Prediksi Kualitas Udara Suspended Particulate Matter dengan Algoritma Backpropagation
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana
Volume 10, No 4. May 2022
Prediksi Kualitas Udara Suspended Particulate Matter dengan Algoritma Backpropagation
I Gede Alanda Indra Kusumaa1, Made Agung Raharjaa2, Cokorda Rai Adi Pramarthaa3, Ida Bagus Made Mahendraa4, I Ketut Gede Suhartanaa5, I Dewa Made Bayu Atmaja Darmawana6
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas UdayanaBadung, Bali, Indonesia
1alanda.indrakusuma99@gmail.com
3cokorda@unud.ac.id 4ibm.mahendra@unud.ac.id 5ikg.suhartana@unud.ac.id 6dewabayu@unud.ac.id
Abstrak
Suspended Particulate Matter (SPM) is particulate dust emitted from several activities such as transportation and industrial factory areas, one of which is PM10. Currently particulates as one of the causes of air pollution are quite a concern in various countries which have an impact on human health. suspended particulate matter stays in the air and does not easily settle and float in the air, on average around 50% - 60% of the suspended particles are 10µm or PM10 in diameter dust so it is very easy to inhale and enter the lungs. So that this research was appointed to predict the concentration of suspended particulate matter using the Backpropagation Algorithm. In this study, three artificial neural network models were built, each of which has a different level of accuracy, the Backpropagation network architecture that produces the highest accuracy value is by using a network scheme of 3 input layers, 20 hidden layers and 1 output layer with a learning rate. 0.8, the target error is 0.001 and the number of epochs is 10,000, the predicted results of the suspended particulate matter concentration obtained using this model can be said to be good because it produces an MSE value of 0.037 with an accuracy rate of 95.526 %.
Kata Kunci: Suspended Particulate Matter, Air Quality, Artificial Neural Network, Backpropagation
Meningkatnya aktivitas individu terutama pada sektor perkotaan merupakan faktor utama penyebab menurunnya kualitas udara. Berpedoman pada Indeks Standar Pencemaran Udara (ISPU) unsur pencemaran udara berupa unsur particulate (PM10), unsur karbondioksida (CO2), unsur sulfur dioksida (SO2), unsur nitrogen dioksida (NO2) dan yang terakhir unsur (O3), namun dari beberapa unsur yang di sebutkan sebelumnya unsur karbonmonoksida (CO) merupakan polutan yang paling berbahaya, namun toksisitasnya paling rendah (Ratnani, 2008). Kini dalam menanggulangi dan pengendalian pencemeran udara instansi terkait seperti BMKG telah melakukan pemantauan atau mengukur tingkat kualitas udara di masing – masing daerah, salah satu sumber polutan yang paling utama adalah Suspended Particulate Matter (SPM) [1].
Suspended Particulate Matter adalah salah satu unsur partikel pencemar udara yang memiliki diameter mulai rentang <1 mikrometer hingga 100 mikrometer [2]. Unsur ini terbentuk ari berbagai sumber, baik secara alami maupun diakibatkan oleh aktivitas manusia, contohnya tranportasi, pembakaran, sektor industri, ekstrasi mineral dan konstruksi. SPM memiliki nilai baku yan telah diatur dalam PP No.41 Tahun 1999 dengan nilai ambang batas sebesar 230 µg/m3. Dimana kadar SPM memiliki dampak yang cukup serius terhadap kesehatan manusia salah satunya ialah penyakit asma.
Solusi antisipasi untuk menanggulangi kualitas udara yang buruk yang dapat berdampak langsung terhadap kesehatan manusia yaitu dengan memprediksi kualitas udara yang akan datang. Algoritma backpropagation (perambatan balik) adalah salah satu jenis algoritma dari jaringan syaraf tiruan dan algoritma ini memiliki kelebihan pada prediksi non-linear, kemudian mempunyai performance yang sangat baik di parallel processing dan kemampuan untuk mentoleransi kesalahan. Hal ini dimungkinkan karena metode Backpropagation merupakan salah satu jenis metode pelatihan jaringan syaraf tiruan dengan supervise. Pada sebuah arsitektur jaringan yang dibangun terdapat pola yang terdiri atas pola masukan dan pola keluaran yang diinginkan. Ketika suatu pola yang diberikan
kepada jaringan, bobot – bobot yang dibangun secara acak sebelumnya diubah untuk memperkecil perbedaan pola keluaran dan pola yang diinginkan. Pada tahap pelatihan ini dapat dilakukan berulang kali sehingga semua pola yang dikeluarkan oleh arsitektur jaringan dapat memenuhi pola yang diinginkan.
Kota Jembrana merupakan kota yang memiliki kawasan yang memiliki lalu lintas yang cukup padat terutama angkutan berat dan angkutan domestik, karena kota Jembrana merupakan jalur penghubung utama dari segala aktivitas antar kota maupun antar pulau. Kota Jembrana juga merupakan kawasan industri yang diarahkan berupa kawasan khusus berbasis sumber daya perikanan dan kegiatan industri lainnya. Tentunya seluruh kegiatan ini menghasilkan polutan yang berbahaya bagi kesehatan, sehingga hal ini tentu harus mendapat perhatian agar dapat meminimalisir kualitas udara yang buruk. Berdasarkan latar permasalahan tersebut, pada penelitian ini menerapkan Algoritma Backpropagation dalam memprediksi kualitas Suspended Particulate Matter (SPM) yang tekandung dalam udara yang diharapkan mampu memberikan informasi sejak dini sehingga dapat mengantisipasi dari pada pencemaran udara yang disebabkan oleh partikel debu.
Pada penelitian ini menggunakan dua data parameter yaitu data konsesntrasi suspended particulate matter, data curah hujan dan data intensitas matahari. Parameter curah hujan dan intensitas matahari ini merupakan faktor meteorologis yang akan membawa pengaruh besar dalam penyebaran dan difusi pencemaran udara yang diemesikan.
Dalam penelitian ini langkah pertama yaitu data yang bersumber dari BMKG Klimatologi Jembrana berupa data suspended particulate matter akan di normalisasi dengan aktivasi sigmoid biner dengan nilai yang yang dihasilkan adalah 0 - 1 setelah itu data tersebut akan masuk ke tahap pelatihan dan pengujian dengan metode backpropagation dimana output yang dihasilkan berupa informasi prediksi konsesntrasi suspended particulate matter pada satu bulan berikutnya dengan parameter yang telah ditentukan pada algoritma backpropagation yaitu nilai epoch, learning rate dan error goals yang kemuadian dipilih akurasi yang terbaik dengan melihat error pada rata-rata keluaran pada tiap pelatihan yang kemudian dipilih untuk melakukan peramalan pada satu bulan berikutnya.
Skenario atau langkah penelitian yang dilakukan pada penelitian ini terdapat beberapa langkah yaitu diawali dengan rumusan masalah, studi literatur, pengumpulan data, pre-processing data, perancangan skema model Arsitektur Jarinan Syaraf Tiruan, processing data, melakukan prediksi terhadap konsentrasi Suspended Particulate Matter, dan terakhir melakukan analisis kesimpulan akurasi yang di hasilkan dalam memprediksi Suspended Particulate Matter dengan Algoritma Backpropagation. adapun gambaran skenario penelitian dapat pada lihat gambar 1:
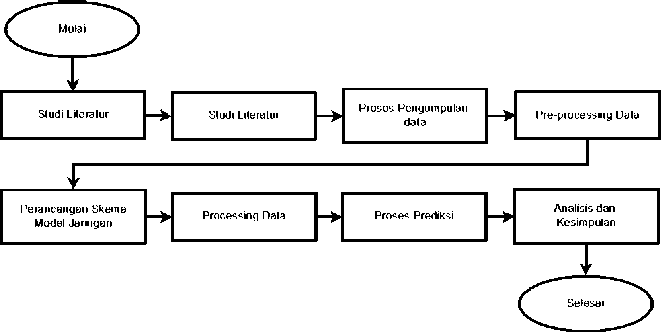
Gambar 1. Diagram Desain Alur Penelitian
Pada penelitian ini bersifat kuantitatif karena data yang digunakan dalam penelitian ini adalah data hasil pengamatan yang dilakukan oleh Badan Meteorologi, Klimatologi, dan Geofisika (BMKG) Stasiun
Klimatologi Jembrana. Adapun variabel yang digunakan ialah variabel parameter arah angin, curah hujan, intensitas matahari sebagai variabel independent dan konsentrasi suspended particulate matter sebagai variabel dependent. Antara kedua variabel ini memiliki keterkaitan yaitu pengaruh dalam penyebaran dan difusi pencemaran udara, dimana variable parameter dapat dilihat pada table 1.
Tabel 1. Variabel Parameter
|
arah_angin (input) |
curah_hujan (input) |
intensitas_matahari (input) |
konsentrasi_spm (target_output) |
|
x1 |
x2 |
x3 |
y |
Data yang di gunakan berupa data rata – rata bulanan dari unsur parameter arah angin, curah hujan, intensitas matahari dan konsentrasi Suspended Particulate Matter dari tahun 2017 hingga tahun 2021, yang berjumlah 60 data dari masing - masing paramter dan dalam bentuk format file .xls*. untuk data parameter arah angin dapat dilihat pada table 2.
Tabel 2. Data Parmeter Arah Angin
|
Data Arah Angin Tahun 2017 | |||||||||||
|
Jan |
Feb |
Mar |
Apr |
Mei |
Jun |
Jul |
Agt |
Sept |
Okt |
Nov |
Des |
|
C |
C |
C |
C |
C |
C |
SE |
SE |
SE |
SE |
C |
C |
Sedangkan untuk data parameter intensitas penyinaran matahari dapat dilihat pada table 3.
Tabel 3. Data Parmeter Intensitas Penyinaran Matahari
|
Data Intensitas Penyinaran Matahari Tahun 2017 *(%) | |||||||||||
|
Jan |
Feb |
Mar |
Apr |
Mei |
Jun |
Jul |
Agt |
Sept |
Okt |
Nov |
Des |
|
49 |
58 |
58 |
69 |
69 |
70 |
60 |
76 |
74 |
69 |
46 |
44 |
Sedangkan untuk data parameter curah hujan dapat dilihat pada table 4.
Tabel 4. Data Parmeter Curah Hujan
|
Data Curah Hujan Tahun 2017 *(mm) | |||||||||||
|
Jan |
Feb |
Mar |
Apr |
Mei |
Jun |
Jul |
Agt |
Sept |
Okt |
Nov |
Des |
|
369 |
209 |
200 |
69 |
230 |
223 |
97 |
61 |
49 |
287 |
557 |
486 |
Sedangkan untuk data parameter Konsentrasi SPM dapat dilihat pada table 5.
Tabel 5. Data Parmeter Konsentrasi SPM
|
Data Konsentrasi SPM Tahun 2017 *(µg/m3) | |||||||||||
|
Jan |
Feb |
Mar |
Apr |
Mei |
Jun |
Jul |
Agt |
Sept |
Okt |
Nov |
Des |
|
65 |
59 |
54 |
63 |
83 |
111 |
132 |
152 |
127 |
64 |
113 |
62 |
Pada penelitian ini ditahap pre-processing, dilakukan data cleaning atau pembersihan data yaitu melakukan perubahan tipe data pada variabel yang bertujuan untuk menghasilkan data yang berkualitas dan dapat mempermudah proses pada tahap korelasi data dan processing data. Pada tahap pre-processing data cleaning ini dilakukan perubahan tipe data pada variabel yakni unsur parameter arah angin yang sebelumnya bertipe data string akan dirubah ke data bertipe integer, ini di karena pada tahap processing algoritma backpropagation diharuskan data masukan berupa data bernilai numerik.
Feature selection adalah sebuah proses yang dengan bertujuan untuk memilih data yang relevan atau data yang memiliki pengaruh besar terhadap nilai prediksi, dengan cara menghapus fitur yang tidak relevan sehingga dapat menugkatkan tingkat efisiensi data dan tingkat akurasi yang dihasilkan. Dalam
penelitian ini feature selection yang digunakan adalah metode filter feature selection yaitu pearson correlation dalam menentukan variabel apa saja yang paling relevan dengan variabel target di penelitian ini. Pearson correlation adalah korelasi yang sederhana yang menyertakan variabel independent dan variabel dependent [3]. Berikut dapat diketahui besaran nilai dari pearson correlation melalui fungsi persamaan dibawah :
„ _ _____n ∑χy-(∑χ) (∑y)______
(1)
rχy = i---------------------------
√[n ∑χ2-(∑χ)2 ][n ∑y 2- (∑y)2
Keteranagan :
-
• rχy = Koefisien r pearson correlation
-
• n = Jumlah sampel
-
• x = Variabel independent
-
• y = Variabel dependent
Koefisien korelasi merupakan ukuran yang digunakan unuk mengetahui derajat hubungan antara variabel – variabel. Nilai koefisien korelasi memiliki rentang nilai antara negatif 1 sampai positif 1, dimana rentang kriteria person corelation dapat dilihat pada table 6.
Tabel 6. Rentang Kriteria Pearson Correlation
|
No. |
Nilai r |
Interpretasi |
|
1 |
0.00 – 0.199 |
Sangat Rendah |
|
2 |
0.20 – 0.399 |
Rendah |
|
3 |
0.40 – 0.599 |
Sedang |
|
4 |
0.60 – 0.799 |
Kuat |
|
5 |
0.80 – 1.00 |
Sangat Kuat |
Pada tahap ini, proses melakukan prediksi menggunakan algoritma backpropagation pada penelitian ini dilakukan pembagian data menjadi dua bagian yaitu data training dan data testing. Data yang digunakna sebanyak 60 data parameter rata – rata bulanan yang nanti nya akan dibagi dua. Persentase pembagian data yaitu sebanyak 80% data training berbanding 20% data testing.
Pemilihan Setelah proses pembagian data di lakukan pada proses pelatihan dan proses pengujian data tidak dapat langsung digunakan akan tetapi data tersebut belum bisa di gunakan langsung, dimana data – data tersebut harus di normalisasi terlebih dahulu agar tidak mengalami kegagalan dalam penelitian ini dalam normalisasi digunakan fungsi aktivasi sigmoid biner dimana nilai yang dihasilkan pada rentang 0-1.
Metode Jaringan Syaraf Tiruan adalah sebuah algoritma komputasi yang memiliki kesamaan dengan jaringan syaraf biologi [4]. Umumnya jaringan syaraf tiruan ini memiliki tiga buah layer yaitu Layer Input, Layer Output dan Layer Hidden. Backpropagation merupakan salah satu model dalam metode jaringan syaraf tiruan. Algoritma ini terdapat eror yang dihasilkan dari perambatan maju menggunakan fungsi turunan aktivasi pada nilai bobotnya, dimana akan mengaktifkan neuron neuron tersebut dan terdapat fase mundur untuk mendapatkan nilai bobot dari erorr output. Lalu erorr output ini digunakan untuk mendapatkan nilai bobot kearah mundur, ini berfungsi untuk mengecilkan kemungkinan terjadinya erorr [5].
Berikut ini merupakan langkah - langkah dari pelatihan Algoritma Backpropagation:
Langkah 0 : tetapkan nilai awal pada bobot dengan nilai acak yang cukup kecil.
Tetapkan : nilai max Epoch, error target, dan Learning Rate.
: Epoch = 0, MSE = 1
Tahap 1 : lakukan tahap - tahap berikut jika berada pada kondisi
Epoch < Maksimum Epoch dan MSE > Target Error:
Epoch = Epoch = Epoch+ 1
Tahap 2 : melakukan pembelajaran pada setiap pasangan elemen, aksi yang dilakuakn
sebagai berikut:
Fase 1 : Feed Forward
Tahap 3 : Pada setiap unit inputan xi, dengan (I = 1,2,3) akan meneruskan sinyal ini pada setiap
unit tersembunyi.
Tahap 4 : Setiap nilai hasil lapisan tersembunyi akan ditambahkan nilai input bobot:
Untuk mengukur nilai sinyal output digunakan fungsi aktivasi:
Lalu akan mengirimkan sinyal tersebut ke setiap lapisan output.
Tahap 5 : Lalu akan menjumlahkan lapisan input pada setiap node output Yk dengan
(k=1,2..m) :
Untuk mengukur nilai sinyal output digunakan fungsi aktivasi:
Dan akan mengirimkan sinyal tersebut ke setiap unit lapisan output.
Fase 2 : Backpropagation
Tahap 6 : Akan mengukur eror yang berasal dari pola fase pelatihan yang telah diterima dari
unit output yk dengan k = (1,2,3):
<P2jk
β2k = S k
Lalu mengukur perubahan bobot dalam memperbaiki nilai:
Dan mengukur kembali perubahan bias dalam memperbaiki nilai:
Tahap 7 : Pada bagian lapisan tersembunyi zj dengan j = (1,2,3) akan dijumlahkan dengan
selisih input atau (delta) dengan lapisan atas:
Mengalikan keluaran nilai ini dengan fungsi aktivasi yaitu turunannya untuk mengukur informasi error:
βii = SV
lalu menghitung perubahan nilai bobot yang untuk memperbaiki nilai:
Dan menghitung kembali perubahan nilai bias untuk memperbaiki nilai:
Tahap 8 : Akan memperbaiki nilai bobot (j=0,1,2…p) pada setiap node output Yk (k=1,2,…,m)):
Wjk (baru) = Wjk (lama) + ∆Wjk(13)
b2 k (baru) = b2 k (lama) + ∆b2 k
melakukan memperbarui nilai bias dan bobot (i=0,1,2,…,n) untuk setiap node tersembunyi Zj (j=1,2,-.,p)) :
Vij (baru) = V-j (lama) + ∆Vj(14)
blj (baru) = bl j (lama) + ∆ blj
Tahap 9 : Terakhiir, hitung nilai Mean Squared Error (MSE)
-
3. Hasil dan Pembahasan
-
3.1. Pengujian dan Evaluasi
-
Pada tahap training dan testing dilakukan berdasarkan langkah – langkah Algoritma Backpropagation yang telah dijelaskan sebelumnya dari membangun skema model arsitektur jaringan hingga menetapkan nilai parameter yang digunakan pada penelitian ini yaitu nilai learning rate sebesar 0.05, target error sebesar 0.01 dan jumlah epoch sebesar 10.000 iterasi. Pertama dilakukan pengujian
terhadap skema model arsitektur jaringan yang ke-1 yaitu pada input layer menggunakan 2 neuron karena terdapat 2 variabel x yaitu unsur variabel arah angin dan intensitas matahari, kemudian pada hidden layer menggunakan 10 neuron dan pada output layer terdapat 1 neuron yang mana merupakan unsur konsentrasi suspended particulate matter yang sebagai variabel y, selanjutnya dilakukan pengujian pada skema model arsitektur jaringan ke-2 menggunakan 2 neuron input layer dengan 15 neuron hidden layer dan 1 neuron output layer, kemudian yang terakhir di lakukan pengujian terhadap pada skema model arsitektur jaringan ke-3 menggunakan 2 neuron input layer dengan 20 neuron hidden layer dan 1 neuron output layer. Output hasil pengujian berupa perbandingan data prediksi terhadap data aktual yang menghasilkan nilai persentase error (Mean Square Error) dan persentase akurasi.
Pada skema model ke-1 ini dilakukan proses training dan testing dengan menggunakan beberapa kombinasi nilai parameter yang telah ditetapkan sebelumnya. Pada proses training dengan skema model ini memperoleh nilai bobot v dan w baru dengan MSE training sebesar 0.218. dimana bobot (v) terlatih model ke-1 pada proses testing dapat dilihat pada table 7.
Tabel 7. Bobot v terlatih model ke-1
|
i / j |
1 |
2 |
3 |
4 |
5 |
|
1 |
1.1 |
0.71 |
1.62 |
0.07 |
3.21 |
|
2 |
0.38 |
0.6 |
0.04 |
0.93 |
0.5 |
|
3 |
0.3 |
0.56 |
0.48 |
0.24 |
0.48 |
|
4 |
1.1 |
0.71 |
1.62 |
0.07 |
3.21 |
|
i / j |
6 |
7 |
8 |
9 |
10 |
|
1 |
-6.8 |
2.29 |
0.58 |
0.18 |
2.6 |
|
2 |
0.61 |
0.13 |
0.07 |
0.96 |
0.84 |
|
3 |
0.89 |
0.07 |
0.6 |
0.34 |
0.39 |
|
4 |
-6.8 |
2.29 |
0.58 |
0.18 |
2.6 |
Sedangkan untuk bobot (w) terlatih model ke-1 dapat dilihat pada table 8.
Tabel 8. Bobot w terlatih model ke-1
|
j / k |
1 |
|
1 |
-3.25 |
|
2 |
0.36 |
|
3 |
0.61 |
|
4 |
-1.63 |
|
5 |
4.58 |
|
6 |
-0.31 |
|
7 |
0.82 |
|
8 |
-1.47 |
|
9 |
-1.32 |
|
10 |
2.81 |
|
11 |
1.45 |
Dalam menyajikan data hasil prediksi terhadap data aktual yang mana pada proses testing dengan skema model ke-1 ini memperoleh nilai MSE sebesar 0.050 dan rata – rata akurasi sebesar 93.908% untuk hasil pengujian model ke-1 dapat dilihat pada table 9.
Tabel 9. Hasil Pengujian Model ke-1
|
No. |
Data Hasil Prediksi |
Output Sebenarnya |
Error |
Akurasi |
|
1 |
93.0 |
96 |
3.0 |
96.88 |
|
2 |
94.0 |
90 |
4.0 |
95.74 |
|
3 |
93.0 |
94 |
1.0 |
98.94 |
|
4 |
95.0 |
90 |
5.0 |
94.74 |
|
5 |
73.0 |
80 |
7.0 |
91.25 |
|
6 |
71.0 |
67 |
4.0 |
94.37 |
|
7 |
71.0 |
70 |
1.0 |
98.59 |
|
8 |
68.0 |
76 |
8.0 |
89.47 |
|
9 |
68.0 |
62 |
6.0 |
91.18 |
|
10 |
68.0 |
80 |
12.0 |
85.0 |
|
11 |
93.0 |
89 |
4.0 |
95.7 |
|
12 |
94.0 |
100 |
6.0 |
94.0 |
|
13 |
94.0 |
102 |
8.0 |
92.16 |
|
14 |
92.0 |
108 |
16.0 |
85.19 |
|
15 |
71.0 |
80 |
9.0 |
88.75 |
|
16 |
71.0 |
76 |
5.0 |
93.42 |
|
17 |
71.0 |
71 |
0.0 |
100.0 |
|
18 |
70.0 |
69 |
1.0 |
98.57 |
|
19 |
70.0 |
70 |
0.0 |
100.0 |
|
20 |
69.0 |
65 |
4.0 |
94.2 |
|
Rata – |
Rata Akurasi |
93.908 % |
Selanjutnya skema model ke-2 ini dilakukan proses training dan testing dengan menggunakan beberapa kombinasi nilai parameter yang telah ditetapkan sebelumnya seperti pada model ke-1. Pada proses training dengan skema model ini memperoleh nilai bobot v dan w baru dengan MSE training sebesar 0.222. untuk bobot (v) terlatih model ke 2 dapat dilihat pada table 10.
Tabel 10. Bobot v terlatih model ke-2
|
i / j |
1 |
2 |
3 |
4 |
5 |
|
1 |
2.33 |
0.24 |
1.86 |
2.79 |
0.74 |
|
2 |
0.99 |
0.59 |
0.66 |
0.39 |
0.45 |
|
3 |
0.08 |
0.42 |
0.4 |
0.85 |
0.18 |
|
4 |
2.33 |
0.24 |
1.86 |
2.79 |
0.74 |
|
i / j |
6 |
7 |
8 |
9 |
10 |
|
1 |
2.37 |
2.27 |
1.18 |
3.1 |
-1.35 |
|
2 |
0.71 |
0.51 |
0.8 |
0.61 |
0.29 |
|
3 |
0.11 |
0.81 |
0.63 |
0.14 |
0.98 |
|
4 |
2.37 |
2.27 |
1.18 |
3.1 |
-1.35 |
|
i / j |
11 |
12 |
13 |
14 |
15 |
|
1 |
1.52 |
-5.11 |
2.04 |
-1.08 |
1 |
|
2 |
0.4 |
0.44 |
0.54 |
0.26 |
0.52 |
|
3 |
0.62 |
0.59 |
0.91 |
0.61 |
0.12 |
|
4 |
1.52 |
-5.11 |
2.04 |
-1.08 |
1 |
Sedangkan untukb obot (w) terlatih model ke-2 dapat dilihat pada table 11.
Tabel 11. Bobot w terlatih model ke-2
|
j / k |
1 |
|
1 |
-7.37 |
|
2 |
-0.2 |
|
3 |
1.42 |
|
4 |
3.51 |
|
5 |
-2.09 |
|
6 |
1.95 |
|
7 |
1.77 |
|
8 |
-0.73 |
|
9 |
3.78 |
|
10 |
-1.97 |
|
11 |
0.62 |
|
12 |
-0.35 |
|
13 |
1.96 |
|
14 |
-0.9 |
|
15 |
0.39 |
|
16 |
2.63 |
Dalam menyajikan data hasil prediksi terhadap data aktual yang mana pada proses testing dengan skema model ke-2 memperoleh nilai MSE sebesar 0.054 dan rata – rata akurasi sebesar 93.146%. untuk hasil pengujian model ke-2 dapat dilihat pada table 12.
Tabel 12. Hasil Pengujian Model Ke-2
|
No. |
Data Hasil Prediksi |
Output Sebenarnya |
Error |
Akurasi |
|
1 |
88.0 |
96 |
8.0 |
91.67 |
|
2 |
91.0 |
90 |
1.0 |
98.9 |
|
3 |
87.0 |
94 |
7.0 |
92.55 |
|
4 |
91.0 |
90 |
1.0 |
98.9 |
|
5 |
76.0 |
80 |
3.0 |
94.03 |
|
6 |
65.0 |
67 |
6.0 |
91.78 |
|
7 |
73.0 |
70 |
3.0 |
95.89 |
|
8 |
66.0 |
76 |
10.0 |
86.84 |
|
9 |
66.0 |
62 |
4.0 |
93.94 |
|
10 |
66.0 |
80 |
14.0 |
82.5 |
|
11 |
88.0 |
89 |
1.0 |
98.88 |
|
12 |
89.0 |
100 |
11.0 |
89.0 |
|
13 |
90.0 |
102 |
12.0 |
88.24 |
|
14 |
85.0 |
108 |
23.0 |
78.7 |
|
15 |
73.0 |
80 |
7.0 |
91.25 |
|
16 |
73.0 |
76 |
3.0 |
96.05 |
|
17 |
73.0 |
71 |
2.0 |
97.26 |
|
18 |
70.0 |
69 |
1.0 |
98.57 |
|
19 |
70.0 |
70 |
0.0 |
100.0 |
|
20 |
67.0 |
65 |
2.0 |
97.01 |
|
Rata – Rata Akurasi |
93.146% | |||
Selanjutnya skema model ke-3 dilakukan proses training dan testing dengan menggunakan kombinasi
nilai parameter yang sama seperti model sebelumnya. Pada proses training dengan skema model ini memperoleh nilai bobot v dan w baru dengan MSE training sebesar 0.221. Berikut Tabel 11 menyajikan kumpulan bobot v terlatih dan Tabel 12 menyajikan kumpulan bobot w terlatih. Selanjutnya bobot – bobot terlatih ini akan digunakan pada proses testing. untuk bobot (v) terlatih model ke-3 dapat dilihat pada table 13.
Tabel 13. Bobot v terlatih model ke-3
|
i / j |
1 |
2 |
3 |
4 |
5 |
|
1 |
1.11 |
-6.39 |
-0.86 |
-0.66 |
-17.52 |
|
2 |
0.94 |
0.99 |
0.42 |
0.48 |
0.15 |
|
3 |
0.46 |
0.34 |
0.39 |
0.67 |
0.05 |
|
4 |
0.43 |
0.85 |
0.71 |
0.99 |
0.27 |
|
i / j |
6 |
7 |
8 |
9 |
10 |
|
1 |
-0.69 |
-0.72 |
-13.9 |
-0.83 |
2.06 |
|
2 |
0.5 |
0.06 |
0.64 |
0.8 |
0.21 |
|
3 |
0.79 |
0.8 |
0.81 |
0.37 |
0.43 |
|
4 |
0.67 |
0.69 |
0.07 |
0.79 |
0.22 |
|
i / j |
11 |
12 |
13 |
14 |
15 |
|
1 |
-22.04 |
-7.09 |
-5.19 |
-20.47 |
0.7 |
|
2 |
0.88 |
0.65 |
0.12 |
0.3 |
0.58 |
|
3 |
0.92 |
0.82 |
0.19 |
0.79 |
0.97 |
|
4 |
0.2 |
0.69 |
0.73 |
0.05 |
0.94 |
|
i / j |
16 |
17 |
18 |
19 |
20 |
|
1 |
-7.54 |
-6.37 |
-21.25 |
-0.95 |
0.33 |
|
2 |
0.22 |
0.2 |
0.67 |
0.97 |
0.14 |
|
3 |
0.66 |
0.07 |
0.73 |
0.04 |
0.88 |
|
4 |
0.78 |
0.43 |
0.23 |
0.51 |
0.49 |
Sedangkan untuk bobot (w) terlatih model ke-3 dapat dilihat pada table 14.
Tabel 14. Bobot w terlatih model ke-3
|
j / k |
1 |
|
1 |
-7.53 |
|
2 |
16.32 |
|
3 |
1.92 |
|
4 |
-5.29 |
|
5 |
-4.06 |
|
6 |
0.31 |
|
7 |
6.1 |
|
8 |
-2.97 |
|
9 |
7 |
|
10 |
-7.69 |
|
11 |
-4.52 |
|
12 |
2.49 |
|
13 |
1.37 |
|
14 |
-3.17 |
|
15 |
3.82 |
|
16 |
0.31 |
|
17 |
-2.11 |
|
18 |
0.61 |
|
19 |
2.13 |
|
20 |
9.91 |
|
21 |
-1.93 |
Dalam menyajikan data hasil prediksi terhadap data aktual yang mana pada proses testing dengan skema model ke-3 ini memperoleh nilai MSE sebesar 0.052 dan rata – rata akurasi sebesar 93.418%. untuk hasil pengujian model ke-3 dapat dilihat pada table 15.
Tabel 15. Hasil Pengujian Model Ke-3
|
No |
Data Hasil Prediksi |
Data Sebenarnya |
Error |
Akurasi |
|
1 |
104.0 |
96 |
4.0 |
96.15 |
|
2 |
106.0 |
90 |
1.0 |
99.06 |
|
3 |
111.0 |
94 |
0.0 |
100.0 |
|
4 |
102.0 |
90 |
19.0 |
81.37 |
|
5 |
63.0 |
80 |
0.0 |
100.0 |
|
6 |
64.0 |
67 |
1.0 |
98.44 |
|
7 |
64.0 |
70 |
5.0 |
92.19 |
|
8 |
66.0 |
76 |
1.0 |
98.48 |
|
9 |
66.0 |
62 |
4.0 |
93.94 |
|
10 |
65.0 |
80 |
1.0 |
98.46 |
|
11 |
99.0 |
89 |
2.0 |
97.98 |
|
12 |
107.0 |
100 |
5.0 |
95.33 |
|
13 |
105.0 |
102 |
1.0 |
99.05 |
|
14 |
112.0 |
108 |
9.0 |
91.96 |
|
15 |
64.0 |
80 |
1.0 |
98.46 |
|
16 |
64.0 |
76 |
1.0 |
98.44 |
|
17 |
66.0 |
71 |
3.0 |
95.45 |
|
18 |
66.0 |
69 |
8.0 |
87.88 |
|
19 |
66.0 |
70 |
7.0 |
89.39 |
|
20 |
66.0 |
65 |
1.0 |
98.48 |
|
Rata – Rata Akurasi |
93.418% | |||
Dalam menyajikan hasil pengujian dari setiap model jaringan yang dibuat maka dapat disimpulkan bahwa hasil dari skema model jaringan ke-1 lebih optimal dari hasil skema model jaringan lainnya dapat dilanjutkan untuk melakukan tahap prediksi dengan menggunakan skema model arsitektur jaringan ke-1. untuk hasil pengujian semua model dapat dilihat pada table 16.
Tabel 16. Hasil Pengujian Semua Model
|
Model JST 1 |
Model JST 2 |
Model JST 3 | |
|
Input Layer |
2 |
2 |
2 |
|
Hidden Layer |
10 |
15 |
20 |
|
Output Layer |
1 |
1 |
1 |
|
Learning Rate |
0.05 |
0.05 |
0.05 |
|
Target Error |
0.01 |
0.01 |
0.01 |
|
Epoch |
10.000 |
10.000 |
10.000 |
|
MSE Pelatihan |
0.218 |
0.222 |
0.221 |
|
MSE Pengujian |
0.050 |
0.054 |
0.052 |
|
Rata – Rata Akurasi |
93.908% |
93.146% |
93.418% |
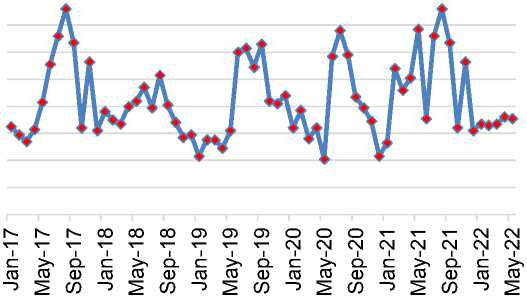
Pada tahap prediksi ini skema model jaringan yang akan digunakan untuk melakukan prediksi adalah model jaringan yang hasil pengujiannya paling baik, dimana pada penelitian ini skema model jaringan pertama mendapatkan hasil pengujian yang paling baik dengan MSE pengujian 0.050 dengan tingkat rata – rata akurasi sebesar 93.908%. Pada penelitian ini terakhir yaitu data ke – 60 yaitu data rata -rata pada bulan Desember pada tahun 2021, dan proses prediksi ini akan memprediksi data ke – 61 sampai seterusnya dan pada kasus ini di dapat data untuk 5 bulan kedepannya yaitu data ke -61, data ke -62, data ke -63, data ke -63, dan data ke -65. untuk grafik konsentrasi suspended particulate matter dapat dilihat pada gambar 2.
Konsentrasi_SPM
160
140
120
100
80
60
40
20
0
Gambar 2. Grafik Konsentrasi Suspended Particulate Matter
Pada gambar 2 memperlihatkan visualisasi dari data tahun 2017 hingga tahun 2022 yang mana pada bulan januari hingga bulan mei 2022 merupakan data hasil dari prediksi dengan menggunakan skema model arsitektur ke-1.
Akurasi yang di hasilkan dalam memprediksi kualitas udara suspended particulate matter menggunakan Algoritma Backpropagation dengan menggunakan 3 skema model jaringan yaitu cukup baik. Akurasi yang di dapat pada skema model pertama yaitu sebesar 93.908 %, selanjutnya pada skema model kedua yaitu sebesar 93.146 % dan yang terakhir pada skema model ketiga yaitu sebesar 93.418 %.
Implementasi arsitektur jaringan syaraf tiruan backpropagation dalam memprediksi konsentrasi suspended particulate matter dengan beberapa skema model jaringan yang bervariasi dan menambahkan hidden layer cukup berpengaruh terhadap hasil prediksi. Dimana pada penelitian ini prediksi konsentrasi suspended particulate matter dengan skema model jaringan pertama yaitu 2 input layer, 10 hidden layer, 1 output layer mendapatkan MSE pelatihan sebesar 0.218 dan MSE pengujian sebesar 0.050 dengan akurasi 93.908 %, selanjutnya skema model jaringan kedua yaitu 2 input layer, 15 hidden layer, 1 output layer mendapatkan MSE pelatihan sebesar 0.222 dan MSE pengujian sebesar 0.054 dengan akurasi 93.146 % dan yang terakhir skema model jaringan ketiga yaitu 2 input layer, 20 hidden layer, 1 output layer mendapatkan MSE pelatihan sebesar 0.221 dan MSE pengujian sebesar 0.052 dengan akurasi 93.418 %, dengan demikian jumlah hidden layer pada skema model pertama yaitu 10 hidden layer yang digunakan dalam penelitian ini menjadi solusi skema model jaringan yang paling optimum.
References
-
[1] Nuryanto, H. M. Gultom, and S. Melinda, “Pengaruh Angin Permukaan dan Kelembapan
Udara Terhadap Suspended Particulate Matter (SPM) di Sorong Periode Januari - Juli 2019,” Buletin. GAW Bariri (BGW), vol. 2, no. 2, pp. 71–78, 2021.
-
[2] E. Nurmala, Budiyono, dan Suhartono, “HUBUNGAN KONSENTRASI SUSPENDED
PARTICULATE MATTER (SPM) UDARA AMBIEN DAN KONDISI CUACA DENGAN ANGKA KEJADIAN ASMA DI KECAMATAN SEMARANG BARAT TAHUN 2015-2017", Jurnal. Kesehatatan Masyarakat, vol. 6, no. 6, 2018.
-
[3] E. P. Cynthia dan E. Ismanto, “Jaringan Syaraf Tiruan Algoritma Backpropagation dalam
Memprediksi ketersediaan Komoditi Pangan Provinsi Palu,” Seminar Nasional Teknolologi Informasi Komunikasi dan Industri (SNTIKI) 9, Fakultas Sains dan Teknologi, UIN Sultan Syarif Kasim Riau, 2017.
-
[4] F. Ayu, "Implementasi Jaringan Saraf Tiruan Untuk Menentukan Kelayakan Proposal Tugas
Akhir", IT Journal Research and Development, vol. 3, no. 2, 2019.
-
[5] Kiki dan S. Kusumadewi, "Jaringan Saraf Tiruan Dengan Metode Backpropagation Untuk
Mendeteksi Gangguan Psikologi", Media Informatika, vol. 2, no. 2, 2004.
866
Discussion and feedback