Identifikasi Forensik Biometrik Pada Individu Melalui Citra Sidik Bibir Menggunakan Descriptor Features
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana
Volume 11, No 4. May 2023
Identifikasi Forensik Biometrik Pada Individu Melalui Citra Sidik Bibir Menggunakan Descriptor Features
Putu Bayu Baskaraa1, I Made Widiarthaa2, I Gede Artha Wibawaa3,
I Wayan Suprianaa4, Ida Bagus Gede Dwidasmaraa5, Gede Santi Astawaa6
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana
Badung, Bali, Indonesia
1bayu.baskara@student.unud.ac.id
Abstract
Identifikasi biometrik menjadi begitu penting dan berkembang cukup pesat. Telah banyak bidang yang menggunakan identifikasi biometrik, salah satunya adalah dalam penyelidikan dan pemecahan kasus forensik seperti tindakan kriminal. Sidik bibir dapat menjadi salah satu metode identifikasi, karena polanya yang unik, stabil dan berbeda untuk setiap individu bahkan pada saudara kembar sekalipun. Identifkasi ini dapat dilakukan dengan bantuan pengolahan citra digital. Terdapat banyak metode yang dapat digunakan untuk melakukan identifikasi, salah satunya Speed Up Robust Features (SURF) dan Fast Approximate Nearest Neighbor (FANN) yang diakan digunakan pada penelitian ini. Data yang akan digunakan berupa data citra sidik bibir sebanyak 105 citra, yang kemudian akan diambil 15 citra sebagai data test dan 90 citra sebegai data refferal. Metode SURF akan mengektraksi fitur citra sidik bibir berupa descriptor yang kemudian akan dicocokkan menggunakan metode FANN. Skenario pengujian yang akan dilakukan dengan mengambil 5 kemungkinan calon yang cocok. Hasil pengujian menunjukkan telah berhasil mengidentifikasi sebanyak 12 individu dari total 15 individu dengan akurasi sebesar 80%.
Keywords: Identification, Biometric, Lip Print, Descriptor Features, Image Processing
Biometrik merupakan serangkaian data unik dan spesifik, yang dapat dikenali dan diverifikasi dalam proses identifikasi biometrik seseorang. Telah banyak bidang yang menggunakan identifikasi biometrik ini, salah satunya adalah dalam penyelidikan dan pemecahan kasus forensik seperti tindakan kriminal. Identifikasi ini diperlukan untuk mengetahui korban maupun pelaku kriminal, baik yang masih hidup maupun sudah meninggal. Data biometrik berupa foto wajah, gigi, sidik jari, golongan darah, dan perbandingan DNA (Deoxyribose Nucleic Acid) adalah metode yang paling umum digunakan untuk proses identifikasi, namun jika data tersebut belum cukup mendukung atau tidak tersedia dengan baik, perlu dilakukan metode identifikasi yang berbeda.
Sidik bibir dapat menjadi salah satu metode identifikasi, karena polanya yang unik, stabil dan berbeda untuk setiap individu bahkan pada saudara kembar sekalipun [1]. Dalam kasus kriminal, sidik bibir dapat tertinggal pada gelas kaca, sedotan, dan beberapa objek barang bukti lain yang terdapat pada TKP. Sidik bibir yang terdapat pada barang bukti tersebut dapat dibandingkan dengan sidik bibir korban maupun tersangka, kemudian hasil analisis dari sidik bibir tersebut dapat digunakan sebagai alat bukti untuk kepentingan identifikasi [2]. Identifikasi menggunakan sidik bibir pertama kali dilakukan oleh R. Fisher pada tahun 1902 [3]. Namun, seiring perkembangan teknologi digital, proses identifikasi pada sidik bibir dapat dipermudah dengan menggunakan Pengolahan Citra Digital (Digital Image Processing). Sehingga hasil identifikasi menjadi lebih akurat dan maksimal.
Salah satu metode yang dapat digunakan untuk proses identifikasi adalah Speed Up Robust Feature (SURF). Metode SURF ini akan menghasilkan keypoint yang masing-masing memiliki descriptor
Baskara, dkk
Identifikasi Forensik Biometrik Pada Individu Melalui Citra Sidik Bibir Menggunakan Descriptor Features feature yang dapat digunakan untuk proses identifikasi. Penelitian Afifah dan Mahmudy, mengenai Implementasi Ekstraksi Fitur Jumlah Keypoint Descriptor Pada Pengenalan Tanda Tangan, akurasi yang diperoleh dari penambahan ektraksi fitur jumlah keypoint descriptor adalah sebesar 92% pada data latih dan 89% pada data uji sedangkan tanpa menggunakan fitur jumlah keypoint descriptor diperoleh akurasi sebesar 88% pada data latih dan 88% pada data uji [4]. Metode Speed Up Robust Feature (SURF) adalah pengembangan dari metode Scale Invariant Feature Transform (SIFT). Hasil dari penelitian Bakshi, dkk mengenai ektraksi fitur lokal citra sidik bibir, menunjukan bahwa metode SURF memiliki tingkat akurasi lebih besar dari metode SIFT, yaitu SIFT sebesar 93,9880% sedangkan SURF sebesar 94,0972% [5].
Pada penelitian ini, ekstraksi descriptor feature dilakukan dengan menggunakan metode Speeded Up Robust Feature (SURF) yang akan gunakan sebagai fitur untuk identifikasi individu.
Penelitian ini terbagi menjadi beberapa tahapan, diantaranya studi literatur, pengumpulan data, preprocessing, ekstraksi fitur, pencocokan fitur, dan pengujian. Pada tahap studi literatur adalah tahapan pencarian, pengumpulan serta pemahaman mengenai informasi dan literatur yang mendukung dalam penelitian ini. Data yang digunakan dalam penelitian ini adalah data sekunder yang diperoleh dari Data berasal dari University of Silesia at Katowice. Tahapan selanjutnya adalah preprocessing, dimana pada tahapan ini terdapat proses resize image, smoothing image, binarization, dan skelentonize. Kemudian dilanjutkan ektraksi fitur descriptor menggunakan metode Speeded Up robust feature (SURF), dan terakhir adalah proses pencocokan descriptor features menggunakan metode Fast Approximate Nearest Neighbor (FANN).
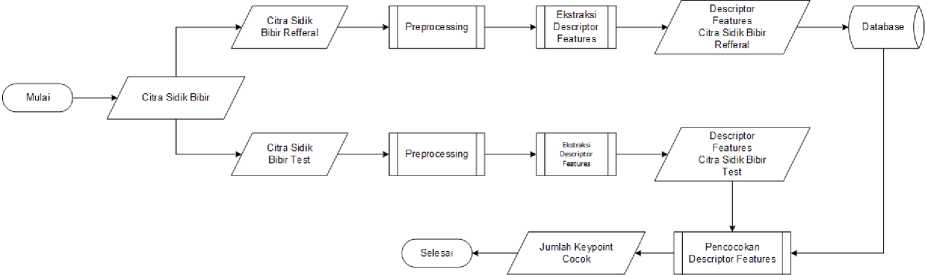
Gambar 1. Flowchart Desain Penelitian
Gambar 1 merupakan desain penelitian identifikasi individu melalui citra sidik bibir. Data citra sidik bibir sebagai input akan dibagi menjadi dua yaitu data refferal dan data test. Masing-masing akan melalui proses yang sama yaitu preprocessing, ekstraksi fitur descriptor menggunakan Speeded Up Robust Feature (SURF) dan terakhir adalah pencocokan fitur menggunakan Fast Approximate Nearest Neighbor (FANN) yang kemudian akan menghasilkan jumlah keypoint yang cocok.
Studi literatur merupakan tahapan pencarian, pengumpulan serta pemahaman mengenai informasi, literatur dan teori-teori yang mendukung terkait dengan penelitian mencakup tahapan dalam pengolahan citra digital dan algoritma yang digunakan untuk ektraksi dan pencocokan fitur sidik bibir yaitu Speeded Up Robust Feature (SURF) dan Fast Approximate Nearest Neighbor (FANN).
Jenis data yang akan digunakan dalam penelitian ini adalah data sekunder berupa sidik bibir. Data berasal dari University of Silesia at Katowice, Faculty of Computer Science and Material Science, Institute of Computer Science, Computer Systems Department (http://biometrics.us.edu.pl). Data terdiri dari 105 file citra sidik bibir berformat BMP (Bitmap Image Format) yang diambil dari 15 orang individu. Data ini kemudian akan dibagi menjadi dua bagian yaitu 15 file sebagai data test yang akan digunakan untuk pengujian dan 90 file sebagai data refferal yang akan menjadi data refferal dalam proses pencocokan fitur.
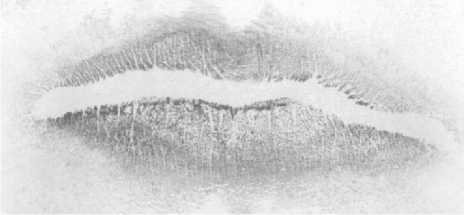
Gambar 2. Contoh Data Citra Sidik Bibir
Gambar diatas adalah contoh data citra sidik bibir yang akan digunakan dalam penelitian. Citra sidik bibir yang digunakan berupa citra grayscale (keabuan). Warna data awal citra dapat saja berwarna merah seperti warna asli bibir yang biasanya menggunakan metode lipstik untuk mengambilannya,
Preprocessing merupakan tahapan untuk membuang informasi-informasi yang tidak diperlakukan agar citra berada dalam kondisi yang sama dengan citra yang lain sehingga citra-citra tersebut bisa diekstraksi dengan baik. Preprocessing ini juga berpengaruh terhadap jumlah keypoint point yang terdeteksi, dimana hasil menunjukkan citra dengan preprocessing lebih banyak menghasilkan keypoint point yang nantinya akan berpengaruh terhadap jumlah fitur descriptor yang dihasilkan.
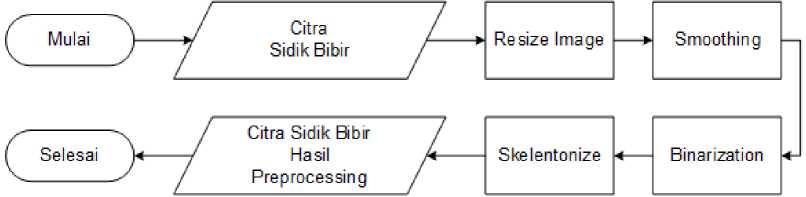
Gambar 3. Flowchart Tahapan Preprocessing
Gambar 3 menunjukkan tahapan preprocessing yang akan dilakukan yaitu dimulai dari resize image, smoothing, binarization, dan skelentonize.
Proses resizing merupakan proses mengubah skala citra awal menjadi skala citra yang diinginkan. Tujuan dari resizing ini adalah agar dimensi dari data yang akan di proses memiliki ukuran yang sama.
Smoothing image merupakan proses mengaburkan (blurring) citra yang bertujuan untuk menghilangkan detail kecil dan menekan gangguan (noise) yang terjadi pada citra sehingga bagian yang ingin diproses pada citra dapat timbul lebih jelas. Smoothing image ini juga sering dikaitkan dengan proses enchancement (pening-katkan kualitas citra). Proses ini menggunakan masking pada citra yang akan dijadikan acuan untuk menentukan nilai intensitas tiap pixels citra.
Binarization pada citra sidik bibir ini menggunakan metode sauvola yang merupakan pengembangan dari metode niblack. Binarization menggunakan metode sauvola yang menerapkan local thresholding T(x,y) untuk melakukan binarization. Perhitungan nilai threshold ini menggunakan rata-rata m(x,y) dan jarak dinamis standard deviasi s(x,y) pada citra. Pada penelitian ini nilai koefisien (k) yang digunakan adalah -0,07 dan range (R) yang digunakan adalah 128. Kamudian nilai threshold ini akan ditentukan untuk menentukan nilai intensitas akhir setiap pixels pada citra. Jika lebih besar dibanding nilai threshold maka akan bernilai 255 jika lebih kecil dibanding nilai threshold maka akan bernilai 0.
Proses ini akan mengurangi objek citra menjadi kerangka tipis yang tetap menahan bentuk asli dari citra. Tahap skelentonize ini akan menggunakan nilai ketetanggaan (neighbor) untuk menentukan intensitas pixels serta bagian pixels yang akan dihilangkan. Neighbor yang digunakan adalah sebanyak delapan nilai yaitu [1 0 0 -1 -1 0 0 1], yang mana nilai ini memberikan hasil yang maksimal dalam melakukan skelentonize citra sidik bibir.
Tahap proses ekstraksi fitur descriptor diawali dengan menginputkan citra hasil preprocessing, kemudian citra tersebut akan difiltering menggunakan integral image. Kemudian akan dideteksi keypoint dari citra. Selanjutnya, keypoint ini akan memiliki nilai descriptor dengan dimensi 64 untuk setiap keypoint yang akan digunakan dalam proses pencocokan. Output dari tahapan ini adalah fitur descriptor akan disimpan kedalam format matriks (.mat) dengan dimensi nx64, d-mana n merupakan jumlah keypoint yang berhasil terdeketsi dengan metode Speeded Up Robust Features (SURF).
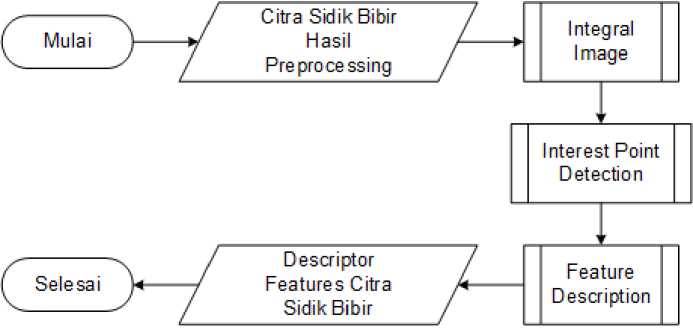
Gambar 4. Flowchart Tahapan Ekstraksi Fitur Descriptor Menggunakan SURF
Gambar 4 menunjukkan proses ekstraksi fitur descriptor pada citra sidik bibir yang telah dipreprocessing dengan menggunakan metode metode Speed Up Robust Features (SURF). Secara garis besar metode ini terbagi menjadi 3 tahapan, yaitu:
-
a. Integral Image, yaitu proses filtering integral image digunakan untuk melakukan filtering terhadap suatu citra sehingga dapat menekan waktu komputasi. Konsep dari integral image adalah dengan menghitung intensitas piksel tiap area dari suatu citra dengan 4 akses dan 3 penjumlahan, sehingga proses ini dapat menekan waktu komputasi [6]. Secara umum integral image dari suatu citra dapat dicari menggunakan persamaan (1) berikut [7].
i≤x j≤y ι∑(χ.y) = ∑∑1 (χ, y) i=0 j=0
-
b. Keypoint Detection digunakan untuk memilih titik (keypoint) yang mengandung banyak informasi serta stabil terhadap gangguan lokal atau global dalam citra digital. Tahapan dimulai dengan mencari ekstrema dari determinan matriks hessian, kemudian membangun scale space untuk menemukan ekstrema disetiap kemungkinan skala. Scale space ini biasanya diimplementasikan dengan bentuk piramida di mana citra secara berulang akan diperhalus (smoothing) dengan fungsi gaussian dan secara berurutan dengan cara sub-sampling untuk mencapai tingkat tertinggi pada piramida [8]. Selanjutnya tahapan terakhir adalah lokalisasi calon fitur menggunakan non-maximum suppression.
-
c. Feature Description, yaitu proses ekstaksi yang akan menghasilkan nilai desriptor dari setiap keypoint yang dideteksi. Langkah untuk melakukan deskripsi fitur adalah melihat orientasi yang domi-nan pada titik perhatian yang terdapat dalam citra, kemudian membangun suatu area yang akan diambil nilainya dan mencari fitur korespondensi pada citra pem-banding. Dalam penentuan orientasi suatu citra menggunakan filter wavelet Haar, disini dapat ditentukan tingkat kemiringan suatu fitur yang diamati. Selanjutnya untuk deskripsi fitur dalam algoritma SURF, digunakan hanya perhitungan gradi-ent histogram dalam empat kelompok (bins) saja untuk mempercepat perhitungan [9].
-
2.5. Pencocokan Fitur
fitur descriptor yang dihasilkan pada proses ekstraksi akan dicocokkan menggunakan metode Fast Approximated Nearest Neighbor (FANN). Tahap ini disebut juga sebagai tahap matching keypoint.
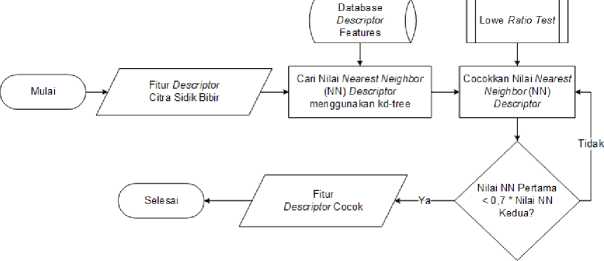
Gambar 5. Flowchart Tahapan Pencocokan Fitur Descriptor Menggunakan FANN
Gambar 5 menunjukkan proses pencocokan fitur descriptor pada citra sidik bibir yang telah dipreprocessing dengan menggunakan metode Fast Approximate Nearest Neighbor (FANN). Tahapan metode dimulai dengan inputan berupa fitur descriptor pada citra sidik bibir yang akan dicari nilai nearest neighbornya menggunkan algoritma kd-tree. Hal yang sama juga dilakukan untuk setiap fitur descriptor data refferal yang tersimpan didalam database. Setelah didapat nilai nearest neighbornya, fitur tersebut akan dicocokkan. Hasil pencocokan fitur descriptor selanjutnya akan difilter menggunakan Lowe Ratio Test dengan threshold sebesar 0,7. Kemudian jika nilai nearest neighbor kurang dari nilai threshold maka fitur descriptor dianggap cocok.
Pada pengujian ini, data fitur descriptor citra sidik bibir akan dibagi men-jadi dua bagian, yaitu data test dan data refferal. Data test merupakan data yang akan menjadi sampel untuk diujikan pada sistem, sedangkan datareferral merupa-kan kumpulan dari seluruh data fitur citra sidik bibir yang akan menjadi rujukan dalam proses pencocokan. Pengujian ini bertujuan untuk mengetahui tingkat iden-tifikasi dengan melakukan evaluasi akurasi
Table 1. Hasil Pengujian Descriptor Feature Citra Sidik Bibir
|
Data Refferal |
Calon Kelas Cocok | ||||||
|
Kelas |
Ind 1 … 1 … 6 … |
. Ind 15 . 85 … 90 |
Calon 1 |
Calon 2 Calon 3 Calon 4 |
Calon 5 | ||
|
Ind 1 |
1 |
k … 48 |
33 … 38 | ||||
|
Rata-rata |
Rata-rata | ||||||
|
H Λ Q |
Ind 3 |
3 |
38 … 41 |
34 … 35 | |||
|
Rata-rata |
Rata-rata | ||||||
Pada Tabel 1, data test yang terdiri dari 15 citra sidik bibir akan dicocokkan dengan masing-masing 90 data refferal. Kedua data ini memiliki 15 kelas, dimana pada data refferal masing-masing kelas memiliki 6 data sedangkan pada data test hanya memiliki 1 data. Kemudian pencocokan ini menggunakan fitur descriptor yang kemudian akan direturn jumlah nilai keypoint yang cocok. Selanjutnya akan dicari nilai rata-rata dari keypoint cocok tersebut pada setiap kelasnya. Kemudian akan diambil tiga buah nilai maksimum dari rata-rata keypoint. Tiga buah nilai maksimum ini akan menjadi calon dalam proses identifikasi dengan melihat kelas yang tertera. Apabila salah satu kelas didalam tiga buah nilai tersebut memiliki kesamaan dengan kelas asli dari data test, maka data citra tersebut berhasil teridentifikasi.
Dari tabel hasil pengujian tersebut, selanjutnya adalah menghitung persentase akurasi dari kelas yang diidentifikasi dengan benar. Persentase akurasi dari hasil identifikasi dapat dilihat dengan menggunakan persamaan (9):
Akurasi(0Zo) =
∑ Kelas Cocok ∑ Kelas Total
× 100
Baskara, dkk Identifikasi Forensik Biometrik Pada Individu Melalui
Citra Sidik Bibir Menggunakan Descriptor Features Perhitungan akurasi diatas dihitung dengan cara membagi jumlah kelas cocok dengan jumlah kelas total. Akurasi ini kemudian akan menjadi akurasi final dari identifikasi citra sidik bibir.
akuisisi citra ini dibagi menjadi dua bagian, yaitu akuisisi data test dan akuisisi data refferal. Yang mana data terdiri dari 15 kelas yaitu kelas Individu 1 sampai dengan Individu 15. Pada data test setiap kelas berisi 1 citra sidik bibir grayscale berfomat BMP, sedangkan data refferal setiap kelas berisi 6 citra sidik bibir grayscale berfomat BMP. Satu persatu data test dan data refferal ini nantinya akan melalui proses preprocessing, ekstraksi fitur, dan pencocokan fitur. Dimana pencocokan fitur akan memakai data refferal sebagai data pembandingnya.
Tahapan pertama dari preprocessing adalah melakukan resize image pada data citra sidik bibir. Data cita sidik bibir akan diresize ke dalam dimensi lebar 700 pixels dan tinggi 300 pixels. Perbedaan dimensi citra sebelum dan sesudah melalui proses resizing dapat dilihat pada Gambar 6.

-'rope'?.
819x379
819 pixels
379 pixels
Property Value
Image
Dimensions 700 x 300
Width 700 pixels
Height 300 pixels
Gambar 6. Perbandingan Dimensi Citra Sidik Bibir Sebelum dan Sesudan di Resize
Selanjutnya, citra sidik bibir yang telah diresize akan masuk ke dalam proses smoothing image. Proses smoothing image pada citra sidik bibir menjadikan garis-garis kerutan pada bibir terlihat lebih jelas jika dibandingkan citra sidik bibir grayscale awal dan noise yang terjadi saat proses pengambilan data dapat lebih tersamarkan setelah melalui proses ini. Gambar 7 adalah hasil dari proses smoothing image pada citra sidik bibir.
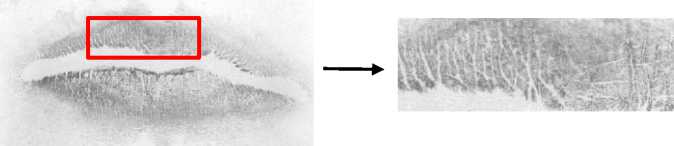
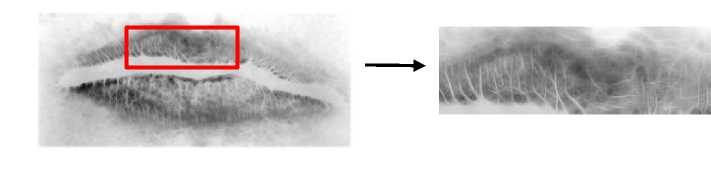
Gambar 7. Hasil Smoothing Image Pada Citra Sidik Bibir
Setelah itu, citra sidik bibir smoothing akan masuk kedalam tahapan binarization yang akan mengubah citra grayscale menjadi citra biner. Binarization ini akan menggunakan metode sauvola. Hasil citra sidik bibir setelah dibinarization dapat dilihat pada Gambar 8.
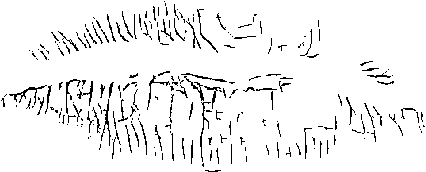
Gambar 8. Hasil Binarization Image Pada Citra Sidik Bibir
Tahapan terakhir dari preprocessing adalah proses skelentonize. Proses ini akan menipiskan objek citra tanpa menghilangkan bentuk aslinya. Hasil proses skelentonize dan perbandingan ketebalan pixels dengan citra sidik bibir binarization dapat dilihat pada Gambar.
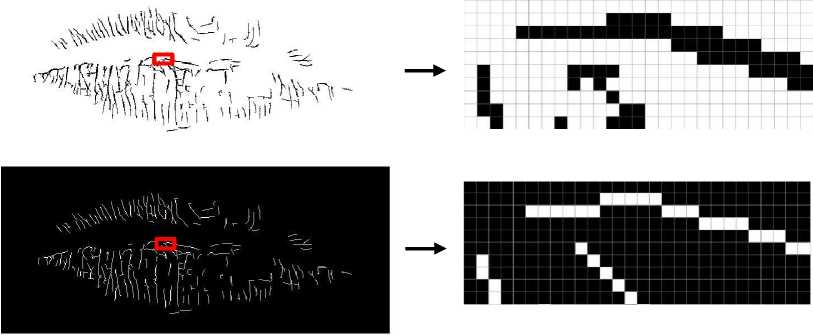
Gambar 9. Perbandingan Ketebalan Pixel Citra Sidik Bibir Binarization dan Skelentonize
Hasil implementasi menunjukkan adanya perbedaan ketebalan pixels pada citra binarization dan skelentonize. Citra binarization memiliki pixels yang seakan-akan bertumpuk sehingga terlihat lebih tebal sedangkan pada citra skelentonize pixels terlihat lebih rapi tanpa adanya tumpukan dan inilah yang membuat citra terlihat lebih tipis namun tidak menghilangkan bentuk asal citra tersebut.
Tahapan ekstraksi fitur menggunakan SURF dimulai dengan membuat Integral Image dari citra inputan, kemudian melakukan interest point detection dan yang terakhir adalah feature description. Hasil dete
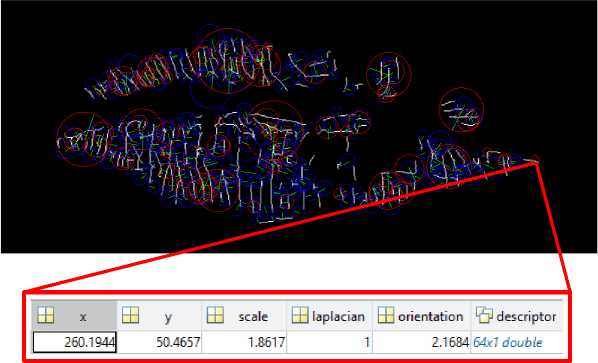
Gambar 10. Ekstraksi Fitur SURF
Dapat dilihat bahwa setiap keypoint menghasilkan beberapa atribut yaitu, koordinat XY, scale, laplacian, orientation, dan descriptor. Kemudian atribut descriptor inilah yang akan diekstrak untuk dijadikan fitur dari setiap keypoint. Contoh dari descriptor feature dapat dilihat pada Gambar 11.
I Ipts X descriptor ⅞ ] E0 371x64 double
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 | |
|
1 |
-0.0059 |
0.0160 |
0.0469 |
0.0418 |
-0.0033 |
0.0139 |
0.0133 |
0.0139 |
0 |
0 |
0 |
0 |
|
2 |
0.0043 |
-0.0113 |
0.0936 |
0.1854 |
-0.0245 |
0.0118 |
0.0486 |
0.0819 |
-0.0017 |
0.0054 |
0.0017 |
0.0054 |
|
3 |
-0.0160 |
0.0312 |
0.0378 |
0.0874 |
-0.0034 |
0.0034 |
0.0034 |
0.0068 |
-7.0442e-04 |
-0.0016 |
7.0442e-04 |
0.0016 |
|
4 |
0.0095 |
-9.6910e-04 |
0.0840 |
0.0973 |
0.0160 |
0.0012 |
0.0846 |
0.1156 |
-0.0237 |
-0.0057 |
0.1406 |
0.1424 |
|
5 |
0.0086 |
-0.0022 |
0.0632 |
0.1524 |
0.0015 |
-0.0030 |
0.1153 |
0.2113 |
-0.0227 |
-0.0072 |
0.0596 |
0.0525 |
Gambar 11. Hasil Descriptor Feature
Fitur descriptor yang terekstrak akan berupa matriks yang berdimensi (n-jumlah keypoint X 64). Seperti pada gambar diatas jumlah keypoint terdeteksi adalah 371, sehinggan setiap keypoint ini akan memiliki 64 nilai descriptor yang akan digunakan untuk pencocokan (matching).
Tahapan pencocokan fitur akan membandingkan satu data test dengan seluruh data refferal, sampai dengan data test ke-n. Ilustrasi pencocokan fitur dapat dilihat pada Gambar 12.
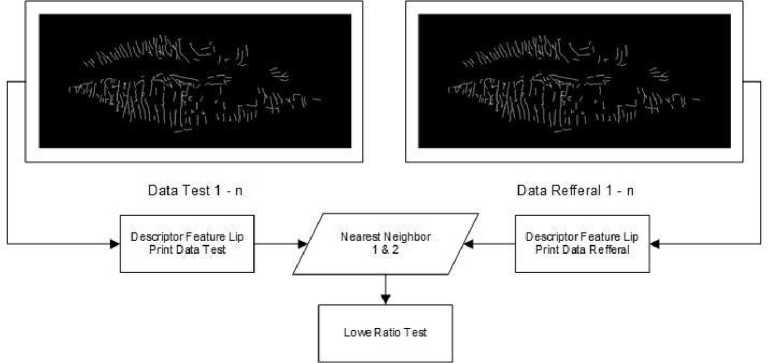
Gambar 12. Pencocokan FANN
Kedua data citra sidik bibir akan dicari dua nearest neighbornya menggunakan algoritma kd-tree berdasarkan fitur descriptor yang telah didapat sebelumnya. Hasil tersebut selanjutnya akan dilakukan lowe ratio test, yang mana jika nearest neighbor pertama kurang dari 0,7*nearest neighbor kedua maka akan dianggap cocok begitupun sebaliknya.
Pengujian akan dilakukan untuk mengetahui akurasi identifikasi individu melalui citra sidik bibir dengan menghitung rata-rata jumlah keypoint cocok berdasarkan pencocokan descriptor feature untuk setiap kelas individu. Kemudian dipilih 5 nilai rata-rata tertinggi untuk menjadi calon kelas cocok. Jika dari kelima calon ini memiliki label kelas yang sama dengan kelas asli dari data test maka identifikasi telah berhasil dilakukan. Selanjutnya akan dihitung akurasi identifikasi berdasarkan jumlah individu yang berhasil diidenifikasi.
Table 2. Hasil Pengujian Descriptor Feature Citra Sidik Bibir
Data Refferal Calon Kelas Cocok
|
Ind 1 …. Ind 15 Kelas 1 … 6 85 … 90 |
Calon 1 |
Calon 2 |
Calon 3 |
Calon 4 |
Calon 5 |
|
27 … 48 33 … 38 Ind 1 1 44 36 |
Ind 8 |
Ind 1 |
Ind 3 |
Ind 12 |
Ind 7 |
|
51 … 51 38 … 42 Ind 2 2 46 41 |
Ind 2 |
Ind 8 |
Ind 10 |
Ind 6 |
Ind 9 |
|
38 … 41 34 … 37 Ind 3 3 40 36 |
Ind 3 |
Ind 7 |
Ind 2 |
Ind 1 |
Ind 5 |
|
C∕) 49 … 75 55 … 76 φ …… Ind 4 4 65 …. 71 *3 21 … 23 21 … 21 S Ind 5 5 2…2 1…9 |
Ind 15 Ind 7 |
Ind 9 Ind 4 |
Ind 10 Ind 9 |
Ind 3 Ind 2 |
Ind 8 Ind 10 |
|
Ind 6 6 52 … 57 47 … 48 55 48 |
Ind 7 |
Ind 11 |
Ind 10 |
Ind 6 |
Ind 3 |
|
27 … 27 42 … 42 Ind 7 7 27 38 |
Ind 15 |
Ind 4 |
Ind 6 |
Ind 7 |
Ind 11 |
|
Ind 8 8 48 … 58 44 … 50 55 49 |
Ind 1 |
Ind 9 |
Ind 2 |
Ind 3 |
Ind 8 |
|
Ind 9 |
9 |
41 |
42 |
46 |
46 |
Ind 3 |
Ind 9 |
Ind 1 |
Ind 14 |
Ind 11 | ||
|
4…2 |
4…3 | |||||||||||
|
Ind 10 |
10 |
39 |
47 |
53 |
53 |
Ind 9 |
Ind 6 |
Ind 10 |
Ind 3 |
Ind 8 | ||
|
4…4 |
5…1 | |||||||||||
|
Ind 11 |
11 |
50 |
62 |
41 |
45 |
Ind 11 |
Ind 1 |
Ind 9 |
Ind 10 |
Ind 7 | ||
|
5…6 |
4…4 | |||||||||||
|
Ind 12 |
12 |
49 |
61 |
61 |
61 |
Ind 10 |
Ind 1 |
Ind 12 |
Ind 9 |
Ind 3 | ||
|
5…6 |
6…0 | |||||||||||
|
Ind 13 |
13 |
54 |
59 |
52 |
52 |
Ind 14 |
Ind 13 |
Ind 1 |
Ind 7 |
Ind 15 | ||
|
5…7 |
5…2 | |||||||||||
|
Ind 14 |
14 |
71 |
71 |
60 |
67 |
Ind 1 |
Ind 7 |
Ind 10 |
Ind 15 |
Ind 2 | ||
|
6…9 |
6…2 | |||||||||||
|
Ind 15 |
15 |
48 |
56 |
50 |
55 |
Ind 10 |
Ind 8 |
Ind 7 |
Ind 15 |
Ind 3 | ||
|
5…3 |
5…3 |
Tabel 2 diatas menunjukkan pengujian pada pencocokan menggunakan descriptor feature. Dapat dilihat bahwa masing-masing data (test dan refferal) memiliki jumlah kelas yang sama yaitu 15 kelas individu. Data test masing-masing memiliki 1 data fitur dan data refferal masing-masing memiliki 6 data fitur. Misalnya data test Ind 1 akan dicocokkan dengan data refferal Ind 1, fitur data test Ind 1 akan dicocokkan secara bergantian dengan 6 buah data fitur milik data refferal Inv 1. Kemudian akan diketahui masing-masing jumlah keypoint yang cocok. Kemudian akan dicari nilai rata-rata dari keypoint tersebuut. Proses ini akan berlanjut hingga ke data refferal Ind 15. Selanjutnya akan di cari 5 buah nilai rata-rata tertinggi dari keseluruhan. Pada data test Ind 1, 5 calon yang memiliki rata-rata tertinggi adalah Ind 8, Ind 1, Ind 1, Ind 12, Ind 7. Nah, dari kelima calon tersebut, akan dilihat apakah ada kelas yang bersesuaian dengan kelas aslinya yaitu Ind 1 dan didapatkan bahwa calon kedua bersesuaian yaitu sama-sama Ind 1. Begitu seterusnya hinggal data test Indv 15. Selanjutnya berdasarkan Tabel 2, kemudian akan dihitung akurasi hasil identifikasi data citra sidik bibir. Berikut adalah akurasi dari hasil identifikasi:
, . 12
Akurasi (%) = — = 80 %
15
Dari perhitungan akurasi, maka didapatkan hasil akurasi identifikasi data citra sidik bibir menggunakan rata-rata fitur descriptor adalah sebesar 80% dengan jumlah individu teridentifikasi sebanyak 12 dari total 15 individu.
Hasil pengujian fitur descriptor Speed Up Robust Features (SURF) menggunakan metode Fast Approximate Nearest Neighbor (FANN) telah berhasil mengidentifikasi sebanyak 12 individu dari total 15 individu dengan akurasi sebesar 80%. Untuk penelitian selanjutnya jika ingin menggunakan data citra primer maka perlu diperhatikan proses dan konsistensi teknik pengambilan sidik bibir agar nantinya data yang dihasilkan bisa sesuai dengan yang diinginkan, data yang digunakan juga dapat menggunakan data citra bibir yang kemudian dipreprocessing untuk mendapatkan sidik bibirnya serta dapat juga menggunakan fitur lain seperti grooves (alur sidik bibir) seperti pada sidik jari.
Referensi
-
[1] S. A. Nadienda, H. F. Oscandar, F. T. Elektro, U. Telkom, D. W. Transform, and S. V.
Machine, “Identifikasi Pola Sidik Bibir Pada Pria Dan Wanita Menggunakan Metode Discrete Wavelet Transform Dan Klasifikasi Support Vector Machine Sebagai Aplikasi Bidang Forensik Identification of Lip Print Pattern on Men and Women Using Discrete Wavelet Transform ,” vol. 4, no. 2, pp. 1923–1931, 2017.
-
[2] M. Yuni, “Metode pengambilan sidik bibir untuk kepentingan identifikasi individu,” J. PDGI, vol.
64, no. 3, pp. 64–70, 2013.
-
[3] M. M. K. Janah Eka Widiarni, Rita Purnamasari, S.T., M.T., drg. Yuti Malinda, “IDENTIFIKASI
POLA SIDIK BIBIR PADA IDENTITAS MANUSIA MENGGUNAKAN METODE HISTOGRAM OF ORIENTED GRADIENTS (HOG) DENGAN KLASIFIKASI DECISION TREE UNTUK APLIKASI BIDANG FORENSIK BIOMETRIK,” ペインクリニック学会治療指針2, vol. 126, no. 1, pp. 1–7, 2019.
-
[4] I. N. Afifah and W. F. Mahmudy, “Implementasi Ekstraksi Fitur Jumlah Keypoint Descriptor
Pada Pengenalan Tanda Tangan Dengan Algoritme Learning Vector Quantization,” vol. 2, no. 11, pp. 4590–4599, 2018.
-
[5] S. Bakshi, R. Raman, and P. K. Sa, “Lip pattern recognition based on local feature extraction,”
Proc. - 2011 Annu. IEEE India Conf. Eng. Sustain. Solut. INDICON-2011, 2011, doi: 10.1109/INDCON.2011.6139357.
-
[6] A. P. Nugraha, S. A. Wibowo, and N. Andini, “Pengaruh Orientasi dari SURF dan U-SURF
Terhadap Waktu Komputasi pada Pelacakan Objek,” pp. 134–140, 2019.
-
[7] C. Evans, “Notes on the OpenSURF Library SURF: Speeded Up Robust Features,” Univ.
Bristol Tech Rep CSTR09001 January, no. 1, p. 25, 2009, [Online]. Available:
http://www.mendeley.com/research/notes-opensurf-library-surf-speeded-up-robust-features/.
-
[8] H. P. Harahap, “Pendeteksi Objek pada Citra Menggunakan Pencocokan Titik-Titik Fitur
berbasis Algoritma SURF dan MSER,” Komputasi, vol. 13, no. 2, pp. 71–79, 2016.
-
[9] David, “Real Time Object Tracking Dengan Algoritma Speeded Up Robust Features Melalui
WebCam,” Semin. Nas. Sist. Inf. dan Teknol. 2018, 2018.
844
Discussion and feedback