SENTIMENT ANALISIS ANTUSIAS MASYARAKAT TERHADAP SAMPAH PLASTIK DENGAN MENGGUNAKAN METODE SUPPORT VECTOR MACHINE (SVM)
on
JITTER- Jurnal Ilmiah Teknologi dan Komputer Vol. 3, No. 1 April 2022
Sentiment Analisi Antusias Masyarakat Terhadap Sampah Plastik Dengan Menggunakan Metode Support Vector Machine (SVM)
Rizki Dwi Satriaa1, I Made Agus Dwi Suarjayaa2, I Putu Agus Eka Pratamaa3 Information Technology Study Program, Faculty of Engineering, Udayana University, Bukit Jimbaran, Bali, Indonesia
e-mail: riskydwisatria@unud.ac.id , agussuarjaya@it.unud.ac.id, Eka.pratama@unud.ac.id
Abstrak
Perkembangan internet di negara Indonesia cukup pesat, hal ini dibuktikan dengan semakin mudahnya akses internet yang semakin banyaknya akses wireless yang ada dan tersebar, perkembangan teknologi smartphone, dan teknologi jaringan yang saat ini hampir menuju 5G membuat masyarakat lebih mudah dan lebih cepat mengakses informasi memlalui internet. Permasalahan sampah di Indonesia merupakan masalah yang belum terselesaikan hingga saat ini, Sementara itu dengan bertambahnya jumlah penduduk maka akan mengikuti pula bertambahnya volume timbulan sampah yang dihasilkan dari aktivitas manusia. Penelitian ini bertujuan untuk mengetahui sentimen antusias atau pendapat masyarakat terhadap sampah plastik. Metode yang digunakan dalam penelitian ini support vector machine (SVM). Adapun metode support vector machine memiliki pengaruh yang cukup signifikan terhadap nilai akurasi klasifikasi. nilai akurasi yang didapatkan sebesar 82,27% sebagai nilai yang paling optimal. Tingkat akurasi tersebut didapatkan dengan jumlah data latih 1.500 kalimat dan 4 kali uji coba.
Kata Kunci: sampah plastik, sentiment analisis, support vector machine
Abstract
The development of the internet in Indonesia is quite fast and rapid, this is evidenced by the easier internet access, the increasing number of existing and spread wireless access, the development of smart phone technology, and network technology which is currently almost towards 5G, making it easier and faster for people to access information. through the internet. The problem of waste in Indonesia is a problem that has not been resolved until now. Meanwhile, with the increase in population, it will also follow the increase in the volume of waste generated from human activities. This study aims to determine the enthusiastic sentiment or public opinion on plastic waste. The method used in this research is support vector machine (SVM). The support vector machine method has a significant influence on the classification accuracy value. the accuracy value obtained is 82.27% as the most optimal value. This level of accuracy was obtained with the amount of training data 1,500 sentences and 4 trials.
Keyword: plastic waste, sentiment analysis, support vector machine
-
[1] Introduction
Perkembangan internet di Indonesia cukup pesat, hal ini dibuktikan dengan semakin mudahnya akses internet, semakin banyaknya akses nirkabel yang ada dan tersebar, perkembangan teknologi smartphone, dan teknologi jaringan yang saat ini sudah hampir menuju 5G, sehingga memudahkan untuk
masyarakat dan lebih cepat dalam mengakses informasi melalui internet Kemudahan akses internet ini telah mengubah kebiasaan masyarakat, yang umumnya mengakses informasi melalui media cetak seperti koran dan majalah atau lainnya, yang kini lebih instan dan praktis dengan menggunakan internet.
Seiring dengan perkembangan pengguna internet, media sosial juga semakin berkembang. Media sosial adalah sebuah platform media yang berfokus pada keberadaan pengguna yang memfasilitasi mereka dalam aktivitas dan kolaborasi mereka. Oleh karena itu, media sosial dapat dilihat sebagai media online (fasilitator) yang mempererat hubungan antar pengguna sekaligus sebagai ikatan sosial. [1] Indonesia merupakan negara yang masuk dalam 10 besar penyumbang sampah plastik. Indonesia termasuk dalam jajaran negara penyumbang sampah terbesar di Indonesia. Tercatat, masyarakat Indonesia mampu memproduksi 175.000 ton per hari. Sehingga lingkungan tercemar oleh sampah plastik, plastik rumah tangga hingga plastik di pabrik lain. Teknologi informasi di era saat ini berkembang sangat pesat, khususnya di bidang media sosial, yang telah mengubah cara manusia berkomunikasi antar manusia. Kebanyakan orang pada umumnya menggunakan media sosial untuk mengungkapkan pendapat, pengalaman, dan hal-hal yang bersifat pribadi atau publik yang menjadi perhatian pengguna media sosial, [2] hal seperti ini sering disebut sentimen, dimana sentimen dinilai dari komentar publik terhadap postingan dari pengguna di media sosial.
Masalah sampah di Indonesia merupakan masalah yang belum terselesaikan hingga saat ini. Sementara itu, dengan bertambahnya jumlah penduduk maka akan diikuti pula dengan peningkatan volume sampah yang dihasilkan dari aktivitas manusia. Permasalahan sampah plastik adalah jika semakin banyak di lingkungan akan berpotensi mencemari lingkungan Mengingat sifat plastik akan terurai di dalam tanah dalam waktu lebih dari 20 tahun, bahkan bisa mencapai 100 tahun sehingga dapat menurunkan kesuburan yang ada pada tanah dan di perairan, plastik akan sulit terurai.
Ada beberapa penelitian sebelumnya yang menjadi pedoman dalam penelitian ini, diambil dari Jurnal Ilmiah Informatika dan Komputer [3] yang menjelaskan tentang pengembangan model popularitas di media sosial video
YouTube dengan formula saluran populer dan video populer, kemudian juga dampak positif atau negatifnya. model video dengan formula video positif dan negatif. Dengan menggunakan model kepopuleran dan dampak video ini diterapkan pada objek bidang politik, hasil yang didapat dari model kepopuleran dan dampak video ini memiliki trend yang sama dengan metode survei dan Google Trends. Kemudian pada tahun 2017 dilakukan [4] dalam penelitiannya menjelaskan tentang menganalisis sentimen opini publik pada acara televisi Dengan menggunakan metode KNN, metode KNN dan pembobotan jumlah retweet dapat diterapkan pada analisis sentimen pada tayangan televisi berdasarkan opini publik di media sosial Twitter. Tahapan proses yang dilakukan adalah pembobotan tekstual, pembobotan jumlah retweet (non-tekstual) yang dinormalisasi ke Min-max, kemudian penggabungan antara keduanya sehingga dapat diketahui bahwa dokumen yang telah diklasifikasikan memiliki positif atau negative. Sebelumnya [5] menjelaskan tentang klasifikasi sentimen positif, negatif, dan netral pada data uji dan untuk mengetahui keakuratan model klasifikasi menggunakan metode Deep Belief Network ketika diterapkan pada klasifikasi tweet untuk menandai kelas sentimen dari data pelatihan tweet bahasa Indonesia. Peneliti selanjutnya melakukan [6] yang menjelaskan analisis sentimen atas pengaduan masyarakat yang masuk melalui Twitter dan website resmi layanan pengaduan terpadu menggunakan pendekatan semantik, dimana Sentiwordnet dan leksikon sentimen bahasa Indonesia digunakan untuk ekstraksi fitur. Metode yang digunakan adalah metode rules-based, fitur yang digunakan dalam penelitian ini adalah unigram (kata) yang sesuai dengan sentimen sentiwordnet dan leksikon bahasa Indonesia.
Dalam penelitian yang dilakukan pada tahun 2018 [7] menjelaskan tentang pemilihan fitur Query Expansion Ranking, yaitu suatu sistem yang mampu memuat dokumen dan melakukan serangkaian proses sehingga dokumen dapat diklasifikasikan menjadi dua kelas, positif atau negatif Kemudian pada penelitian selanjutnya [8] menjelaskan tentang analisis sentimen pada opini berupa sentimen yang diperoleh dari media sosial Twitter dan Instagram menggunakan metode SVM dan Lexicon Based sehingga dapat
diterapkan untuk mengetahui souvenir mana yang memiliki review paling positif dari masyarakat atau wisatawan yang telah membeli oleh- oleh tersebut, serta perbandingan penggunaan metode Lexicon Based and Support Vector Machine (SVM) yang tidak digabungkan, dan membandingkan hasil akurasi pengujian sistem yang dihasilkan dari masing-masing metode sehingga dapat dilihat kinerja mana yang lebih unggul dari kedua metode tersebut. Penelitian selanjutnya yang telah dilakukan [9] menjelaskan opini publik tentang maskapai penerbangan dalam dokumen twitter perlu dipelajari sebagai pengolahan teks dengan proses yang sangat diperlukan dalam menyaring opini publik dan diklasifikasikan ke dalam kelas positif dan negatif. Sehingga dengan mendapatkan hasil klasifikasi menggunakan metode Support Vector Machine (SVM). Penelitian selanjutnya yang telah dilakukan [10] menjelaskan opini publik tentang film, bersumber dari twitter dengan menggunakan metode Naïve Bayes dan Lexicon Based Feature, dengan menguji metode Naïve Bayes dan fitur berbasis leksikon untuk analisis sentimen opini film. Melakukan analisis objek wisata di Bali menggunakan alat snowflake [11]. melakukan analisis transportasi menggunakan media sosial [12]. Pada penelitian selanjutnya [13] menjelaskan identifikasi dengan metode support vector machine (SVM) Melakukan pendekatan berbasis teks yang dianalisis untuk melacak insiden lalu lintas serupa menggunakan kesamaan teks. [14].
Berdasarkan latar belakang di atas, penulis melakukan penelitian tentang analisis sentimen antusias masyarakat terhadap sampah plastik menggunakan metode support vector machine (SVM), guna mengetahui antusiasme masyarakat terhadap sampah plastik sekali pakai, dan memberikan saran untuk mengatasi banyaknya sampah plastik di Indonesia berdasarkan tweet orangorang di twitter, karena support vector machine (SVM) lebih efisien dibandingkan metode lain.
-
[2] Metode Penelitian
Beberapa tahapan yang dilakukan dalam penelitian, antara lain dimulai dari pengumpulan data yang dijadikan sebagai data latih dan berjumlah 1500 data. Data diambil dari media sosial twitter dengan kata kunci sampah plastik, botol plastik, kantong plastik, sampah plastik, setelah data latih terkumpul langkah selanjutnya adalah mengumpulkan sumber data pengujian dari media sosial twitter. Setelah data training dan testing terkumpul, dilakukan analisis sentimen dengan beberapa proses yaitu pre-processing, TF-IDF, dan klasifikasi metode SVM. Keluaran
dari hasil analisis berupa sentimen positif, netral dan negatif, tahap terakhir adalah memvisualisasikan data dan menarik kesimpulan.
-
1. Pengumpulan Data
Pengumpulan data yang digunakan adalah tahap pengumpulan data yang digunakan sebagai data pengetahuan dalam analisis sentimen yang terdapat dalam teks. Data latih yang digunakan berupa data yang diperoleh dari hasil pengikisan dan pelabelan dilakukan secara manual. Detail data latih dan struktur data latih dapat dilihat sebagai berikut.
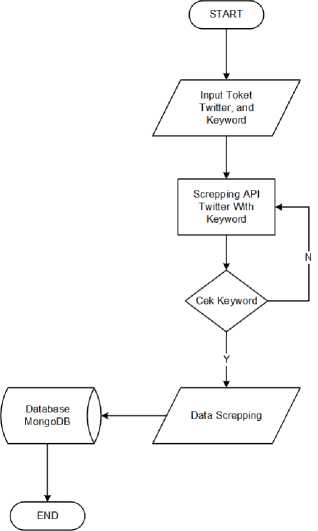
Gambar 1 Diagram Proses Scraping Data
-
2. Pre-Processing
Pre-Processing data merupakan rangkaian tahapan bagaimana data akan diolah terlebih dahulu sebelum memasuki tahap pengolahan, diagram proses tahapan pre-processing dapat dilihat sebagai berikut.
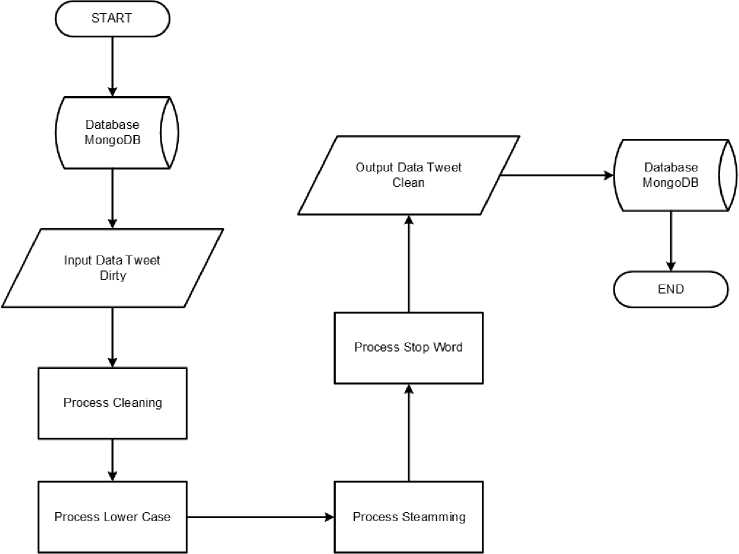
Gambar 2 Diagram Pre-Processing
Tahapan yang dilakukan dalam proses pre-processing dijelaskan sebagai berikut, proses data cleaning adalah proses untuk menghilangkan atribut teks yang tidak diperlukan, berupa username tweet dalam teks, link URL dalam teks, dan atribut seperti symbol, selanjutnya adalah proses lowering case yaitu mengubah huruf kapital semua review yang terdapat pada dokumen data latih dan data uji diubah menjadi huruf kecil, selanjutnya adalah proses data stemming yaitu proses pengambilan kata dasar yang telah dibubuhi akhiran dan awalan. Proses stemming data ini menggunakan library stemmer dari sastrawi Sastrawi merupakan salah satu library dalam proses data stemming, pada data bahasa Indonesia untuk menghilangkan suffix dan prefix, proses data tokenization adalah pemotongan kata berdasarkan setiap kata yang menyusunnya menjadi satu kesatuan, dan yang terakhir data proses stop words yaitu process menghilangkan kata-kata yang tidak sesuai dengan topik dokumen, karena kata-kata tersebut tidak mempengaruhi keakuratan dalam klasifikasi dari analisis sentimen. [15]
-
3. TF-IDF Weighting
Pada tahap pembobotan kata digunakan metode Term Frequency – Inverse Document Frequency (TF-IDF) untuk mendapatkan nilai bobot setiap kata pada data yang digunakan.
Proses pembobotan kata menggunakan algoritma tf-idf. Tf-idf menyajikan skor frekuensi kata, terutama untuk kata-kata yang menarik, misalnya kata-kata yang sering muncul dalam satu dokumen tetapi tidak semua dokumen. Proses ini dilakukan dengan menghitung bobot setiap kata pada data latih menggunakan library Sklearn dengan dua skema, skema yang digunakan antara lain jumlah kata dengan CountVectorizer, frekuensi kata dengan Tf-idfVectorizer. [16]
-
4. Data Visualization
Perancangan visualisasi data merupakan rangkaian tahapan dalam menampilkan hasil analisis data, yang menggambarkan diagram proses visualisasi data menggunakan tool Tableau. Diagram proses visualisasi data dijelaskan sebagai berikut.
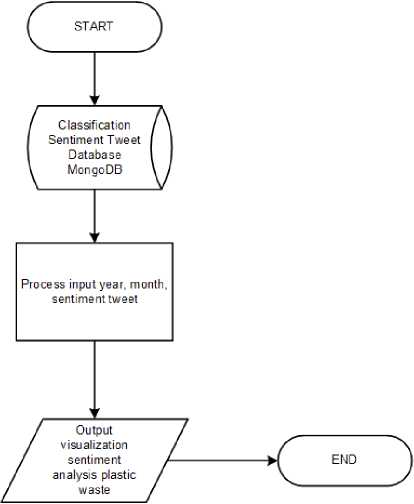
Gambar 3 Diagram Proses Visualisasi Data
Proses visualisasi data menggunakan tool Tableau, dimulai dengan mengimpor data dari database MongoDB, kemudian dilanjutkan dengan proses memasukkan tahun, bulan, dan sentimen dari tweet yang diproses, dan terakhir menampilkan hasil analisis sentimen dalam bentuk baris grafik dan peta.
-
[3] Kajian Pustaka
Kajian Pustaka merupakan tahapan yang digunakan dalam teori dalam analisis sentimen antusias masyarakat terhadap sampah plastik dengan menggunakan metode support vector machine. Bagian kajian pustaka memaparkan berbagai teori yang diperoleh dari buku, jurnal atau e-book dan berbagai penelitian sebelumnya yang memiliki permasalahan yang berkaitan satu sama lain dengan penelitian yang dilakukan.
-
a. Twitter
Twitter adalah layanan aplikasi untuk media sosial dan merupakan layanan micro blogging yang memungkinkan pengguna untuk mengirim pesan secara real time, pesan ini dikenal sebagai tweet. Tweet adalah pesan singkat dengan panjang karakter dibatasi hingga 140 karakter yang ditetapkan oleh Twitter, Karena keterbatasan jumlah karakter yang dapat ditulis, tweet sering mengandung singkatan, bahasa asing, atau kesalahan ejaan, twitter dibuat sebagai ponsel layanan berbasis dirancang sesuai dengan batas karakter dalam pesan teks sampai saat ini. Teks yang tidak terstruktur dapat dilihat pada bagian teks atau yang lebih
sering disebut dengan tweet karena isi pada bagian ini tidak memiliki struktur khusus, aturan yang berlaku hanya maksimal jumlah karakter yang boleh dimasukkan adalah 140 karakter. [9]
-
b. Sentiment Analysis
Analisis sentimen atau penggalian opini adalah pendeteksian sikap terhadap objek atau orang. Analisis sentimen dapat digunakan untuk mendapatkan persentase sentimen positif, netral dan negatif terhadap seseorang, perusahaan, institusi, produk atau dalam kondisi tertentu. Nilai dari analisis sentimen dapat dipecah menjadi 3 yaitu sentimen positif, sentimen negatif dan sentimen netral atau diperdalam sehingga dapat ditemukan siapa atau kelompok yang menjadi sumber sentimen positif, netral atau negatif.
Sedangkan menurut analisis sentimen adalah proses yang digunakan untuk menentukan opini, emosi dan sikap yang tercermin melalui teks, dan biasanya diklasifikasikan menjadi opini negatif, netral dan positif. menentukan sentimen atau pendapat seseorang yang diwujudkan dalam bentuk teks dan dapat dikategorikan sebagai sentimen positif, netral atau negatif. Seperti yang telah ditulis sebelumnya, banyak pengguna internet yang menulis tentang pengalaman, opini, dan hal-hal yang menjadi perhatian mereka. Menulis tentang apa yang mereka rasakan berupa perasaan positif, netral atau negatif yang dapat diungkapkan dengan cara yang cukup kompleks. [17]
-
c. Support Vector Machine
Support Vector Machine (SVM) merupakan salah satu teknik untuk melakukan prediksi, baik dalam hal klasifikasi maupun regresi. SVM memiliki prinsip dasar pengklasifikasi linier, yaitu kasus klasifikasi yang dapat dipisahkan secara linier, tetapi SVM telah dikembangkan untuk bekerja pada masalah nonlinier dengan memasukkan konsep kernel dalam ruang kerja berdimensi tinggi Pada ruang berdimensi tinggi akan dicari hyperplane (hyperplane) yang dapat memaksimalkan jarak (margin) antar kelas data. Hal ini dapat dirumuskan dalam masalah optimasi SVM untuk klasifikasi linier. [18]
Mesin vektor dukungan dan Neural Network telah berhasil digunakan dalam pengenalan pola. Pembelajaran dilakukan dengan menggunakan sepasang data masukan dan data keluaran berupa target yang diinginkan Konsep SVM dapat dijelaskan secara sederhana sebagai upaya untuk menemukan hyperplane terbaik yang berfungsi sebagai pemisah dua kelas dalam ruang input. SVM mencoba mencari fungsi pemisah (hyperplane) dengan memaksimalkan jarak antar kelas. Dengan cara ini, SVM dapat menjamin generalisasi yang tinggi untuk data di masa mendatang. [19]
-
[4] Hasil dan Pembahasan
Analisis sentimen antusias masyarakat terhadap sampah plastik menggunakan metode support vector machine yang bertujuan untuk menganalisis antusias masyarakat terhadap
sampah plastik dan mengetahui grafik peningkatan antusias dan daerah mana saja yang peduli terhadap sampah plastik, setelah dilakukan analisis akan menunjukkan angka positif, netral, dan negatif mengikuti struktur data pelatihan sebagai berikut.

Gambar 4 Struktur Data Training
-
1. Hasil Pengolahan Data
Hasil dari proses data latih merupakan hasil dari rangkaian analisis sebelum melakukan analisis sentimen, dilakukan proses data latih untuk pengujian sentimen engine menggunakan 1.500 data latih yang sudah berisi label positif, netral dan negatif. Tujuan dari pengujian data latih adalah untuk mengetahui kualitas model data yang digunakan dalam analisis sentimen mulai dari akurasi, presisi, recall, dan f1score. Pengujian dilakukan dengan memisahkan data pada data latih, hasil skenario proses data latih adalah seperti pada tabel 1 di bawah ini.
Table 1 Proses Scenario Data Training
|
No |
Jumlah data |
Training Data |
Testing Data |
Accurac y |
Precision |
Recall |
F1 Score |
|
1 |
1,500 |
90% |
10% |
81.81 |
98,90 |
81.81 |
89.21 |
|
2 |
1,500 |
80% |
20% |
82.27 |
97.89 |
82.27 |
88.73 |
|
3 |
1,500 |
70% |
30% |
81.21 |
97.99 |
81.21 |
88.43 |
|
4 |
1,500 |
60% |
40% |
80.00 |
98.22 |
80.00 |
87.74 |
Hasil skenario proses pelatihan data dilakukan dengan 4 kali uji coba. Hasil terbaik dari proses pelatihan terdapat pada data proses pelatihan no. 2 yang menggunakan 80% data latih dan 20% data uji dan menghasilkan akurasi 82,27%, presisi 97,89%, recall 82,27%, dan skor f1 sebesar 88,73%.
-
2. Hasil Proses Analisis SVM
Hasil analisis metode Support Vector Mechine (SVM) merupakan hasil dari rangkaian proses analisis SVM. yang bertujuan untuk mencari nilai masing-masing label sentimen pada data pengujian, kemudian menampilkan label sentimen positif, netral dan negatif dari tweet Hasil dari proses analisis sentimen menggunakan metode support vector machine (SVM)
Dimana sebelumnya tweet tersebut tidak memiliki label sentimen, maka dilakukan proses analisis sentimen dan didapatkan hasil sentimen dari tweet tersebut.
suka banget pantai hobi snorkeling Laut bersih tanpa sampah plastik aplg selam hati benci ras cinta damai suka teman siapa aplg teman calon mertua biar anak drestui layak folbek
Positive
{,Created.at,: lSat Nov Θ2 11:25:20 +OOOO 2Θ19,, 'Text': 'suka banget pantai hobi snorkeling laut bersih tanpa sampah plastik aplg selam hati benci ras cinta damai suka teman siapa
suka banget makan ikan betul suka makan daging makan teman cinta alam yang selalu buang sampah pada tempat sampah plastik kaleng mantan kalo giat bersih pantai ikut dong karena Positive
{'Created_at': 'Sat Nov 02 11:18:11 +θθθθ 2019', 'Text': 'suka banget makan ikan betul suka makan daging makan teman cinta alam yang selalu buang sampah pada tempat sampah plastik
serma ilham fahruzi sama lembaga peduli lingkung hidup bersih sampah plastik alir sungai
Positive
{'Created-at': 'Sat Nov 02 10:58:00 +00θ0 2019', 'Text': 'serma ilham fahruzi sama lembaga peduli lingkung hidup bersih sampah plastik alir sungai', 'Sentiment': 'Positive'}
puluh pramuka grobogan latih olah sampah plastik jadi barang serbaguna Positive
. {'Created-at': 'Sat Nov 02 10:56:12 +0000 2019', 'Text': 'puluh pramuka grobogan latih olah sampah plastik jadi barang serbaguna', 'Sentiment': 'Positive'}
s ===============================================================
kelas kreatif kolaborasi antara Profesoresartproduction sama mamuju ajar molo buat antisias siswa molo agak beda hari olah sampah plastik jadi rajin tangan upa bunga Positive
g {'Created_at': 'Sat Nov 02 10:54:17 +0000 2Θ19', 'Text': 'kelas kreatif kolaborasi antara Profesoresartproduction sama mamuju ajar molo buat antisias siswa molo agak beda hari olah
Gambar 5 Hasil Analisis SVM
-
3. Hasil Visualisasi
Hasil visualisasi data merupakan hasil visualisasi data analisis sentimen dari tweet berupa grafik garis dan peta. Adapun hasil mengenai bentuk visualisasi data dapat dilihat sebagai berikut.
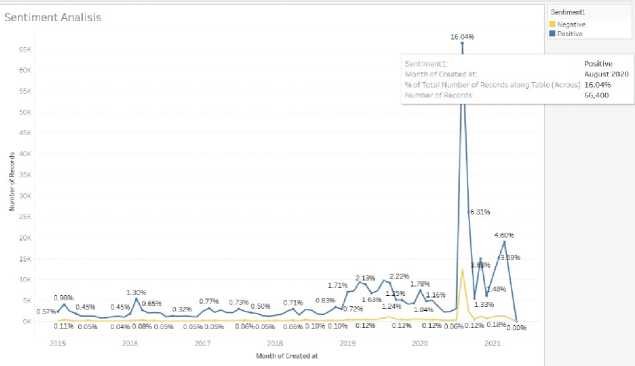
Gambar 6 Hasil Visualisasi Grafik
Gambar 6 menggambarkan hasil visualisasi analisis sentimen pada sampah plastik mulai tahun 2015 hingga 2021 dalam bentuk grafik garis. Hasil visualisasi menunjukkan bahwa setiap tahun dan bulan terjadi peningkatan dari antusiasme masyarakat yang mendukung pengurangan sampah plastik, hal ini ditunjukkan dengan sentimen positif yang terus meningkat dari tahun ke tahun, dan pada bulan Agustus 2020 terjadi peningkatan yang sangat tinggi. dari tahun-tahun sebelumnya dan bulan-bulan sebelumnya, pada Agustus 2020 meningkat sebesar 17,71%, berdasarkan data tweet di media sosial Twitter.
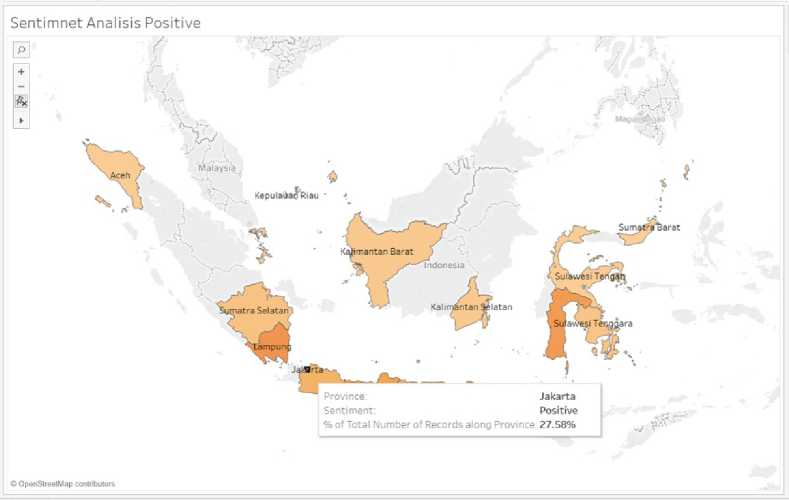
Gambar 7 Hasil Visualisasi Sentiment Posistif
Gambar 7 menggambarkan visualisasi sentimen analitik positif dalam bentuk peta, gradasi warna pada peta menunjukkan tingkat antusiasme masyarakat yang ada, semakin gelap gradasi warna maka semakin besar tingkat kepedulian terhadap sampah plastik di provinsi tersebut. Pada gambar tersebut, Jakarta memiliki warna yang lebih gelap dari provinsi lain dan merupakan provinsi yang paling antusias mengurangi sampah plastik sebesar 27,58%, berdasarkan data tweet di media sosial Twitter.
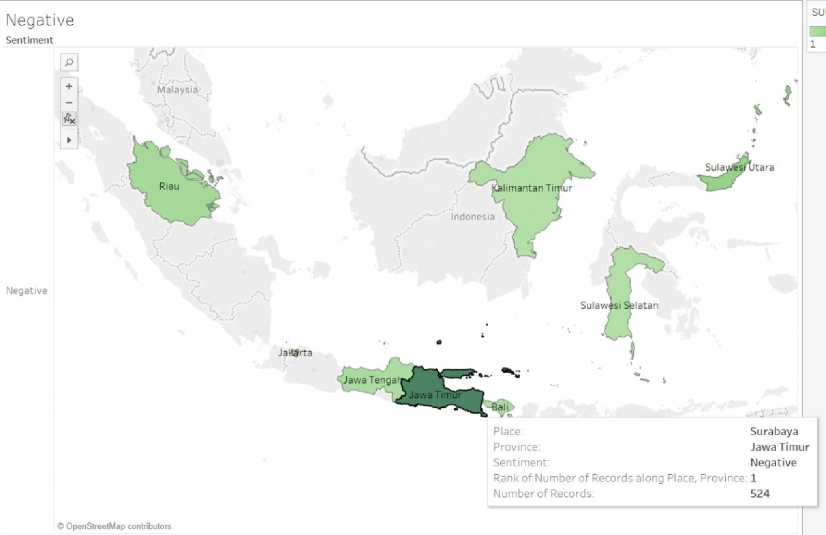
Gambar 8 Hasil Visualisasi Sentiment Negatif
Gambar 8 menjelaskan hasil visualisasi analisis sentimen negatif berupa peta, gradasi warna pada peta menunjukkan tingkat kurang antusiasnya masyarakat yang ada, semakin gelap gradasi warna maka semakin besar tingkat ketidakpedulian terhadap sampah plastik di provinsi. Pada gambar tersebut, Jawa Timur memiliki warna yang lebih gelap dari provinsi lain dan merupakan provinsi yang berdasarkan tweet kurang peduli dan menghasilkan sampah plastik paling banyak, berdasarkan data tweet di media sosial twitter.
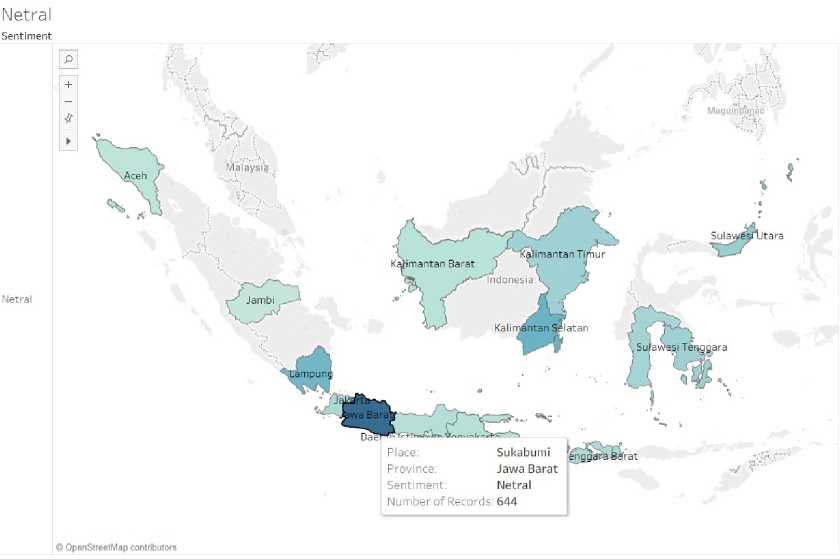
Gambar 9 Hasil Visualisasai Sentiment Netral
Gambar 9 menggambarkan hasil visualisasi sentimen analisis netral dalam bentuk peta, gradasi warna pada peta menunjukkan tingkat ketidakberdayaan masyarakat yang ada, semakin gelap warna gradasinya maka semakin besar tingkat netralitasnya dengan sampah plastik di provinsi tersebut. Pada gambar tersebut, Jawa Barat memiliki warna yang lebih gelap dibandingkan provinsi lain dan merupakan provinsi yang netral terhadap sampah plastik, berdasarkan data tweet di media sosial Twitter.
-
[5] Kesimpulan
Kesimpulan yang dapat diambil dari analisis antusias masyarakat terhadap sampah plastik menggunakan metode support vector machine (SVM) adalah penelitian ini membuktikan bahwa metode klasifikasi support vector machine berpengaruh signifikan terhadap nilai akurasi klasifikasi. Rata-rata nilai akurasi yang diperoleh adalah 82,27% sebagai nilai paling optimal Tingkat ketelitian ini diperoleh dengan jumlah data latih 1500 kalimat dan 4 kali percobaan Daerah yang memiliki tingkat kepedulian terhadap sampah plastik adalah provinsi DKI Jakarta, kemudian daerah yang kurang antusias terhadap sampah plastik adalah provinsi Jawa Timur di kota Surabaya, dan daerah yang netral terhadap sampah plastik adalah barat. Wilayah Jawa di Kota Sukabumi, data-data yang di peroleh bersumber dari kicauan (tweet) di media sosial twitter yang ditulis oleh masyarakat.
References
-
[1] R. H. R. A. H. I. N. A. Astari Clara Sari, Komunikasi dan Media Sosial, Makasar: ReseachGate, December 2018.
-
[2] P. I. S. W. W. W. Nurrun Muchammad Shiddieqy Hadna, "Studi Literatur Tentang Perbandingan Metode untuk Proses Untuk Proses Analisis Sentimen di Twitter," SENTIKA, 2016.
-
[3] E. W. Wirga, "Analisis Konten Pada Media Sosial Video Youtube Untuk Mendukung Strategi Kampanye Politik," Jurnal Ilmiah Informatika dan Komputer, vol. 21, no. (1), pp. 14 - 26, 2016.
-
[4] R. S. P. M. A. F. Winda Estu Nurjanah, "Analisis Sentimen Terhadap Tayangan Televisi Berdasarkan Opini Masyarakat pada Media Sosial Twitter menggunakan Metode K-Nearest Neighbor dan Pembobotan Jumlah Retweet," Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol. 1, no. (12), pp. 1750 - 1757, 2017.
-
[5] Z. Ira, "Sentiment Analisis Tweet Berbahasa Indonesia Dengan Deep Belief Network," IJCCS, vol. 11, no. (2), pp. 187 - 198, 2017.
-
[6] M. Lailiyah, "SENTIMENT ANALYSIS MENGGUNAKAN RULE BASED METHOD PADA DATA PENGADUAN PUBLIK BERBASIS LEXICAL RESOURCES," Political Science, Surabaya, 2017.
-
[7] M. A. F. S. A. Shima Fanissa, "Analisis Sentimen Pariwisata di Kota Malang Menggunakan Metode Naive Bayes dan Seleksi Fitur Query Expansion Ranking," Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol. 2, no. (8), pp. 2766 - 2770, Agustus 2018.
-
[8] D. G. P. D. ,. W. K. Hidayatulah Himawan, "Metode Lexicon Based Dan Support Vector Machine Untuk Menganalisis Sentiment Pada Media Sosial Sebagai Rekomendasi Oleh-Oleh Favorit," Seminar Nasional Informatika, vol. 1, no. (1), pp. 235 - 244, 2018.
-
[9] I. C. P. P. A. Arsya Monica Pravina, "Analisis Sentimen Tentang Opini Maskapai Penerbangan pada Dokumen Twitter Menggunakan Algoritme Support Vector Machine (SVM)," Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol. 3, no. (3), pp. 2789 - 2797, 2019.
-
[10] I. S. A. Arifin Kurniawan, "Analisis Sentimen Opini Film Menggunakan Metode Naïve Bayes dan Lexicon Based Features," Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol. 3, no. (9), pp. 8335 - 8342, 2019.
-
[11] I. M. A. D. S. D. P. G. Ni Putu Ayu Widiari, "Teknik Data Cleaning Menggunakan Snowflake untuk Studi Kasus Objek Pariwisata di Bali," Jurnal Ilmiah Merpati, vol. 8, no. (2), pp. 137 - 145, 2020.
-
[12] I. K. G. D. P. N. K. D. Desak Ayu Putu Savita Arsarini, "Public Sentiment Analysis of Online Transportation in Indonesia through Social Media Using Google Machine Learning," Jurnal Ilmiah Merpati, vol. 9, no. (2), pp. 153 - 164, 2021.
-
[13] Y. L. Antonius Rachmat Chrismanto, "Identifikasi Komentar Spam Pada Instagram," Lontar Komputer, vol. 8, no. (3), pp. 219 - 231, 2017.
-
[14] J. L. B. Myrna Ermawati, "Text Based Approach For Similar Traffic Incident Detection from Twitter," Lontar Komputer, vol. 9, no. (2), pp. 63 -71, 2018.
-
[15] S. MUJILAHWATI, "Pre-Processing Text Minning pada Data Twitter," Seminar Nasional Teknologi Informasi dan Komunikasi, pp. 49 - 56, 2016.
-
[16] E. S. P. Alven Safik Ritonga, "PENERAPAN METODE SUPPORT VECTOR MACHINE (SVM) DALAM KLASIFIKASI KUALITAS PENGELASAN SMAW (SHIELD METAL ARC WELDING)," Jurnal Ilmiah Edutic, vol. 5, no. (1), pp. 17 -25, 2018.
-
[17] L. e. a. Coletta, "Combining Classification and Clustering for Tweet Sentiment Analysis. In 2014 Brazilian Conference on Intelligent Systems. IEEE," Brazilian Conference on Intelligent Systems, pp. 210 - 215, 2014.
-
[18] A. M. S. K.Srividya, "Sentiment Analysis of Face Book Statuses," International Journal of
Recent Technology and Engineering, vol. 7, pp. 636 - 641, 2019.
-
[19] A. M. ,. S. M. J. D. S. Zidna Alhaq, "PENERAPAN METODE SUPPORT VECTOR MACHINE UNTUK ANALISIS SENTIMEN PENGGUNA TWITTER," Jurnal of Information System Management, vol. 3, no. (1), pp. 16 - 21, 2021.
Discussion and feedback