Klasifikasi Penggunaan Protokol Komunikasi Pada Trafik Jaringan Menggunakan Algoritma K-Nearest Neighbor
on
Teknologi Elektro, Vol. 16, No1, Januari-April 2017
67
Klasifikasi Penggunaan Protokol Komunikasi Pada Trafik Jaringan Menggunakan Algoritma K-Nearest Neighbor
I Komang Kompyang Agus Subrata1, I Made Oka Widyantara2, Linawati3
Abstract — Network traffic internet is data communication in a network, which is characterized by information from the packet header data. Proper classification of network traffic on a very important notably in terms of architectural design network design, network and network security Risk Management. The analysis of computer network traffic is one way to know the use of the computer network communication protocol, so it can be the basis for determining the priority of Quality of Service (QoS). Basic practice in providing QoS priority is to analyze the data traffic on the network. In this study the classification of the data capture network traffic on though Algorithm K-Neaerest Neighbor (K-NN). Applications used to capture network traffic that wireshark application. The results of observations of the dataset and the network traffic through the calculation process using K-NN algorithm obtained a result that classification K-NN has a very high level of accuracy. This is evidenced by the results of calculations which reached 99.14%, ie by calculating k = 3.
Intisari—Trafik jaringan internet merupakan lalu lintas komunikasiidata dalam suatuajaringan, yang ditandaiidengan informasi dari header paket data.iKlasifikasi yang tepat terhadap sebuah trafik jaringan sangat penting dilakukan terutama dalam hal disain perancangan arsitektur jaringan, manajemennjaringan dan keamanan jaringan. Analisa terhadap suatu trafik jaringan komputer merupakan salah satu cara mengetahui penggunaan protokol komunikasi jaringan komputer, sehingga dapat menjadi dasar penentuan iprioritas Quality of Service ( QoS ). Dasar didalam pemberian prioritas QoS yaitu dengan menganalisa terhadap data trafik jaringan. Pada penelitian ini melakukan klasifikasi terhadap data capture trafik jaringan yang di olah menggunakan Algoritma K-Neaerest Neighbor (K-NN). Aplikasi yang digunakan untuk capture trafik jaringan yaitu aplikasi wireshark. Hasil observasi terhadap dataset trafik jaringan dan melalui proses perhitungan menggunakan Algoritma K-NN didapatkan sebuah hasil bahwa klasifikasi K-NN memilikiitingkat keakuratan yang sangat tinggi. Hal ini dibuktikan dengan hasil perhitungannyang mencapai nilai 99,14 % yaitu dengann perhitungan k = 3.
Kata Kunci —Network protocol, K-NN, QoS, network capture
-
I. PENDAHULUAN
Padaasaat ini komunikasi data pada jaringan internet mencapai kemajuan yang sangat pesat, sehingga sudah begitu banyak variasi data yang disebarkan melalui internet, yang dulunya hanya melewati paket-paket data biasa, kini sesuai dengan kebutuhan trafik jaringan internet sudah dilewati paket-paket multimedia seperti audio dan video. Hal ini akan berakibat pada meningkatnya trafik data yang dapat menyebabkan penurunan performansi jaringan terutama pada jaringan yang memiliki bandwidth terbatas[1] .
Klasifikasi yang tepat terhadap sebuah trafik jaringan internet sangat penting dilakukan terutama dalam hal disain perancangan iarsitektur jaringan,mmanajemen jaringan dan keamanan jaringan. Klasifikasi yang dilakukan yaitu berdasarkan atas banyaknya tipe aktifitas komunikasi, yang diatur oleh protocol-protokol jaringan. Analisa terhadap suatu trafik jaringan adalah salah satu cara mengetahuiipenggunaanipro-tokol komunikasi jaringan, sehingga dapat menjadiidasar untuk penentuan prioritas suatu trafik jaringan[1] .
Terkait dengan klasifikasi trafik internet, beberapa penelitian telah dilakukan dengan menggunakan metode data mining, penerapan algoritma K-NN untuk klasifikasi trafik jaringan telah diajukan oleh[2], Dimana kinerja sistem aplikasi klasifikasi yang dihasilkan cukup baik, karena penerapan algoritma K-NN memiliki kemudahan yaitu tidak ada persyaratan prosedur pelatihan, dan secara alami mampu menangani sejumlah besar kelas. Selanjutnya, penerapan algoritma Naive Bayes oleh[3], juga mampu membuat klasifikasi yang baik dengan mekanisme penentuan Qos berdasarkan protocol-protokol jaringan yang sering digunakan. Selanjutnya Penerapan algoritma K-NN untuk klasifikasi data wine diajukan oleh[4] , adalah mengklasifikasi minuman wine menggunakan algoritma K-NN, dimana pengklasifikasian wine menggunakan dua cara, yaitu pengukuran obyektif dan pengukuran subyektif. Pengukuran secara obyektif dilakukan dengan cara uji laboratorium berdasarkan senyawa yang terkandung dalam wine tesebut. Sedangkan untuk pengukuran subyektif dilakukan oleh seorang pakar yang ahli dalam menilai langsung karakteristik wine. pengukuran secara subyektif dengan melibatkan pakar yang ahli dalam hal wine. Dan yang terakhir dilakukan oleh, adalah buku referensi yang membahas tentang algoritma K-NN. Dalam bukunya menjelaskan bahwa klasifikasi dengan menggunakan algoritma K-NN memiliki tingkat akurasi yang cukup baik. K-Nearest Neighbor merupakan metode yang mampu memberikan sebuah keputusan dalam bentuk klasifikasi yang terbagi atas kategori tertentu yang dasar pengklasifikasiannya didapat dari hasil perhitungan dan analisa data latih yang ada.
rotokol...... p-ISSN:1693 – 2951; e-ISSN: 2503-2372

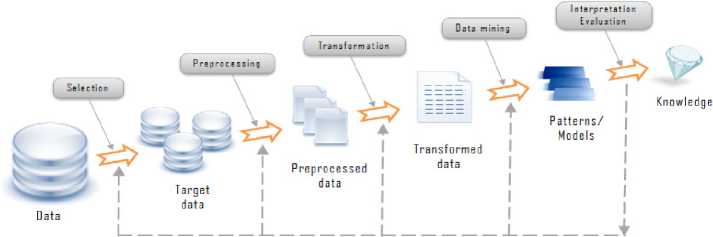
Gambar 1. Tahapan Data Mining
Pemaparan diata menunjukan bahwa penerapan algoritma K-Nearest Neighbor ( K-NN ) adalah solusi yang bisa diterapkan pada mekanisme klasifikasi trafik intenet untuk penentuan prioritas layanan QoS. Selanjutnya, paper ini akan mengevaluasi lebih lanjut kinerja penerapan algorima K-Nearest Neighbor untuk klasifikasi trafik jaringan dengan studi kasus pada trafik internet universitas Udayana. Sasarannya adalah meningkatkan kinerja suatu jaringan dan memudahkan administrator jaringan didalam manajemen suatu jaringan. Mekanisme klasifikasi yang digunakan adalah mengklasifikasi objek baru berdasarkan atribut dan training samples dimana dari data uji yang baruddiklasifikasikan berdasarkan jarak terdekat dalam data pelatihan.
Paper ini diorganiasikan sebagai berikut: bab 1 memaparkan tentang latar belakang dan penggambaran umum lingkup penelitian, bab 2 memaparkan tentang tinjauan pustaka, bab 3 memaparkan tentang metodelogi penelitian, bab 4 memaparkan tentang hasil dan pembahasan, dan bab 5 memaparkan tentang kesimpulan
-
II. ANALISIS DATA MINING
-
A. Data Mining
Han dan Kamber (2006) dalam bukunya yang berjudul “ Data Mining Concepts and Techniques” mengatakan, secara singkat data mining dapat diartikan sebagai mengektraksi atau menggali pengetahuan dari data yang berjumlah besar.
Pada dasarnya data miningbberhubungan erat dengan analisis data, dan penggunaan perangkat lunak untuk mencari pola dan kesamaan dalam sekumpulan data. Ide dasarnya adalah menggali sumber yang berharga dari suatu tempat yang sama sekali tidak diduga, seperti perangkat lunak data mining mengekstrasi pola yang sebelumnya tidak terlihat atau tidak begitu jelas sehingga tidak seorang pun yang memperhatikan sebelumnya. Analisa data mining berjalan pada data yang cenderung terus membesar dan teknik terbaik yang digunakan kemudian berorientasi kepada data berukuran sangat besar untuk mendapatkan kesimpulan dan keputusan paling layak [1]. Berikut merupakan gambaran tahapan data mining yang ditunjukan pada Gambar 1.
Tahapan yang dipresentasikan dalam Gambar 1: mengilustrasikan bagaimana tiap proses bersifatiinteraktif dimana pemakaiantterlibat langsung
-
a) Target data
-
b) pra pemrosesan
-
c) transformasi data
-
d) teknik data mining
-
e) evaluasi pola.
B.
Algoritma K-NN
AlgoritmaaK-NN adalah suatu metode yang mengguna-
kan algoritma supervised, Tujuan dari algoritmaaK-NN adalah untuk mengklasifikasi objek baru berdasarkan atribut dan data sampel. Hasil dari data uji yang baru diklasifikasikaniberda-sarkan mayoritasidari kategori pada K-NN .
Prinsip kerja K-Nearest Neighbor yaitu mencari jarak antara dua titik yaitu titik pelatihan dan titik uji, yang kemudian dilakukan evaluasi dengan K tetangga terdekatnya dalam data pelatihan. Persamaan perhitungan untuk mencari jarak dihitung berdasarkan jarak Euclidean, Correlation, Cosine
dan Cityblock. Pada penelitian ini parameter yang digunakan adalah Euclidean. Rumus menghitung jarak Euclidean sebagai
berikut : dengan mengunakan rumus euclidean [5].
⅛,y]
2^Cα: Yip
(1)
Dimana, d adalah jarak antara titik pada data pelatihan x dan titik data uji y yang akan diklasifikasikan, dimana x = x1, x2, ..., xi dan y = y1, y2,..., yiidan merepresentasikan nilai dari atribut serta n merupakan dimensi data atribut [5]. Langkah-langkah untuk menghitung algoritma K-NN
-
a) Menentukan parameter K ( Jumlah tetangga terdekat )
-
b) menghitung kuadrat jarak Euclid masing-masing objek terhadap data sampel yang diberikan.
-
c) kemudian mengurutkan objek-objek tersebut keda-lam kelompokiyang mempunyaiijarak Euclid terkecil
-
d) mengumpulkannkategori Y ( Klasifikasi Nearest Neighbor )
-
e) dengan menggunakanikategori NearesttNeighbor yang paling mayoritas maka dapat diprediksi nilai queri istance yanggtelah dihitung.
-
C. Pengukuran Kinerja Klasifikasi
Pengujian kinerja sistem klasifikasi pada algoritma K-NN ini dapat dilakukan dengan menggunakan confusion matrix. Confusion matrix ini alat yang berguna untuk menganalisis seberapa baiknya klasifikasi yang kita pakai dapat mengenali pola dari kelas yang berbeda seperti ditunjukan pada Ttable 1.
TABLE I CONFUSION MATRIX
|
fa |
Kelas Prediksi | ||
|
Kelas = 1 |
Kelas = 0 | ||
|
Kelas asli ( i) |
Kelas=1 |
Ai |
Ad |
|
Kelas = 0 |
Ad | ||
A ^L. ITlLGQ CtGtG Cl IDffCi i⅞∣li ffCGΓG CfHGf*
Akurasi =
Jumian prediSsi yaτ.s dιlaκuten
=
At+Ao+Ai+Jiii
(2)
-
III. ANALISIS TAHAPAN PENELITIAN
Pada Tahap ini akan dilakukan analisa bagaimana penerapan algoritma K-NN menggunakan rumus euclidean distance untuk menyelesaikan masalah berupa membagi data sampel (training) dan data uji (testing ),ikemudian data uji diklasifikasi menggunakan k-nearest neighbor. Berikut ilustrasi penggambaran model Klasifikasi secara umum, dapat dilihat pada Gambar 2.

Pengumpulan Data
I ^
Seleksi Data
Cleaning Data
Input Data Training
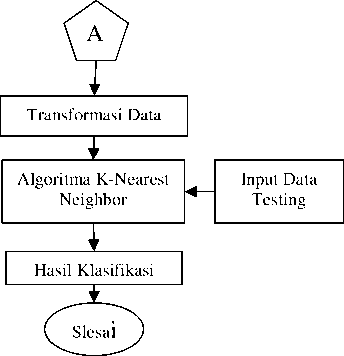
Gambar 2. Metodelogi Penelitian
Berdasarkan tahapan pada Gambar2, maka dapat dijabarkan secara lebih terperinci sebagai berikut :
-
A. Teknik Pengambilan Data Trafik Internet
Pengambilan trafik jaringan menggunakan aplikasi wireshark, menghasilkan kurang lebih hingga puluhan juta record Trafik Jaringan. Model capture trafik jaringan dari wireshark adalah seperti pada Gambar 3.
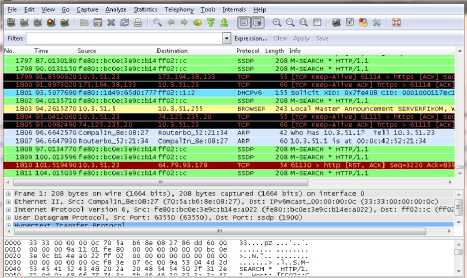
Gambar 3. Trafik Jaringan
-
B. Seleksi Data
Pada tahap ini dilakukanndengan memilihhdata yang akan digunakan sebagai proses penghitungan klasifikasi. Format record dari hasil network capture yaitu berupa data mentah akan diolah dan difilter menggunakan aplikasi Pentaho. Counting dilakukan untuk menghitungirecord traffic yang sama. Pada dataffilter, ffield yang dihitung nanti menggunakan metode K-NN hanya menggunakan field Protocol, Length dan jumlah counting. sehingga dapat dijadikan acuan dalam penentuan QoS dengannmenganalisa jumlah data counting.
-
C. Klasifikasiidengan Algoritma K-NN
Pada tahapan pembentukan klasifikasi menggunakan K-NN adalah dengan menghitung jarak semua variabel pada data uji dengan semua data sampel menggunakan rumus euclidean distance. Selanjutnya setelah nilai jarak euclidean pada data
I Komang Kompyang Agus Subrata : Klasifikasi Penggunaan Protokol.
p-ISSN:1693 – 2951; e-ISSN: 2503-2372
9
772503
237
009
sampel diketahui, maka dapat ditentukan cluster-cluster pada data sampel berdasarkan kedekatan nilai-nilai yang dihasilkan dari perhitungan jarak Euclidean tersebut. Pembentukan klasifikasi akan dilakukan pada pola k berbeda yaitu k=3, k=5, k=7 dan k=9.
Data trafik jaringan yang dipetakan dalam metode K-NN sebagai kelas klasifikasi yang ditunjukan pada Tabel II sebagai berikut :
Data yangidigunakan dalam penelitian ini yaitu sebanyak 6256 data hasil klasifikasi dengan atribut protocol, length, counting, length range dan counting range dan pioritas. Untuk melakukan inisialisasi, penelitian ini mengusulkan model untuk menentukan kelas label seperti dititunjukan pada Tabel III, yaitu sebagai berikut.
TABEL III
MODEL KLAS LABEL
|
TABEL II DATA TRAFIK JARINGAN |
Range |
Prioritas | |||||||
|
Rendah |
Menengah |
Tinggi | |||||||
|
Jenis Protokol |
length Range |
counting Range |
Prioritas |
Length |
33 – 64 65 - 128 |
129 – 256 257 - 512 |
513 - 1024 1025 - 2048 | ||
|
ARP, DHCP, DHCPv6, HTTP, DNS, TCP, ICMP, ICMPv6, IGMP, MNDP MDNS, , NBNS, NTP, SSDP, SSHv2 |
0 – 32, 33 – 64, 65 – 128, 129 – 256, 257 – 512, 513 – 1024, 1025 – 2048 |
0 – 500, 501 – 1000, 1501 – 2000, 2001 – 2500, 2501 – 3000, x > 3000 |
Rendah, Menengah Tinggi |
Counting |
0 - 500 501 - 1000 1001 - 1500 |
1501 – 2000 2001 – 2500 |
2501 - 3000 x > 3000 | ||
|
Seperti ditunjukan pada Tabel III, rentang batas minimum dan maksimum setiap prioritas didasarkan pada hasil data trafik jaringan. Dari aturan model tersebut penelitian ini mengajukan inisialisasi label kelas dalam pemben- | |||||||||
|
tukan data latih yang dilakukan secara manual, seperti ditun-jukan pada Table IV sebagai berikut: | |||||||||
TABEL IV
INISIALISASI KELAS LABEL
|
Protokol |
Length |
Counting |
Length Range |
Counting Range |
Prioritas |
|
ARP |
118 |
6095 |
65 - 128 |
X > 3000 |
Rendah |
|
ARP |
128 |
1743 |
65 - 128 |
1501 - 2000 |
Menengah |
|
ARP |
136 |
8 |
129 - 256 |
0 - 500 |
Menengah |
|
DHCP |
301 |
3 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
320 |
2 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
331 |
1 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
342 |
616 |
257 - 512 |
501 - 1000 |
Menengah |
|
DHCP |
344 |
51 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
346 |
225 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
347 |
3 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
348 |
6 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
349 |
1 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
350 |
2 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
351 |
3 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
352 |
5 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
353 |
1 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
354 |
80 |
257 - 512 |
0 - 500 |
Menengah |
|
DHCP |
355 |
7 |
257 - 512 |
0 - 500 |
Menengah |
|
DNS |
73 |
2754 |
65 - 128 |
2501 - 3000 |
Tinggi |
|
DNS |
74 |
3577 |
65 - 128 |
X > 3000 |
Tinggi |
|
DNS |
75 |
3950 |
65 - 128 |
X > 3000 |
Tinggi |
|
DNS |
76 |
5100 |
65 - 128 |
X > 3000 |
Tinggi |
-
IV. HASIL DAN PEMBAHASAN
-
a. Evaluasi Mekanisme Penelitian
Berikut adalah langkah-langkah perhitungan secara manual atau menentukan prioritas suatu trafik jaringan menggunakan Algoritma K-NN .
-
1. Menghitung jarak total semua parameter pada data training dan data testing dengan menggunakan persamaan (1). Untuk perhitungan beberapa parameter yang digunakan adalah .
-
• Data Sampel yang digunakan sebanyak 5 buah, yang ditunjukan pada Tabel V.
-
• Data Testing dengan data parameter seperti ditunjukan pada Tabel VI.,
Selanjutnya mencari perbandingan jarak terpendek dengan menggunakan persamaan 1, maka dapat dipaparkan sebagai berikut.
D (1) =√(136 - 346)z + (1743 - 225J2
= = 6.81
|
D (2) = √(320 - 346)2 + (2 - 225)2 |
|
= = 26.93 |
D (3) =√(1328 - 346)2 + (4- 225)2
= = 31.83
D (4) = √(333 -346)2 + (123 -225)2
= = 3.25
D (5) = √(340 - 346/ + (196 - 225)2
= = 29.61
Maka didapatkan hasil perbandingan jarak terpendek seperti ditunjukan pada Tabel VII.
-
2. Selanjutnya mengurutkan hasil perhitungan jarak yang diperoleh pada langkah 1 yang mana data tersebut diurutkan berdasarkan jarak terkecil sampai jarak terbesar, seperti yang ditunjukan pada Tabel VIII.
TABEL V
DATA TESTING (UJI)
|
No id |
Protokol |
Lenght |
Counting |
Length Range |
Counting Range |
Prioritas |
|
1 |
ARP |
136 |
1743 |
65 – 128 |
1501- 2000 |
Menengah |
|
2 |
DHCP |
320 |
2 |
257 – 512 |
0 – 500 |
Menengah |
|
3 |
HTTP |
1328 |
4 |
1025 – 204 |
0 – 500 |
Rendah |
|
4 |
DNS |
333 |
123 |
257 – 512 |
0 – 500 |
Menengah |
|
5 |
DNS |
340 |
196 |
257 – 512 |
0-500 |
Menengah |
TABEL VI
DATA SAMPEL (TRAINING)
|
No Id |
Protokol |
Length |
Counting |
Prioritas |
|
1 |
DNS |
346 |
225 |
? |
TABEL VII
DATA HASIL PERHITUNGAN PERBANDINGAN JARAK
|
No id |
Protokol |
Lenght |
Counting |
Length Range |
Counting Range |
Prioritas |
Jarak |
|
1 |
ARP |
136 |
1743 |
65 – 128 |
1501 – 2000 |
Menengah |
6.81 |
|
2 |
DHCP |
320 |
2 |
257 – 512 |
0 – 500 |
Menengah |
26.93 |
|
3 |
HTTP |
1328 |
4 |
1025 – 204 |
0 – 500 |
Rendah |
31,83 |
|
4 |
DNS |
333 |
123 |
257 – 512 |
0 - 500 |
Menengah |
3.25 |
|
5 |
DNS |
340 |
196 |
257 – 512 |
0-500 |
Menengah |
29.61 |
TABEL VIII
DATA YANG TELAH DIURUTKAN
|
No id |
Protoko l |
Lenght |
Counting |
Length Range |
Counting Range |
Prioritas |
Jarak |
|
4 |
DNS |
333 |
123 |
257- 512 |
0 - 500 |
Menengah |
3.25 |
|
1 |
ARP |
136 |
1743 |
65 - 128 |
1501-2000 |
Menengah |
6.81 |
|
2 |
DHCP |
320 |
2 |
257- 512 |
0 - 500 |
Menengah |
26.93 |
|
5 |
DNS |
340 |
196 |
257- 512 |
0-500 |
Menengah |
29.61 |
|
3 |
HTTP |
1328 |
4 |
1025-204 |
0 - 500 |
Rendah |
31,83 |
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

-
3. Menentukan ketetanggaan terdekat untuk mendapatkan prioritas yang cocok dengan data testing.
Berdasarkan hasil perhitungan jarak ditetapkan k = 5, Maka didapatkan hasil : Menengah = 4, Rendah = 1, Maka bisa ditetapkan bahwa, sampel trafik jaringan yaitu dengan length 346 dan counting 225 menghasilkan prioritas Menengah. Seperti ditunjukan pada Tabel IX.
-
B. Hasil Klasifikasi Algoritma K-NN
Berdasarkan hasil pengujian klasifikasi trafik jaringan menggunakan algoritma K-NN pada MATLAB , yaitu menggunakan 6257 sebagai data latih dan 5596 sebagai data uji maka didapatkan hasil seperti ditunjukan pada Tabel X.
Tabel X. menunjukan hasil pengujian yang dilakukan terhadap data baru maka dihasilkan data hasil klasifikasi menggunakan algoritma K-NN menggunakan MATLAB. Bahwa protokol ARP dengan length 60 dan counting 552581 menghasilkan klasifikasi dengan prioritas tinggi.
Hal ini disebabkan karena pengguna internet yang menggunakan protokol ARP lebih sering dengan ukuran length 60 byte oleh karena itu, protokol ARP akan diberikan prioritas tinggi. Dengan diberikan prioritas tinggi kepada pengguna internet maka pengguna internet merasa nyaman menggunakan protokol komunikasi ARP tersebut.
TABEL IX
DATA HASIL KLASIFIKASI
|
No Id |
Protokol |
Length |
Counting |
Prioritas |
|
1 |
DNS |
346 |
225 |
Menengah |
TABEL X
Hasil Klasifikasi Trafik Jaringan menggunakan Algoritma K-NN
3 Variable Editor - res
File Edit View Graphics Debug Desktop Window Help
|
& I * ⅞ ⅛ I ⅛⅛ I «< I ^∣ Stack: Eiase ▼ J L^SP Select data to plot ^ | |||||||
|
3 res <5596x6 cell> | |||||||
|
2 |
1 ARP |
2 60 |
3 552581 |
4 33 - 64 |
5 X > 3000 |
6 Tinggi |
7 |
|
3 |
ARP |
110 |
96 |
65 - 128 |
0 - 500 |
Rendah | |
|
4 |
ARP |
118 |
1920 |
65 - 128 |
1501 - 2000 |
Menengah | |
|
5 |
ARP |
128 |
1058 |
65 - 128 |
1001 - 1500 |
Rendah | |
|
6 |
DHCP |
342 |
249 |
257 - 512 |
0 - 500 |
Menengah | |
|
7 |
DHCP |
343 |
1 |
257 - 512 |
0 - 500 |
Menengah | |
|
8 |
DHCP |
344 |
27 |
257 - 512 |
O - 500 |
Menengah | |
|
9 |
DHCP |
346 |
93 |
257 - 512 |
O - 500 |
M en en g a h | |
|
IO |
DHCP |
347 |
5 |
257 - 512 |
O - 500 |
Menen gah | |
|
H |
DHCP |
348 |
4 |
257 - 512 |
O - 500 |
Menengah | |
|
12 |
DHCP |
350 |
3 |
257 - 512 |
0 - 500 |
M enengah | |
|
13 |
DHCP |
351 |
1 |
257 - 512 |
O - 500 |
Menengah | |
|
14 |
DHCP |
353 |
3 |
257 - 512 |
O - 500 |
Menengah | |
|
15 |
DHCP |
354 |
37 |
257 - 512 |
0 - 500 |
Menengah | |
|
16 |
DHCP |
355 |
1 |
257 - 512 |
0 - 500 |
Menengah | |
|
17 |
DHCP |
356 |
1 |
257 - 512 |
0 - 500 |
Menengah | |
|
18 |
DHCP |
357 |
3 |
257 - 512 |
0 - 500 |
Menengah | |
|
19 |
DHCP |
360 |
2 |
257 - 512 |
0 - 500 |
Menengah | |
|
20 |
DHCP |
362 |
7 |
257 - 512 |
0 - 500 |
Menengah | |
|
21 |
DHCP |
365 |
1 |
257 - 512 |
O - 500 |
M enen gah | |
|
27 |
DHCP |
370 |
4 |
257 - 512 |
O - 500 |
M en ∈n g a h | |
|
23 |
DHCP |
386 |
1 |
257 512 |
O - 500 |
M enen gah | |
|
24 |
DHCP |
414 |
104 |
257 - 512 |
O - 500 |
M enen gah | |
|
25 |
DHCP |
418 |
104 |
257 - 512 |
O - 500 |
Menengah | |
|
26 |
DHCP |
420 |
? |
257 - 512 |
O - 500 |
Menengah | |
|
27 |
DHCP |
421 |
2 |
257 - 512 |
O - 500 |
Menengah | |
|
28 |
DHCP |
422 |
2 |
257 - 512 |
0 - 500 |
Menengah | |
|
29 |
DHCP |
423 |
2 |
257 - 512 |
0 - 500 |
Menengah | |
|
30 |
DHCP |
424 |
8 |
257 - 512 |
0 - 500 |
Menengah | |
|
31 |
DHCP |
427 |
12 |
257 - 512 |
0 - 500 |
Menengah | |
|
32 |
DHCP |
428 |
4 |
257 - 512 |
0 - 500 |
Menengah | |
|
33 |
DHCP |
429 |
6 |
257 - 512 |
0 - 500 |
Menengah | |
|
3.4 |
4 3∩ |
2 |
7S7 - SI 7 |
n - sn∩ |
h>∕1 ^n^n n^K |
___________________________I | |
|
model x [ res x j | |||||||
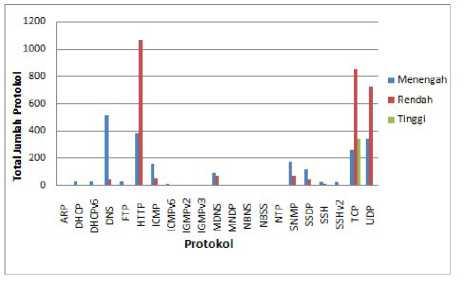
Gambar 4. Banyak protokol berdasarkan prioritas
Dari Gambar 4, dapat disimpulkan bahwa hasil klasifikasiitrafik jaringan dari sisiiprotokol terhadap prioritas menjelaskan bahwa protokol HTTP memiliki tingkat kemunculan yang tinggi maka prioritas yang diberikan oleh sistem adalah prioritas rendah.
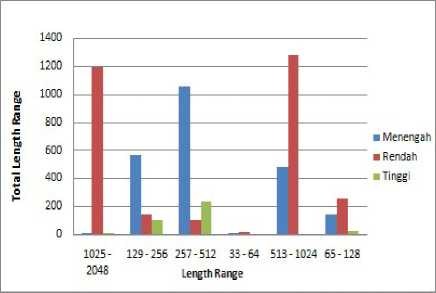
Gambar 5. Banyak length range berdasarkan priorita
Pada Gambar 5. menunjukan bahwa length yang diberikan prioritas rendah yaitu terhadap komunikasi yang memiliki ukuran data dari 1025–2048 byte dan 513 – 1024 byte.
I Komang Kompyang Agus Subrata : Klasifikasi Penggunaan Protokol
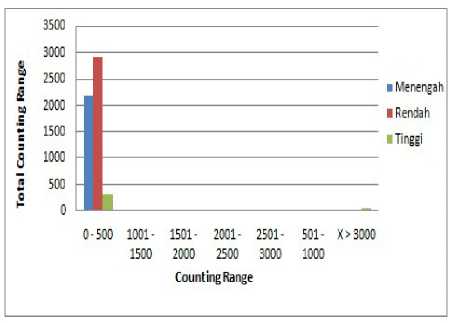
Gambar 6. Banyak Counting Range berdasarkan prioritas
Dari Gambar 6. dapat disimpulkan bahwa counting range 0 – 500 memiliki tingkat kemunculan (banyaknya data record aktifitas yang sama) yang tinggi maka, akan diberikan prioritas rendah pada count range 0 – 500.
-
C. Hasil Akurasi
Pada pengujian ini didapatkan akurasi tertinggi pada K-NN mencapai 99.14% seperti yang ditunjukan pada Tabel XI.
TABEL XI
Hasil Penghitungana akurasi klasifikasi K-NN
|
Data Uji |
Nilai K |
Akurasi |
|
6257 |
3 |
0,9914 |
|
5 |
0,9864 | |
|
7 |
0,9839 | |
|
9 |
0,9824 |
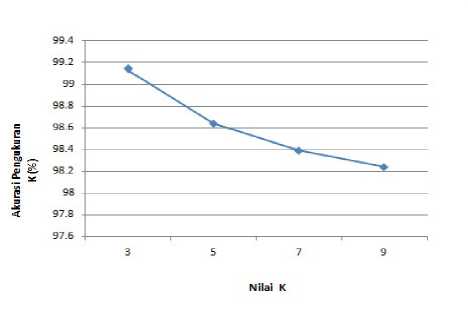
Gambar 5. Pengaruh Nilai k pada 6257 Data Latih
Kesimpulan yang diperoleh yaitu, dari 6257 data uji (testing) kemudian dilakukan pengukuran akurasi dengan menggunakan parameter k yang bereda-beda, maka nilai akurasi yang didapat berbeda-beda, tetapi memilikiinilai akurasi yang hampir sama sehingga didapatkan tingkat akurasi kecocokan tertinggi pada hasil sebenarnya terhadap hasil dari prediksi dengan menggunakan algoritma K-Nearest Neighbor didapatkan pada nilai k = 3, yaituisebesar 99,14 %. Dari grafik diketahui bahwa semakin tinggi jumlah k, maka semakin rendah akurasi yang didapatkan. Hal ini dikarenakan rentang kelas pada k yang semakin banyak memberikan nilai sensi-tifitas yang besar pada penentuan prediksi.
V. KESIMPULAN
Peper ini telah memaparkan sebuah model penentuan klasifikasi trafik internet menggunakan algoritma K-NN dengan inisialisasi yang telah ditentukan. Informasi data trafik internet Universitas Udayana diambil atau diperoleh melalui mekanisme Capture data menggunakan aplikasi perangkat lunak wireshar. Hasil data trafik capture akan diolah dengan
p-ISSN:1693 – 2951; e-ISSN: 2503-2372

proses data maining dengan menggunakan algoritma K-NN. Algoritma K-NN mengklasifikasi Qos berdasarkan tingkat kemiripan data uji dengan data pelatihan.
Berdasarkan analisis data yang telah dilakukan didapatkan sebuah hasil bahwa nilaiiyang dihasilkan oleh klasifikasi K-NN memiliki tingkat keakuratan yang sangat tinggi. Hal ini dibuktikan dari hasil observasi terhadap dataset trafik jaringan UPT PUSKOM Universitas Udayana dan melalui proses perhitungan menggunakan Algoritma K-NN dengan label kelas dan atribut yang telah dipaparkan di pembahasan sebelumnya, didapatkannsebuah hasil bahwa nilai yang dihasilkan oleh klasifikasi K-NN memiliki tingkat keakuratan yang sangat tinggi. Hal ini dibuktikan dengan hasil perhitungan yang mencapaiinilai 99,14 % yaitu dengan perhitungan k = 3.
Besar nilai k dan banyak data training yang digunakan dalam melakukan klasifikasi sangat berpengaruh dalam menentukan hasil klasifikasi. Semakin besar nilai k yang digunakan, maka akan menghasilkan klasifikasi yang tidak jelas dan juga akan menghasilkan kesalahan klasifikasi yang besar.
REFERENSI
-
[1] R. O. Duda, P. E. Hart, and D. G. Stork, Pattern Classification. John Wiley & Sons, 2012.
-
[2] J. Zhang, C. Chen, Y. Xiang, W. Zhou, and Y. Xiang, “Internet Traffic Classification by Aggregating Correlated Naive Bayes Predictions,” IEEE Trans. Inf. Forensics Secur., vol. 8, no. 1, pp. 5–15, Jan. 2013.
-
[3] M. Sudarma and D. P. Hostiadi, “Klasifikasi Penggunaan Protokol Komunikasi Pada Nework Traffic Menggunakan Naïve Bayes Sebagai Penentuan QoS,” Pros. CSGTEIS 2013,2013.
-
[4] “Klasifikasi Data Minuman Wine Menggunakan Algoritma K-Nearest
Neighbor.” [Online]. Available:
https://www.scribd.com/document/317831440/Klasifikasi-Data-Minuman-Wine-Menggunakan-Algoritma-K-Nearest-Neighbor. [Accessed: 12-Jul-2016].
-
[5] W. Hidayat$^1$, E. M. Dharma, and M. A. Bijaksana, “PENERAPAN K-NEAREST NEIGHBOUR UNTUK KLASIFIKASI GAMBAR LANDSCAPE BERDASARKAN FITUR WARNA DAN TEKSTUR,” 2005.
ISSN 1693 – 2951; e-ISSN: 2503-2372 I Komang Kompyang Agus Subrata : Klasifikasi Penggunaan Protokol
Discussion and feedback