Analisis Sentimen pada Teks Berbahasa Bali Menggunakan Metode Multinomial Naive Bayes dengan TF-IDF dan BoW
on
JNATIA Volume 2, Nomor 1, November 2023
Jurnal Nasional Teknologi Informasi dan Aplikasinya
p-ISSN: 2986-3929
Analisis Sentimen pada Teks Berbahasa Bali Menggunakan Metode Multinomial Naive Bayes dengan TF-IDF dan BoW
Putu Widyantara Artanta Wibawaa1, Cokorda Pramarthaa2
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Udayana, Bali
Jln. Raya Kampus UNUD, Bukit Jimbaran, Kuta Selatan, Badung, 08261, Bali, Indonesia 1putuwaw973@gmail.com 2cokorda@unud.ac.id
Abstract
Currently, digital technology is developing rapidly thus increasing the availability of textual data in the digital form. Many of the digital texts are available in Balinese. From the existing Balinese language texts, an analysis can be carried out to determine the emotional level or sentiment contained in them. Through this analysis, information will be obtained regarding sentiment towards a product or service so that it can be used as information for consideration in making decisions. To determine sentiment in textual data, more specifically unstructured data, several stages are required, one of which is feature extraction such as TF-IDF and BoW. This study will analyze the effect of TF-IDF and BoW feature extraction on the Multinomial Naive Bayes method. The test results show that the TF-IDF feature extraction provides precision, recall, accuracy, and F1-score values respectively 92.3%, 91.13%, 91.5%, and 91.38% higher than with BoW feature extraction.
Keywords: Sentiment Analysis, Balinese Language, Multinomial Naive Bayes, TF-IDF, BoW
Dewasa ini teknologi telah mengalami perkembangan yang sangat pesat. Pesatnya perkembangan teknologi telah menyebabkan pertumbungan yang signifikan terhadap ketersediaan data, salah satunya adalah data tekstual [1]. Dari banyaknya data tekstual yang ada, beberapa diantaranya menggunakan bahasa Bali. Bahasa Bali merupakan bahasa daerah yang masih eksis dituturkan oleh penduduk Bali hingga saat ini [2]. Beberapa inisiasi pelestarian dan pemajuan Bahasa dan Aksara Bali dalam bentuk digital telah dilakukan oleh komunitas dan peneliti. Dari teks berbahasa Bali yang ada dapat dilakukan analisis untuk menentukan tingkat emosional atau sentimen yang terdapat didalamnya.
Banyaknya jumlah teks yang ada menyulitkan proses untuk melakukan analisis atau sentimen dari suatu teks. Terlebih lagi jika analisis tersebut dilakukan secara manual. Oleh karena itu, diperlukan sebuah sebuah sistem yang mampu untuk melakukan analisis sentimen dari suatu teks secara otomatis. Analisis sentimen sendiri adalah proses untuk mendapatkan informasi tentang sentimen baik sentimen positif, negatif, maupun netral dari suatu teks. Analisis sentimen termasuk ke dalam permasalahan klasifikasi, yaitu bagian dari supervised maching learning yang memungkinkan model untuk memberikan prediksi dari masukan baru yang diberikan setelah dilatih dengan menggunakan data berlabel [3].
Saat ini, analisis sentimen merupakan salah satu bidang dalam NLP yang memiliki banyak manfaat di berbagai sektor kehidupan. Pada sektor ekonomi atau bisnis, analisis sentimen dapat digunakan untuk mengukur tingkat kepuasan pengguna terhadap produk atau jasa yang diberikan oleh perusahan. Sentimen analisis juga dapat digunakan pada sektor pendidikan untuk mengetahui tingkat kepuasan siswa terhadap materi pembelajaran yang diberikan. Selain itu,
pada sektor pemerintahan analisis sentimen juga dapat digunakan untuk melihat respon masyarakat terhadap kebijakan yang diberlakukan.
Terdapat cukup banyak penelitian tedahulu yang telah melakukan analisis sentimen. Beberapa diataranya menggunakan metode Mutlinomial Naive Bayes karena metode ini memiliki kecepatan dan akurasi yang tinggi ketika digunakan data yang besar dan beragam [4]. Selain itu, jika dibandingkan dari segi kompleksitas, metode Multinomial Naive Bayes lebih sederhana dibandingkan dengan algoritma lainnya, sehingga akan memiliki waktu komputasi yang lebih singkat untuk melakukan proses klasifikasi [5].
Dalam melakukan analisis sentimen, khususnya dari data tekstual yang tidak terstruktur, diperlukan proses untuk mengekstraksi fitur yang ada dari data tersebut. Setelah ekstraksi fitur akan dilakukan seleksi fitur dan kemudian mengaplikasikan metode untuk melakukan klasifikasi [6]. Terdapat beberapa teknik ekstraksi fitur yang ada, diantaranya seperti TF-IDF, Bag of Words, dan Word Embedding. Penggunaan ekstraksi fitur yang tepat akan mampu untuk meningkatkan performa dari model. Oleh karena itu, pada penelitian ini akan membandingkan pengaruh ekstraksi fitur TF-IDF dengan Bag of Words (BoW) terhadap performa dari metode Multinomial Naive Bayes. Diharapkan dengan dilakukannya penelitian ini dapat membantu dalam melakukan analisis atau klasifikasi terhadap sentimen pada teks berbahasa Bali.
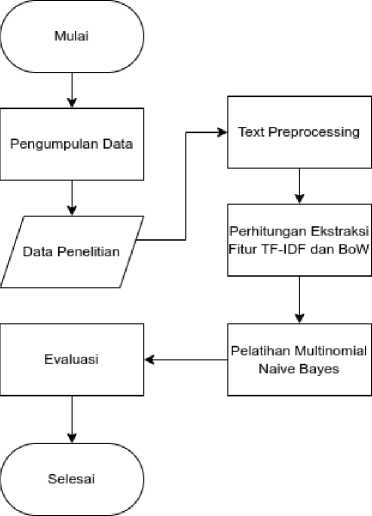
Gambar 1. Bagan Alur Penelitian
Penelitian ini diawali dengan pengumpulan data terhadap teks berbahasa Bali yang nantinya akan dilakukan proses analisis sentimen. Setelah data terkumpul, tahapan selanjutnya adalah melakukan proses text preprocessing. Kemudian, akan dilakukan perhitungan ekstraksi fitur menggunakan Term Frequency-Inverse Document Frequency (TF-IDF) dan Bag of Words (BoW). Setelah ekstraksi fitur, selanjutnya adalah melakukan pelatihan model Multinomial Naive Bayes dengan kedua jenis ekstraksi fitur tersebut. Tahap terakhir adalah melakukan evaluasi terhadap model untuk menentukan model dengan ekstraksi fitur yang menghasilkan performa terbaik.
Data yang digunakan pada penelitian ini adalah data sekunder yang berasal dari NusaX-Senti, yaitu dataset sentimen analisis untuk 10 bahasa daerah di Indonesia [7]. Dataset yang digunakan adalah dataset sentimen bahasa Bali yang terdiri atas 1000 data yang tersebar ke dalam 3 kelas, yaitu sentimen positif sebanyak 378 data, netral sebanyak 239 data, dan sentimen negatif sebanyak 383 data. Pada penelitian ini, hanya akan digunakan dua kelas, yaitu kelas atau label positif dan label negatif. Gambaran data yang akan digunakan pada penelitian ini ditunjukkan pada Tabel 1.
Tabel 1. Gambaran Dataset
|
id |
text |
label |
|
592 Pelayanan bus DAMRI luung pesan. |
positive | |
|
317 |
Dot ngae postingan sane isine mengedukasi customers gojek. |
neutral |
|
352 |
Satusan umah ring medan merendem banjir |
neutral |
Text preprocessing adalah tahap pertama dalam klasifikasi teks yang mengubah data teks asli yang tidak terstruktur menjadi data yang terstruktur sekaligus juga untuk mengidentifikasi fitur dari teks yang paling signifikan untuk membedakan antara kategori teks [8]. Tahap ini akan menghasilkan data teks yang siap digunakan untuk proses selanjutnya. Adapun tahapan dalam text preprocessing ini ditunjukkan pada Gambar 2.
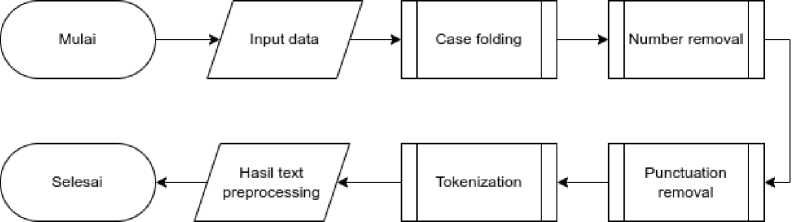
Gambar 2. Tahapan Text Preprocessing
Tahapan pertama dalam text preprocessing adalah melakukan case folding, yaitu mengubah semua huruf menjadi huruf kecil atau lowercase. Setelah dilakukan case folding, tahapan selanjutnya adalah menghilangkan karakter selain alfabet seperti tanda baca dan angka. Kemudian, data teks akan dilakukan proses filtering untuk menghilangkan kata-kata yang bukan berasal dari bahasa Bali. Tahapan terakhir setelah filtering adalah tokenisasi, yaitu memecah data teks menjadi token-token.
Dalam penelitian ini, terdapat dua metode ekstraksi fitur yang akan digunakan yaitu Term Frequency-Invers Document Frequency (TF-IDF) dan Bag of Words (BoW).
TF-IDF adalah algoritma yang dapat digunakan untuk melakukan ekstraksi fitur pada dokumen. Algoritma ini menunjukkan informasi mengenai pentingnya suatu kata pada dokumen. Prinsipnya adalah jika suatu kata atau frasa sering muncul di suatu kelas dokumen namun tidak muncul di kelas dokumen yang lain, maka kata atau frasa tersebut dianggap memiliki pembeda yang baik untuk klasifikasi [9]. Nilai TF-IDF didapatkan dengan menghitung TF (term frequency) yang
dikalikan dengan IDF (invers document frequency). Representasi matematis dari bobot term d dalam dokumen t oleh TF-IDF diberikan dalam Persamaan 1 [10].
Nx
W(d,t)=TF(d,t)× log (—) (1)
Dimana TF(d,t) adalah term frequency atau jumlah kemunculan term d dalam dokumen t, N adalah jumlah dokumen, df(t) adalah jumlah dokumen yang mengantung term t.
Bag of Words (BoW) adalah sebuah teknik ekstraksi fitur untuk merepresentasikan dokumen teks ke dalam bentuk matriks. Teknik ini bekerja dengan cara mempelajari seluruh kosakata dari dokumen, lalu memodelkan tiap dokumen dengan menghitung jumlah kemunculan tiap katanya [11]. Dalam Bag of Words, matriks yang dihasilkan akan tidak akan mampu untuk menangkap baik struktur dari kalimat maupun hubungan semantik yang ada pada kalimat [10].
Multinomial Naive Bayes adalah salah satu bagian dari Naive Bayes yang termasuk ke dalam supervised learning. Algoritma ini bekerja dengan prinsip distribusi multinomial dan dapat diterapkan pada kasus teks dengan mengkonversi ke bentuk nominal yang dapat dihitung dengan nilai bilangan bulat [12]. Algoritma ini akan menghitung probabilitas sebuah dokumen d terhadap kelas C yang ditunjukkan pada Persamaan 2 [13].
Nc
P(C) = ^ (2)
Dimana Nc adalah jumlah kelas C pada seluruh dokumen dan N adalah jumlah seluruh dokumen. Untuk probabilitas dari kata ke-n ditentukan dengan menggunakan persamaan berikut:
Nr + + ot
w) = N≡τV (3)
Dimana Nxn ,c adalah jumlah term Xn yang ditemukan di seluruh data training pada kelas C dan N(C) adalah jumlah term di seluruh data training pada kelas C, dan α adalah parameter laplace smoothing, V adalah jumlah seluruh kata pada data training. Sementara rumus Multinomial yang digunakan dalam pembobotan TF-IDF adalah sebagai berikut:
p'χ ■■■■ ∑t√,,d (C''o (4)
LNdec + v
Dimana ∑ tf(Xn,d ∈ C) adalah jumlah pembobotan kata Xndari seluruh data training pada kelas C dan ∑ Nd∈C adalah jumlah bobot seluruh term pada data training pada kelas C.
Dalam penelitian ini, dataset yang telah melalui text preprocessing akan dibagi menjadi 80% untuk training dan 20% untuk testing. Tahapan ekstraksi fitur akan menggunakan ekstraksi fitur Bag of Words dan TF-IDF. Kedua ekstraksi fitur akan dicoba dengan menggunakan jumlah NGram 1 sampai 2 (unigram dan bigram) dengan jumlah maksimal 4000 fitur. Dari skenario tersebut, akan dicari model Multinomial Naive Bayes dengan ekstraksi fitur yang memiliki performa terbaik. Performa yang ditinjau dalam penelitian ini adalah tingkat accuracy, recall, precision, dan F1-score. Adapun skema dari pelatihan model Multinomial Naive Bayes ditunjukkan oleh Gambar 3.

Gambar 3. Skema Pelatihan Model Multinomial Naive Bayes
Evaluasi akan dilakukan dengan menggunaan data testing yang telah dibagi sebelumnya. Pada tahap evaluasi akan dihitung performa dari tiap model untuk mencari model dengan performa tertinggi yang diukur dari akurasi, presisi, recall, dan F1-score. Perhitungan akurasi didapatkan pada confusion matrix. Confusion matrix sendiri adalah sebuah matriks dua dimensi yang menunjukkan hasil prediksi dari model dan hasil sebenarnya [4]. Untuk menghitung performa dari model melalui akurasi, presisi, recall, dan F1-score dapat digunakan rumus sebagai berikut [4]:
TP
Precision = τp + Fp
Recall =
TP
TP+ FN
TP + TN Accuracy =
TP + TN + FP + FN
F1
— Score = 2 ×
Precision × Recall
Precision + Recall
(5)
(6)
(7)
(8)
Dari data yang berjumlah 383 data dengan label positif dan 378 data dengan label negatif terlebih dahulu dilakukan proses preprocessing untuk keseragaman dan meningkatkan performa dari model. Hasil dari text preprocessing ditampilkan pada Tabel 2.
Tabel 2. Tabel Hasil Text Preprocessing
|
No. Proses |
Hasil |
|
1 Initial Data |
Iraga saling megedegan ajak sane lianan uli 4 warsa sane lintang. |
|
2 Case Folding |
iraga saling megedegan ajak sane lianan uli 4 warsa sane lintang. |
|
3 Number removal |
iraga saling megedegan ajak sane lianan uli warsa sane lintang. |
|
4 |
Punctutation removal |
iraga saling megedegan ajak sane lianan uli warsa sane lintang |
|
5 |
Tokenization |
['iraga', 'saling', 'megedegan', 'ajak', 'sane', 'lianan', 'uli', 'warsa', 'sane', 'lintang'] |
Selain itu, label dari data akan dilakukan proses mapping untuk mengubahnya menjadi data nominal, dimana label negatif akan diubah menjadi -1 dan label positif akan diubah menjadi 1.
Adapun hasil akhir dari text preprocessing dan label mapping ditampilkan pada Tabel 3.
Tabel 3. Tabel Hasil Akhir Text Preprocessing dan Label Mapping
|
text |
label |
|
['jajejaje', 'ne', 'sane', 'kasajiang', 'ngaenang', 'tiang', 'bernostalgia', 'makejang', 'sakadi', 'jaje', 'jaman', 'ipidan', 'uli', 'penampilanne', 'tur', 'rasa', 'ne', 'jajene', 'jaan', 'lan', 'ajine', 'mudah'] |
1 |
|
['paling', 'demen', 'sajan', 'ngajeng', 'siang', 'driki', 'be', 'siap', 'lan', 'sambelne', 'jaen', 'sajan', 'ajine', 'jeg', 'mudah', 'sajan', 'rasan', 'be', 'siap', 'ne', 'ngresep', 'kanti', 'ke', 'tulang', 'ne', 'ngrasa', 'lebih', 'jaen', 'ke', 'waduk'] |
1 |
|
['pelayanan', 'bus', 'damri', 'luung', 'pesan'] |
1 |
|
['barange', 'lumayan', 'nanging', 'sane', 'tiang', 'heran', 'xiaomi', 'redmi', 'note', 'niki', 'tombol', 'onne', 'mula', 'agak', 'usak', 'terus', 'batre', 'mula', 'enggal', 'low', 'bat', 'bos'] |
-1 |
|
['keweh', 'sajan', 'ngugu', 'anak', 'ane', 'suba', 'taen', 'berkhianat'] |
-1 |
Setelah data setelesai melalui tahap preprocessing, kemudian akan dilakukan ekstraksi fitur dengan TF-IDF dan Bag of Words (BoW). Dalam melakukan proses ekstraksi fitur, digunakan bantuan dari modul CountVectorizer dan TfidfVectorizer dari library scikit-learn dengan menggunakan bahasa pemrograman Python. Jumlah maksimal fitur yang digunakan adalah 4000 dan ngram yang digunakan adalah unigram dan bigram.
tfidf = TfidfVectorizer(max_features=4000s ngram_range=( 1, 2))
bow = CountVectorizer(max_features=4ΘΘΘ, ngram range=(l, 2))
X_train_tfidf = tfidf.fit tra∏5form(X_train)
X_test„tfidf = tfidf.transformX test)
X_train_bow = bow.fit-transform(X_train)
X_test_bow ≡ bow.transform(X_test)
Gambar 4. Implementasi Ekstraksi Fitur
Model Multinomial Naive Bayes dibangun dengan menggunakan bantuan library scikit-learn dalam bahasa pemrograman Python. Salah satu hyperparameter yang digunakan adalah alpha atau laplace smoothing sebesar 0,1. Setelah itu model akan dilatih dengan data training yang telah dilakukan ekstraksi fitur TF-IDF dan Bag of Words untuk kemudian dilakukan evaluasi menggunakan data testing.
mnbtfidf = MultinomialNB(alpha=.1)
mnb_tfidf.fit(X_train_tfidf, y_train)
mnb_bow = MultinomialNB(alpha=.1)
m∏b bow.ftt(X_train_bow, ytrain)
Gambar 5. Implementasi Multinomial Naive Bayes
Selanjutnya, setiap model akan diuji menggunakan data testing. Hasil dari pengujian dari model Multinomial Naive Bayes dengan ekstraksi fitur TF-IDF ditunjukkan oleh confusion matrix pada Gambar 6.
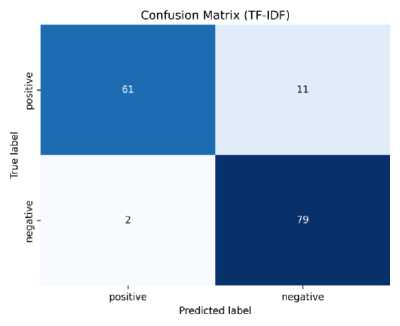
Gambar 6. Confusion Matrix dengan Ekstrasi Fitur TF-IDF
Pada Gambar 6. ditunjukkan bahwa dari model berhasil memprediksi secara benar sebanyak 61 data dengan label positif dan sebanyak 79 data dengan label negatif. Adapun sebanyak 11 data yang seharusnya memiliki label positif diprediksi negatif oleh model dan sebanyak 2 data yang seharusnya memiliki label negatif diprediksi positif oleh model. Sementara hasil dari pengujian model Multinomial Naive Bayes dengan ekstraksi fitur Bag of Words (BoW) ditunjukkan oleh confusion matrix pada Gambar 7.
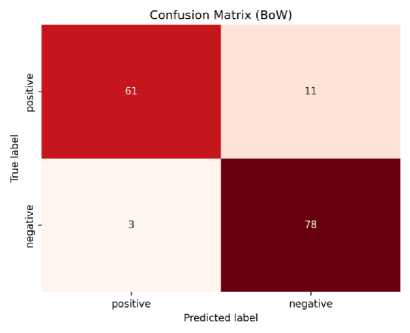
Gambar 7. Confusion Matrix dengan Ekstraksi Fitur BoW
Pada Gambar 7. ditunjukkan bahwa dari model berhasil memprediksi secara benar sebanyak 61 data dengan label positif dan sebanyak 78 data dengan label negatif. Adapun sebanyak 11 data yang seharusnya memiliki label positif diprediksi negatif oleh model dan sebanyak 3 data yang seharusnya memiliki label negatif diprediksi positif oleh model.
Berdasarkan confusion matrix tersebut, didapatkan perbandingan nilai accuracy, precision, recall, dan F1-score dari model Multinomial Naive Bayes dengan menggunakan ekstraksi fitur TF-IDF dan BoW yang ditunjukkan pada Tabel 4.
Tabel 4. Perbandingan Performa Ekstraksi Fitur TF-IDF dan BoW
Precision Recall Accuracy F1-Score
BoW 91,48% 90,51% 90,85% 90,74%
TF-IDF 92,3% 91,13% 91,5% 91,38%
Berdasarkan Tabel 4, nilai dari precision, recall, accuracy, dan F1-score dari TF-IDF secara berturut-turut adalah 92,3%, 91,13%, 91,5%, dan 91,38%. Nilai tersebut lebih tinggi dibandingkan BoW dengan nilai precision, recall, accuracy, dan F1-score secara berturut-turut 91,48%, 90,51%, 90,85%, dan 90,74%. Terlihat bahwa nilai precision, recall, accuracy, dan F1-score dari model Multinomial Naive Bayes dengan ekstraksi fitur TF-IDF lebih tinggi dibandingkan dengan ekstraksi fitur Bag of Words (BoW).
Berdasarkan penelitian yang telah dilakukan, dapat ditarik kesimpulan bahwa dari perbandingan ekstraksi fitur antara TF-IDF dan Bag of Words (BoW) yang memberikan performa lebih baik pada metode Multinomial Naive Bayes adalah TF-IDF. Ekstraksi fitur TF-IDF memberikan nilai precision, recall, accuracy, dan F1-score dari TF-IDF secara berturut-turut adalah 92,3%, 91,13%, 91,5%, dan 91,38%. Sementara ekstraksi fitur BoW memberikan nilai nilai precision, recall, accuracy, dan F1-score secara berturut-turut 91,48%, 90,51%, 90,85%, dan 90,74%. Selain melalui pemilihan ekstrasi fitur, untuk meningkatkan performa dari model juga dapat dilakukan dengan teknik seleksi fitur serta melakukan tuning terhadap hyperparameter pada model yang digunakan.
Daftar Pustaka
-
[1] Saputra A, Firdaus MI, Wahyudi R, Mohdo L, Gunawan ME, Encep M, and Khaira M, “Big Data”, KARIMAH TAUHID, vol. 1, no. 6, pp. 880-889, 2022, doi: 10.30997/karimahtauhid. v1i6.7664
-
[2] Suwija I, “Tingkat-Tingkatan Bicara Bahasa Bali (Dampak Anggah-Ungguh Kruna)”, Sosiohumaniora, vol. 21, no. 1, pp. 90-97, 2019, doi: 10.24198/sosiohumaniora.
v21i1.19507
-
[3] P. C. Sen, M. Hajra, and M. Ghosh, “Supervised Classification Algorithms in Machine
Learning: A Survey and Review,” Advances in Intelligent Systems and Computing, pp. 99– 111, Jul. 2019, doi: 10.1007/978-981-13-7403-6_11.
-
[4] Mas'udah E, Wahyuni ED, and Anjani A, “Analisis sentimen: Pemindahan ibu kota
Indonesia pada twitter”, Jurnal Informatika dan Sistem Informasi, vol. 1, no. 2, pp. 397401, 2020.
-
[5] Naf'an MZ, Bimantara AA, Larasati A, Risondang EM, and Nugraha NA, “Sentiment
Analysis of Cyberbullying on Instagram User Comments”. Journal of Data Science and Its Applications, vol. 2, no. 1, pp. 38-48, 2019, doi: 10.21108/jdsa.2019.2.20
-
[6] R. Ahuja, A. Chug, S. Kohli, S. Gupta, and P. Ahuja, “The Impact of Features Extraction
on the Sentiment Analysis,” Procedia Computer Science, vol. 152, pp. 341–348, 2019, doi: 10.1016/j.procs.2019.05.008.
-
[7] Genta Indra Winata et al., “NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages,” May 2022, doi: 10.48550/arxiv.2205.15960.
-
[8] Kadhim AI, “An evaluation of preprocessing techniques for text classification”, International
Journal of Computer Science and Information Security (IJCSIS), vol. 16, no. 6, pp. 22-32, 2018
-
[9] C. Liu, Y. Sheng, Z. Wei, and Y. Yang, “Research of Text Classification Based on Improved TF-IDF Algorithm,” IEEE Xplore, Aug. 01, 2018.
https://ieeexplore.ieee.org/abstract/document/8492945
-
[10] K. Kowsari, K. Jafari Meimandi, M. Heidarysafa, S. Mendu, L. Barnes, and D. Brown, “Text Classification Algorithms: A Survey,” Information, vol. 10, no. 4, p. 150, Apr. 2019, doi: 10.3390/info10040150.
-
[11] Wahyuningdiah Trisari Harsanti Putri and Retno Hendrowati, “PENGGALIAN TEKS DENGAN MODEL BAG OF WORDS TERHADAP DATA TWITTER,” vol. 2, no. 1, pp. 129– 138, Sep. 2018, doi: 10.24912/jmstkik. v2i1.1560.
-
[12] A. A. Farisi, Y. Sibaroni, and S. A. Faraby, “Sentiment analysis on hotel reviews using Multinomial Naïve Bayes classifier,” Journal of Physics: Conference Series, vol. 1192, p. 012024, Mar. 2019, doi: 10.1088/1742-6596/1192/1/012024.
-
[13] Harjito, B., Aini, K.N. and Murtiyasa, B., “Klasifikasi Dokumen berkonten Serangan jaringan menggunakan Multinomial Naive Bayes”, In Seminar Nasional Teknologi Informasi dan Komunikasi (SEMNASTIK), vol. 1, no. 1, pp. 112-118, 2018
-
[14] M. Grandini, Enrico Bagli, and Giorgio Visani, “Metrics for Multi-Class Classification: An Overview,” arXiv (Cornell University), Aug. 2020, doi: 10.48550/arxiv.2008.05756.
Halaman ini sengaja dibiarkan kosong
46
Discussion and feedback