Peramalan Jumlah Kecelakaan Lalu Lintas Menggunakan Metode Support Vector Regression
on
JURNAL ILMIAH MERPATI VOL. 8, NO. 2 AUGUST 2020
p-ISSN: 2252-3006
e-ISSN: 2685-2411
Peramalan Jumlah Kecelakaan Lalu Lintas Menggunakan Metode Support Vector Regression
Ni Putu Ratindia Apriyanti, I Ketut Gede Darma Putra, I Made Suwija Putra Program Studi Teknologi Informasi, Fakultas Teknik, Universitas Udayana Bukit Jimbaran, Bali, Indonesia, telp. (0361) 701806
e-mail: puturatindia@gmail.com, ikgdarmaputra@unud.ac.id, putrasuwija@unud.ac.id
Abstrak
Kecelakaan lalu lintas merupakan salah satu peristiwa yang sering terjadi dijalan yang dapat menyebabkan adanya korban jiwa. Pentingnya penelitian bertujuan untuk meramalkan kasus Kecelakaan Lalu Lintas di Provinsi Bali. Peramalan dilakukan dengan menerapkan teknik penambangan data atau yang sering disebut dengan data mining. Penambangan data (data mining) merupakan sekumpulan proses yang digunakan untuk mencari nilai yang tidak bisa didapatkan secara otomatisl. Peramalan dalam penelitian ini menggunakan Metode Support Vector Regression dengan 2 kernel yaitu Kernel Polynomial dan Kernel RBF. Data yang digunakan dari Tahun 2006 sampai dengan Tahun 2018. Data tersebut dikelompokkan menjadi data training dengan jumlah (9 data) dan data testing dengan jumlah (4 data). Hasil peramalan yang didapatkan dibandingkan dengan nilai persentase MAPE yang dihasilkan. Hasil peramalan menggunakan kernel Polynomial menghasilkan nilai Persentase MAPE sebesar 7,95% dimana hasil peramalan artinya “Sangat Bagus”. Hasil peramalan menggunakan kernel RBF memiliki persentase MAPE yang lebih besar yaitu 13.35% yang artinya hasil peramalan “Bagus”. Penggunaan dari dua kernel tersebut menyatakan bahwa dalam Metode Support Vector Regression untuk meramalkan kasus kecelakaan lalu lintas lebih tepat menggunakan Kernel Polynomial. Semakin kecil nilai persentase MAPE yang dihasilkan maka semakin bagus juga hasil peramalan yang didapatkan.
Kata kunci: Kecelakaan Lalu Lintas, Data Mining, Peramalan, Support Vector Regression
Abstract
Traffic accidents are one of the events that often occur on the road that can cause fatalities. The importance of research aims to predict the case of Traffic Accidents in the Province of Bali. Forecasting is done by applying data mining techniques or often called data mining. Data mining is a set of processes that are used to find values that cannot be obtained automatically. Forecasting in this study uses the Support Vector Regression Method with 2 kernels, namely the Polynomial Kernel and the RBF Kernel. The data is used from 2006 to 2018. The data is grouped into training data with the number (9 data) and testing data with the number (4 data). Forecasting results obtained compared with the percentage value of the MAPE produced. Forecasting results using the Polynomial kernel produce a MAPE Percentage value of 7.95% where the forecasting results mean "Very Good". Forecasting results using the RBF kernel have a greater percentage of MAPE which is 13.35% which means the forecast results are "Good". The use of the two kernels states that in the Support Vector Regression Method to predict traffic accident cases it is more appropriate to use the Polynomial Kernel. The smaller the percentage value of MAPE produced, the better the forecasting results obtained.
Keywords : Traffict Accidents, Data Mining, Forecasting, Support Vector Regression
Kecelakaan lalu lintas merupakan salah satu kejdian/peristiwa yang sering terjadi dijalanan. Menurut peraturan yang dikeluarkan oleh pemerintah yaitu PP Nomor: 43 Tahun 1993 Pasal 93 mengenai Prasarana dan Lalu Lintas Jalan menerangkan bahwa kecelakaan merupakan suatu peristiwa dijalan yang tidak disangka-sangka dan tidak sengaja melibatkan kendaraan dengan atau tanpa pemakai jalan lainnya, mengakibatkan korban manusia atau rugi harta benda. Organisasi Kesehatan Dunia (WHO) memperkirakan bahwa 1,17 juta kematian
terjadi setiap tahun di seluruh dunia karena kecelakaan lalu lintas [1]. Indonesia, Provinsi Bali merupakan salah satu provinsi yang memiliki jumlah kecelakaan yang tinggi [2]. Data dan informasi dari Badan Pusat Statistik (BPS) Provinsi Bali, menunjukkan bahwa jumlah kecelakaan dari Tahun 1996 sampai dengan Tahun 2018 mengalami peningkatan, dimana dari Tahun 1996 sampai dengan Tahun 2005 jumlah kecelakaan masih berada dibawah angka 1000, sedangkan dari Tahun 2006 sampai dengan Tahun 2018 angka kecelakaan berada diatas 1000 kasus kecelakaan [3]. Banyaknya jumlah kecelakaan yang terjadi, menimbulkan adanya permasalahan bagaimana cara memberikan informasi kepada pemerintah dan pihak terkait mengenai jumlah kecelakaan yang terjadi pada tahun berikutnya, sehingga pihak pemerintah dan pihak yang terkait dapat lebih serius dalam mengatasi kasus kecelakaan di tahun-tahun berikutnya. Salah satu cara yang dapat dilakukan adalah dengan teknik peramalan dengan Metode Support Vector Regression (SVR).
Penelitian sebelumnya yang pernah menggunakan Metode SVR adalah penelitian yang dilakukan untuk meramalkan penjualan roti [4]. Data roti yang diramalkan adalah roti dengan varian rasa manis, tawar dan cake dengan mengimplementasikan metode data time series. Penerapan Metode SVR yang dilakukan dalam pebelitian ini, didapatkan hasil nilai evaluasi RMSE (Root Mean Square Error) untuk roti varian rasa manis sebesar 0,00176, roti varian rasa tawar sebesar 0,00010 dan cake sebesar 0,00019 [4]. Metode SVR juga digunakan untuk meramalkan kondisi curah hujan di daerah Pujon, Malang. Kasus peramalan ini, menggunakan metode SVR yang dioptimasi dengan Algoritma Improved-Particle Swarm Optimization. Tujuan dilakukannya optimasi SVR dengan Algoritma Improved-Particle Swarm Optimization (IPSO) adalah untuk mencari nilai parameter SVR yang paling baik (optimal). Parameter SVR yang dioptimasi ada lima parameter yang terdiri dari cLR (konstanta learning rate), C (kompleksitas), λ (koefisien Hessian), ε (error rate) dan σ (koefisien kernel). Hasil peramalan curah hujan pada bulan Januari pada sepuluh hari pertama pada Tahun 2007-2015 menggunakan Algoritma IPSO-SVR menghasilkan nilai RMSE sebesar 25.839085. Hasil peramalan curah hujan di daerah Pujon, Malang menunjukkan bahwa Metode SVR yang dioptimasikan dengan Algoritma IPSO lebih baik dibandingkan dengan dengan Metode SVR yang belum dioptimasi [5]. Penelitian lainnya yang menggunakan Metode SVR adalah peramalan/prediksi nilai tukar dolar Amerika Serikat terhadap rupiah. Data nilai tukar dolar terhadap rupiah terdiri dari 445 data yang dibagi menjadi dua bagian, yaitu data latih (training) daa data uji (testing). Data latih (training) sebanyak 415 data dan data uji (testing sebanyak 30 data. Hasil penelitian menyatakan bahwa parameter SVR yang diestimasi menghasilkan nilai prediksi yang telah disesuaikan dengan data training yang ada. Data training tersebut memiliki nilai nilai R2 0,9223 dan RMSE bernilai 54,3156 [6]. Penelitian selanjutnya yaitu peramalan untuk menentukan harga saham. Penelitian ini menggunakan Metode Support Vector Regression yang juga diimplentasikan dengan menggunakan Algoritma Genetika. Algoritma Genetika digunakan untuk menentukan parameter Metode SVR yang tepat sehingga dapat menghasilkan hasil peramalan yang bagus dengan nilai kesalahan yang sedikit. Hasil pengujian Metode SVR yang dioptimasi dengan Algoritma Genetika, didapatkan nilai kesalahan/MAPE sebesar 0,165% dibandingkan dengan hanya menggunakan Metode SVR tanpa dioptimasi menghasilkan nilai kesalahan/MAPE yang lebih besar yaitu 1,612%. Adapun parameter terbaik yang digunakan yaitu ukuran populasi sebanyak 50, banyaknya generasi 200, tingkat crossover 0;4, tingkat mutasi 0;6, rentang nilai sigma 0,5-1, rentang nilai epsilon 10-7-10-3 rentang nillai C 0,01-5 dan rentang nilai gamma 10-5-10-3 [7].
Penelitian yang dilakukan menggunakan Metode Support Vector Regression, berbeda dari penelitian yang sudah ada terkait peramalan kasus jumlah kecelakaan lalu lintas yang terjadi. Peramalan dengan menggunakan Metode SVR ini diharapkan mampu memberikan hasil terbaik, sehingga informasi dari hasil peramalan dapat dijadikan tinjauan untuk mengambil tindakan dalam mencegah jumlah kecelakaan yang terjadi oleh pihak pemerintah dan instansi terkait.
Metodologi penelitian menjelaskan mengenai tahapan penelitian yang menggambarkan urutan logis untuk mendapatkan output dari penelitian. Penelitian mengenai Peramalan Jumlah Kecelakaan Lalu Lintas di Provinsi Bali Menggunakan Metode Support Vector Regression terdiri dari 3 tahap yang terdiri dari normalisasi data, peramalan dan denormalisasi data yang dapat dilihat pada Gambar 1.
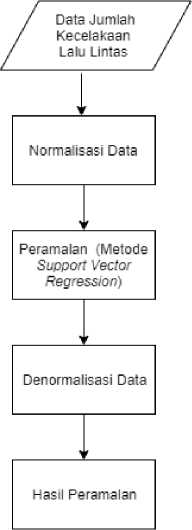
Gambar 1. Gambaran Umum Penelitian
Data yang digunakan pada penelitian adalah data yang bersumber dari Badan Pusat Statistik (BPS) Provinsi Bali. Data yang diperoleh adalah data mengenai jumlah kecelakaan lalu lintas yang terjadi di Provinsi Bali dari Tahun 2006 sampai dengan Tahun 2018. Data yang dipergunakan adalah data dalam hitungan tahunan, jadi data yang diperoleh sebanyak 13 data.
Normalisasi (normalization) merupakan proses penskalaan, pemetaan data atau juga bisa dikatakan sebagai tahap pra-pemrosesan data. Normalisasi dilakukan dengan tujuan untuk menghilakangkan data yang sama, mengurangi kompleksitas dan mempermudah dalam proses pemodifikasian data. Normalisasi data input harus menyesuaikan nilai range data dengan fungsi aktivasi dan dalam sistem ELM (Extreme Learning Machine), dimana hal tersebut dapat diartikan bahwa nilai kuadrat input harus berada dalam range 0 sampai dengan 1. Persamaan yang dapat digunakan untuk proses normalisasi dapat dilihat pada Persamaan 1.
y =
x — min
max — min
(0,8) + 0,1
(1)
y adalah nilai hasil dari proses normalisasi, min merupakan nilai paling kecil yang pada data set dan max merupakan nilai nilai paling besar yang ada pada pada data set [8]. Contoh proses normalisasi dapat dilihat pada Tabel 1.
Tabel 1. Hasil dari Proses Normalisasi Jumlah Kecelakaan Lalu Lintas
|
Tahun |
Jumlah |
y |
|
2006 |
1419 |
0 |
|
2007 |
1441 |
0,013888889 |
|
2008 |
1469 |
0,031565657 |
|
2009 |
1580 |
0,101641414 |
|
2010 |
1583 |
0,103535354 |
|
2011 |
1737 |
0,200757576 |
|
2012 |
1793 |
0,236111111 |
|
2013 |
1824 |
0,255681818 |
|
2014 |
1827 |
0,257575758 |
|
Tahun |
Jumlah |
y |
|
2015 |
2166 |
0,471590909 |
|
2016 |
2441 |
0,64520202 |
|
2017 |
3003 |
1 |
|
2018 |
2730 |
0,827651515 |
Tabel 1 merupakan hasil dari proses normalisasi terhadap data jumlah kecelakaan lalu lintas. Nilai maxsimum atau jumlah paling banyak terjadinya kecelakaan lalu lintas adalah pada tahun 2017 yaitu sebanyak 3003 kasus, sedangkan nilai minimum atau jumlah paling sedikit terjadinya kecelakaan lalu lintas adalah pada Tahun 2006 yaitu sebanyak 1419 kasus kecelakaan. Y merupakan hasil dari proses normalisasi data set dengan menerapkan persamaan 1 sehingga didapatkan hasil seperti pada Tabel 1.
Peramalan jumlah kecelakaan lalu lintas di Provinsi Bali dibuat menggunakan aplikasi Machine Learning Weka 3.9.3. Data kecelakaan lalu lintas yang digunakan berdasarkan tahun dengan jumlah 13 data yaitu dari Tahun 2006-2018. Data dikelompokkan menjadi dua bagian, yaitu data latih (training) dan data uji (testing). Data latih (training dari Tahun 2006-2014 dan data uji (testing) dari Tahun 2015-2018.
Peramalan menggunakan Metode Support Vector Regression dengan menggunakan dua kernel yaitu Kernel Polynomial dan Kernel RBF. Nilai akurasi paling bagus dari kedua kernel tersebut dilihat dari persentase MAPE (Mean Absolute Percentage Error) yang dihasilkan.
Kernel polynomial merupakan kernel yang biasa digunakan dalam SVM (Support Vector Machine). Kernel polynomial sangat banyak digunakan dalam kasus pemetaan vektor untuk kasus non-linear [6]. Polynomial memiliki parameter yang terdiri dari Cost and Degree (d) dan proses pengoptimalannya menggunakan cara trial and error. Persamaan Kernel Polynomial dapat dilihat pada Persamaan 2.
K (x.z) = (γ(x,z) + C0)d (2)
γ merupakan parameter kemiringan, c0 merupakan trade-off antara suku-suku minor dari polynominal yang dihasilkan, d merupakan derajat polynomial, dan x,z merupakan pola data [9].
-
2.3.2 Kernel RBF (Radial Basis Fuction)
Kernel RBF juga merupakan salah satu kernel yang sering digunakan dalam SVM (Support Vector Machine). Kernel RBF digunakan ketika data tidak terpisah secara linear. Kernel RBF juga memiliki fungsi yang hampir sama dengan kernel linear dan polynomial. Kernel RBF paling sering digunakan karena pemilihan nilai σ yang tepat [10]. Persamaan Kernel RBF dapat dilihat pada Persamaan 3.
K (x, z) = exp (-γ | x -z | 2)
(3)
-
γ berfungsi untuk mengawasi penyebaran fungsi basis radial dan x, z merupakan pola data [9]. Parameter yang dioptimasi dalam kernel RBF adalah parameter Cost (C) dan Gamma (γ).
Denormalisasi merupakan alur/proses yang dilakukan untuk mengembalikan nilai ke nilai asli (awal) dengan tujuan agar mudah dipahami [11]. Persamaan yang digunakan untuk proses denormalisasi dapat dilihat pada Persamaan 4.
x' -fth .
——— Gnax — min) + min
(4)
O >8
y' adalah hasil yang didapatkan dari proses denormalisasi, x' adalah nilai data sebelum dilakukan proses denormalisasi, min adalah nilai paling kecil yang ada pada data set dan max adalah nilai nilai paling besar yang ada pada data set [8].
Akurasi hasil peramalan dihitung menggunakan MAPE (Mean Absolute Percentage Error). MAPE merupakan perhitungan yang digunakan untuk melihat nilai ketetapan ramalan dan untuk melihat seberapa besar kesalahan dalam proses peramalan dibandingan dengan nilai aktualnya. Persamaan untuk perhitungan nilai MAPE dapat dilihat pada Persamaan 5.
∑⅛100% ∑^y^≡
MAPE = --------= -----------
(5)
n n
Xi merupakan data aktual dan Fi merupakan nilai ramalan dari Xi. Menurut Chen, R.J.C, Bloomfield, P, & Cubbage, F.W, [2007], nilai MAPE memiliki interpretasi yang terdiri dari 4 bagian yang dijelaskan pada Tabel 2.
Tabel 2. Interpretasi MAPE
|
Nilai MAPE |
Interpretasi |
|
MAPE < 10% MAPE 10 % - 20% MAPE 20% - 50% MAPE > 50% |
Peramalan Akurat (Sangat Bagus) Peramalan Baik (Bagus) Peramalan Wajar (Cukup) Peramalan Tidak Akurat (Buruk) |
Tabel 2 merupakan interpretasi MAPE yang dibagi menjadi 4 bagian yaitu Peramalan Akurat (Sangat Bagus), Peramalan Baik (Bagus), Peramalan Wajar (Cukup) dan Peramalan Tidak Akurat (Buruk).
Kajian pustaka memuat materi yang menjadi referensi penelitian. Pemilihan referensi yang digunakan disesuaikan dengan topik penelitian yang dilakukan. Topik pada penelitian adalah peramalan jumlah kecelakaan lalu lintas. Referensi yang dimuat yakni terkait kecelakaan lalu intas, Data Mining, Peramalan dan Metode Support Vector Regression. 3.1 Kecelakaan Lalu Lintas
Peraturan Pemerintah Nomor: 43 tahun 1993 pasal 93 tentang Prasarana dan Lalu Lintas Jalan menyebutkan bahwa kecelakaan lalu lintas adalah suatu peristiwa yang tidak pernah disangka-sangka dengan tidak sengaja melibatkan kendaraan dan atau pemakai jalan lainnya yang dapat mengakibatkan korban manusia atau kerugian harta benda. Korban kecelakaan yang dimaksud disini adalah korban meninggal, korban luka berat dan korban luka ringan. Menurut Pamungkas [2014], beberapa kondisi yang digunakan untuk mengklasifikasikan korban kecelakaan lalu lintas,yaitu:
-
1. Kecelakaan lalu lintas dengan korban meninggal dunia adalah dimana kondisi korban
kecelakaan dipastikan meninggal dunia sebagai akibat dari kecelakaan lalu lintas yang dialami dalam jangka waktu paling lama 30 hari setelah terjadinya kecelakaan tersebut.
-
2. Kecelakaan lalu lintas dengan korban luka berat adalah dimana kondisi korban
kecelakaan mengalami cacat tetap atau korban harus dirawat inap di rumah sakit dalam jangka waktu lebih dari 30 hari sejak terjadinya kecelakaan tersebut.
-
3. Kecelakaan lalu lintas dengan korban luka ringan adalah dimana kondisi korban
kecelakaan mengalami luka-luka yang tidak memerlukan perawatan di rumah sakit atau yang dirawat di rumah sakit kurang dari 30 hari.
Data mining adalah teknik perhitungan yang menggunakan sistem perhitungan teknik statistik, matematika, artificial intelligence (kecerdasan buatan) dan machine learning (pembelajaran mesin) yang digunakan untuk mengekstraksi dan mengidentifikasi informasi bermanfaat yang bisa didapatkan dari sebuah database yang besar. Data mining dapat digunakan untuk mencari informasi berupa nilai yang tidak dapat diketahui secara manual [12].
Menurut Fayyad [1996], data mining dibagi menjadi 5 tahap yang terdiri dari Data Selection, Data Preprocessing / Cleaning, Data Transformation, Data Mining dan Interpretation / Evaluation. Data mining dalam menjalankan tugasnya dibagi menjadi 5 kelompok yang terdiri dari Deskripsi, Prediksi, Estimasi, Klasifikasi, Clustering dan Asosiasi.
Peramalan (forecasting) merupakan proses yang dilakukan untuk meramalkan keadaan yang terjadi pada masa yang akan datang[13]. Peramalan juga didasarkan pada hasil keputusan yang dilihat dari data yang sudah ada sebelumnya. Peramalan terdiri dari suatu kerangka kerja yang baku dan kaidah-kaidah yang dapat dijelaskan secara matematis [14]. Menurut Heizer [2005], Peramalan sering diklasifikasikan menjadi 3 bagian yaitu peramalan jangka panjang, peramalan jangka menengah dan peramalan jangka panjang. Peramalan jangka pendek biasanya digunakan untuk meramalkan suatu kejadian dalam hitungan hari, minggu atau bulan di masa depan. Peramalan jangka menengah memiliki jangkauan lebih luas dari jangka pendek yaitu meramalkan kejadian satu hingga dua tahun kedepan dan peramalan jangka panjang adalah peramalan yang dilakukan untuk meramalkan suatu kejadian yang melampaui beberapa tahun kedepan.
-
3.4 Support Vector Regression (SVR)
Support Vector Regression (SVR) merupakan salah satu algoritma yang diambil dari teori Machine Learning. SVR sering digunakan untuk memecahkan kasus regresi. Tujuan dari adanya SVR adalah untuk mencari garis pemisah yang sering disebut dengan Hyperpline [4]. SVR juga merupakan salah satu algoritma yang digunakan untuk mengatasi overfitting dengan tujuan agar mendapatkan hasil yang lebih baik [15]. Algoritma SVR memiliki kelebihan yaitu mampu menangkap relasi non-linear dalam proses regresi [16]. SVR secara umum digunakan untuk mencari fungsi f(x) dengan jumlah nilai deviasi ɛ maximum dan nilai aktual y untuk semua data latih (training). Hasil regresi dapat dkatakan sempurna jika nilai deviasi ɛ = 0.
[17].
Hasil yang dibahas dalam peramalan ini adalah bagaimana teknik peramalan yang dilakukan dalam proses peramalan kasus kecelakaan lalu lintas di Provinsi Bali menggunakan metode Support Vector Regression dan mengaplikasikan dengan dua kernel yaitu kernel Polynomial dan kernel RBF.
Peramalan kasus kecelakaan lalu lintas di Provinsi Bali yang pertama menggunakan Metode Support Vector Regression dengan kernel Polynomial. Hasil pengujian parameter yang digunakan terdapat pada Tabel 3.
Tabel 3. Hasil Pengujian Parameter (C)
|
Parameter (C) |
Nilai Persentase MAPE |
|
1 |
7,95% |
|
10 |
7,99% |
|
100 |
8,03% |
Tabel 3 merupakan hasil perbandingan pengujian parameter, dimana pengujian dilakukan sebanyak tiga kali. Parameter yang digunakan dalam metode Support Vector Regression dan kernel Polynomial yaitu C. Besarnya nilai C sangat berpengaruh terhadap hasil pengujian. Nilai parameter yang semakin kecil menghasilkan persentase MAPE yang lebih baik. Persentase MAPE terbaik yang dihasilkan oleh parameter dengan nilai C paling kecil yaitu 1 dengan nilai persentase 7,95%. Hasil peramalan data kasus kecelakaan lalu lintas di Provinsi Bali menggunakan parameter terbaik terdapat pada Tabel 4.
Tabel 4. Hasil Peramalan Kasus Kecelakaan Lalu Lintas dengan Kernel Polynomial
|
Tahun |
Kasus Laka |
Data Latih |
Data Uji |
MAD |
MAPE % |
|
2007 |
1441 |
2080,7952 |
|
Tahun |
Kasus Laka |
Data Latih |
Data Uji |
MAD |
MAPE % |
|
2008 |
1469 |
2114,376 | |||
|
2009 |
1580 |
2148,432 | |||
|
2010 |
1583 |
2190,8832 | |||
|
2011 |
1737 |
2222,5632 | |||
|
2012 |
1793 |
2269,4496 | |||
|
2013 |
1824 |
2306,5152 | |||
|
2014 |
1827 |
2341,0464 | |||
|
2015 |
2166 |
2372,7264 |
206,73 |
9,54% | |
|
2016 |
2441 |
2438,1456 |
2,85 |
0,12% | |
|
2017 |
3003 |
2497,2288 |
505,77 |
16,84% | |
|
2018 |
2730 |
2584,9824 |
145,02 |
5,31% | |
|
2019 |
2254,8768 | ||||
|
2020 |
2221,4544 | ||||
|
2021 |
2222,4048 | ||||
|
Rata-rata |
7,95% |
Tabel 4 merupakan hasil peramalan data kasus Kecelakaan Lalu Lintas di Provinsi Bali dengan Metode Support Vector Regression dan kernel Polynomial. Hasil persentase MAPE menunjukkan bahwa dengan menggunakan Metode Support Vector Regression dan kernel Polynomial hasilnya “Sangat Bagus” karena nilai persentase berada di bawah 10% (< 10%) yaitu dengan nilai rata-rata 7,95%.
Peramalan kasus kecelakaan lalu lintas di Provinsi Bali yang kedua menggunakan Metode Support Vector Regression dengan kernel RBF. Hasil pengujian parameter yang digunakan terdapat pada Tabel 5.
Tabel 5. Hasil Pengujian Parameter C
|
Parameter (C) |
Nilai Persentase MAPE |
|
1 |
13,35% |
|
10 |
2847,17% |
|
100 |
4854,09% |
Tabel 5 merupakan hasil perbandingan pengujian parameter, dimana pengujian dilakukan sebanyak tiga kali. Parameter yang digunakan dalam metode Support Vector Regression dan kernel RBF yaitu C. Besarnya nilai C sangat berpengaruh terhadap hasil pengujian. Nilai parameter yang semakin kecil akan menghasilkan persentase MAPE yang lebih baik. Persentase MAPE terbaik yang dihasilkan oleh parameter dengan nilai C paling kecil yaitu 1 dengan nilai persentase 13,35%. Hasil peramalan data kasus kecelakaan lalu lintas di Provinsi Bali menggunakan parameter terbaik terdapat pada Tabel 6.
|
Tabel 6. Hasil |
Peramalan Kasus Kecelakaan Lalu Lintas dengan Kernel RBF | |||
|
Tahun |
Kasus |
Data |
Data |
MAD MAPE |
|
Laka |
Latih |
Uji |
% | |
|
2007 |
1441 |
2151,9168 | ||
|
2008 |
1469 |
2157,3024 | ||
|
2009 |
1580 |
2162,8464 | ||
|
2010 |
1583 |
2172,8256 | ||
|
Tahun |
Kasus Laka |
Data Latih |
Data Uji |
MAD |
MAPE % |
|
2011 |
1737 |
2177,2608 | |||
|
2012 |
1793 |
2189,4576 | |||
|
2013 |
1824 |
2196,5856 | |||
|
2014 |
1827 |
2202,288 | |||
|
2015 |
2166 |
2206,5648 |
1645,502999 |
1,87% | |
|
2016 |
2441 |
2226,2064 |
46136,290601 |
8,80% | |
|
2017 |
3003 |
2240,304 |
581705,188416 |
25,40% | |
|
2018 |
2730 |
2256,7776 |
223939,439862 |
17,33% | |
|
2019 |
2254,8768 | ||||
|
2020 |
2221,4544 | ||||
|
2021 |
2222,4048 | ||||
|
Rata-rata |
13,35% |
Tabel 6 merupakan hasil peramalan data kasus Kecelakaan Lalu Lintas di Provinsi Bali dengan Metode Support Vector Regression dan kernel RBF. Hasil persentase MAPE yang dihasilkan menunjukkan bahwa dengan menggunakan Metode Support Vector Regression dan kernel RBF hasilnya “Bagus” karena nilai persentase berada diantara nilai 10%-20% yaitu dengan nilai rata-rata 13,35%.
Perbandingan dari hasil peramalan dengan penggunaan kernel Polynomial dan RBF pada kasus Peramalan Kecelakaan Lalu Lintas di Provinsi Bali Menggunakan Metode Support Vector Regression dapat dilihat pada Tabel 7.
Tabel 7. Perbandingan Hasil Peramalan
|
Kasus |
Kernel | |
|
Polynomial |
RBF | |
|
Kasus Kecelakaan Lalu Lintas |
7.95% |
13.35% |
Berdasarkan Tabel 7 hasil peramalan menggunakan kernel Polynomial memiliki akurasi yang lebih baik dengan nilai MAPE sebesar 7.95%, dibandingkan kernel RBF yang menghasilkan nilai MAPE sebesar 13.35%.
Kasus kecelakaan lalu lintas di Bali terus mengalami peningkatan setiap tahunnya. Adanya peningkatan jumlah kecelakaan tersebut maka diperlukan adanya penanggulangan yang harus dilakukan untuk mencegah jumlah kecelakaan meningkat. Salah satu cara yang dapat dilakukan adalah dengan menerapkan teknik data mining yaitu peramalan (forecasting) mengenai kecelakaan lalu lintas. Hasil peramalan yang dilakukan bisa dijadikan referensi bagi instansi terkait terutama pihak Kepolisian untuk mengambil tindakan agar jumlah kecelakaan lalu lintas tidak mengalami peningkatan. Peramalan yang dilakukan menggunakan data yang berasal dari dari Badan Pusat Statistik (BPS) Provinsi Bali. Data yang digunakan dalam peramalan ini yaitu kasus Kecelakaan Lalu Lintas dari Tahun 2006-2018. Peramalan dilakukan menggunakan Metode Support Vector Regression dan dua kernel, yaitu kernel Polynomial dan RBF.
Kesimpulan dari hasil peramalan yang telah dilakukan dengan mengimplementasikan Metode Support Vector Regression menggunakan kernel Polynomial memiliki hasil akurasi yang lebih baik, yaitu dengan nilai MAPE sebesar 7.95% yang dapat dinyatakan bahwa hasil peramalan “Sangat Bagus”, dibandingkan kernel RBF yang menghasilkan nilai MAPE sebesar 13.35% dengan pernyataan “Bagus”. Penentuaan parameter C juga sangat mempengaruhi
hasil peramalan. Semakin kecil nilai parameter C yang dimasukkan maka hasil nilai persentase MAPE semakin baik.
Daftar Pustaka
-
[1] R. Planning, “DETERMINANTS OF ROAD TRAFFIC ACCIDENT OCCURRENCES IN
LAGOS STATE : SOME LESSONS FOR NIGERIA,” vol. 2, no. 6, pp. 252-259, 2012.
-
[2] Tribun-Bali.com, “Angka Kecelakaan di Bali Meningkat,” bali.tribunnews.com, 2018.
-
[3] BPS, “Banyaknya Kecelakaan Lalu Lintas Menurut Akibat Kecelakaan di Bali, 1996
2018,” 2018. .
-
[4] N. D. Maulana, B. D. Setiawan, and C. Dewi, “Implementasi Metode Support Vector
Regression ( SVR ) Dalam Peramalan Penjualan Roti ( Studi Kasus: Harum Bakery ),” vol. 3, no. 3, pp. 2986–2995, 2019.
-
[5] H. Muhamad, I. Cholissodin, and B. D. Setiawan, “Optimasi Support Vector Regression (
SVR ) Menggunakan Algoritma Improved-Particle Swarm Optimization ( IPSO ) untuk Peramalan Curah Hujan,” vol. 1, no. 11, pp. 1142–1151, 2017.
-
[6] S. Martha and E. Sulistianingsih, “SUPPORT VECTOR REGRESSION ( SVR ),” vol. 08,
no. 1, pp. 1–10, 2019.
-
[7] N. A. Putra, B. D. Setiawan, and P. P. Adikara, “Peramalan Harga Saham Menggunakan
Support Vector Regression Dengan Algoritme Genetika,” vol. 2, no. 1, pp. 209–216, 2018.
-
[8] B. Pada, P. G. Candi, B. Sidoarjo, A. S. Rachman, I. Cholissodin, and M. A. Fauzi,
“Peramalan Produksi Gula Menggunakan Metode Jaringan Syaraf Tiruan,” vol. 2, no. 4, pp. 1683–1689, 2018.
-
[9] C. López-martín, “ʋ -SVR Polynomial Kernel for Predicting the Defect Density in New
Software Projects,” no. December, 2018.
-
[10] R. A. Wijayanti, M. T. Furqon, and S. Adinugroho, “Penerapan Algoritme Support Vector Machine Terhadap Klasifikasi Tingkat Risiko Pasien Gagal Ginjal,” vol. 2, no. 10, pp. 3500–3507, 2018.
-
[11] J. I. Matematika and S. D. Anggraini, “MATH unesa,” vol. 3, no. 6, pp. 110–115, 2017.
-
[12] D. J. Hand, Principles of data mining, vol. 30, no. 7. 2007.
-
[13] R. Susetyoko, “Peramalan Gabungan Rantai Markov dan Model Deret Waktu Pada Kasus Peramalan Kurs Nilai Mata Uang,” pp. 104–115, 2016.
-
[14] D. P. Fardani, E. Wuryanto, and I. Werdiningsih, “MENGGUNAKAN METODE EXTREME LEARNING MACHINE ( STUDI KASUS: POLI GIGI RSU DR . WAHIDIN SUDIRO HUSODO MOJOKERTO ),” vol. 1, no. 1, 2015.
-
[15] D. T. Adiningtyas, “Peramalan jumlah tamu hotel di kabupaten demak menggunakan
metode support vector regression,” vol. 4, pp. 785–794, 2015.
-
[16] N. N. Putriwijaya and W. F. Mahmudy, “Peramalan Jumlah Pemakaian Air di PT .
Pembangkitan Jawa Bali Unit Peramalan Jumlah Pemakaian Air di PT . Pembangkitan Jawa Bali Unit Pembangkit Gresik Menggunakan Support Vector Regression,” no. October, 2018.
-
[17] R. Rismala, “Prediksi Harga Saham menggunakan Support Vector Regression dan Firefly Algorithm Stock Market Price Prediction using Support Vector Regression and Firefly Algorithm Abstrak 2 LANDASAN TEORI,” vol. 2, no. 2, pp. 6217–6231, 2015.
Peramalan Jumlah Kecelakaan Lalu Lintas Menggunakan Metode Support Vector
Regression (Ni Putu Ratindia Apriyanti)
80
Discussion and feedback