Klasifikasi Lagu Daerah di Indonesia dengan Metode Machine Learning
on
JNATIA Volume 1, Nomor 3, Mei 2023
Jurnal Nasional Teknologi Informasi dan Aplikasinya
p-ISSN: 2986-3929
Klasifikasi Lagu Daerah di Indonesia dengan Metode Machine Learning
Gst. Ayu Vida Mastrika Giria1, Made Leo Radhityaa2
aProgram Studi Informatika, Universitas Udayana
Badung, Bali, Indonesia 1vida@unud.ac.id
bProgram Studi Teknik Informatika, Institut Bisnis dan Teknologi Indonesia Denpasar, Bali, Indonesia 2leo.radhitya@instiki.ac.id
Abstract
Keunikan dari lagu daerah yang mencerminkan daerah asal adalah diiringi dengan alat musik daerah dan dinyanyikan dengan bahasa daerah masing-masing. Ciri khas lagu daerah dapat dilihat dari fitur-fitur musik seperti spectral centroid dan Mel Frequency Cepstral Coefficients (MFCC) karena dimainkan dengan alat musik berbeda dan memiliki timbre yang berbeda pula. Dengan menggunakan fitur-fitur musik tersebut dan algoritma machine learning, lagu-lagu daerah dapat diklasifikasi berdasarkan daerah asalnya. Pada penelitian ini digunakan sebuah dataset lagu daerah Indonesia yang bernama IRSD: Indonesian Regional Song Dataset yang terdiri dari 67 fitur musik yang diantaranya adalah MFCC, energy, dan spectral centroid dari 500 lagu daerah dari 10 provinsi di Indonesia. Metode machine learning yang akan digunakan untuk klasifikasi adalah SVM dan K-NN untuk menghasilkan nilai klasifikasi yang baik dengan waktu eksekusi yang cepat. Dengan menggunakan nilai K=3 dan 5-fold cross validation, metode K-NN menghasilkan nilai akurasi 0,69. Klasifikasi dengan metode SVM menggunakan kernel RBF dan 5-fold cross validation menghasilkan nilai akurasi 0,73. Pada penelitian kali ini, metode SVM dapat mengklasifikasi lagu daerah lebih baik daripada metode K-NN.
Keywords: K-Nearest Neighbor, klasifikasi, lagu daerah Indonesia, machine learning, Support Vector Machine
Wilayah negara Indonesia berbentuk kepulauan dari Sabang sampai Merauke yang memiliki keragaman suku dan kebudayaan. Setiap daerah di Indonesia memiliki kebudayaannya masing-masing yang unik jika dibandingkan dengan daerah lainnya. Salah satu jenis kebudayaan yang dimiliki setiap daerah adalah lagu daerah. Lagu daerah diciptakan di hampir setiap daerah di Indonesia dan memiliki sifat serta keunikan tersendiri yang mencerminkan ciri khas dari daerah asalnya [1]. Keunikan dari lagu daerah yang mencerminkan daerah asal adalah diiringi dengan alat musik daerah dan dinyanyikan dengan bahasa daerah masing-masing. Ciri khas lagu daerah dapat dilihat dari fitur-fitur musik seperti spectral centroid dan Mel Frequency Cepstral Coefficients (MFCC) karena dimainkan dengan alat musik berbeda dan memiliki timbre yang berbeda pula. Saat ini, ada ratusan lagu daerah Indonesia yang bisa didengarkan dan dipelajari. Dengan menggunakan fitur-fitur musik tersebut dan algoritma machine learning, lagu-lagu daerah dapat diklasifikasi berdasarkan daerah asalnya.
Penelitian tentang klasifikasi musik sebelumnya telah dilakukan oleh beberapa peneliti menggunakan fitur musik dan metode yang berbeda. Fitur MFCC telah digunakan untuk mengklasifikasi lagu daerah Indonesia berdasarkan genre menggunakan metode machine learning Support Vector Machine (SVM) dan menghasilkan akurasi sebesar 83% [2]. Pada penelitian yang dilakukan oleh Cettiar & Selvakumar tentang klasifikasi musik berdasarkan genre yang juga menggunakan fitur MFCC dan berbagai metode machine learning dan deep learning, metode SVM menghasilkan nilai akurasi tertinggi, yaitu 70,66% [3]. Metode machine learning
juga digunakan untuk klasifikasi bunyi alat musik dengan fitur MFCC pada penelitian yang telah dilakukan oleh Anuz, dkk. Metode SVM dan K-Nearest Neighbor (K-NN) yang digunakan pada penelitian tersebut menghasilkan nilai akurasi 97% dengan menggunakan metode SVM dan 96% dengan menggunakan K-NN [4].
Pada penelitian ini digunakan sebuah dataset lagu daerah Indonesia telah disusun oleh Mahardhika, dkk yang bernama IRSD: Indonesian Regional Song Dataset yang terdiri dari 67 fitur musik yang diantaranya adalah MFCC, energy, dan spectral centroid dari 500 lagu daerah dari 10 provinsi di Indonesia [5]. Metode machine learning yang akan digunakan untuk klasifikasi adalah SVM dan K-NN untuk menghasilkan nilai klasifikasi yang baik dengan waktu eksekusi yang cepat.
Bagian ini berisi penjelasan tentang dataset yang digunakan serta alur yang digunakan dalam penelitian ini secara umum.
Dataset yang digunakan pada penelitian ini adalah IRSD: Indonesian Regional Song Dataset [5] yang terdiri dari 500 lagu daerah dari 10 provinsi di Indonesia dengan pembagian jumlah 50 lagu daerah pada setiap provinsi. Provinsi yang terdaftar dalam dataset ini adalah DI Aceh, Sumatera Barat, Riau, Jawa Barat, DKI Jakarta, Jawa Tengah, Kalimantan Barat, Sulawesi Utara, Maluku, dan Papua. Sebanyak 67 fitur telah diekstrak dari setiap lagu berdasarkan domain waktu dan frekuensi. Tabel 1 menunjukkan daftar fitur yang diekstrak, domain, dan dimensi dari fitur tersebut. Dalam setiap fitur terdapat nilai mean dan standard deviation sehingga semua fitur berjumlah 67.
Tabel 1. Daftar Fitur [5]
|
Nama Fitur |
Domain |
Dimensi |
|
Energy |
2 | |
|
Energy Entrophy |
Waktu |
2 |
|
Zero Crossing Rate (ZCR) |
2 | |
|
Spectral Centroid |
2 | |
|
Spectral Spread |
2 | |
|
Spectral Entropy |
2 | |
|
Spectral Flux |
Frekuensi |
2 |
|
Spectral Rolloff |
2 | |
|
MFCC 1 to MFCC 13 |
26 | |
|
Chroma 1 to Chroma 12 |
24 | |
|
Chroma Deviation |
1 |
Fitur yang termasuk pada domain waktu pada dataset IRSD adalah energy, energy entrophy, dan ZCR. Energi terkait dengan intensitas suara yang dirasakan, fitur ini digunakan untuk memperkirakan kenyaringan dan sebagai indikator kejadian baru dalam segmentasi audio. Entropi energi dapat diartikan sebagai perubahan yang terjadi secara spontan atau tiba-tiba [5]. ZCR adalah frekuensi saat sinyal waktu diskrit berubah tanda dari positif ke negatif atau sebaliknya [6].
Fitur domain frekuensi diekstrak dengan mengimplementasikan Fourier Transform pada sinyal audio musik. Pada dataset IRSD terdapat 8 fitur domain frekuensi seperti yang tertera pada Tabel 1. Spectral centroid adalah frekuensi dimana energi terpusat pada sebuah frame [7], hal ini dapat digunakan untuk mengukur “kecerahan” suara dan berhubungan dengan timbre musik. Spectral spread merupakan turunan dari spectral centroid, yang dapat diartikan sebagai varian dari frekuensi rata-rata dalam sinyal. Spectral entrophy digunakan untuk mengukur besar kecilnya distribusi daya atau daya spektral. Spectral flux digunakan untuk menggambarkan perubahan daya atau spektrum daya secara berturut-turut antara setiap frame [5].
Penelitian ini melakukan klasifikasi lagu daerah berdasarkan daerah asalnya menggunakan fitur yang tersedia pada dataset IRSD. Alur penelitian ini, ditunjukkan pada Gambar 1, diawali dengan normalisasi data, klasifikasi lagu dengan K-NN/SVM yang dilakukan secara terpisah, 5-Fold Cross Validation untuk memastikan bahwa dataset terbagi dengan baik, dan diakhiri dengan evaluasi hasil klasifikasi dengan menghitung nilai precision, recall, F1-Score, dan nilai akurasi.

Gambar 1. Alur Umum Penelitian
Data fitur yang terdapat pada dataset IRSD belum berada pada range yang sama, sehingga perlu dilakukan normalisasi. Persamaan 1 digunakan untuk menormalisasi data dengan metode minmax, agar semua fitur berada dalam range 0-1 [8].
x - minValue
(1)
nor m(x) = --—---—--—
maxValue — min value
Klasifikasi dengan metode machine learning K-NN pada penelitian ini menggunakan python lybrary Scikit Learn, Grid Search untuk mencari nilai K optimal, serta menggunakan 5-Fold Cross Validation untuk membagi sampel data secara acak. Klasifikasi dengan metode machine learning SVM pada penelitian ini menggunakan kernel RBF. Sama dengan klasifikasi dengan metode K-NN, 5-Fold Cross Validation juga digunakan pada klasifikasi dengan SVM.
Evaluasi hasil klasifikasi dilakukan dengan menghitung nilai precision, recall, dan F1 score, dan nilai akurasi. Precision adalah jumlah prediksi kasus positif yang benar/sesuai dengan kelas sebenarnya (true positive) yang dihitung dengan persamaan (2), dimana TP adalah true positive, dan FP adalah false positive [9].
Precision =
TP
TP +FP
(2)
Nilai recall adalah jumlah prediksi kasus positif yang diklasifikasi benar/sesuai kelas sebenarnya oleh metode klasifikasi dibandingkan dengan semua data kasus positif yang ada pada dataset. Nilai recall dihitung dengan persamaan (3), dimana TP dalah true positive, dan FN adalah false negative [9].
Recall =
TP
TP+FN
(3)
F1-Score didapat dengan menggabungkan nilai precision dan recall yang dikalkulasi menggunakan persamaan (4) [9].
2×TP
(4)
Fl Score =---------------
2×TP + FP + FN
Nilai akurasi, berbeda dengan nilai precision, recall, dan F1-Score, menghitung perbandingan secara keseluruhan jumlah kasus positif yang diprediksi benar dengan jumlah total prediksi. Persamaan (5) digunakan untuk menghitung nilai akurasi [9].
Accuracy =
Number of correct prediction Total number of prediction
(5)
Bagian ini memuat hasil dan pembahasan dari penelitian yang telah dilakukan. Penjelasan akan dibagi menjadi dua, yaitu hasil pembahasan klasifikasi menggunakan K-NN dan SVM.
Klasifikasi dengan menggunakan metode K-NN dimulai dengan menggunakan grid search untuk menentukan nilai K terbaik dengan mencoba keseluruhan kemungkinan yang ada (pencarian menyeluruh/exhaustive search). Nilai K yang akan digunakan dipilih berdasarkan hasil cross validation terbaik dari setiap percobaan. Grid search dilakukan dalam range nilai K=3 hingga K=50. Pada Gambar 2 diperlihatkan hasil mean test score, hasil rata-rata dari tiap 5-fold cross validation dari 10 nilai K pertama yaitu K=3 sampai K=23. Nilai means test score tertinggi ada pada nilai K=3, yaitu 0,688. Nilai K setelahnya menghasilkan nilai yang tidak lebih tinggi dari 0,55.
1
* ⅝ ⅝ I τ _ _ _
0.5
0
3 5 7 9 11 13 15 17 19 21 23
Mean Test Score
Gambar 2. Hasil Grid Search untuk 10 Nilai K Pertama.
Selanjutnya, klasifikasi dengan K-NN menggunakan nilai K=3. Hasil klasifikasinya ditunjukkan pada Gambar 3. Provinsi yang paling banyak lagu daerahnya benar diklasifikasi adalah Jawa Barat, Jawa Tengah, dan Papua. Jumlah prediksi tertinggi tersebut adalah 9 lagu daerah. Klasifikasi terendah ada pada Provinsi Aceh dan Sumatera Barat, dengan 5 lagu daerah. Lebih jelas tentang hasil klasifikasi menggunakan K-NN dapat dilihat pada Tabel 2.

Gambar 3. Confusion Matrix Hasil Klasifikasi dengan Metode K-NN
Hasil precision, recall, dan F1-Score untuk setiap provinsi ditunjukkan pada Tabel 2. Nilai F1-Score tertinggi ada pada Provinsi Jawa Barat, dengan nilai 0,90, disusul dengan Provinsi Jawa Tengah dengan Nilai 0,86, dan Papua dengan nilai 0,75. Nilai F1-Score terendah ada pada Provinsi Aceh, dengan nilai 0,59. Rata-rata nilai F1-Score yang didapat adalah 0,70. Nilai akurasi total dari semua provinsi adalah 0,69, yang menyatakan bahwa 69% lagu daerah terklasifikasi dengan benar berdasarkan provinsi/daerah asal lagu tersebut dengan menggunakan metode machine learning K-NN.
Tabel 2. Nilai Precision, Recall, dan F1-Score Hasil Klasifikasi Lagu Daerah dengan K-NN
|
Precision |
Recall |
F1-Score | |
|
Aceh |
0,56 |
0,62 |
0,59 |
|
Jabar |
0,82 |
1,00 |
0,90 |
|
Jakarta |
0,47 |
0,88 |
0,61 |
|
Jateng |
0,90 |
0,82 |
0,86 |
|
Kalbar |
0,64 |
0,54 |
0,58 |
|
Maluku |
0,43 |
0,75 |
0,55 |
|
Papua |
0,90 |
0,64 |
0,75 |
|
Riau |
0,75 |
0,55 |
0,63 |
|
Sulut |
0,86 |
0,67 |
0,75 |
|
Sumbar |
1,00 |
0,56 |
0,71 |
|
Macro Average |
0,73 |
0,70 |
0,70 |
Klasifikasi dengan metode machine learning SVM pada penelitian ini menggunakan kernel RBF dan sama dengan klasifikasi dengan K-NN, klasifikasi dengan SVM juga menggunakan 5-fold
cross validation. Hasil means dari seluruh cross validation adalah 0,686, dengan masing-masing hasil cross validation 0,65, 0,8, 0,65, 0,71, dan 0,62.
Confusion matrix dari hasil klasifikasi dengan SVM dapat dilihat pada Gambar 4. Lagu daerah yang paling banyak benar diklasifikasi berdasarkan daerah asalnya adalah lagu daerah Papua, dengan jumlah 10 lagu, selanjutnya adalah Jawa Barat, Jawa Tengah, dan Sulawesi Utara dengan 9 lagu. Lagu daerah yang paling banyak salah diklasifikasi adalah lagu daerah Sumatera Barat, sebagian besar lagunya salah diklasifikasi berasal dari Aceh. Lebih jelas tentang hasil klasifikasi dapat dilihat pada Tabel 3.
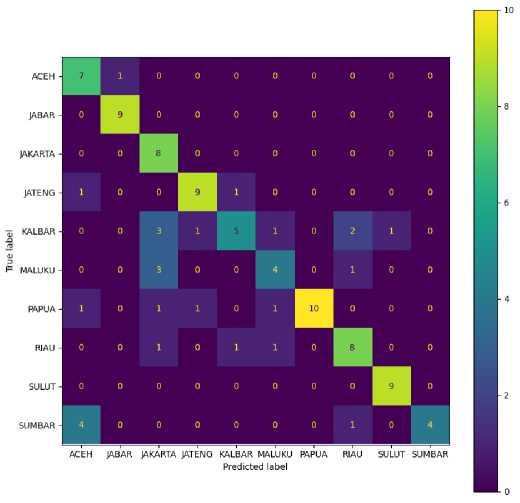
Gambar 4. Confusion Matrix Hasil Klasifikasi dengan Metode SVM
Nilai F1-score tertinggi ada pada klasifikasi lagu daerah Jawa Barat dan Sulawesi Utara dengan nilai 0,95, disusul dengan Jawa Tengah dengan nilai 0,82. Nilai rata-rata F1-score untuk keseluruhan hasil klasifikasi adalah 0,72. Perhitungan akurasi juga telah dilakukan dan menghasilkan 73% lagu daerah dapat diklasifikasi dengan benar dengan menggunakan metode machine learning SVM.
Tabel 3. Nilai Precision, Recall, dan F1-Score Hasil Klasifikasi Lagu Daerah dengan SVM
|
Precision |
Recall F1-Score | ||
|
Aceh |
0,54 |
0,88 |
0,67 |
|
Jabar |
0,90 |
1,00 |
0,95 |
|
Jakarta |
0,50 |
1.00 |
0,67 |
|
Jateng |
0,82 |
0,82 |
0,82 |
|
Kalbar |
0,71 |
0,38 |
0,50 |
|
Maluku |
0,57 |
0,50 |
0,53 |
|
Papua |
1,00 |
0,71 |
0,83 |
|
Riau |
0,67 |
0,73 |
0,70 |
|
Sulut |
0,90 |
1,00 |
0,95 |
Precision Recall F1-Score
Sumbar 1,00 0,44 0,62
Macro Average 0,76 0,75 0,72
Klasifikasi lagu daerah di Indonesia telah berhasil dilakukan dengan menggunakan dataset IRSD dua metode machine learning, yaitu K-NN dan SVM. Dataset IRSD yang digunakan dinormalisasi terlebih dahulu sebelum masuk ke metode klasifikasi. Klasifikasi dengan metode K-NN menggunakan grid search untuk menemukan nilai K terbaik. Dengan menggunakan nilai K=3 dan 5-fold cross validation, metode K-NN menghasilkan nilai akurasi 0,69. Klasifikasi dengan metode SVM menggunakan kernel RBF dan 5-fold cross validation menghasilkan nilai akurasi 0,73. Pada penelitian kali ini, metode SVM dapat mengklasifikasi lagu daerah lebih baik daripada metode K-NN.
Daftar Pustaka
-
[1] G. Santoso, R. Sakinah, A. S. Hidayat, A. Ramadhania, S. N. Tiara, D. Safitri and G. Geifira, "Mengenal Lagu Daerah dan Lagu Nasional Republik Indonesia Sebagai Pendidikan Multikultural bagi Mahasiswa," Jurnal Pendidikan Transformatif (Jupetra), vol. 2, no. 2, pp. 325-335, 2021.
-
[2] S. Y. Yehezkiel and Y. Suyanto, "Music Genre Identification Using SVM and MFCC Feature Extraction," IJEIS (Indonesian Journal of Electronics and Instrumentation Systems), vol. 12, no. 2, pp. 115-122, 2022.
-
[3] G. Chettiar and K. Selvakumar, "Music Genre Classification Techniques," in International Conference on Innovation Challenges and Advances in Engineering & Technology: A road to self-reliant India (ICAET-2021) - Virtual Conference, 2021.
-
[4] H. Anuz, A. K. M. Masum, S. Abujar and S. A. Hossain, "Musical Instrument Classification Based on Machine Learning Algorithm," in Emerging Technologies in Data Mining and Information Security, Springer, 2021, pp. 57-67.
-
[5] F. Mahardhika, H. L. H. S. Warnars, A. S. Nugroho and W. Budiharto, "IRSD: Indonesian Regional Song Dataset," International Journal of Computing and Digital Systems, vol. 13, no. 1, pp. 1107-1117, 2023.
-
[6] P. Sahil, V. Chetan and M. Nikita, "10.1007/978-981-19-2177-3_83," 10.1007/978-981-19-2177-3_83, vol. 13, no. 1, pp. 15-21, 2022.
-
[7] D. Lau and R. Ajooda, "Music Genre Classification: A Comparative Study Between DeepLearning And Traditional Machine," in Proceedings of Sixth International Congress on Information and Communication Technology, Singapore, 2021.
-
[8] I. N. Y. T. Giri, L. A. A. R. Putri, G. A. V. M. Giri, G. N. A. C. Putra, I. M. Widiartha and I. W. Supriyana, "Music Genre Classification Using Modified K-Nearest Neighbor (MK-NN)," Jurnal Elektronik Ilmu Komputer Udayana, vol. 10, no. 3, pp. 261-270, 2022.
-
[9] G. A. V. M. Giri and M. L. Radhitya, "Klasifikasi Genre Musik Menggunakan Teknik Pembelajaran Mesin," Jurnal Teknologi Informasi dan Komputer (JuTIK), vol. 9, no. 1, pp. 1-9, 2023.
-
[10] R. Luis and N. Rokhman, Klasifikasi Daerah Asal Musik Tradisional menggunakan Convolutional Neural Network (CNN) dan Mel Frequency Cepstrum Coefficients (MFCC), Yogyakarta: Universitas Gadjah Mada, 2022.
-
[11] P.-N. Tan, M. Steinbach, A. Karpatne and V. Kumar, Introduction to Data Mining, Harlow: Pearson Education Limited, 2019.
Halaman ini sengaja dibiarkan kosong
1010
Discussion and feedback