Klasterisasi Frequently Asked Question menggunakan K-means Clustering
on
JNATIA Volume 1, Nomor 1, November 2022
Jurnal Nasional Teknologi Informasi dan Aplikasinya
Klasterisasi Frequently Asked Question menggunakan K-means Clustering
Khaerul Anwara1, I Ketut Gede Suhartanaa2
aProgram Studi Informatika, Universitas Udayana Bukit
Jimbaran, Bali, Indonesia
Abstract
Frequently asked questions are an important part of providing good service to customers. information provided in the form of questions and answers related to products, applications, companies that are available in detail, concise and easily accessible .The determination of the format of the frequently asked question list should be based on the questions asked by the customer so that they are relevant to the customer's needs. clustering the list of questions using K-means and TF-IDF as the feature extraction method provides an optimal solution of 50000 list questions divided into 18 clusters with a silhoutte coefficients = 00. each cluster is taken 1 document which will be a question in that category provided that the document has at most the term frequncy of the features on the cluster.
Keywords: Clustering, Frequently Asked Question, K-means,TF-IDF, Information
FAQ singkatan dari frequently asked question adalah daftar informasi pertanyaan yang sering diajukan pengguna dan jawaban terkait produk, apliaksi, perusahan yang tersedia secara detail, ringkas dan mudah diakses. FAQ tersusun atas topik kompleks dan diatur berdasarkan sub-topik yang berfungsi untuk meminimlakan pertanyaan berulang dari pengguna dari sosial media, chat, atau email. Selain itu FAQ juga dapat meningkatkan peringkat SEO pada mesin pencari untuk layanan berbasis website. Penentuan daftar pertanyaan yang sering diajukan dibuat berdasarkan asumsi perusahaan yang didapatkan dari tim customer service atau admin.
Penentuan seperti ini tidak sepenuhnya memuat informasi yang relevan dengan kebutuhan pengguna. Oleh karena itu, diperlukan suatu cara dalam penentuan format pertanyaan yang sering diajukan berdasarkan data pertanyaan yang telah diajukan pengguna. Terdapat berbagai macam cara peenntuan salah satunya dengan klasterisasi daftar pertanyaan menggunakan Kmeans clustering. Algoritma k-means adalah bagian dari metode non-hierarchical data clustering yang bertujuan untuk membagi-bagi data ke dalam bentuk satu atau lebih kelompok[1]. Metode ini menempatkan data ke dalam kelompok yang memiliki titik pusat terdekat dan mempunyai karakteristik sama ditempatkan pada kelompok yang sama, sedangkan jika data memiliki titik pusat yang jauh dan karakteristik berbeda maka dimasukkan ke kelompok yang berbeda.
Algoritma K-means clustering digunakan pada penenlitian [1] menggunakan 3 cluster mendapatkan silhouette coefficient dengan nilai 0,108690751 untuk klasterisasi kinerja akademik mahasiswa. Penelitian [2] membandingkan K-means dan DBSCAN dalam klasterisasi data kesehatan menghasilkan K-means berkerja lebih baik daripada DBSCAN. Sehingga dapat disimpulkan bahwa algoritma K-means dapat menjadi solusi yang optimal dalam menyelesaikan masalah klasterisasi.
Pengumpulan dataset pada penelitian ini menggunakan data train pasangan pertanyaan quora yang diperoleh dari website Kaggle, diakses pada tanggal 28 September 2022 pukul 09:10:30 WITA dengan alamat akses https://www.kaggle.com/competitions/quora-question-pairs/data?select=train.csv.zip. Data ini terdiri dari 6 kolom dan 404289 baris, namun penenlitian ini hanya menggunakan 50000 baris data dan kolom pertanyaan 1. Detail 5 dataset teratas dapat dilihat pada gambar berikut.
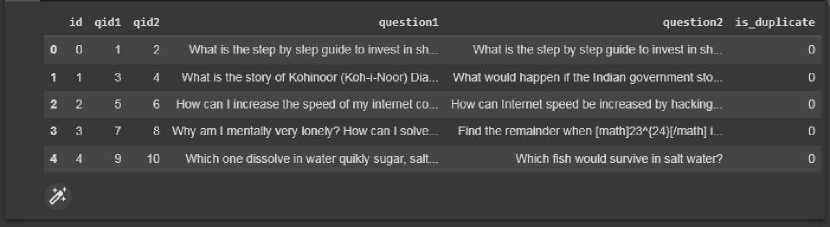
Gambar 2. Detail dataset
-
2.3. Pre-processing Data
Data daftar pertanyaan quora yang telah dikumpulkan akan dipre-processing dengan tahapan case folding, removing punctuation, tokenizing, stopword removal dan stemming. Case folding dilakukan untuk mengubah semua huruf pada data menjadi huruf kecil, proses ini bertujuan untuk membuat kata yang sama jika ditulis dengan huruf berbeda akan menghasilkan nilai yang sama. Setelah semua kata menjadi huruf kecil maka
dilakukan penghapusan karakter-karakter yang tidak termasuk dalam ASCII melalui proses removing punctuation. Tokenizing merupakan proses untuk membagi data kalimat pertanyaan pada setiap baris menjadi kata – kata yang terpisah. Stop word removal adalah proses untuk menghapus kata - kata yang dianggap tidak penting dalam penelitian ini menggunakan stopword bahasa inggris maka yang dihapus kata-kata seperti “by”, “the”, “is”, “do” dan lain lain. Proses text pre-processing terakhir adalah stemming yaitu mengembalikan kata menjadi kata dasar.
Pada tahap ini ekstraksi fitur ini mengubah data tekstual menjadi vector yang dapat diamati jarak kedekatan pada proses klasterisasi. Proses ini menggunakan metode Term Frequency Inverse Document Frequency. Metode TF-IDF merupakan metode untuk menghitung bobot suatu kata (term) terhadap dokumen[3]. Keunggulan yang dimiliki metode yaitu mudah digunakan, efisien waktu, dan menghasilkan fitur yang akurat. Pada metode ini konsep perhitungan bobot frekuensi kemunculan kata dalam dokumen dan inverse frekuensi dokumen yang memiliki kata tersebut. Frekuensi kemunculan menunjukkan seberapa kuat pengaruh kata tersebut di dalam dokumen. Perhitungan TFIDF menggunakan rumus sebagai berikut.
tfidfdt = tfdt idft (1)
Dengan idft diperoleh dari idft = log (_N ) (2)
df
K-means clustering dalam melakukan klasterisasi dokumen pertanyaan yang memiliki makna sama menggunakan beberapa tahapan sebagai berrikut: a. Menginisialisasi jumlah cluster
-
b. Menentukan nilai awal pusat cluster secara acak
-
c. Menentukan nilai kedekatan antara vector dan pusat cluster
-
d. Menempatkan vector ke cluster dengan jarak pusat terkecil
-
e. Menginisialisasi pusat cluster baru
-
f. Menentukan nilai kedekatan anatara vector dan pusat cluster baru sampai vector tidak berpindah cluster
Tahap pengujjian ini digunakan untuk menjadi tolak ukur keberhasilan Metode yang digunakan dalam mengelompokkan data. Dalam pengujian K-means clustering tolak ukur yang digunakan yaitu ketepatan kelompok dan kualitas kelompok. Untuk menentukan ketepatan pengelompokan dan kualitas kelompok menggunakan ketepatan kelompok deret waktu yaitu metode silhouette coefficient[1].
Perhitungan silhoutte coefficient memiliki rentang nilai -1 sampai 1. Ketepatan pengelompokan dikatan baik jika perhitungan bernilai positif yang menunjukkan data berada pada cluster yang sesuai. Sedangkan jika perhitungan bernilai negatif menunjukkan data berada pada cluster yang sesuai sehingga satu data dapat memiliki dua atau lebih cluster. Menurut teori Kaufman dan Rousseeuw[1] hasil perhitungan silhouette coefficient terbagi menjadi empat jenis yaitu:
-
1. Sangat Struktur 0,7 - 1
-
2. Terstruktur 0,5 - 0,7
-
3. Kurang terstruktur 0,25 - 0,5
-
4. Tidak terstruktur ≤ 0,25
Pada penelitian ini, tahap awal adalah pre-processing data meliputi case folding, removing punctuation, tokenizing, stopword removal dan stemming. Hasil pre-processing dapat dilihat pada gambar 3.
id questionl Pre-processing
0 0 Whatisthestepbystepguidetoinvestinsh Stepstepguidinvestsharemarketindia
1 1 What is the story of Kohinoor (Koh-I-Noor) Dia... stori Kohinoor Kohinoor diamond
2 2 How can I inc rease the speed of my internet co.. inc teas speed internet connect use vpn
|
3 |
3 |
Why am I mentally very lonely? How can l solve.. |
mental lone solv | |
|
4 |
4 |
Which one dissolve in Waterquikly sugar, salt. |
one dissolv water quikli sugar salt methan car... | |
|
49995 |
49995 |
How do you take the derivative of [math]∖ftac{.. |
take deriv mathfracx22math | |
|
49996 |
49996 |
How much space does Mac OS X Yosemite take on |
much space mac 0 |
s x yosemit take new mac book |
|
49997 |
49997 |
Why are critehum races pre-arranged and so lu.. |
Criterium race prearrang Iucr | |
-
Gambar 2. Hasil Preprocessing
Hasil pre-processing mengubah semua kata menjadi huruf kecil, menghilangkan karakterkarakter seperti (), -, ?, menghilangkan kata-kata tidak penting, dan mengembalikan kata ke kata dasar.
Data yang telah melewati proses pre-processing diubah ke vector menggunakan metode Term Frequency Inverse Document Frequency. Berikut hasil ekstraksi fitur.
kohinoor
step solv lone mental
vpn connect speed diamond internet
responsel
0.0eθWθ 0.711288 0.000000 0.000000 0.00Θ0βθ 0.000000 0.000000 0.000000 0.000000 0.000000
response2 6.824032 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.412016 0.000000
resρonse3 0.ΘΘΘΘ00 0.ΘΘ0Θ00 0.000000 0.0ΘΘΘ00 θ.000000 0.467608 0.441332 0.441332 0.000000 0.396412
respoπse4 0.000000 0.000000 0.595797 0.595797 0.538564 0.000000 0.000000 0.000000 0.000000 0.000000
responses
0.0
0.θ
0.0
0.e
0.0
0.0
0.0
0.0
0.0
0.0
Gambar 4. Hasil Ekstraksi fitur
Untuk melakukan klasterisasi tahap awal menentukan jumlah klister, pada penelitian ini menggunakan 18 klaster kemudian melakukan pemodelan menggunakan algoritma K-means clustering. Berikut hasil klasterisasi.
|
cluster |
terms |
jumlah | |
|
O |
O |
imrgiri,Ieav,send,even, month, ask, feel,faster,... |
1 |
|
1 |
1 |
attend,CoIIeg1Iike,univers,chines1graduat,pres... |
6 |
|
2 |
2 |
caus,death,earl!,reason,problem,reaction,war,w... |
36 |
|
3 |
3 |
best, way, team, book, India, mo vi, Ia ptop, institut... |
399 |
|
4 |
4 |
modi,narendra,mr,pm,meet,muslim,India,letter,c... |
17 |
|
5 |
5 |
quota,question,answer, ask,improv,need,peopl,ma... |
114 |
|
6 |
6 |
code, learn, app,start,googl1 rule, wrong, creat,wa... |
19 |
|
7 |
7 |
care,fast, blac k, mean,feel,featur,fear,fa vou rit... |
1 |
|
8 |
8 |
increas,height,concentr,21,traffic,skip,way,we... |
31 |
|
9 |
9 |
expens,japan,cheap,colteg,track,becom, water,da... |
6 |
|
10 |
10 |
good, learn,e∩gin,car, make,compa∩i,score,song, s... |
123 |
|
11 |
11 |
note,1000,50D,rupe, ban, rs,currenc, blac k,india∩... |
48 |
|
12 |
12 |
c hang.life Jme,belιev,peopl.year.account.hair... |
41 |
|
13 |
13 |
differ,use,india,peopl, make, life, mean, think, wo... |
4023 |
|
14 |
14 |
like,work,guy,gir1,live,feel1personrlook, women... |
135 |
-
Gambar 5. Hasil Klasterisasi
Berdasarkan hasil pada gambar 5, pertanyaan terkait cluster 0 hanya ditanyakan sekali, cluster 1 ditanyakan 6 kali, cluster 2 hanya ditanyakan 36 kali, cluster 3 hanya ditanyakan 399 kali, cluster 4 hanya ditanyakan 17 kali, cluster 5 hanya ditanyakan 114 kali, cluster 6 hanya ditanyakan 19 kali, cluster 7 hanya ditanyakan sekali, cluster 8 hanya ditanyakan 31 kali, cluster 9 hanya ditanyakan 6 kali, cluster 10 hanya ditanyakan 123 kali, cluster 11 hanya ditanyakan 48 kali, cluster 12 hanya ditanyakan 41 kali, cluster 13 hanya ditanyakan 4023 kali, cluster 14 hanya ditanyakan 135 kali.
Tahap akhir adalah pengujian model yang telah dibuat menggunakan metode silhouette coefficients, berikut hasil pengujian.
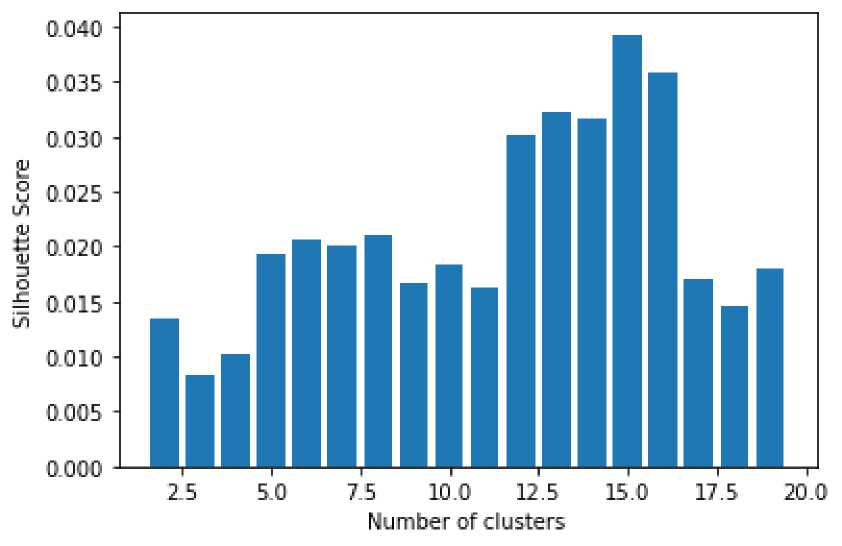
Gambar 6. Hasil Pengujian Silhoutte Coefficients
Berdasarkan grafik pengujian menggunakan rentang jumlah cluster antara 2 sampai 20 didapatkan silhouette coefficients = 0.04 pada jumlah cluster 15.
4. Kesimpulan
Berdasarkan penelitian yang dilakukan, dapat disimpulkan bahwa klasterisasi frequently asked question menggunakan algoritma K-means dan TFIDF mendapatkan silhouette coefficients = 0.04. Hasil klasterisasi tersebut memiliki nilai yang tidak baik karena termasuk dalam kategori nostructure atau data-data pada cluster masih terjadi overlapping.
References
-
[1] Aziz dkk, “Implementasi Algoritma K-Means untuk Klasterisasi Kinerja Akademik Mahasiswa”, Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer Vol. 2, No. 6, Juni 2018, hlm. 2243-2251
-
[2] Godwin Ogbuabor, Ugwoke, F. N, “Clustering Algorithm For A Healthcare Dataset Using Silhouette Score Value”, International Journal of Computer Science & Information Technology (IJCSIT), Vol 10, No 2, April 2018.
-
[3] Ade Riyani , Muhammad Zidny Naf’an , Auliya Burhanuddin, “Penerapan Cosine Similarity dan Pembobotan TF-IDF untuk Mendeteksi Kemiripan Dokumen”, Jurnal Linguistik Komputasional, Vol 2, No 1 Maret 2019.
Halaman ini sengaja dibiarkan kosong
166
Discussion and feedback