Sentiment Analysis of Domestic Violence Issues on Twitter Using Multinomial Naïve Bayes and Support Vector Machine
on
JITTER- Jurnal Ilmiah Teknologi dan Komputer Vol. 4, No. 3 December 2023
Sentiment Analysis of Domestic Violence Issues on Twitter Using Multinomial Naïve Bayes and Support Vector Machine
Uli Rindu Deboraa1, I Putu Agus Eka Pratamaa2, Gusti Made Arya Sasmitab3 aDepartment of Information Technology, Faculty of Engineering, Udayana University Bukit Jimbaran, Bali, Indonesia
e-mail: 1rindudebora@student.unud.ac.id, 2eka.pratama@unud.ac.id, 3aryasasmita@it.unud.ac.id
Abstrak
Kasus kekerasan dalam rumah tangga (KDRT) selalu mengundang banyak komentar publik di media sosial Twitter. Penelitian ini bertujuan untuk melakukan analisis klasifikasi sentimen opini masyarakat terkait kasus KDRT yang terus berlangsung di Twitter. Penelitian ini menggunakan algoritma Multinomial Naive Bayes dan SVM untuk menguji akurasi dalam melakukan klasifikasi tweet. Metode penelitian ini mencakup langkah-langkah sebagai berikut: pengumpulan data dari Twitter, pra-pemrosesan data, analisis sentimen, klasifikasi sentimen dengan menggunakan algoritma SVM dan Multinomial Naïve Bayes, serta analisis hasil dari kedua algoritma tersebut. Hasil penelitian menunjukkan bahwa tingkat akurasi tertinggi yang didapatkan algoritma SVM mencapai 73% pada rasio 80:20, sementara algoritma Multinomial Naïve Bayes mendapatkan tingkat akurasi sebesar 70% pada rasio yang sama yaitu 80:20. Dapat disimpulkan bahwa algoritma SVM memiliki tingkat akurasi yang lebih baik daripada algoritma Multinomial Naïve Bayes.
Kata kunci: Analisis Sentimen, Isu KDRT, Multinomial Naïve Bayes, Support Vector Machine, Twitter
Abstract
Cases of domestic violence (KDRT) always attract numerous public comments on Twitter's social media platform. This research aims to conduct a sentiment analysis classification regarding ongoing cases of KDRT on Twitter. The study employs the Multinomial Naive Bayes and SVM algorithms to test accuracy in classifying tweets. The research methodology includes the following steps: data collection from Twitter, data preprocessing, sentiment analysis, sentiment classification using SVM and Multinomial Naïve Bayes algorithms, and analysis of results from both algorithms. The research findings indicate that the SVM algorithm achieves the highest accuracy rate, reaching 73% at an 80:20 ratio. In comparison, the Multinomial Naïve Bayes algorithm attains an accuracy rate of 70% at the same ratio. Therefore, it can be concluded that the SVM algorithm exhibits better accuracy compared to the Multinomial Naïve Bayes algorithm.
Keywords : Sentiment Analysis, Domestic Violence Issues, Multinomial Naïve Bayes (MNB), Support Vector Machine (SVM), Twitter
-
1. Introduction
Domestic violence in Indonesia is a more complex problem than is publicly apparent. Published data and figures reflect only a fraction of the cases that occur. Many cases of domestic violence go unreported or hidden from the public, so we have only a fraction of the real problem in today's picture. It is essential to understand that domestic violence is a deep and complex issue, and further efforts are needed to reveal and address all cases.
The National Commission on Violence Against Women (Komnas Perempuan), in its latest annual report, stated that domestic violence cases occupy the highest position as cases of violence against women. Domestic violence cases contributed 79% or 6,480 cases out of a
total of 8,234 data on cases of violence against women throughout 2020 obtained by Komnas Perempuan. Cases of violence against women ranked first, with 3,221 cases out of the total domestic violence cases [1]. Considering the statement from the National Commission on Violence Against Women, many victims of domestic violence (KDRT) often include women and children. Males frequently perpetrate this violence, and if it occurs too frequently, it can lead to issues in the development of children, affecting both their physical and mental well-being in the future.
Twitter is often used to express feelings about something. It can be both praise and criticism from an emotional point of view. Users write messages about various things, share information, inspire, discuss specific topics, and express happiness and other emotional expressions through status writing and tweets. The author sees millions of information and messages every day through the activities of Twitter social media users. Hence, this final project will analyze research on Sentiment Analysis of Domestic Violence Issues on Twitter social media in Indonesia, using the Naïve Bayes Classifier Algorithm to examine public opinion expressed through tweets.
This study implemented two algorithms: Multinomial Naive Bayes and Support Vector Machine (SVM). Multinomial Naive Bayes is one of the algorithms used in text mining. The Naive Bayes algorithm, known as the Bayes' Theorem, involves statistical calculations to predict future probabilities based on past experiences or encountered issues. SVM excels in its ability to handle both linear and non-linear classification problems. In sentiment analysis, where the relationship between features such as words or phrases and sentiment can be highly complex SVM leverages kernel techniques to handle non-linear data.
-
2. Research Method / Proposed Method
Research Methods contains a discussion of the research methodology, which contains the stages or description of the research conducted. The research method is helpful to facilitate the research process.
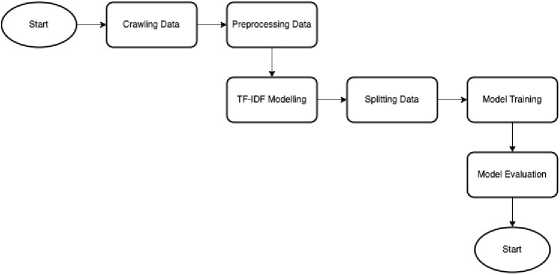
Figure 1. System Process Flow
Figure 1 represents the system’s process flow. In this study, the system process flow begins with the data crawling or data collection process and proceeds to the preprocessing stage involving several processes. Following this, the TF-IDF modeling process takes place and subsequently, the division of data into two parts—training data and test data—can be adjusted according to research needs. Subsequently, the study employs two algorithms Multinomial Naïve Bayes and Support Vector Machine, to perform the classification. Finally, the study compares the results of the two models to identify the best-performing model.
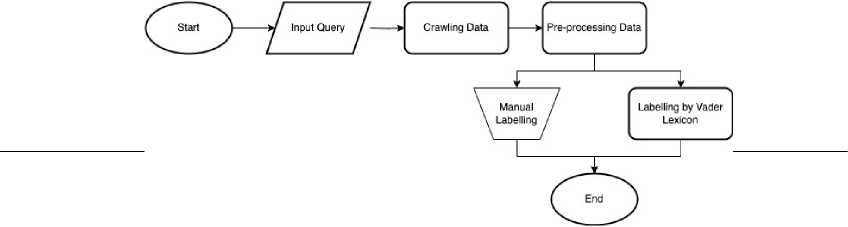
Figure 2. The Data Processing Flow
Figure 2 depicts the data processing flow. Data processing begins with collecting data about the case study taken, namely the issue of domestic violence. After that, it continued with preprocessing stages such as removing usernames, cleaning, case folding, tokenization stopwords, normalization, stemming, and un-tokenization. Subsequently, two methods of labeling data are manual labeling and automatic labeling using the Vader Lexicon.
-
3. Literature Study
The literature review discusses theories related to writing research reports.
Sentiment Analysis (SA) involves automatically understanding and processing textual data to extract sentiment information from a sentence or text, portraying it as an opinion. The purpose of sentiment analysis is to see the view or opinion of the text related to a problem or object, whether it tends to have a positive or negative view. Sentiment analysis consists of natural language processing, text analysis, and linguistic computing to identify the sentiment of a document [2].
The Naïve Bayes method is a classification technique used in data analysis and machine learning. This method employs simple probabilities based on Bayes' Theorem allowing us to classify data into different categories. The Naïve Bayes method calculates the probability of each feature or attribute present in the data to determine the likelihood of a specific event or condition occurring [3].
Support Vector Machine (SVM) is one of the classification methods included in supervised learning and is part of machine learning that follows the principle of Structural Risk Minimization (SRM). SVM aims to achieve the most optimal hyperplane with the optimum margin in the input space to separate each class effectively [4]. SVMs exhibit lower sensitivity to overfitting than other methods, and they can be utilized for prediction and classification, offering an additional advantage [5].
VADER (Valence Aware Dictionary and Sentiment Reasoner) is a model responsive to negative and positive polarity and emotional intensity used for sentiment analysis. The NLTK toolkit includes the VADER model, which can directly applied to unlabeled text data. Sentiment analysis performed by VADER relies on a dictionary mapping lexical features to sentiment scores. The sentiment score of a text can only be obtained by summing the weights of each word present in the text [6]. For example, if the text contains words like 'like,' 'peaceful,' and 'love,' it will yield a positive sentiment result.
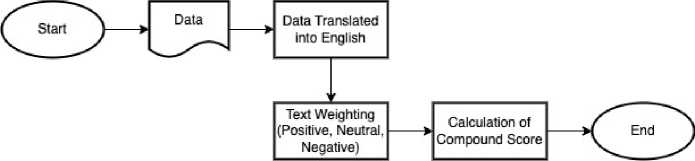
Figure 3. VADER Lexicon Labeling Flow
Figure 3 provides a detailed overview of the labeling process using the VADER lexicon system. The data will be translated into English as the VADER Lexicon only supports English texts. The text undergoes a weighting process based on each word present, assessing three weights: negative, neutral, and positive. Additionally, a compound score is calculated by summing the weights of each word in the text and dividing it by the total number of words.
-
4. Result and Discussion
This section contains a discussion about the comparison of the obtained results. The topics covered in this chapter are related to the comparison between manually labeled results and labeling using the Vader lexicon, as well as the comparison of the evaluation results of the MNB and SVM models.
Data preprocessing constitutes a crucial step in the data mining process. It involves cleaning, transforming, and integrating data to prepare it for analysis. The goal of data preprocessing is to enhance data quality and make it more suitable for specific data mining tasks.
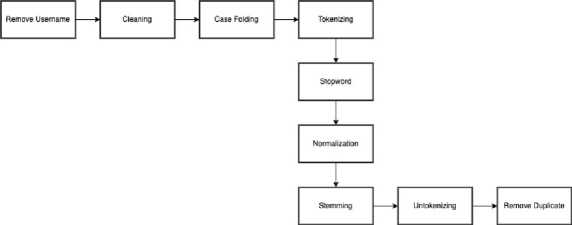
Figure 4. Preprocessing Stages
Figure 4 represents the preprocessing stages of the data conducted in this research The resulting forms at each process will be explained in table 1.
Table 1. Data Preprocessing
|
Preprocessing Stages |
After |
|
Raw Data |
@cintanyaV @tanyarlfes Pisah dong ~ sudah lah g pernah ngasih uang bulanan, kdrt (fisik verbal mental) ,kelakuannya kaya gt pula |
|
Remove Username |
Pisah dong ~ sudah lah g pernah ngasih uang bulanan, kdrt (fisik verbal mental) ,kelakuannya kaya gt pula “ https://t.co/8Z03l2AewM |
|
Cleaning |
Pisah dong sudah lah pernah ngasih uang bulanan kdrt fisik verbal mental kelakuannya kaya gt pula |
|
Case Folding |
pisah dong sudah lah pernah ngasih uang bulanan kdrt fisik verbal mental kelakuannya kaya gt pula |
|
Tokenisasi |
['pisah', 'dong', 'sudah', 'lah', 'pernah', 'ngasih', 'uang', 'bulanan', 'kdrt', 'fisik', 'verbal', 'mental', 'kelakuannya', 'kaya', 'gt', 'pula'] |
|
Stopword |
['pisah', 'ngasih', 'uang', 'bulanan', 'kdrt', 'fisik', 'verbal', 'mental', 'kelakuannya', 'kaya'] |
|
Normalisation |
['pisah', 'mengasih', 'uang', 'bulanan', 'kdrt', 'fisik', 'verbal', 'mental', 'kelakuannya', 'kayak'] |
|
Stemming |
['pisah', 'asih', 'uang', 'bulan', 'kdrt', 'fisik', 'verbal', 'mental', 'laku', 'kayak'] |
|
Untokenizing |
pisah asih uang bulan kdrt fisik verbal mental laku kayak |
Table 1 illustrates each stage of preprocessing conducted in this research. It begins with raw data and progresses through the removal of usernames, followed by a cleaning process to eliminate emojis and unnecessary symbols. Subsequently, the data undergoes case folding to convert the text into lowercase. The next step involves tokenization, breaking sentences into tokens. Following that is the Stopword stage, which eliminates common words that typically do not provide significant information in text analysis.
According to the colloquial-Indonesian-lexicon dictionary, the process then changes to normalization, transforming all slang or non-formal words into formal ones. Next, the data undergoes stemming, a process that removes prefixes and suffixes to obtain the base form of words. After completing all these processes, the data is untokenized, reverting the tokenized form into complete sentences. The final step involves removing duplicate data identified after the preprocessing phase.
Wordcloud is a visualization of a collection of words within a text, where the size of the words reflects how frequently they appear. In a word cloud, words that appear more frequently will be displayed with a larger size, while words that appear less often will be shown with a smaller size or may not be displayed at all.
Wordcloud Data

Figure 5. Data Visualization
Figure 5 represents the most frequently occurring words in the data. As observed, the word "KDRT" has the most significant size among other words, indicating its highest frequency in the data. Additionally, words such as "anak" (child) and "suami" (husband) also have substantial sizes, suggesting that in the context of domestic violence (KDRT), discussions often involve topics related to children and husbands.
Two individuals performed manual labeling after the data underwent preprocessing stages to mitigate subjectivity. They categorized the labeling into two classes: positive labels and negative labels. The following example illustrates data that received manual labeling.
Table 2. Manual Labeled Data
|
No |
Tweet |
Label |
|
1. |
baru kejadian semalam. Temen kakak gue abis kena kdrt sama suaminya sampe babak belur. Sama kakak gue dibawa ke rumah sakit. |
Negative |
|
2. |
stop kdrt, mari kira budayakan hidup sehat secara jasmani dan rohani |
Positive |
|
3. |
anehhhh, harus banget pdhl bilar dipenjarain, kenapaaa si lestiii..bilar |
Negative |
tuh udh kdrt in kamuuuu kenapaaa dicabut laporannya
-
4. kawal kasus kdrt di bogor rpa perindo apresiasi kinerja polisi Positive
Table 2 illustrates an example of text that two individuals manually labeled. Text receives a positive label if it contains many words with positive meanings, as seen in entries 2 and 4 in the table above. Both texts receive a positive label because the words "sehat" (healthy) and "apresiasi" (appreciation) carry high positive weights. Conversely, texts 1 and 3 receive negative labels due to the presence of words like "babak belur" (beaten badly) and "dipenjarain" (imprisoned), which have high negative weights. "As a result, both texts received an unfavorable label.
The labeling process utilizes the Vader Lexicon algorithm, a model designed for sentiment analysis of text sensitive to polarity (negative/positive). The advantage of using VADER in sentiment analysis lies in its ability to expedite the labeling process, which can be time-consuming when done manually. However, the use of VADER also comes with limitations. The lexicon does not encompass slang or colloquial language commonly used in social media. If the Vader Lexicon does not recognize a word in the text, it may lead to a lack of
understanding of the overall context, resulting in labeling errors. Additionally, applying the VADER Lexicon is limited to English-language texts, requiring data translation into English before analysis. Language differences can introduce errors, potentially causing misunderstandings of context.
Table 3. Data with Vader Lexicon Labels
|
No. |
Tweet |
Scores |
Compound |
Sentiment |
|
1. |
syukuri nder rezeki langgeng tidak selalu hahahihi selama tidak pisah tidak selingkuh tidak kdrt sampai maut memisahkan keluargamu bumbunya lumayan pedas selama tidak mules nikmati aja |
{'neg': 0.233, 'neu': 0.652, 'pos': 0.115} |
-0,5859 |
Negative |
|
2. |
tukang selingkuh kalo gak kdrt meriang kali ya |
{'neg': 0.315, 'neu': 0.326, 'pos': 0.359} |
0,1027 |
Positive |
|
3. |
sharing is caring namun aku berdoa semoga tidak ada lagi yang menjadi korban kdrt |
{'neg': 0.39, 'neu': 0.244, 'pos': 0.366} |
-0,1027 |
Negative |
|
4. |
temenku nikah sama orang sholih eh taunya kdrt |
{'neg': 0.0, 'neu': 0.714, 'pos': 0.286} |
0,4939 |
Positive |
Table 3 illustrates an example of text labeled using the VADER Lexicon. Data labeled with VADER results in two types of assessments: scores and compound. There are three types of sentiments—negative, neutral, and positive. Meanwhile, the compound represents the overall sentiment value of the analyzed text. This compound score encompasses all aspects of sentiment (negative, neutral, and positive) and provides an overall overview of the sentiment expressed in the entire text.
The manual labeling process, relying on human judgment, differs from labeling using the VADER Lexicon algorithm. Differences in sentiment assessment in text can arise due to the subjective approach in manual labeling, whereas VADER Lexicon provides an automatic approach. Thus, these different labeling methods can result in variations in the sentiment assessment of a text.
Table 4. Comparison of Label Results
|
No. |
Tweet |
Label Manual |
Vader Lexicon |
|
1. |
jangan percaya sama orang yang suka kdrt tiba bersujud gini bokap juga dulu gini tapi tetep aja ngulang lagi apalagi nangis sambil divideoin |
Negative |
Positive |
|
2. |
ada lo cewek yang dijodohin ortu trus sampe kejadian kdrt bubar terus mau nikah lagi tetep dijodohin gak boleh sama yang disukai cuma gara alisnya si cowok gak disukain ibunya |
Negative |
Positive |
|
3. |
salah satu cita cita ku adlh punya rumah perlindungan buat para korban |
Positive |
Negative |
KDRT yg kabur dr rumah biar mereka gak homeless buat para korban, semangat ya
-
4. Nih ya soal isu KDRT, dukungan dari Positive Negative
komunitas dan LSM itu banget penting.
Mereka biasanya kasih support buat
korban KDRT.
Table 4 illustrates texts that obtained different labels through two applied labeling methods. In addition to differences in assessment approaches, another factor contributing to variations in labeling results is that VADER Lexicon labels text in English. This condition introduces the potential for differences in text interpretation due to language disparities and nuances that may influence the final labeling outcome.
Applying manually labeled data generated from the preprocessing stage involves the process; the model testing phase involves applying Naive Bayes and Support Vector Machine (SVM) algorithms to determine the best model. The evaluation considers the best model with the highest accuracy, and the testing process commences by splitting the data into training and test sets.
This study divided the data into three different schemes, specifically with ratios of 80:20 70:30, and 60:40. Subsequently, the data splitting process was applied to the Multinomial Naïve Bayes and Support Vector Machine. Through implementing various data splits and using two different algorithms, the goal is to evaluate the performance and responsiveness of the algorithms to the variation in data splitting ratios.
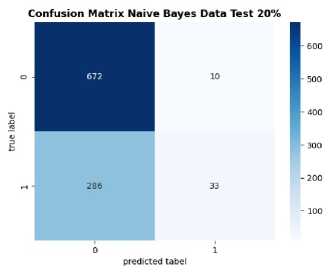
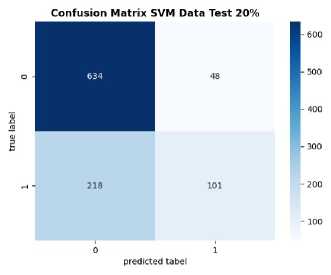
Figure 6. Confusion Matrix of Manual Data
Figure 6 illustrates a visualization of the confusion matrix for both models used. The algorithms attained the highest accuracy at the same data ratio of 80:20, signifying their utilization of only 20% of the total data for testing. For the Multinomial Naïve Bayes algorithm there were 672 True Negatives (TN), 33 True Positives (TP), 10 False Positives (FP), and 286 False Negatives (FN). Meanwhile, for the Support Vector Machine algorithm, there were 634 True Negatives (TN), 101 True Positives (TP), 48 False Positives (FP), and 218 False Negatives (FN).
|
Table 5. Manual Label Data Evaluation Results | |||||||
|
Train:Test |
Multinomial Naïve Bayes |
Support Vector Machine | |||||
|
Accuracy Precision |
Recall |
F1-Score |
Accuracy |
Precision |
Recall |
F1-Score | |
|
80:20 |
70% 73% |
54% |
50% |
73% |
71% |
62% |
63% |
|
70:30 |
69% 67% |
52% |
46% |
72% |
69% |
59% |
58% |
|
60:40 |
69% 72% |
53% |
47% |
72% |
71% |
60% |
59% |
Table 5 presents the results from the two algorithms employed in this study. The Multinomial Naïve Bayes algorithm exhibited its best performance at a data ratio of 80:20 utilizing 80% of the data for training and 20% for testing. Similarly, the Support Vector Machine algorithm showed optimal performance at a data ratio 80:20.
During the model testing phase, the VADER Lexicon labels the data. Following this, the Multinomial Naive Bayes and Support Vector Machine (SVM) algorithms perform classification to identify the best model. The model with the highest accuracy is deemed the best during this phase, and the testing process starts by splitting the data into training and test sets.
This segment employs a comparable data division, reflecting the manual data ratios of 80:20, 70:30, and 60:40. Following that, the two algorithms, Multinomial Naïve Bayes and Support Vector Machine, undergo the data splitting process.
Table 6. Vader Lexicon Data Evaluation Results
|
Train:Test |
Multinomial Naïve Bayes |
Support Vector Machine | ||||||
|
Accuracy |
Precision |
Recall |
F1-Score |
Accuracy |
Precision |
Recall |
F1-Scor e | |
|
80:20 |
66% |
71% |
61% |
58% |
74% |
74% |
72% |
73% |
|
70:30 |
67% |
73% |
61% |
59% |
74% |
74% |
72% |
73% |
|
60:40 |
68% |
74% |
63% |
61% |
76% |
75% |
74% |
74% |
Table 6 shows the results of both algorithms using data labeled with the Vader Lexicon employed in this study. The Multinomial Naïve Bayes algorithm exhibited its best performance at the 60:40 data ratio, utilizing 60% of the data for training and 40% for testing, resulting in the highest accuracy of 68%. Similarly, the Support Vector Machine algorithm achieved its best performance at the 60:40 data ratio, yielding the highest accuracy of 76%.
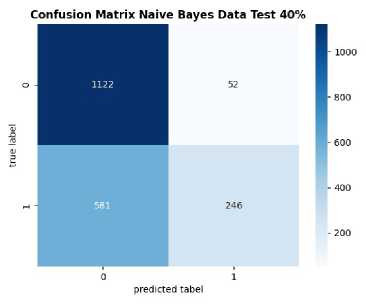
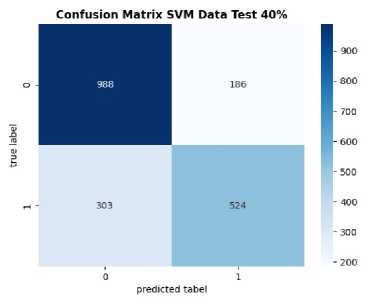
Figure 7. Confusion Matrix of Vader Lexicon Data
Figure 7 presents a visualization of the confusion matrix for both utilized models. The algorithms attained their highest accuracy at the same data ratio of 60:40, signifying the utilization of only 40% of the data for testing. For the Multinomial Naïve Bayes algorithm, there were 1122 True Negatives (TN), 246 True Positives (TP), 52 False Positives (FP), and 581 False Negatives (FN). Meanwhile, for the Support Vector Machine algorithm, there were 988 True Negatives (TN), 524 True Positives (TP), 186 False Positives (FP), and 303 False Negatives (FN).
-
5. Conclusion
Several conclusions can be drawn from the research results regarding Sentiment Analysis on the issue of Domestic Violence on Twitter using the Naïve Bayes Classifier Algorithm. Firstly, observing and analyzing Twitter users' opinions on the issue of Domestic Violence in Indonesia, and the classification of sentiment in tweet data, can be carried out through several steps, including data collection, preprocessing, sentiment classification, and result analysis.
Furthermore, utilizing two labeling methods and two algorithms (SVM and Multinomial Naïve Bayes) yielded the following results. For both algorithms tested with manually labeled data, the highest accuracy was achieved at a ratio of 80:20. In the Multinomial Naïve Bayes algorithm with manual labels, the highest accuracy reached 70%. In contrast, in the Support Vector Machine (SVM) algorithm with manual labels, the highest accuracy reached 73%.
Meanwhile, for both algorithms tested using data labeled with Vader Lexicon, the highest accuracy was found at a ratio of 60:40. The highest accuracy for the Multinomial Naïve Bayes algorithm with Vader Lexicon labels reached 68%. For the SVM algorithm with Vader Lexicon labels, it reached 76%.
References
-
[1] K. Perempuan, "CATATAN KEKERASAN TERHADAP PEREMPUAN TAHUN 2020," Komnas Perempuan, 2021.
-
[2] G. Vinodhini and R. Chandrasekaran, "Sentiment Analysis and Opinion Mining: A Survey," International Journal of Advanced Research in Computer Science and Software Engineering, 2012.
-
[3] F. V. Sari and A. Wibowo, "Analisis Sentimen Pelanggan Toko Online JD.ID Menggunakan Metode Naive Bayes Classifier Berbasis Konversi Ikon Emoji," Jurnal Simetris, 2019.
-
[4] F. Maylani, Sriyanto and Nosiel, "Implementasi Metode Data Mining untuk Memprediksi Warna Anak Kucing Pada Proses Pengembangbiakan Kucing Ras Menggunakan Algoritma SVM.," Seminar Nasional Hasil Penelitian dan Pengabdian Masyarakat, 2021.
-
[5] A. Beri, "Analisis Sentimental Menggunakan Vader," Medium, 28 May 2020. [Online]. Available: https://towardsdatascience.com/sentimental-analysis-using-vader-a3415fef7664. [Accessed 2023].
-
[6] N. Wardhani, Rezkiani and dkk, "Sentiment Analysis Article News Coordinator Minister of Maritime Affairs Using Algorithm Naive Bayes and Support Vector Machine with Particle Swarm Optimization," Journal of Theoretical and Applied Information Technology, 2018.
Discussion and feedback