Genetic K-Means Algorithms, ASSU Analisis Peningkatan Kompetensi Mahasiswa Menggunakan Model Pembelajaran ASSURE berbasis Project-Based Learning
on
Majalah Ilmiah Teknologi Elektro, Vol. 17, No. 3, September - Desember 2018
DOI: https://doi.org/10.24843/MITE.2018.v17i03.P16
409
Analisis Peningkatan Kompetensi Mahasiswa Menggunakan Model Pembelajaran ASSURE berbasis Project-Based Learning
Asri Prameshwari1, Rukmi Sari Hartati2, Made Sudarma3
Abstract— Learning systems that have been implemented and developed to improve and understand about learning material that later becomes a basic competency. This study analyzes the results of student's competency improvement in information technology courses at STIKes Wira Medika Bali Bachelor of Nursing using ASSURE and Project-Based Learning. The method used for grouping the results of the improvement using Genetic K-Means Algorithms, this method was chosen because it has more optimal performance than simple K-Means. This algorithm which uses natural selections for optimization determines initial seeds. Determination of the number of clusters used in this study was three clusters with high, medium and low categories. The results of this study for the medium category increased with a range of 3.92% and 14%, for the low category increased by 31.37% and 74%, for the high category decreased by 35.29% and 60%.
Intisari— Sistem pembelajaran yang telah diterapkan dan dikembangkan bertujuan untuk meningkatkan, menguasai, memahami, dan menerapkan materi belajar untuk kemudian dijadikan suatu kompetensi dasar. Penelitian ini menganalisa hasil peningkatan kompetensi mahasiswa dalam mata kuliah teknologi informasi di STIKes Wira Medika Bali pada jenjang S1 Keperawatan dengan menggunakan sistem pembelajaran ASSURE berbasis Project-Based Learning. Metode yang digunakan dalam pengelompokkan hasil peningkatan tersebut menggunakan Genetic K-Means Algorithms, Metode ini dipilih karena mempunyai kinerja lebih optimal dari K-Means sederhana. Algoritma ini yang menggunakan natural selections untuk opitimalisasi menentukan initial seeds. Penentuan jumlah cluster yang digunakan dalam penelitian ini sebanyak tiga cluster dengan kategori tinggi, sedang dan rendah. Hasil dari penelitian ini untuk kategori sedang meningkat dengan range 3,92% dan 14%, untuk kategori rendah meningkat 31,37% dan 74%, untuk kategori tinggi menurun 35,29% dan 60%.
Kata Kunci— Genetic K-Means Algorithms, ASSURE, ProjectBased Learning, Kompetensi Mahasiswa, Cluster
I. pendahuluan
Salah satu upaya peningkatan kompetensi mahasiswa dalam bidang teknologi informasi adalah dengan menerapkan satu sistem pembelajaran yang berbasis teknologi informasi.
Diketahui bahwa dengan menggunakan satu sistem pembelajaran yang terstruktur diharapkan bisa meningkatkan motivasi belajar dan dorongan untuk meningkatkan minat belajar. Fungsi dari sistem pembelajaran adalah untuk memberikan media pengembangan kepada rancangan pembelajaran yang telah disusun guna mencapai sasaran dan tujuan dari. Satu model pembelajaran dan satu metode pembelajaran, yang kemudian digabungkan untuk membentuk sistem pembelajaran baru.
Model pembelajaran yang pilih adalah model pembelajaran ASSURE karena model pembelajaran ini memadukan penggunaan teknologi dan media untuk menciptakan program pembelajaran yang sistematis dan menarik[1]. Untuk metode pembelajaran yang digunakan adalah metode pembelajaran berbasis proyek (Project-Based Learning), metode pembelajaran ini berpusat pada siswa untuk melakukan suatu pendalaman pembelajaran dengan pendekatan berbasis riset terhadap suatu permasalahan dan pertanyaan yang berbobot, nyata, dan relevan[2].
Pada hasil penerapan sistem pembelajaran ini akan dilakukan pengelompokkan tingkat kompetensi mahasiswa sebagai tolok ukur keberhasilan penggunaan sistem pembelajaran terhadap mahasiswa. Untuk pengelompokkan hasil peningkatan tersebut digunakan cluster dengan K-means, dengan pertimbangan bahwa algoritma clustering tersebut merupakan algoritma sederhana dan paling banyak digunakan karena mempunyai kelebihan dalam pengelompokkan data dengan jumlah yang cukup besar pada waktu yang lebih cepat dan efisien[3].
Dengan kelemahan yang dimiliki oleh algoritma K-Means dalam penentuan pusat awal cluster, maka dikolaborasikan dengan Genetic Algorithm sebagai optimasi initial seeds. Penggabungan metode ini dinamakan dengan Genetic K-Means Algorithm Sebuah studi yang diterapkan pada segmentasi pasar perdagangan membuktikan Genetic K-Means Algorithm dapat menghasilkan segmentasi yang lebih baik dari algoritma clustering tradisional seperti simple K-Means[4]. Dengan menggunakan K-Means dan Genetic Algorithm tersebut diharapkan dapat mengelompokkan hasil peningkatan kompetensi mahasiswa sesuai dengan tinggi rendahnya peningkatan tersebut.
1Mahasiswa Magister Teknik Elektro Fakultas Teknik Universitas Udayana Jln. Jalan Kampus Bukit Jimbaran 80361 INDONESIA (tlp: 0361-555225; fax: 0361-4321982; e-mail: asri.prameshwari@yahoo.com)
-
2, 3 Dosen,Jurusan Teknik Elektro Fakultas Teknik Universitas Udayana, Jln. Jalan Kampus Bukit Jimbaran 80361 INDONESIA (telp: 0361-703315; fax: 0361-703315; e-mail: msudarma@unud.ac.id, rukmisari@unud..ac.id)
Asri Prameshwari: Analisis Peningkatan Kompetensi Mahasiswa
-
II. METODE PENELITIAN
-
A. Kompetensi Mahasiswa
Seiring dengan perkembangan dalam pendidikan, maka kemampuan mahasiswa dalam mempelajari ilmu pengetahuan juga harus ditingkatkan karena semua bidang pekerjaan membutuhkan kemampuan akan penguasaan suatu kompetensi. Secara umum definisi kompetensi adalah
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

karateristik yang dimiliki oleh individu dan digunakan secara tepat dengan cara yang konsisten untuk mencapai kinerja yang diinginkan[5]. Gambaran kompetensi pada mahasiswa bisa dikelompokan menjadi tiga yaitu yang pertama adalah kompetensi dasar di mana kemampuan minimal yang harus dicapai dalam penguasaan konsep dan materi, yang kedua adalah kompetensi standar yaitu kemampuan minimal yang harus dicapai oleh mahasiswa dan yang ketiga adalah kompetensi lulusan yang diartikan sebagai kemampuan minimal dari mahasiswa setelah tamat.
-
B. Model Pembelajaran ASSURE
Model pembelajaran ASSURE adalah model pembelajaran yang dikembangkan oleh Sharon Smaldino, Robert Henich, James Rusell dan Michael Molenda di dalam buku yang berjudul “Instructional Technology and Media for Learning”[1].
Tahapan proses yang ada pada model pembelajaran ASSURE dapat dijelaskan pada Gambar 1:

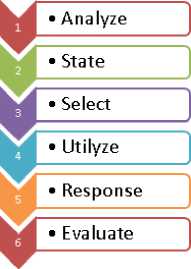
Gambar 1. Tahapan proses ASSURE
Dari gambar 1, enam tahapan proses pembelajaran ASSURE adalah sebagai berikut :
-
1) Analyze Learners : Dalam tahap pertama ini yang akan dilakukan adalah menganalisa kebutuhan mahasiswa sehingga mereka mampu mendapatkan tingkatan pengetahuan dalam pembelajaran secara maksimal.
-
2) State Objectives : Pada langkah ini yang dibahas adalah tujuan dari pembelajaran dan pemaparan tentang apa yang akan dicapai.
-
3) Select Methods, Media and Material : Dalam tahap ini membuat pembelajaran yang efektif dengan menentukan sistematika pemilihan strategi, teknologi, dan media sebagai bahan ajar.
-
4) Utilize Media and Materials : Dalam tahap ini terdapat berberapa yang perlu disiapkan antara lain persiapan materi yang akan disampaikan, penggunaan media sebagai sarana penyampaian, fasilitas yang harus disiapkan, penyampaian tujuan pembelajaran kepada mahasiswa
-
5) Require Learner Participation : Terdapatnya partisipasi mahasiswa dalam materi dan media yang diberikan
-
6) Evaluate and Revise : Penilaian dan perbaikan adalah aspek yang sangat mendasar untuk mengembangkan kualitas pembelajaran
Menurut penjabaran dari Kementerian Pendidikan dan Kebudayaan dalam artikel mengenai Project-Based Learning dengan Badan Pengembangan SDM Pendidikan dan Kebudayaan dan Penjaminan Mutu Pendidikan menjelaskan bahwa metode Project-Based Learning adalah metode pembelajaran yang menggunakan proyek atau kegiatan sebagai langkah awal dalam mengintegrasikan pengetahuan baru[6].
Tahapan proses pelaksanaan dari Project-Based Learning
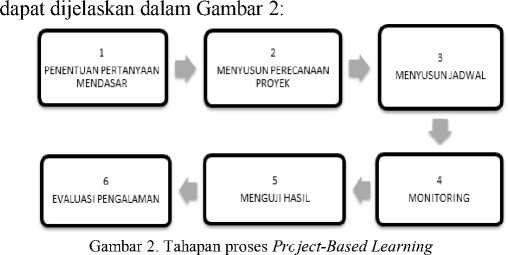
Dari gambar 2, enam tahapan proses Project-Based Learning adalah sebagai berikut :
-
1) Penentuan Pertanyaan Mendasar (Start With Essential Question) : Pembelajaran dimulai dengan pertanyaan yang dapat memberikan penugasan untuk melakukan suatu aktivitas dengan mengambil topik yang sesuai dengan realitas dan relevan untuk diangkat oleh mahasiswa.
-
2) Mendesain Perencanaan Proyek (Design A Plan For The Project) : Perencaan akan desain proyek dilakukan secara kolaboratif oleh mahasiswa dan dosen dengan tujuan mahasiswa akan merasa “memiliki” atas proyek tersebut.
-
3) Menyusun Jadwal (Create A Schedule) : Penyusunan jadwal secara kolaboratif disusun oleh dosen dan mahasiswa.
-
4) Memonitoring Mahasiswa dan Kemajuan Proyek (Monitoring) : Dosen bertanggung jawab untuk melakukan monitoring terhadap aktivitas mahasiswa selama pengerjaan proyek.
-
5) Menguji Hasil (Assess the Outcome) : Penilaian dilakukan untuk membantu dosen dalam mengukur ketercapaian, evaluasi kemajuan, memberi umpan balik dan menyusun strategi pembelajaran.
-
6) Mengevaluasi Pengalaman (Evaluate The Experience)
Pada akhir proses pembelajaran, dosen dan mahasiswa melakukan refleksi terhadap aktivitas dan hasil proyek yang sudah dijalankan.
-
D. Sample Slovin
Pemilihan sampel dengan metode yang tepat dapat menggambarkan kondisi populasi yang sesungguhnya, maka idealnya sampel harus mewakili hal tersebut. Salah satu metode yang digunakan untuk menentukan jumlah sampel adalah menggunakan rumus Slovin[7] pada rumus 1:
Jlf n = — l+s dengan :
(1)
Tl = Jumlah sampel
JV = Jumlah populasi
e = Batas toleransi kesalahan (error tolerance)
C. Project-Based Learning
E. Metode Clustering
Clustering adalah proses pengelompokan set objek fisik atau abstrak ke dalam kelas benda serupa atau mirip. Sebuah benda dari salah satu cluster/kelompok akan berbeda dengan objek milik kelompok lain dan clustering dapat dibedakan menjadi dua kategori, yaitu Hierarchical Clustering dan Partitional Clustering[8]. Hierarchical Clustering adalah suatu metode pengelompokkan data yang dimulai dengan mengelompokkan dua atau lebih objek yang memiliki kesamaan paling dekat, untuk kemudian diteruskan dengan proses yang sama pada keseluruhan data. Hasil cluster tersebut akan membentuk suatu tingkatan (hierarki) dari data yang memiliki kesamaan paling mirip hingga data yang memiliki kesamaan[9]. Partitional Clustering dilakukan dengan penentuan jumlah cluster diawal yang kemudian diproses untuk dikelompokkan data tersebut di dalam cluster tanpa hierarki, proses ini dinamakan K-Means Clustering [9].
-
F. K-Means
Ada berbagai metode untuk melakukan clustering. Algoritma K-Means merupakan salah satu metode yang cepat dan efisien dalam melakukan clustering. Proses clustering dengan algoritma K-Means sebagai berikut[9] :
-
• Penentuan banyaknya cluster k
-
• Pemberian nilai awal secara acak pada titik pusat cluster k.
-
• Penempatan keseluruhan data pada cluster paling dekat, yang jarak kedekatannya ditentukan oleh data – data tersebut. Dimana rumus perhitungan jarak menggunakan teori jarak Euclidian pada rumus 2 dan 3:
d = ∑ ?= L∑jΛjj ⅛m i ∑J = i C¾J x ⅛) (2)
d(i,j) =-¾y+⅛ -⅛y + -+c⅛ -⅛r
(3)
dengan :
d(i,j) = Jarak data ke i ke pusat cluster j ¾t = Data ke i pada atribut data ke k ¾ = Titik pusat j ke atribut k
-
• Perhitungan kembali nilai pada titik pusat cluster dengan rumus sebagai berikut
ft = (4)
-
• Mengkalkulasi setiap data dengan pusat cluster yang baru. Jika pusat cluster tidak berubah, maka proses clustering selesai. Jika tetap berubah maka mengulang langkah poin c sampai pusat cluster tidak berubah.
-
G. Genetic K-Means Algorithms
Pencarian optimalisasi dari untuk mencari solusi yang lebih baik dapat diperoleh dengan proses perhitungan yang cukup panjang dan tidak praktis. Untuk mengatasinya digunakan metode yang didasarkan atas intuisi atau aturan empiris untuk memperoleh solusi yang lebih baik daripada solusi yang telah dicapai sebelumnya[10]. Genetic Algorithm adalah suatu cabang evolutionary algorithms yakni suatu teknik optimasi yang didasarkan pada genetika alami dan melakukan proses pencarian diantara sejumlah alternatif titik
optimal berdasarkan fungsi probabilistic[11]. Salah satu kelebihan dari Genetic Algorithm adalah mempunyai penyelesaian yang optimal dengan berbagai macam variable obyektif[12] sehingga algoritma ini membantu mengoptimasi titik pusat dari K-Means. Genetic K-Means Algorithms adalah salah satu algoritma untuk optimalisasi K-Means Algorithm yang memiliki kelemahan dalam menentukan titik pusat cluster (initial seeds). Dimana tahap inisialisasi awal dari Algoritma K-Means ditentukan secara random, pemilihan intial seeds (titik pusat cluster) yang berbeda akan menghasilkan klaster yang berbeda pula[13]. Alur proses kerja Genetic K-Means Algorithm [14] dapat dijelaskan pada Gambar 3:
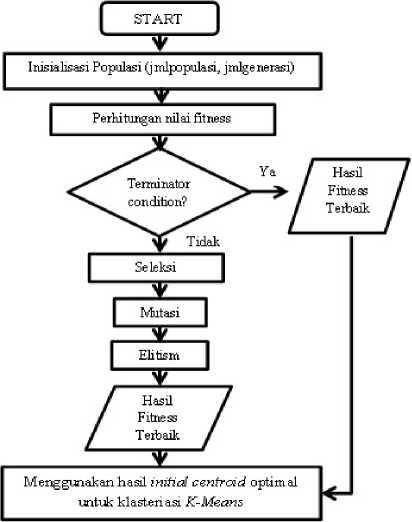
Gambar 3. Alur Proses Kerja Genetic K-Means
Dari gambar 3, dijelaskan bahwa algoritma dimulai dengan fase inisialisasi populasi awal dan generasi yang kemudian dilanjutkan mencari nilai fitness individu yang dilakukan dengan melakukan seleksi populasi, mutasi, dan eltism yang dilakukan secara terus menerus hingga menghasilkan kondisi akhir telah dicapai yaitu pada tiap kromosom memiliki angka fitness yang konvengen pada suatu generasi, yang kemudian menjadi langkah awal untuk intial centroid untuk klasterisasi K-Means. Untuk mendapatkan
-
III. DESAIN MODEL
-
A. Sumber Data
Pada penelitian ini menggunakan dua kelompok penelitian yakni kelompok eksperimen yang terdiri dari dua kelas mahasiswa (Kelas B dan Kelas C) dan kelompok kontrol (Kelas A) yang masing – masing terdiri dari 50 orang mahasiswa. Kedua kelompok penelitian tersebut diberikan perlakuan yang sama dalam hal ini adalah pretest dan posttest untuk mengambil data awal dan data akhir. Tabel pembagian kelompok dapat dilihat pada Tabel 1:
Asri Prameshwari: Analisis Peningkatan Kompetensi Mahasiswa …
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

TABEL I
PEMBAGIAN KELOMPOK PENELITIAN
|
Kelompok |
Pretest |
Posttest | |
|
Kelas A10-A |
O1 |
Pembelajaran Langsung |
O2 |
|
Kelas A10-B Kelas A10-C |
O3 |
Pembelajaran ASSURE-Project Based Learning |
O4 |
Dari tabel 1 tersebut digunakan dua kelompok yang dipilih sesuai dengan metode penelitian eksperimen yakni PretestPosttest Control Group Design, yang merupakan metode penelitian eksperimen yang menggunakan dua kelompok subjek. Dua kelompok subjek tes tersebut diberi nama kelompok kontrol dan eksperimen. Dimana kelompok eksperimen diberi perlakuan, sementara kelompok kontrol tidak, sebelum dan sesudah pemberian perlakuan kedua kelompok tersebut diukur variabelnya
-
B. Variabel Penelitian
Berikut beberapa variabel penelitian yang meliputi kompetensi akademik dan domain aspek yang akan diukur peningkatannya.Untuk kompetensi akademik antara lain sebagai berikut :
-
• Memahami tentang hardware (Konsep, Bagian, Cara Kerja).
-
• Memahami akan teori-teori dasar komputer, dasar-dasar aplikasi, dan pengetahuan umum mengenai perkembangan perangkat lunak.
-
• Mengerti akan jaringan komputer.
-
• Dapat membuat aplikasi sederhana.
-
C. Desain Model Pembelajaran ASSURE berbasis Project
Based Learning
Sistem pembelajaran yang dirancang ini merupakan perpaduan tahapan-tahapan proses dari model pembelajaran ASSURE berbasis metode Project-Based Learning. Untuk gambaran dari desain model pembelajaran dapat dilihat pada Gambar 4 :
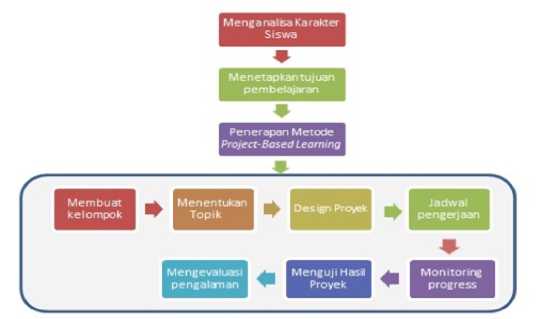
Gambar 4. Alur Proses Kerja Genetic K-Means
Dari gambar 4 tersebut, terlihat metode Project-Based Learning tergabung ke dalam model pembelajaran ASSURE pada tahapan ke ketiga (Select Methods, Media and Material), dimana pada tahapan empat dan seterusnya sudah tercantum di dalam tahapan proses metode Project-Based Learning.
-
D. Skema Alur Penelitian
Skema penjelasan dari alur penelitian dapat dilihat pada Gambar 5:
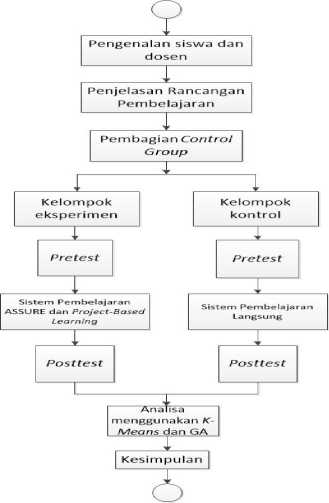
Gambar 5. Skema alur penelitian sistem pembelajaran ASSURE berbasis Project-Based Learning
Dari gambar 5 tersebut, tahapan – tahapan yang telah ada pada desain pembelajaran ASSURE berbasis Project-Based Learning diterapkan pada kelompok eksperimen dan sistem pembelajaran langsung diterapkan pada kelompok kontrol. Dimana akhir dari skema tersebut adalah analisa pengelompokkan data dengan menggunakan Genetic K-Means Algorithm.
-
E. Populasi dan Sample
Jumlah populasi yang dilakukan penelitian adalah sebesar 150 orang mahasiswa yang mengikuti perkuliahan yang terdiri dari tiga kelas ajar dan terbagi menjadi dua kelas penelitian. Untuk penentuan sampel dari populasi tersebut dapat dihitung sesuai dengan rujukan dari rumus 1 tentang metode penentuan sampel dapat dihitung sebagai berikut :
150
Tl — -----------------
1 + 150(0.05√
150
-
- 1 + 0,375
= 109.09
Dari hasil perhitungan dengn rumus 1 di atas dihitung dengan populasi siswa sebanyak 150 orang dengan kemungkinan sampel tidak bisa digunakan (error tolerance) sebesar 0,05 maka didapatkan hasil sampel yang bisa digunakan sebesar 109 mahasiswa.
-
IV. DESAIN MODEL
-
A. Kompetensi Akademik
Dalam penilaian kompetensi akademik dilakukan pemberian pretest dan posttest dalam bentuk soal sebanyak 30 pertanyaan yang mewakili dari empat capaian kompetensi akademik dengan pembagian kelompok penelitian yang terdiri dari tiga kelas (Kelas A 51 orang mahasiswa, Kelas B 50 orang mahasiswa, Kelas C 51 orang mahasiswa). Dari
penilaian tersebut dikelompokkan dengan nilai diatas rata-rata(>50), rata-rata(=50) dan dibawah rata-rata(<50) dari hasil total nilai sempurna 100. Presentase hasil dapat dilihat dalam Tabel 2:
TABEL III
PRESENTASE HASIL PRETEST POSTTEST
|
Kelas A |
Kelas B |
Kelas C | ||||
|
Pre test |
Post test |
Pre test |
Post test |
Pre test |
Post test | |
|
Rata-rata |
3.92 |
9.80 |
0 |
4 |
3.92 |
7.84 |
|
Diatas rata-rata |
94.11 |
62.74 |
98 |
10 |
84.31 |
49.01 |
|
Dibawah rata-rata |
1.96 |
33.33 |
10 |
94 |
17.64 |
49.01 |
Dari tabel 2 tersebut, dapat dilihat perbedaan hasil yang signifikan antara kelas A (kelompok kontrol) yang nilai diatas rata-rata lebih stabil penurunan hasil. Pada kelompok eksperimen (kelas B dan C) hasil pretest posttest mengalami signifikansi penurunan. Hal ini dikarenakan pada kelompok eksperimen, rentang waktu penerapan sistem pembelajaran yang relatif singkat membuat mahasiswa perlu beradaptasi dalam penyerapan materi.
-
B. Variabel Domain Aspek
Dalam penilaian domain aspek dilakukan dengan metode pengamatan tiap mahasiswa dalam setiap kali pertemuan, yang kemudian diberikan penilaian dengan range nilai 10 sebagai nilai terendah dan 100 sebagai nilai tertinggi, dengan mengacu pada klasifikasi nilai di STIKes Wira Medika yakni Amat Baik (76-100), Baik (66-75), Cukup (56-65) dan Kurang (40-55). Klasifikasi untuk domain aspek Afektif adalah minat, sikap dan tingkat disiplin, untuk domain Kognitif adalah menghafal, menganalisa, dan evaluasi, untuk domain Psikomotor adalah kemampuan membuat proyek, dan untuk domain Interpersonal adalah kemampuan bekerja dalam tim. Hasil domain untuk kelompok kontrol dapat dilihat pada Tabel 3:
TABEL IIIII
HASIL DOMAIN ASPEK KELOMPOK KONTROL
|
Kelas A | ||||
|
Afektif |
Kognitif |
Psikomotor |
Interpersonal | |
|
Istimewa (A) |
13 |
8 |
6 |
5 |
|
Baik (B) |
-4 |
4 |
4 |
5 |
|
Cukup (C) |
-7 |
-12 |
-7 |
-10 |
|
Kurang (D) |
0 |
0 |
3 |
0 |
Dari tabel 3 tersebut, dapat dilihat untuk hasil pengamatan pretest posttest selama rentang waktu penelitian, pada keempat domain tersebut terdapat penurunan jumlah mahasiswa untuk tiap kategori yang diwakilkan dengan simbol minus. Contohnya untuk kategori nilai B pada domain Afektif terdapat penurunan sebanyak 4 mahasiswa dari proses pretest posttest (sewaku pretest terdapat 28 mahasiswa dan sewaktu posttest terdapat 24 mahasiswa).
Hal ini terjadi, untuk beberapa mahasiswa mengalami kesulitan untuk beradaptasi dengan sistem pembelajaran.
Untuk hasil domain untuk kelompok eksperimen (Kelas B dan C) dapat dilihat pada tabel 4:
TABEL IVII
HASIL DOMAIN ASPEK KELOMPOK KONTROL
|
Kelas B dan C | ||||
|
Afektif |
Kognitif |
Psikomotor |
Interpersonal | |
|
Istimewa (A) |
30 |
20 |
9 |
14 |
|
Baik (B) |
-8 |
6 |
10 |
2 |
|
Cukup (C) |
-22 |
-22 |
-7 |
-22 |
|
Kurang (D) |
0 |
4 |
12 |
2 |
Dari tabel 4 diatas, terlihat hasil penilaian untuk domain aspek kelompok eksperimen (Kelas B dan C). Perlakuan yang sama juga diterapkan selama pengamatan pretest posttest. Sebagai penanda terjadinya penurunan jumlah mahasiswa dari hasil pengamatan kemudian diberikan simbol minus. Seperti pada domain Kognitif dengan nilai C, sewaktu pengamatan terdapat penurunan mahasiswa (Kelas B 12 mahasiswa, kelas C 10 mahasiswa).
-
C. Clustering Data
Tahapan – tahapan yang digunakan dalam Clustering data pada penelitian ini adalah data preparatation, modeling dan interpretation.
-
1) Data Preparation : Pada tahap ini data pretest dan posttest dalam bentuk excel diubah menjadi format text dokument dengan mengambil nilai – nilai yang dibutuhkan untuk cluster. Data dalam bentuk file dokumen dapat dilihat pada Gambar 6:
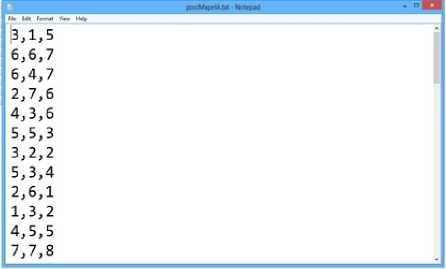
Gambar 6. Data Text Dokumen
Dari gambar 6 tersebut, menjelaskan mengenai nilai pretest posttest yang dibutuhkan, dalam hal ini adalah nilai benar yang diambil untuk tiap mahasiswa. Dari hasil diatas akan diproses untuk masuk ke masing – masing cluster yang telah terbentuk, untuk kemudian dianalisis profil cluster yang ada.
-
2) Modeling
Dalam data modeling ada dua tahapan besar :
-
• Intial Centroid
Tujuannya adalah mencari titik tengah dari klaster yang akan digunakan, dalam hal ini menggunakan Algortima Genetika (Genetic Algorithm) yang mencari nilai fitness terbaik dari individu dari proses evaluasi individu, sorting, crossover, dan pengulangan semua proses sehingga
Asri Prameshwari: Analisis Peningkatan Kompetensi Mahasiswa …
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

mendapatkan hasil terbaik. Code program untuk mencari intial centroid dapat dilihat pada Gambar 7:
function [ centroid ] = findlnitialCentroid(X,k)
CostFunction=0(m) ClusteringCost(It), X); % Cost
Function
VarSize=[k size(X,2)]; % Decision Variables Matrix Size
(VarSize); ⅞ Nuinber of Decision Variables
VarMin= repmat(min (X),k,1); ⅞ Lower Bound of
Variables
VarMax= repmat(max (X),k,1); ⅜ Upper Bound of
Variables
Gambar 7. Program Function FindIntialCentroid
-
• K-Means Algorithm
K-Means merupakan algoritma clustering yang sudah umum digunakan, pada penelitian ini jumlah klaster yang digunakan sudah ditentukan dari awal yakni tiga klaster dengan pembagian klaster tinggi, klaster sedang, klaster rendah. Tujuan dari sudah ditentukannya ada tiga buah klaster adalah memudahkan melihat dan pengelompokkan data sesuai dengan hasil Pretest Posttest materi dan karateristik tiap mahasiswa. Code program untuk K-Means Algorithm dapat dilihat pada Gambar 8:
function
[class,centroid,counter]=MyKMeans(data,k,init_centroid)
% 1- Randon
⅜2- First three
%3- One from each group
⅝4- Centroid passes as parameter
centroid=[] ;
class= [] ;
[n,m]=size(data) ;
selected=[];
centroid=init centroid;
fIag=O;
count=0;
counter=[];
%classify the data
while(fIag==O)
[di≡t,class]"MyDistance(centroid, data);
if(count~=0)
temp=(class==prevclass) ;
if( max(max(temp))==1 ££ min(min(temp))==1) fIag=I;
counter;
break;
end
end
prevclass=class;
Gambar 8. Program Function MyKMeans
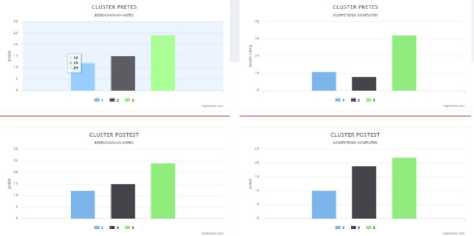
Gambar 9. Grafik hasil cluster
Dari gambar 9 tersebut, ringkasan jumlah data ditiap cluster berdasarkan pretest dan posttest variabel domain aspek maupun kompetensi materi yang diujikan.
-
V. KESIMPULAN
Kesimpulan dari penelitian ini adalah hasil untuk kelompok eksperimen dari keempat variabel domain karateristik dan kompetensi akademik tidak berbanding lurus, yakni mengalamai penurunan. Hal ini disebabkan dengan beberapa faktor antara lain kelompok eksperimen diterapkan sistem pembelajaran ASSURE berbasis Project Based-Learning dalam jangka waktu yang relatif singkat dan belum terbiasa akan sistem pembelajaran yang baru sehingga nilai posttest lebih menurun dibandingkan dengan nilai pretest. Pada kelompok kontrol, nilai kompetensi akademik dan variabel domain relatif lebih stabil tingkat penurunan, dikarenakan kelas tersebut tidak memerlukan adaptasi akan sistem pembelajaran baru.
Hasil penelitian dari kedua kelompok pembelajaran (eksperimen dan kontrol) berdasarkan tabel 2, didapatkan penilaian akademik untuk kelas A (Nilai diatas rata-rata menurun sebesar 31,37%, nilai rata – rata meningkat 5,88%, nilai dibawah rata – rata meningkat 31,37%), untuk kelas B (Nilai diatas rata –rata menurun sebesar 88%, nilai rata – rata meningkat 4%, nilai dibawah rata – rata meningkat 84%), untuk kelas C (Nilai diatas rata – rata menurun 35,29%, nilai rata – rata meningkat sebesar 3,92%, dibawah rata – rata meningkat 31.37%). Dari hasil tersebut, analisi tren penurunan terjadi dikedua kelompok dengan nilai diatas rata-rata, disamping karena alokasi waktu penerapan sistem pembelajaran yang relatif pendek, hal itu juga di sebabkan antara lain kurang fokusnya mahasiswa, lingkungan belajar, penurunan minat belajar pada saat posttest.
REFERENSI
3) Interpretation
Pada tahap interpretation ini, informasi hasil clustering yang ditampilkan secara visual dalam bentuk grafik. Untuk grafik hasil cluster dapat dilihat pada Gambar 9:
-
[1] Smaldino, S., Rusell J., Heinich, R., Molenda M. Instructional Technology and Media for Learning. Upper Saddle River, New Jersey : Pearson Merill Prentice Hall.2005
-
[2] Grant, M. M. Getting a grip on project-based learning: Theory, cases and recommendations. Meridian: A Middle School Computer Technologies Journal, 5, 2002. 1-17.
-
[3] K.Arai and A.R. Barakbah. “Hierarchical K-Means:and Algorithm for centroids initialization for K-Means”.2007
-
[4] Kim, K. and Ahn, H. A Recommender System Using GA k-Means Clustering in an Online Shopping Market. Expert Systems with Applications, 34, 2008.1200-1209.
-
[5] Depdikbud. Kurikulum Berbasis Kompetensi. Jakarta:Depdikbud. 1994
-
[6] Kebudayaan, K.P.D., n.d. Model Pembelajaran Berbasis Proyek (Project-Based Learning).2013.
-
[7] Sevilla C.G.et.al. Research Method. Quezon City:Rex Printing Company. 1960
-
[8] Prabin Lama and Patric Granholm. Clustering System Based On Text Mining Using The K-Means Algorithm.2013
-
[9] Santosa, B. Data Mining : Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta:Graha Ilmu. 2007
-
[10] Taha, H.A. Operations Research – An Introduction,6th ed, Pearson Education Inc. 2002
-
[11] Wahyu Widodo, Agus & Mahmudy, Wayan. . Penerapan algoritma genetika pada sistem rekomendasi wisata kuliner. Kursor. 5. 2010. 205-211.
-
[12] Mahmudy, W.F., Algoritme Evolusi, Malang, PTIK Universitas Brawijaya, 2013
-
[13] Al-Shboul, Bashar & Myaeng, Sung-Hyon. Initializing K-Means using Genetic Algorithms. 2009. 54.
-
[14] Lu, Yi & Lu, Shiyong & Fotouhi, Farshad & Deng, Youping & Brown, Susan.FGKA: a Fast Genetic K-means Clustering Algorithm .622-623. 2004. DOI:10.1145/967900.968029.
Asri Prameshwari: Analisis Peningkatan Kompetensi Mahasiswa …
p
-ISSN:1693 – 2951; e-ISSN: 2503-2372

{ Halaman ini sengaja dikosongkan }
ISSN 1693 – 2951
Asri Prameshwari: Analisis Peningkatan Kompetensi Mahasiswa…
Discussion and feedback