Perbandingan Berbagai Metode Segmentasi dan Mechine Learning pada Makanan Khas Tradisional Sumatera Utara Guna Meningkatkan Promosi Budaya dan Kuliner Nusantara
on
JNATIA Volume 1, Nomor 4, Agustus 2023
Jurnal Nasional Teknologi Informasi dan Aplikasinya
p-ISSN: 2986-3929
Perbandingan Berbagai Metode Segmentasi dan Mechine Learning pada Makanan Tradisional Sumatera Utara
Anugrah Ignatius Sitinjaka1, I Made Widiarthaa2
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana
Jalan Raya Kampus Udayana, Bukit Jimbaran, Kuta Selatan, Badung, Bali Indonesia 1ignatiusanugrah03@email.com
2madewidiartha@unud.ac.id (Corresponding Author)
Abstract
This study investigates the categorization of traditional North Sumatran dishes using various segmentation methods. The goal is to participate and participate in the preservation of North Sumatran culture. The study covers 34 types of traditional North Sumatran dishes originating from various regions. Food images are processed using segmentation techniques such as Sobel, Prewitt, Robert, Scharr, and Canny filters. The data set is then used in traditional machine learning algorithms, including Random Fortst, Decision Tree, and four SVM algorithms, for classification purposes. Among the algorithms with the highest performance, the Random Forest algorithm with Robert's segmentation method achieves outstanding results on dataset testing, with 85.52% accuracy, 84.63% recall, 83.77% precision, and 82.49% f1 score. The execution time for most of the best performing algorithms is around 1 minute on average. In addition, the Random Forest algorithm with the Canny operator achieves 81.51% accuracy, 84.97% recall, 86.81% precision, and 85.61% f1 score on dataset testing. The Random Forest algorithm with the Sobel operator obtains an accuracy of 78.41%, a recall of 65.28%, a precision of 62.33%, and an f1 score of 63.71%. Among the four SVM algorithms, the Sigmoid SVM with the Scharr operator achieves the highest performance in its category across all classification metrics. The importance of insight into the traditional cuisine of North Sumatra is invaluable. Emphasizing the importance of this research in promoting the preservation and introduction of traditional North Sumatran food.
Keywords: North Sumatera, food, categorization
Sumatera Utara adalah salah satu provinsi di Indonesia memiliki kekayaan budaya yang cukup besar. Salah satu aspek yang memperkaya keunikan provinsi ini adalah ragam makanan tradisionalnya yang lezat dan memikat. Makanan tradisional Sumatera Utara mencerminkan keanekaragaman suku dan etnis yang ada di daerah ini, seperti suku Batak, Melayu, Nias, dan banyak lagi. Dalam era globalisasi dan kemajuan teknologi, promosi budaya dan pariwisata telah menjadi salah satu fokus utama pemerintah daerah untuk meningkatkan kunjungan wisatawan. Dalam hal ini, penggunaan teknologi menjadi sangat relevan dan memiliki potensi besar untuk meningkatkan promosi dan pengenalan makanan tradisional Sumatera Utara. Dalam penelitian ini, kami mengusulkan penggunaan Jaringan Syaraf Konvolusional (Convolutional Neural Network/CNN) dan metode segmentasi untuk memperkenalkan makanan tradisional Sumatera Utara secara efektif kepada khalayak. Jaringan syaraf konvolusional merupakan salah satu metode dalam bidang kecerdasan buatan yang mampu melakukan klasifikasi dan pengenalan pola pada data gambar. Sedangkan metode segmentasi digunakan untuk memisahkan makanan dari latar belakang gambar secara otomatis, memungkinkan gambar makanan tampil dengan lebih jelas dan menarik. Dengan menggunakan teknologi ini, diharapkan promosi budaya dan pariwisata Sumatera Utara dapat meningkat dengan cara yang lebih menarik dan informatif. Dengan melakukan pengenalan makanan tradisional secara
visual, wisatawan dapat memperoleh pemahaman yang lebih baik tentang kekayaan kuliner daerah ini dan terinspirasi untuk menjelajahi lebih lanjut. Untuk mengatasi hal ini, para peneliti telah bekerja untuk mengkategorikan dan mengklasifikasikan makanan ini untuk memberikan pemahaman menyeluruh tentang warisan kuliner Sumatera Utara yang kaya. Melalui penelitian ini, kami berharap bahwa hasil yang diperoleh dapat menjadi sumbangan penting dalam mempromosikan budaya dan pariwisata Sumatera Utara, serta memberikan manfaat bagi pengembangan teknologi pengenalan gambar dan aplikasinya dalam konteks yang lebih luas [1].
Penelitian ini berfokus pada pelatihan algoritma dan evaluasi dataset uji berdasarkan pengujian dari fitur-fitur. Di sini, 34 kelas diperkenalkan: Mie Gomak, Lontong Medan, Soto Medan, Lemang, Bika Ambon, Bihun Bebek Medan, Daun Ubi Tumbuk, Kari Bihun, Mie Balap, Rujak Kolam, Martabak Piring, Gulai Ikan Mas, Laksa Medan, Arsik, Naniura , Pelleng, Lappet, Manuk Napinadar, Babi Panggang Karo, Ayang Pakis, Sayur Gurih Tauco, Putu Bambu, Natinombur, Kolak Durian, Sate Kerang, Sambal Tuktuk, Dali ni Horbo, Kacang Sihobuk, Ssgun, Tanggo-tanggo, Gulai Kuta-Kuta, Manuk Gota, Kidu Kidu, Cimpa, dan Saksang sebanyak 34 label kelas. Kemampuan untuk menggeneralisasi 34 penting untuk algoritma pembelajaran mesin tradisional untuk mengekstraksi karakteristik yang diperlukan.

Gambar 1. Makanan Khas Sumatera Utara
Proses berlanjut ke klasifikasi menggunakan algoritma pembelajaran mesin tradisional.
Diagram alir penelitian ini dapat dilihat di bawah ini.
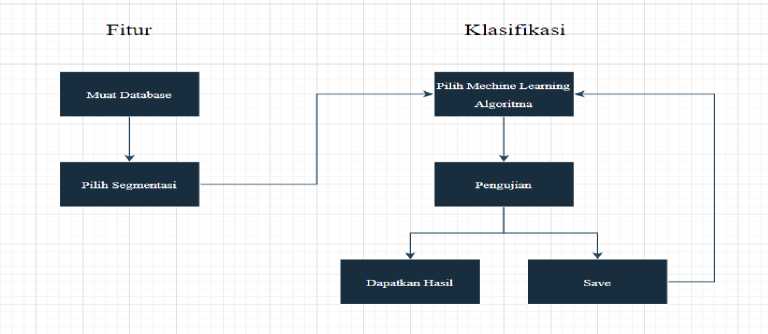
Gambar 2. Flowchart Penelitian
-
a. Sobel
Operator Sobel, dikenal sebagai operator Sobel-Feldman atau filter Sobel, adalah teknik perbaikan citra yang diciptakan oleh Irwin Sobel dan Gary Feldman. Tujuannya adalah untuk menekankan tepi gambar dengan memperkirakan gradien intensitas gambar. Ini dilakukan dengan menerapkan filter kecil, dapat dipisahkan, dan bernilai bilangan bulat ke gambar dalam arah horizontal (Gx) dan vertikal (Gy).
1+1
+2 0
-2
+1 0
-1
∣
* A
(1)
Selain itu, operator Sobel efisien dalam hal sumber daya komputasi, menjadikannya pilihan yang hemat biaya. Jika kita menganggap A sebagai citra, persamaan tersebut mengilustrasikan proses penerapan operasi konvolusi ke setiap piksel dalam citra. Operasi ini melibatkan melakukan perhitungan sepanjang sumbu horizontal dan vertikal, yang diwakili oleh simbol *.
Gx
= √gx2 + Gy2
(2)
Untuk memperoleh perkiraan gradien, persamaan yang disebutkan sebelumnya melibatkan perhitungan akar kuadrat dari jumlah komponen kuadrat dari gradien horizontal dan vertikal. Pemanfaatan operator Sobel telah menguntungkan dalam berbagai aplikasi seperti pengenalan sidik jari, pembuatan peta tepi satelit yang realistis, dan peningkatan visi robotika [4]. Dengan mengintegrasikan filter Sobel ke dalam algoritma deteksi, pemrosesan gambar dapat dipercepat, menghasilkan waktu pengambilan yang lebih cepat. Hal ini dicapai dengan menggunakan Gray Level CoOccurrence Matrix (GLCCM) di samping filter [5]. Selain itu, filter disarankan untuk analisis citra radar jarak jauh dari berbagai perspektif, sehingga meningkatkan kinerja pendekatan berbasis histogram [5].
-
b. Prewitt
Metode Prewitt menggunakan operasi konvolusi dengan kernel Prewitt pada citra. Kernel Prewitt terdiri dari dua matriks, yaitu kernel horizontal dan kernel vertikal. Kernel horizontal pada metode Prewitt memiliki elemen matriks yang memberikan bobot yang lebih tinggi pada piksel-piksel di sekitar sumbu horizontal, sedangkan kernel vertikal memberikan bobot yang lebih tinggi pada piksel-piksel di sekitar sumbu vertikal. Sebuah studi baru telah mengusulkan metode yang menggabungkan Prewitt dengan representasi kuantum canggih yang disebut NEQR, yang telah menunjukkan keefektifan yang mengesankan dalam mengekstraksi tepi. Pendekatan ini telah ditemukan menjadi algoritma yang sangat efisien [7]. Ketika diterapkan pada gambar medis yang disimulasikan, khususnya data MRI, Prewitt telah menunjukkan kemampuan pencarian lokal yang kuat dan kecepatan konvergensi yang cepat. Penerapan filter ini telah menghasilkan tingkat akurasi yang luar biasa sebesar 100% saat diuji pada berbagai dataset tumor otak yang dapat diakses secara terbuka seperti BMIBTB, CE-MRI, dan FSB [8].
-
c. Robert
Pada tahun 1963, Lawrence Roberts mengusulkan operator Robert, sebuah metode untuk memperkirakan gradien citra melalui diferensiasi diskrit. Teknik ini melibatkan evaluasi varians kuadrat antara sumbu horizontal dan vertikal, lalu menjumlahkannya untuk memperkirakan gradien gambar.
r +1 ,M'0 +lι (3) L 0 -1] L-1 o ]
Pertama, gambar yang diberikan mengalami konvolusi menggunakan filter, yaitu Gx untuk sumbu horizontal dan Gy untuk sumbu vertikal. Setelah itu, gradien dihitung dengan menggunakan persamaan berikut. Nilai gradien yang diperoleh kemudian digunakan sebagai I(x,y) untuk memperkirakan gradien citra. Persamaan yang disarankan Lawrence Robert, ketika digunakan bersamaan dengan Balance Contrast Enhancement Technique (BCET), terbukti efisien dalam meningkatkan karakteristik citra medis [9]. Integrasi operator Robert dengan algoritma aturan fuzzy Mamdani (Tipe-2) untuk deteksi pembuluh darah, bersama dengan Penyetaraan Histogram Adaptif Kontras-Terbatas (CLAHE), membantu dalam partisi gambar retina dengan mengekstraksi informasi gradiennya. Metodologi ini memberikan kontribusi yang signifikan untuk mencapai penentuan ambang batas yang tepat dan pada akhirnya meningkatkan akurasi aplikasi secara keseluruhan [10].
-
d. Scharr
Scharr adalah metode alternatif dalam pengolahan citra untuk mendeteksi tepi atau perubahan intensitas yang tajam antara piksel-piksel dalam gambar. Metode ini serupa dengan metode Sobel dan Prewitt, tetapi menggunakan kernel Scharr yang memiliki respons lebih sensitif terhadap perubahan intensitas yang halus. Operator filter Scharr digunakan untuk mengidentifikasi dan menyorot tepi atau karakteristik gradien dalam gambar dengan memanfaatkan turunan pertama.
Mirip dengan teknik Sobel dan Prewitt, algoritma ini memperkirakan gradien gambar dengan menggabungkan gambar dengan filter kecil, dapat dipisahkan, dan berbasis bilangan bulat baik dalam arah horizontal (Gx) maupun vertikal (Gy). Dengan menerapkan filter ini ke nilai intensitas gambar, akan lebih mudah untuk mendeteksi tepi atau fitur gradient. Untuk mendapatkan estimasi gradien tersebut di atas, akar kuadrat dari setiap dimensi dimasukkan ke dalam persamaan sebagai berikut.
(5)
g = Jgx2 + Gy2
-
e. Canny
Metode Canny adalah salah satu metode yang populer dalam pengolahan citra untuk mendeteksi tepi dengan presisi tinggi. Metode ini dikembangkan oleh John F. Canny pada tahun 1986 dan sering digunakan dalam berbagai aplikasi pengolahan citra dan pengenalan pola. Deteksi tepi melibatkan penggunaan teknik matematis untuk mengidentifikasi titik-titik dalam gambar di mana ada pergeseran intensitas piksel yang signifikan, secara efektif mendeteksi batas objek yang ada dalam gambar. Ini memerlukan pendeteksian perubahan kecerahan dan salah satu pendekatan populer untuk deteksi tepi dikenal sebagai Canny Edge Detection.
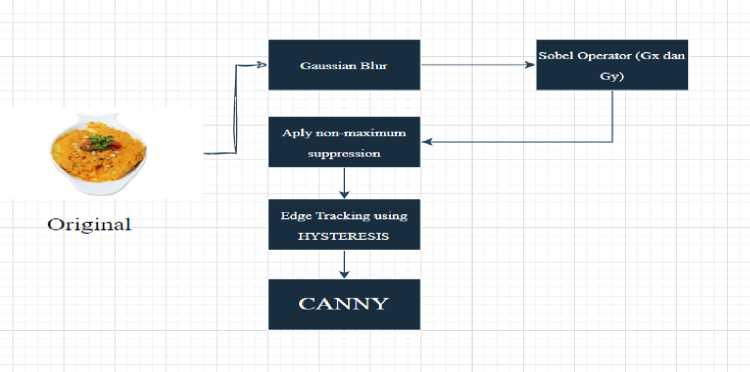
Gambar 3. Teknik Canny pada foto yang menampilkan masakan asli Sumatera Utara
Penerapan teknik Gaussian blur melibatkan penggabungan gambar dengan kernel filter Gaussian untuk mengurangi adanya noise. Tingkat kekaburan yang diterapkan pada gambar ditentukan oleh ukuran kernel, yang ditunjukkan dengan dimensi seperti 3x3 atau 7x7. Ukuran kernel yang lebih besar menghasilkan efek buram yang lebih kuat. Prosedur ini membantu mengurangi fluktuasi kecil dalam intensitas piksel yang disebabkan oleh derau, sekaligus mempertahankan tepi penting yang ada dalam gambar.
G(χ,y)
1
2πσ2
■ exp
x2 + y2' (-^σr,
(6)
Persamaan yang diberikan menunjukkan nilai filter Gaussian pada koordinat (x, y) yang diberikan, di mana σ mewakili standar deviasi distribusi Gaussian.
M =
√G2+⅛
(7)
Perhitungan Gradien: Algoritma Canny menggunakan operator Sobel untuk menentukan kekuatan dan orientasi gradien pada setiap piksel. Prosedur ini memerlukan penerapan dua kernel konvolusi: satu untuk mendeteksi gradien horizontal (Gx) dan satu lagi untuk mengidentifikasi gradien vertikal (Gy). Penekanan Non-maksimum: Untuk meningkatkan akurasi tepi yang teridentifikasi, metode ini diterapkan. Teknik ini memerlukan pemeriksaan besaran gradien piksel dan membandingkannya dengan besaran piksel tetangga dalam arah gradien yang sama. Jika piksel memiliki magnitudo tertinggi di antara tetangganya, piksel tersebut dipertahankan. Namun, jika tidak memiliki magnitudo tertinggi, maka akan ditekan dan diberi nilai nol. Ambang Batas Ganda: Teknik ambang ganda mencakup penggunaan dua ambang batas pada besaran gradien. Ambang batas ini terdiri dari ambang tinggi dan ambang rendah. Piksel dengan besaran gradien lebih tinggi dari ambang batas tinggi dikenali sebagai piksel tepi yang kuat, sedangkan piksel dengan besaran lebih rendah dari ambang batas rendah dianggap sebagai piksel non-tepi dan diabaikan. Piksel dengan besaran yang berada di antara dua ambang dikategorikan sebagai piksel tepi lemah.Pelacakan Tepi dengan Histeresis: Tahap selanjutnya melibatkan penautan piksel yang kurang menonjol di sepanjang tepi ke piksel yang lebih menonjol. Ini dimulai dengan piksel tepi yang menonjol dan berlanjut dengan mengikuti jalur piksel tepi yang kurang menonjol yang terhubung di dalam area terdekat. Proses penelusuran ini berlanjut hingga semua piksel tepi yang kurang menonjol yang tersisa terhubung. Akibatnya, kumpulan garis tepi yang tidak terputus tercapai. Algoritma Canny menggabungkan filter median dan filter Gaussian untuk secara efektif menghilangkan noise dari gambar sambil mempertahankan detail penting dan menghadirkan kekaburan halus [15]. Ini banyak digunakan untuk deteksi tepi dan
menawarkan fleksibilitas dalam menyesuaikan kualitas keluaran dengan memanipulasi parameter deteksi tepi [16]. Dalam penelitian medis, seperti analisis tuberkulosis, penggunaan filter Canny untuk mengelompokkan gambar paru-paru telah menunjukkan akurasi sebesar 93,59% dan akurasi sensitivitas sebesar 92,31% [17]. Dalam pengawasan video, mengintegrasikan algoritma Canny dengan transformasi Hough pada platform seperti Hadoop dan Spark memberikan kinerja dan skalabilitas yang sangat baik untuk memproses kumpulan data besar [18]. Integrasi ini memungkinkan deteksi jalur yang efisien, mengaktifkan pelacakan, pemantauan, dan perekaman aktivitas. Metode segmentasi ini sangat penting untuk meningkatkan akurasi algoritma dengan secara akurat mengidentifikasi wilayah yang diminati dalam gambar. Kombinasi deteksi tepi Canny dan transformasi kontur dengan dekomposisi nilai singular digunakan untuk membuat skema watermarking yang kuat dan tidak terdeteksi. Algoritma yang diusulkan telah diuji dan ternyata tahan terhadap serangan umum [19]. Dengan menggabungkan YOLO dan Canny, akurasi 62,60% pada Mean Average Precision (mAP) dicapai dalam mendeteksi kecelakaan di jalan raya dalam kumpulan data tertentu. Model ini memiliki kemampuan untuk menggeneralisasi gambar tersegmentasi dan meningkatkan fitur yang dipelajari [20]. Canny filter digunakan dalam skema komputasi yang menjaga privasi untuk mempertahankan permutasi piksel yang aman selama protokol multiplikasi, memastikan keamanan yang ditingkatkan [21]. Dalam metode segmentasi api, Canny digunakan sebagai alat segmentasi utama untuk mengidentifikasi api pada suatu citra. Model yang diusulkan secara efektif menyoroti tepi dengan menekan kebisingan dan mencapai akurasi 98%, mengungguli operator Sobel [22]. Sebuah sistem parkir cerdas, yang dilatih menggunakan Canny, berhasil mendeteksi kendaraan yang masuk dan keluar dari tempat parkir melalui pemanfaatan servomotors dan sensor [23]. Selain itu, sistem pendeteksi banjir menggabungkan filter Canny dengan metode SCED (Sobel Canny Edge Detection) untuk memantau ketinggian air. Sistem ini menggunakan bola oranye untuk menunjukkan kenaikan permukaan air selama percobaan pendeteksian permukaan air [24].
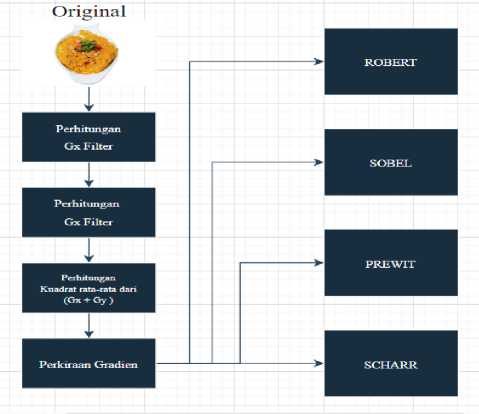
Gambar 3. Pemanfaatan algoritma Sobel, Prewitt, Robert, dan Scharr pada foto masakan tradisional Sumatera Utara
Menggunakan teknik segmentasi seperti yang ditunjukkan pada gambar 3, algoritma dapat memisahkan dan menekankan wilayah penting, yang mengarah ke peningkatan ketepatan tugas selanjutnya.
Untuk menganalisis karakteristik dari gambar yang menggambarkan masakan tradisional Sumatera Utara, digunakan teknik pembelajaran mesin konvensional. Tujuh algoritma yang sudah ada sebelumnya, termasuk Random Forest, Decision Tree, KNN, Linear SVM, Rbf SVM, Polynomial SVM, dan Sigmoid SVM, digunakan untuk mengevaluasi keefektifannya dalam mengklasifikasikan fitur yang relevan dari citra makanan. Algoritma pra-pelatihan ini diperoleh dari API perpustakaan scikit-learn melalui prosedur pengunduhan.
-
a. Random Forest
Adalah algoritma pembelajaran terawasi yang banyak digunakan dan cocok untuk tugas klasifikasi dan regresi. Ini beroperasi berdasarkan prinsip pembelajaran ansambel, yang melibatkan penggabungan beberapa pengklasifikasi untuk mengatasi masalah yang kompleks dan meningkatkan kinerja algoritma. Random Forest seperti namanya, mempekerjakan banyak pohon keputusan yang dilatih pada himpunan bagian yang berbeda dari kumpulan data yang diberikan, dan kemudian rata – rata prediksi mereka untuk meningkatkan akurasi prediksi secara keseluruhan. Daripada mengandalkan satu pohon keputusan, hutan acak mengumpulkan prediksi dari setiap pohon dan menentukan hasilnya berdasarkan suara mayoritas [26]. Dengan menambah jumlah pohon di hutan, akurasi yang lebih tinggi dapat dicapai sambil mengurangi risiko overfitting [27]. Random Forest sebagai algoritma yang ideal karena mampu menangkap hubungan yang kompleks antara variabel prediktor dan data yang diamati [25]. Ini menguntungkan Random Forest untuk dapat menangani kumpulan data besar dengan jumlah variabel prediktor yang besar. Setiap pohon keputusan dibangun menggunakan himpunan bagian ini, yang bertujuan untuk memaksimalkan perolehan informasi atau meminimalkan ketidakmurnian di setiap node. Selama prediksi, contoh baru dilewatkan melalui setiap pohon keputusan, dan prediksi akhir diperoleh dengan menggabungkan prediksi dari semua pohon melalui pemungutan suara mayoritas (untuk klasifikasi) atau rata-rata (untuk regresi). Secara matematis, prediksi ansambel untuk klasifikasi dapat direpresentasikan sebagai:
N
y
= arg max y
∑1(y = y)
(8)
di mana y ̂ adalah kelas prediksi akhir, y mewakili kemungkinan label kelas, N adalah jumlah total pohon keputusan di Hutan Acak, y_i adalah prediksi pohon keputusan ke-i, dan I(y_i=y) adalah fungsi indikator yang mengembalikan 1 jika kondisinya benar dan 0 jika tidak [41]. Hutan acak, seperti namanya, mempekerjakan banyak pohon keputusan yang dilatih pada himpunan bagian yang berbeda dari kumpulan data yang diberikan, dan kemudian rata-rata prediksi mereka untuk meningkatkan akurasi prediksi secara keseluruhan. Daripada mengandalkan satu pohon keputusan, hutan acak mengumpulkan prediksi dari setiap pohon dan menentukan hasilnya berdasarkan suara mayoritas [26]. Dengan menambah jumlah pohon di hutan, akurasi yang lebih tinggi dapat dicapai sambil mengurangi risiko overfitting [27]. Random Forest sebagai algoritma yang ideal karena mampu menangkap hubungan yang kompleks antara variabel prediktor dan data yang diamati [25]. Ini menguntungkan Random Forest untuk dapat menangani kumpulan data besar dengan jumlah variabel prediktor yang besar [26][27].
-
b. Decision Tree
Algoritma Pohon Keputusan adalah teknik pembelajaran mesin populer yang membangun algoritma seperti pohon untuk membuat keputusan. Ini beroperasi secara top-down, mempartisi dataset secara rekursif berdasarkan fitur yang dipilih untuk membuat struktur pohon. Setiap simpul internal pohon mewakili uji fitur, sedangkan simpul daun sesuai dengan label kelas yang diprediksi atau nilai regresi. Pembangunan pohon keputusan melibatkan pencarian fitur terbaik dan ambang batas untuk pemisahan
pada setiap node internal. Ini dilakukan dengan mengevaluasi kriteria pemisahan yang berbeda, seperti Indeks Gini atau Penguatan Informasi, yang mengukur kualitas pemisahan berdasarkan ketidakmurnian atau pengurangan ketidakpastian yang diberikannya. Indeks Gini adalah kriteria pemisahan umum yang digunakan dalam pohon keputusan. Ini mengukur ketidakmurnian kumpulan data, di mana nilai yang lebih rendah menunjukkan distribusi kelas yang lebih homogen. Untuk masalah klasifikasi biner, Indeks Gini dapat dinyatakan sebagai:
C
(9)
Gini(D,c^) = 1
∑ "■■
l=1
di mana Gini(D) adalah Gini Index dari dataset D, c adalah jumlah kelas, dan p_i mewakili probabilitas sebuah instance milik kelas i dalam dataset D. Indeks Gini dihitung untuk setiap fitur kandidat dan kombinasi ambang batas, dan fitur dan ambang batas yang meminimalkan pengotor dipilih untuk pemisahan [41]. Algoritma pohon keputusan berlanjut secara rekursif, membuat simpul anak untuk setiap kemungkinan hasil pemisahan. Proses ini diulangi sampai kriteria pemberhentian terpenuhi, seperti mencapai kedalaman maksimum, memiliki jumlah minimum contoh per daun, atau mencapai simpul daun murni di mana semua contoh termasuk dalam kelas yang sama.
-
c. Linear SVM
Algoritma Linear SVM adalah metode pembelajaran mesin populer yang digunakan untuk tugas klasifikasi biner. Ini bertujuan untuk menemukan hyperplane optimal yang memisahkan titik data milik kelas yang berbeda secara linear dipisahkan. Algoritma beroperasi dengan memaksimalkan margin, yaitu jarak antara hyperplane dan titik data terdekat dari masing-masing kelas. dan akurasi validasi yang melebihi 60% disimpan untuk analisis lebih lanjut. Algoritma yang dipilih ini selanjutnya digunakan dalam proses klasifikasi menggunakan algoritma pembelajaran yang diawasi. Diberikan dataset pelatihan dengan vektor fitur x_i dan label kelas yang sesuai y_i (di mana y_ie\ {-1,1∖}), tujuan SVM Linier adalah untuk menemukan vektor bobot optimal w dan suku bias b yang menentukan hyperplane pemisah. Fungsi keputusan dari Linear SVM didefinisikan sebagai:
f(x) = sign(w∙x + 6) (10)
Masalah optimisasi untuk Linear SVM dapat dirumuskan sebagai berikut:
∖yl(w ■ xt + b) ≥ 1, for all i = 1,2,^,N] (11)
di mana N adalah jumlah contoh pelatihan. Fungsi tujuan bertujuan untuk meminimalkan norma vektor bobot, mempromosikan margin yang besar antar kelas. Kendala memastikan bahwa titik data diklasifikasikan dengan benar dan berada di atas atau di luar margin. Linear SVM mengatasi masalah overfitting dengan mengidentifikasi hyperplane terbaik untuk secara efektif memisahkan titik data yang termasuk dalam kelas atau kategori yang berbeda [28]. Contoh penting dari kinerjanya ditunjukkan pada kumpulan data UNSW-NB15 baru-baru ini, di mana SVM mencapai tingkat akurasi yang mengesankan sebesar 93,75% [29]. Selain itu, ketika diterapkan pada kumpulan data yang berisi gambar kanker payudara dan paru-paru, algoritma SVM mencapai skor akurasi luar biasa sebesar 99% pada kumpulan data uji [31].
-
d. Sigmoid SVM
Algoritma Sigmoid SVM adalah varian dari Support Vector Machine yang menggunakan fungsi sigmoid sebagai fungsi keputusan, bukan fungsi linier. Ini biasanya digunakan untuk tugas klasifikasi biner dan dapat menangani data yang tidak dapat dipisahkan secara linier dengan memetakannya ke dalam ruang fitur berdimensi lebih tinggi.
Diberikan dataset pelatihan dengan vektor fitur x_i dan label kelas yang sesuai y_i (di mana y_i∈\{-1,1\}), tujuan dari SVM Sigmoid adalah untuk menemukan vektor bobot optimal w dan istilah bias b yang menentukan batas keputusan. Fungsi keputusan dari SVM Sigmoid didefinisikan sebagai:
[f(x) = sign
(∑
αlylσ(xl ■ x + b0) + b
)l
(12)
di mana N adalah jumlah instance pelatihan, α_i adalah pengali Lagrange yang diperoleh selama proses pengoptimalan, σ (■) adalah fungsi sigmoid, x_i adalah vektor pendukung, dan b_0 dan b adalah suku bias. Masalah pengoptimalan untuk SVM Sigmoid melibatkan meminimalkan fungsi tujuan sehubungan dengan α_i dan b, tunduk pada kendala:
[0 ≤ α, ≤ C,
N
∑ αιyι = 0] 1=1
(13)
di mana C adalah parameter regularisasi yang mengontrol trade-off antara memaksimalkan margin dan meminimalkan kesalahan pelatihan [41]. Algoritma SVM menunjukkan kinerja yang luar biasa, mencapai skor akurasi yang mengesankan sebesar 99% saat digunakan pada kumpulan gambar kanker payudara dan paru-paru [31]. Dalam bidang penelitian gangguan otak, SVM umumnya digunakan dalam analisis pola multivoxel (MVPA) karena kapasitasnya untuk menangani data pencitraan dimensi tinggi secara efektif, menghindari overfitting. Baru-baru ini, SVM menjadi semakin relevan dalam psikiatri presisi, khususnya dalam memprediksi diagnosis dan prognosis penyakit otak seperti penyakit Alzheimer, skizofrenia, dan depresi [32]. Di bidang ilmu ekonomi, penggunaan SVM untuk peramalan keuangan pada dataset deret waktu telah mendapat perhatian yang signifikan. Telah diamati bahwa algoritma SVM yang diusulkan melampaui algoritma lain dalam memprediksi nilai tukar dalam pasar keuangan, menunjukkan keefektifannya dalam mencapai kinerja peramalan yang unggul, yang sangat penting mengingat krisis ekonomi global baru-baru ini.
-
e. RBF SMV
Algoritma RBF SVM merupakan varian dari Support Vector Machine yang menggunakan kernel Radial Basis Function (RBF) sebagai dasar klasifikasi. Ini adalah algoritma yang kuat yang mampu menangani data yang dapat dipisahkan secara linear dan non-linear dengan memetakannya ke dalam ruang fitur berdimensi lebih tinggi. Diberikan dataset pelatihan dengan vektor fitur x_i dan label kelas yang sesuai y_i (di mana y_i∈\{-1,1\}), tujuan RBF SVM adalah untuk menemukan hyperplane optimal yang secara maksimal memisahkan titik data milik kelas yang berbeda. Fungsi keputusan dari RBF SVM didefinisikan sebagai:
[f(x) = sign
(∑
αlylK(xl,x) + b
)l
(14)
di mana N adalah jumlah instance pelatihan, α_i adalah pengali Lagrange yang diperoleh selama proses optimasi, σ (■) adalah fungsi sigmoid, x_i adalah vektor pendukung, dan b_0 dan b adalah suku bias [41]. Masalah pengoptimalan untuk RBF SVM melibatkan meminimalkan fungsi tujuan sehubungan dengan α_i dan b, tunduk pada kendala:
[0 ≤ α, ≤ C,
N
∑ α⅛yi =0] 1=1
(15)
di mana C adalah parameter regularisasi yang mengontrol trade-off antara
memaksimalkan margin dan meminimalkan kesalahan pelatihan. Menerapkan SVM ke set data COVID-19, para peneliti mencapai akurasi sensitivitas rata-rata 95,76%
menggunakan gambar sinar-X format jpeg 512x512 piksel [35]. Dengan menggabungkan SVM, menerapkan high pass filter menggunakan Sobel untuk mendapatkan edge, mereka mampu mencapai akurasi 99,76% dan akurasi sensitivitas 100% pada dataset COVID-19 [36][37]. Di bidang pencitraan medis, metode baru yang menggabungkan SVM dengan Depthwise Separable Convolution Neural Network telah menunjukkan kinerja yang sangat baik pada dataset citra Chest X-ray (CXR). Pendekatan ini mencapai akurasi 98,54% untuk klasifikasi biner dan 99,06% untuk klasifikasi multikelas, menawarkan janji dalam mendiagnosis dan mengklasifikasikan kasus COVID-19 secara akurat menggunakan data pencitraan medis
-
f. Polinomial SVM
Algoritma Polynomial SVM adalah varian dari Support Vector Machine yang menggunakan fungsi kernel polinomial sebagai dasar klasifikasi. Ini biasanya digunakan untuk tugas klasifikasi biner dan dapat menangani data yang tidak dapat dipisahkan secara linier dengan memetakannya ke dalam ruang fitur berdimensi lebih tinggi. Diberikan dataset pelatihan dengan vektor fitur x_i dan label kelas yang sesuai y_i (di mana y_i∈\{-1,1\}), tujuan SVM Polinomial adalah untuk menemukan hyperplane optimal yang memisahkan titik data milik kelas yang berbeda. Fungsi keputusan dari Polynomial SVM didefinisikan sebagai:
[f(x) = sign (∑ αiyi(xi ■x + c') + b)
(16)
]
di mana N adalah jumlah instance pelatihan, α_i adalah pengali Lagrange yang diperoleh selama proses optimasi, y_i adalah label kelas, c adalah suku konstan, d adalah derajat kernel polinomial, x_i adalah vektor pendukung, dan b adalah istilah bias. Fungsi kernel polinomial didefinisikan sebagai:
K(xl,x) = (xl∙ x + C^d
(17)
di mana c adalah suku konstan dan d adalah derajat kernel polinomial. Kernel polinomial menghitung kesamaan antara dua vektor berdasarkan produk titiknya yang dinaikkan ke derajat yang ditentukan. Masalah pengoptimalan untuk Polinomial SVM melibatkan meminimalkan fungsi tujuan sehubungan dengan α_i dan b, tunduk pada kendala:
[0 ≤ αi ≤ C,
N
∑ αιyι = 0] 1=1
(18)
di mana C adalah parameter regularisasi yang mengontrol trade-off antara memaksimalkan margin dan meminimalkan kesalahan pelatihan [41]. Poly SVM digunakan untuk menganalisis kumpulan data tweet COVID-19, menunjukkan tingkat akurasi 80% dan skor f1 81,84% [30]. Studi lain menyelidiki perbedaan antara dataset gambar X-ray normal, pneumonia, dan COVID-19 dengan menggunakan SVM sebagai kerangka dasar, menghasilkan akurasi yang mengesankan sebesar 97,33% di ketiga kelas [38]. Seperti kumpulan data sebelumnya, SVM digabungkan dengan model VGG16 dengan parameter yang disesuaikan untuk mengekstraksi fitur dari citra CT. Penggabungan ini menyebabkan model mencapai waktu pemrosesan cepat 385ms, sambil mempertahankan akurasi tinggi 95,7% pada 208 citra uji menurut kurva AUC [39]. Selain itu, metode yang disebut CSVM, yang menggabungkan SVM dengan Convolutional Neural Network, mengusulkan akurasi rata-rata 94% dan akurasi 96,09% yang mengesankan dalam penentuan sensitivitas untuk gambar CT [40]. Setelah menerapkan algoritma pembelajaran mesin tradisional ini untuk mengklasifikasikan data,
keefektifan algoritma akan dinilai menggunakan berbagai metode evaluasi. Penilaian akan mencakup metrik seperti akurasi, presisi, daya ingat, dan skor F1, yang secara kolektif mengukur seberapa baik performa algoritma. Selain itu, waktu yang dibutuhkan oleh setiap algoritma untuk mengklasifikasikan data akan diukur dan dilaporkan, memberikan informasi berharga tentang efisiensi komputasi algorithm.
Berdasarkan gambar. 4, terbukti bahwa Random Forest menunjukkan akurasi pelatihan mendekati 1, sedangkan KNN tampil buruk di set ini.
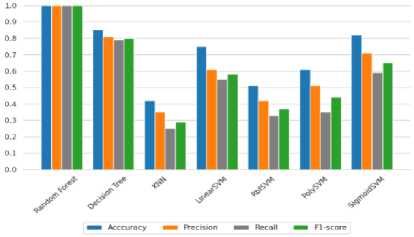
Gambar 4. Pelatihan akurasi dari setiap grafik algoritma pembelajaran mesin tradisional menggunakan Sobel
Berdasarkan gambar. 5, Random Forest melakukan yang terbaik pada pengujian dataset dengan metode segmentasi Sobel. Adapun sisanya rata-rata buruk kecuali KNN yang berkinerja paling buruk pada dataset ini.
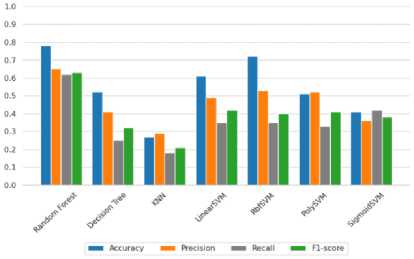
Gambar 5. Menguji akurasi setiap grafik algoritma pembelajaran mesin tradisional menggunakan Sobel
Seperti yang digambarkan pada gambar 6, ini menunjukkan bahwa 4 keluarga SVM tidak berkinerja terlalu baik pada dataset pengujian dengan segmentasi Prewitt Sementara itu, algoritma Random Forest melakukan rata-rata yang layak pada 0,9 atau 90% di seluruh metriknya sementara sebagian besar keluarga SVM tidak berkinerja terlalu baik.
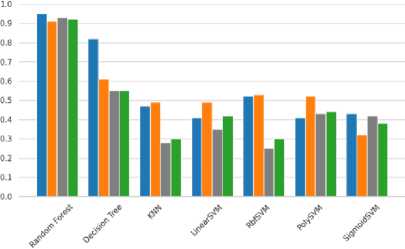
Accuracy ^a Precision ^a Recall ^a Fl-score
Gambar 6. Pelatihan akurasi dari setiap grafik algoritma pembelajaran mesin tradisional menggunakan Prewitt
Hasil yang ditunjukkan pada gambar. 7 dengan jelas menunjukkan bahwa Random Forest mempertahankan algoritma berkinerja tertinggi teratas dalam dataset ini menggunakan metode segmentasi Prewitt, memberikan kinerja tertinggi yang menguntungkan. Selain itu,perlu dicatat bahwa Pohon Keputusan mengungguli algoritma lain juga.
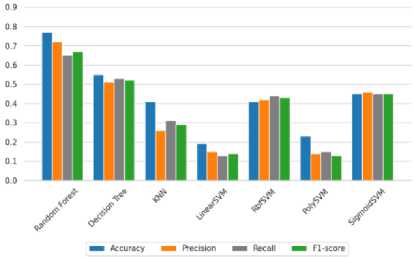
Gambar 7. Menguji akurasi setiap grafik algoritma pembelajaran mesin tradisional menggunakan Prewitt
Berdasarkan gambar. 8, algoritma menunjukkan kinerja yang luar biasa pada dataset pelatihan terutama Hutan Acak yang mencapai rata-rata 0,9 atau 90% pada metriknya. Namun, ketika menggunakan algoritma Linear SVM, tampaknya algoritma tersebut tidak bekerja dengan baik jika dibandingkan dengan algoritma lainnya.
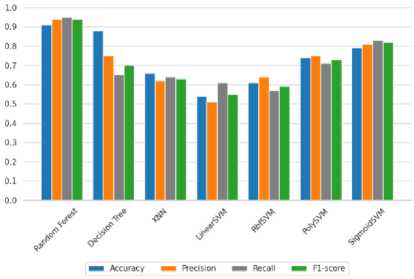
Gambar 8. Pelatihan akurasi setiap grafik algoritma pembelajaran mesin tradisional menggunakan Robert
Berdasarkan gambar. 9, Random Forest mencapai metrik rata-rata tertinggi pada dataset tak terlihat, sehingga dianggap sebagai algoritma terbaik untuk dataset ini menggunakan metode segmentasi Robert.
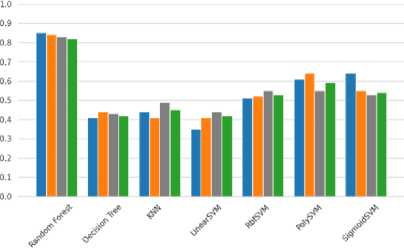
Accuracy v Precision ^b Recall ^b Fl-score
Gambar 9. Menguji akurasi setiap grafik algoritma algoritma mesin tradisional menggunakan Robert
Berdasarkan gambar. 10, di antara algoritma yang dievaluasi, Random Forest mencapai akurasi pelatihan tertinggi saat digabungkan dengan operator Scharr untuk segmentasi gambar. Algoritma seperti Linear dan Rbf SVM juga mencapai hasil yang memuaskan.
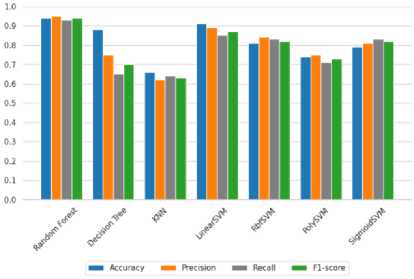
Gambar 10. Pelatihan akurasi dari setiap grafik algoritma pembelajaran mesin tradisional menggunakan Scharr
Berdasarkan gambar. 11, algoritma tidak menghasilkan hasil yang memuaskan pada kumpulan data pengujian, menunjukkan kemampuan terbatas untuk menggeneralisasi secara efektif dalam hal segmentasi Scharr.
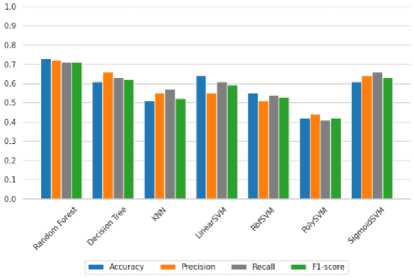
Gambar 11. Menguji akurasi setiap grafik algoritma pembelajaran mesin tradisional menggunakan Scharr
Berdasarkan gambar. 12, di antara algoritma yang diuji, Random Forest mencapai akurasi pelatihan tertinggi saat digabungkan dengan operator Canny, juga, Linear SVM mencapai hasil yang memuaskan selain Random Forest. Namun, beberapa algoritma tidak sepuas yang seharusnya.
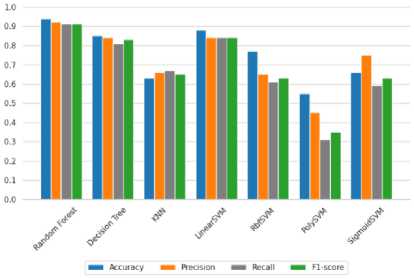
Gambar 12. Pelatihan akurasi dari setiap grafik algoritma pembelajaran mesin tradisional menggunakan Canny
Berdasarkan gambar. 13, algoritma terkait akurasi pengujian yang dicapai oleh operator Canny tidak memuaskan karena beberapa menunjukkan hasil rata-rata dibawah 0,7 atau 70% kecuali untuk Hutan Acak yang rata-rata 0,8 atau 80%.
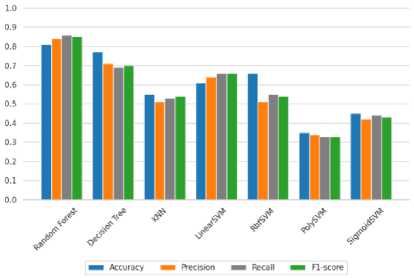
Gambar 13. Menguji akurasi setiap grafik algoritma pembelajaran mesin tradisional menggunakan Canny
Tabel 1: Waktu Eksekusi Random Forest
|
Algorithms |
Time |
|
Random Forest (Sobel) |
1min 34s |
|
Random Forest (Prewitt) |
1min 29s |
|
Random Forest (Scharr) |
1min 27s |
|
Random Forest (Robert) |
1min 51s |
|
Random Forest (Canny) |
1min 37s |
|
Sigmoid SVM (Scharr) |
7min 44s |
-
6 (enam) algoritma terbaik pada dataset pengujian:
-
a. Hutan Acak dengan operator Sobel
-
b. Hutan Acak dengan operator Prewitt
1. Akurasi
: 0,7711
2. Ingat
: 0,7262
3. Presisi
: 0,6578
4. Skor F1
: 0,6791
-
c. Hutan Acak dengan operator Robert
-
1. Akurasi : 0,8552
-
2. Ingat : 0,8463
-
3. Presisi : 0,8377
-
4. Skor F1 : 0,8249
d. Hutan Acak dengan operator Scharr
|
: 0,7346 : 0,7241 : 0,7123 : 0,7149 |
-
e. Hutan Acak dengan operator Canny
-
1. Akurasi : 0,8151
-
2. Ingat : 0,8497
-
3. Presisi : 0,8681
-
4. Skor F1 : 0,8561
-
f. Sigmoid SVM dengan operator Scharr
1. Akurasi
: 0,6445
2. Ingat
: 0,5578
3. Presisi
: 0,6172
4. Skor F1
: 0,5991
Berdasarkan hasil yang telah disebutkan sebelumnya, algoritma Random Forest dengan menggunakan metode segmentasi Scharr menunjukkan waktu eksekusi yang jauh lebih cepat dibandingkan dengan algoritma lainnya. Terlepas dari keunggulan waktu ini, algoritma hutan acak mengungguli sebagian besar metode segmentasi, dengan skor rata-rata 0,70 atau 70% di semua metrik. Sebaliknya, algoritma Sigmoid SVM membutuhkan waktu paling lama untuk dieksekusi di antara semua algoritma dan menghasilkan skor yang lebih rendah, tetapi masih dianggap sebagai salah satu dari 6 algoritma dengan kinerja terbaik.
-
4. Kesimpulan
Menurut temuan yang disajikan, algoritma Random Forest dengan operator Robert menonjol sebagai yang terbaik. Meskipun berjalan sedikit lebih lama dibandingkan dengan algoritma Random Forest lainnya menggunakan metode segmentasi yang berbeda, algoritma Random Forest secara konsisten menunjukkan kinerja yang unggul di semua enam algoritma. Perbedaan waktu eksekusi berkisar 10-15 detik lebih lambat.
Daftar Pustaka
-
[1] Wibisono, A., Wisesa, H.A., Rahmadhani, Z.P. et al. Traditional food knowledge of Indonesia: a new high-quality food dataset and automatic recognition system. J Big Data 7, 69 (2020). https://doi.org/10.1186/s40537-020-00342-5
-
[2] D. Sarwinda et al., "Automatic Multi-class Classification of Indonesian Traditional Food using Convolutional Neural Networks," 2020 3rd International Conference on Computer and Informatics Engineering (IC2IE), Yogyakarta, Indonesia, 2020, pp. 43-47, doi: 10.1109/IC2IE50715.2020.9274636.
-
[3] Dian Ade Kurnia et al 2021 J. Phys.: Conf. Ser. 1783 012047
-
[4] Chen, G., Jiang, Z., & Kamruzzaman, M. M. (2020). Radar remote sensing image
retrieval algorithm based on improved Sobel operator. Journal of Visual Communication and Image Representation, 71, 102720.
-
[5] Ravivarma, G., Gavaskar, K., Malathi, D., Asha, K. G., Ashok, B., & Aarthi, S. (2021). Implementation of Sobel operator-based image edge detection on FPGA. Materials Today: Proceedings, 45, 2401-2407.
-
[6] Zhou, R. G., Yu, H., Cheng, Y., & Li, F. X. (2019). Quantum image edge extraction based on improved Prewitt operator. Quantum Information Processing, 18, 1-24.
-
[7] Song, Y., Ma, B., Gao, W., & Fan, S. (2019). Medical Image Edge Detection Based on Improved Differential Evolution Algorithm and Prewitt Operator. Acta Microscopica, 28(1).
-
[8] Liao, B., Chen, X., Yu, Y., & Li, Y. Few-Shot Brain Tumor MRI Image Classification Using Graph Isomorphic Network and Prewitt Operator. Xiaokun and Yu, Yang and Li, Yong, Few-Shot Brain Tumor MRI Image Classification Using Graph Isomorphic Network and Prewitt Operator.
-
[9] Abdel-Gawad, A. H., Said, L. A., & Radwan, A. G. (2020). Optimized edge detection technique for brain tumor detection in MR images. IEEE Access, 8, 136243-136259.
-
[10] Orujov, F., Maskeliūnas, R., Damaševičius, R., & Wei, W. J. A. S. C. (2020). Fuzzy based image edge detection algorithm for blood vessel detection in retinal images. Applied Soft Computing, 94, 106452.
-
[11] G. N. Chaple, R. D. Daruwala and M. S. Gofane, "Comparisions of Robert, Prewitt, Sobel operator-based edge detection methods for real time uses on FPGA," 2015 International Conference on Technologies for Sustainable Development (ICTSD), Mumbai, India, 2015, pp. 1-4, doi: 10.1109/ICTSD.2015.7095920.
-
[12] Z. A. Seghir and F. Hachouf, "Image quality assessment scheme based on gradient similarity and color distortion," 2015 12th International Symposium on Programming and Systems (ISPS), Algiers, Algeria, 2015, pp. 1-8, doi: 10.1109/ISPS.2015.7244985.
-
[13] Wang, Y., Xiao, Z., & Cao, G. (2022). A convolutional neural network method based on Adam optimizer with power-exponential learning rate for bearing fault diagnosis. Journal of Vibroengineering, 24(4), 666-678.
-
[14] Y. A. Sari et al., "Indonesian Traditional Food Image Identification using Random Forest Classifier based on Color and Texture Features," 2019 International Conference on Sustainable Information Engineering and Technology (SIET), Lombok, Indonesia, 2019, pp. 206-211, doi: 10.1109/SIET48054.2019.8986058.
-
[15] Sekehravani, E. A., Babulak, E., & Masoodi, M. (2020). Implementing canny edge
detection algorithm for noisy images. Bulletin of Electrical Engineering and Informatics, 9(4), 1404-1410.
-
[16] M. Kalbasi and H. Nikmehr, "Noise-Robust, Reconfigurable Canny Edge Detection and its Hardware Realization," in IEEE Access, vol. 8, pp. 39934-39945, 2020, doi:
10.1109/ACCESS.2020.2976860.
-
[17] Hwa, S. K. T., Bade, A., Hijazi, M. H. A., & Jeffree, M. S. (2020). Tuberculosis detection using deep learning and contrastenhanced canny edge detected X-Ray images. IAES International Journal of Artificial Intelligence, 9(4), 713.
-
[18] Iqbal, B., Iqbal, W., Khan, N., Mahmood, A., & Erradi, A. (2020). Canny edge detection and Hough transform for high resolution video streams using Hadoop and Spark. Cluster Computing, 23(1), 397-408.
-
[19] Gong, L. H., Tian, C., Zou, W. P., & Zhou, N. R. (2021). Robust and imperceptible watermarking scheme based on Canny edge detection and SVD in the contourlet domain. Multimedia tools and applications, 80, 439-461.
-
[20] Chung, Y. L., & Lin, C. K. (2020). Application of a model that combines the YOLOv3 object detection algorithm and canny edge detection algorithm to detect highway accidents. Symmetry, 12(11), 1875.
-
[21] Li, B., He, F., & Zeng, X. (2021). A novel privacy-preserving outsourcing computation
scheme for Canny edge detection. The Visual Computer, 1-19.
-
[22] Malbog, M. A. F., Lacatan, L. L., Dellosa, R. M., Austria, Y. D., & Cunanan, C. F. (2020,
August). Edge detection comparison of hybrid feature extraction for combustible fire segmentation: a Canny vs Sobel performance analysis. In 2020 11th IEEE Control and System Graduate Research Colloquium (ICSGRC) (pp. 318-322). IEEE.
-
[23] Trivedi, J., Devi, M. S., & Dhara, D. (2020). Canny edge detection based real-time intelligent parking management system. Zeszyty Naukowe. Transport/Politechnika Śląska.
-
[24] Utomo, S. B., Irawan, J. F., & Alinra, R. R. (2021). Early warning flood detector adopting camera by Sobel Canny edge detection algorithm method. Indonesian Journal of Electrical Engineering and Computer Science, 22(3), 1796-1802.
-
[25] Jara, J. D. Z., & Bowen, S. (2022). Learning Curve Analysis on Adam, Sgd, and Adagrad Optimizers on a Convolutional Neural Network Model for Cancer Cells Recognition. ADCAIJ: Advances in Distributed Computing and Artificial Intelligence Journal, 11(3), 263-283.
-
[26] He, S., Wu, J., Wang, D., & He, X. (2022). Predictive modeling of groundwater nitrate pollution and evaluating its main impact factors using random forest. Chemosphere, 290, 133388.
-
[27] Speiser, J. L., Miller, M. E., Tooze, J., & Ip, E. (2019). A comparison of random forest variable selection methods for classification prediction modeling. Expert systems with applications, 134, 93-101.
-
[28] Yeşilkanat, C. M. (2020). Spatio-temporal estimation of the daily cases of COVID-19 worldwide using random forest machine learning algorithm. Chaos, Solitons & Fractals, 140, 110210.
-
[29] Kurani, A., Doshi, P., Vakharia, A., & Shah, M. (2023). A comprehensive comparative study of artificial neural network (ANN) and support vector machines (SVM) on stock forecasting. Annals of Data Science, 10(1), 183-208.
-
[30] Gu, J., & Lu, S. (2021). An effective intrusion detection approach using SVM with naïve Bayes feature embedding. Computers & Security, 103, 102158.
-
[31] Prastyo, P. H., Sumi, A. S., Dian, A. W., & Permanasari, A. E. (2020). Tweets responding to the Indonesian Government’s handling of COVID-19: Sentiment analysis using SVM with normalized poly kernel. J. Inf. Syst. Eng. Bus. Intell, 6(2), 112.
-
[32] Reddy, M. R. (2021). Implementation of SVM machine learning Algorithm to predict lung And Breast Cancer. Turkish Journal of Computer and Mathematics Education
(TURCOMAT), 12(12), 3050-3060.
-
[33] Pisner, D. A., & Schnyer, D. M. (2020). Support vector machine. In Machine learning (pp. 101-121). Academic Press.
-
[34] Altan, A., & Karasu, S. (2019). The effect of kernel values in support vector machine to forecasting performance of financial time series. The Journal of Cognitive Systems, 4(1), 17-21.
-
[35] Le, D. N., Parvathy, V. S., Gupta, D., Khanna, A., Rodrigues, J. J., & Shankar, K. (2021). IoT enabled depthwise separable convolution neural network with deep support vector machine for COVID-19 diagnosis and classification. International journal of machine learning and cybernetics, 1-14.
-
[36] Mahdy, L. N., Ezzat, K. A., Elmousalami, H. H., Ella, H. A., & Hassanien, A. E. (2020). Automatic x-ray covid-19 lung image classification system based on multi-level thresholding and support vector machine. MedRxiv, 2020-03.
-
[37] Sharifrazi, D., Alizadehsani, R., Roshanzamir, M., Joloudari, J. H., Shoeibi, A., Jafari, M., ... & Acharya, U. R. (2021). Fusion of convolution neural network, support vector machine and Sobel filter for accurate detection of COVID-19 patients using X-ray images. Biomedical Signal Processing and Control, 68, 102622.
-
[38] Le, D. N., Parvathy, V. S., Gupta, D., Khanna, A., Rodrigues, J. J., & Shankar, K. (2021). IoT enabled depthwise separable convolution neural network with deep support vector
machine for COVID-19 diagnosis and classification. International journal of machine learning and cybernetics, 1-14.
-
[39] Novitasari, D. C. R., Hendradi, R., Caraka, R. E., Rachmawati, Y., Fanani, N. Z., Syarifudin, A., ... & Chen, R. C. (2020). Detection of COVID-19 chest X-ray using support vector machine and convolutional neural network. Commun. Math. Biol. Neurosci., 2020, Article-ID.
-
[40] Özkaya, U., Öztürk, Ş., Budak, S., Melgani, F., & Polat, K. (2020). Classification of COVID-19 in chest CT images using convolutional support vector machines. arXiv preprint arXiv:2011.05746.
-
[41] Singh, M., Bansal, S., Ahuja, S., Dubey, R. K., Panigrahi, B. K., & Dey, N. (2021). Transfer learning–based ensemble support vector machine model for automated COVID-19 detection using lung computerized tomography scan data. Medical & biological engineering & computing, 59, 825-839.
1118
Discussion and feedback