18i02.P0X
Referensi
-
[1] F. Rahutomo, Z. Hanif Rachmat Adi, I. Fahrur Rozi, and P. Yoga Saputra, “Implementasi Text Mining Pada Website/Blog Di Internet Untuk Menilai Kinerja Suatu Organisasi,” INOVTEK Polbeng - Seri Inform., vol. 3, no. 2, p. 101, Nov. 2018.
-
[2] G. A. Buntoro, “Sentiments Analysis for Governor of East Java 2018 in Twitter,” SinkrOn, vol. 3, no. 2, p. 49, Dec. 2019.
-
[3] E. I. Setiawan, “Komparasi algoritma untuk analisa sentimen review produk pada twitter,” vol. 7, no. 1, pp. 7–14, 2015.
-
[4] N. D. Putranti and E. Winarko, “Analisis Sentimen Twitter untuk Teks Berbahasa Indonesia dengan Maximum Entropy dan Support Vector Machine,” IJCCS (Indonesian J. Comput. Cybern. Syst., vol. 8, no. 1, pp. 91–100, Jan. 2014.
-
[5] M. Lailiyah, “Sentiment Analysis Menggunakan Rule Based Method Pada Data Pengaduan Publik Berbasis Lexical Resources,” Aug. 2017.
-
[6] I. M. D. Ardiada, M. Sudarma, and D. Giriantari, “Text Mining pada Sosial Media untuk Mendeteksi Emosi Pengguna Menggunakan Metode Support Vector Machine dan K-Nearest Neighbour,” Maj. Ilm. Teknol. Elektro, vol. 18, no. 1, p. 55, May 2019.
-
[7] P. S. M. Suryani, L. Linawati, and K. O. Saputra, “Penggunaan Metode Naïve Bayes Classifier pada Analisis Sentimen Facebook Berbahasa Indonesia,” Maj. Ilm. Teknol. Elektro, vol. 18, no. 1, p. 145, May 2019.
-
[8] M. R. Huq, A. Ali, and A. Rahman, “Sentiment Analysis on Twitter Data using KNN and SVM,” IJACSA) Int. J. Adv. Comput. Sci. Appl., vol. 8, no. 6, pp. 19–25, 2017.
-
[9] H. Peng et al., “Tensor Fusion Network for
Multimodal Sentiment Analysis,” IJCCS (Indonesian J. Comput. Cybern. Syst., vol. 5, no. 2, pp. 147–156, 2017.
-
[10] N. L. Ratniasih, M. Sudarma, and N. Gunantara, “Penerapan Text Mining Dalam Spam Filtering Untuk Aplikasi Chat,” Maj. Ilm. Teknol. Elektro, vol. 16, no. 3, p. 13, Dec. 2017.
-
[11] N. G. Yudiarta, M. Sudarma, and W. G. Ariastina, “Penerapan Metode Clustering Text Mining Untuk Pengelompokan Berita Pada Unstructured Textual Data,” Maj. Ilm. Teknol. Elektro, vol. 17, no. 3, p. 339, Dec. 2018.
-
[12] A. A. Magriyanti, “Analisis Pengembangan Algoritma Porter Stemming Dalam Bahasa Indonesia,” Attrib.
-
4.0 Int., 2018.
-
[13] I. M. A. Agastya, “Pengaruh Stemmer Bahasa Indonesia Terhadap Peforma Analisis Sentimen Terjemahan Ulasan Film,” J. Tekno Kompak, vol. 12, no. 1, pp. 18–23, Feb. 2018.
-
[14] C. Lu, D. Wang, X. Liu, and K. Gan, “A mining and visualizing system for large-scale Chinese technical standards,” in Proceedings - IEEE 4th International Conference on Big Data Computing Service and Applications, BigDataService 2018, 2018, pp. 1–8.
I Komang Dharmendra dkk: Analisa Sentiment Untuk Opini…
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

{ Halaman ini sengaja dikosongkan }
ISSN 1693 – 2951
I Komang Dharmendra dkk: Analisa Sentiment Untuk Opini…
Discussion and feedback