Perintah Menggunakan Sinyal Suara dengan Mel-Frequency Cepstral Coefficients (MFCC) dan K-Nearest Neighbor (KNN)
on
JNATIA Volume 1, Nomor 1, November 2022
Jurnal Nasional Teknologi Informasi dan Aplikasinya
Perintah Menggunakan Sinyal Suara dengan Mel-Frequency Cepstral Coefficients (MFCC) dan K-Nearest
Neighbor (KNN)
Gusti Putu Aryo Widano1, Anak Agung Istri Ngurah Eka Karyawati2
aInformatika, Universitas Udayana
Bali, Indonesia
Abstract
Current technological developments allow every action that previously required more energy to complete can be more practical, input to give commands can not only be done with the mouse, keyboard, or touchscreen technology but can also be done with the help of voice. However, before it can be used as a command, the data will be retrieved using a computer first. In this study, two stages will be carried out, namely the voice feature extraction process using Mel-Frequency Cepstral Coefficients (MFCC) and the classification process using the K-Nearest Neighbor (KNN) method. Previously there have been similar studies that have been carried out, where the difference with this research lies in the classification method used previously, whereas previous research used Learning Vector Quantization (LVQ).
Keywords: Voice, Command, Mel-Frequency Cepstral Coefficients (MFCC), K-Nearest Neighbor (KNN), Learning Vector Quantization (LVQ)
-
1. Pendahuluan
Perkembangan teknologi di zaman ini memungkinkan setiap tindakan yang semulanya membutuhkan tenaga lebih untuk menyelesaikannya akan menjadi lebih praktis, salah satunya ketika sebuah masukan untuk memberikan sebuah perintah tidak hanya dapat dilakukan dengan mouse, keyboard ataupun teknologi layer sentuh, tetapi juga dapat dilakukan dengan suara dengan bantuan pemrosesan-pemrosesan data oleh komputer. Banyak teknologi yang memanfaatkan input suara untuk perintah, sebagai contoh google assistent, Alexa, Bixby dan masih banyak lagi teknologi yang memanfaatkan input suara sebagai perintah.
Terdapat beberapa penelitian yang mengangkat topit terkait suara atau voice command diantaranya perintah suara berdasarkan gender [3], pengenalan suara artikulasi p [1], perancangan smart -tv menggunakan perintah suara [2] sistem buka tutup pintu otomatis berbasis suara manusia [9].
Sebelum dapat digunakan sebagai sebuah perintah, suara terlebih dahulu melalui proseses ekstraksi fitur suara dan pembelajaran mesin. Penelitian terdahulu menggunakan 180 data yang diperoleh dari enam naracoba, tiga diantaranya pria dan tiga lainnya adalah perempuan. Hasil akurasi tertinggi yang diperoleh pada penelitian sebelumnya adalah α 0.1 dan penurunan learning rate 0.1, dengan metode klasifikasi yang digunakan adalah Learning Vector Quantization (LVQ).
Pada penelitian ini, akan dilakukan pengujian akurasi terhadap data audio yang didapatkan dari enam naracoba, dengan data yang diperoleh sebanyak 120 data audio dengan format .wav. Dari data tersebut kata kunci yang digunakan adalah “buka” dan “tutup”, masing-masing kata akan dilakukan 10 kali rekaman per orang.
-
2. Metode Penelitian
-
2.1. Akusisi Data
-
Pengambilan data dilakukan secara online dengan menggunakan 2 kata kunci yaitu “buka” dan “tutup”, masing-masing naracoba akan melakukan 10 kali rekaman tiap 1 kata, rekaman melalui fitur voice note lewat whatshapp, dan artikulasi harus diucapkan dengan jelas sehingga mendapatkan data latih yang baik, jumlah data yang diperoleh sejumlah 120 data. Rata-rata durasi rekaman adalah selama 1 detik, dan format data yang digunakan adalah .wav.
MFCC merupakan metode yang digunakan untuk mengekstraksi fitur audio yang banyak digunakan dalam bidang speech technology. Terdapat beberapa tahapan
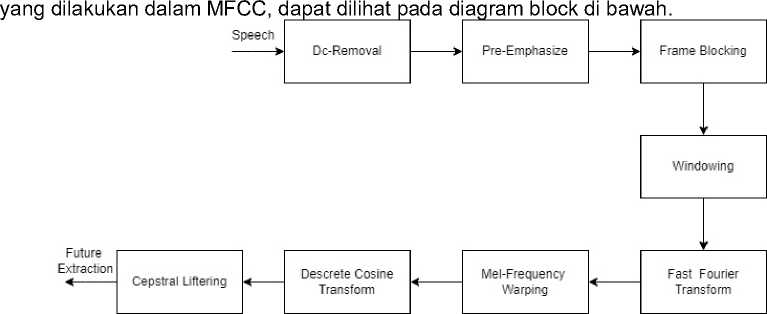
Gambar 1. Ekstraksi menggunakan metode MFCC
Proses ini dilakukan untuk mendapatkan nilai rata-rata serta untuk mengurangi nilai dari setiap sampel dengan nilai rata-rata yang didapat, tujuannya adalah untuk mengeleminasi data yang tidak digunakan. Berikut adalah persamaan dari proses DC Removal.
y[n] = x[n] - x, 0 ≤ n ≤ N — 1 (1)
Dimana:
y[n]= Sample signal hasil DC Removal
x[n] = Sample signal asli
-
x= Nilai rata-rata sample signal
N = Panjang signal
Proses ini dilakukan untuk meminimalisir noise inputan suara, dengan tujuan tingkat akurasi dari proses ekstraksi fitur dapat ditingkatkan. Berikut persamaan dari proses pre emphasize.
I y[n] = s[n]- α.s[n-1],0.9 ' ≤ a ≤ 1.0 ∣ (2)
Dimana :
y[n] = Signal hasil pre-emphasize filter
s[n] = Signal sebelum pre-emphasize filter
-
a = nilai alpha
Proses ini digunakan untuk proses pembagian data menjadi beberapa frame atau slot. Berikut persamaan dari proses frame blocking.
I jumlah frame = Ts/M ∖ (3)
Dimana:
Ts = Durasi pengambilan suara (ms) M = Panjang Frame (ms)
2.2.4. Windowing
Proses ini digunakan untuk meminimalisir discontinuitas sinyal pada awal dan akhir setelah dilakukan proses frame blocking. Berikut persamaan dari proses windowing.
I x(n) = xi(n)w(n∏ (4)
Dimana:
x(n) = nilai sample signal hasil windowing xi(n) = nilai sample signal dari frame signal ke-i w(n)= fungsi window
Proses ini digunakan untuk melakukan perubahan terhadap domain waktu menjadi domain frekuensi. Berikut persamaan dari proses FFT.
Dimana:
ΣN-1
y^M^W,n = 0,1,2,...,N -1
k≡α______________________________
(5)
f(n)=Frekuensi
N= Jumlah sample pada masing-masing frame k=0, 1, 2, ..., (N-1)
J=Bilangan Imajiner (√-1)
2.2.6. Mel Frequency Warping
Proses ini dilakukan menggunakan filterbank yang dapat dilihat pada persamaan berikut.
Melf f =
2595 *log10(1 + ^)
Si _2_
(6)
Dimana:
Si = Sinyal awal hasil FFT f= fo-f
2.2.7. DCT
Proses yang digunakan untuk menghitung mel spectrum untuk dapat menghasilkan representasi yang baik dari spektral suara. Berikut merupakan persamaan dari proses DCT.
k
cn = ∑(logSk)cosn[n(k--)^]; n = 1,2,...,K
______k=1________________________________________________
Dimana:
Sk = Keluaran dari proses filterbank pada index k K= Jumlah Koefisien
(7)
2.2.8. Cepstral Filtering
Proses yang digunakan untuk meningkatkan kualitas pengenalan suara, sekaligus merupakan proses terakhir pada tahapan MFCC. Berikut merupakan persamaan dari proses cepstral filtering.
W[n] = {1 + 2 sin(jκ) n = 1,2, .,l}
(8)
Dimana:
L = Jumlah cepstral Coefficients
N = Index dari cepstral coefficients
-
2.3. K-Nearest Neighbor
Algoritma K-Nearest Neigbhor merupakan algoritma yang digunakan untuk melakukan proses klasifikasi data yang bekerja relatif menggunakan cara yang lebih sederhana dibandingkan dengan metode pengklasifikasian data lainnya. Metode ini akan melakukan proses klasifikasi terhadap data baru yang belum diketahui class-nya dengan cara memilih data sejumlah k yang letaknya paling dekat dengan data baru tersebut. Untuk menentukan class yang nantinya diprediksi untuk data baru adalah dengan cara mencari class terbanyak dari data terdekat sejumlah k.
Dengan demikian K-NN mengambil keputusan yaitu data baru d merupakan anggota dalam class C berdasarkan beberapa tetangga terdekat dari d. Berikut persamaan yang dapat digunakan untuk menentukan dekat atau jauhnya tetangga dari data yang dimiliki, yaitu.
(9)
^ √(ll — ⅛1)2 + (^2 — ⅛2)2 +----+ (<⅛ - ⅛)2
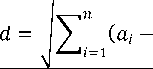
bl )2
(10)
Klasifikasi K-NN dilakukan dengan mencari k-buah tetangga terdekat dan memilih kelas dengan kl terbanyak pada kelas ωl.
-
3. Hasil dan Pembahasan
Data yang digunakan dalam penelitian ini berjumlah 120 data yang diperoleh dari enam naracoba, kata yang di rekam adalah dengan kata kunci “buka” dan “tutup”, masing-masing kata dilakukan perekaman sebanyak 10 kali pengulangan. Rata-rata durasi perekaman adalah 1 detik, dan format file yang digunakan adalah .wav.
Pada penelitian sebelumnya jumlah data yang digunakan sebanyak 180 dengan 3 kata kunci, yaitu “klasik”, “dangdut”, “pop”, dan masing-masing kata akan dilakukan perekaman sebanyak 10 kali. Proses klasifikasi menggunakan algoritma LVQ dengan akurasi tertinggi yang diperoleh adalah α 0.1, dan penurunan learning rate 0.1, oleh karena itu parameter pelatihan LVQ yang digunakan yaitu α 0.1, dengan maksimum epoch 1000, minimum learning rate 0.0001, dan pengurangan α 0.1. Berikut adalah table dari hasil pengujian dari penelitian sebelumnya.
Table 1. Hasil Pengujian Sistem
|
No |
Naracoba |
Kelas |
Jumlah Data |
Jumlah Data Tepat Dikenali % | |
|
DL |
DB | ||||
|
1 |
Naracoba 1 |
Klasik |
10 |
100 |
90 |
|
2 |
Naracoba 1 |
Dangdut |
10 |
100 |
90 |
|
3 |
Naracoba 1 |
Pop |
10 |
100 |
70 |
|
4 |
Naracoba 2 |
Klasik |
10 |
70 |
30 |
|
5 |
Naracoba 2 |
Dangdut |
10 |
100 |
30 |
|
6 |
Naracoba 2 |
Pop |
10 |
100 |
50 |
|
7 |
Naracoba 3 |
Klasik |
10 |
90 |
60 |
|
8 |
Naracoba 3 |
Dangdut |
10 |
100 |
50 |
|
9 |
Naracoba 3 |
Pop |
10 |
70 |
50 |
|
10 |
Naracoba 4 |
Klasik |
10 |
90 |
30 |
|
11 |
Naracoba 4 |
Dangdut |
10 |
100 |
30 |
|
12 |
Naracoba 4 |
Pop |
10 |
90 |
60 |
|
13 |
Naracoba 5 |
Klasik |
10 |
100 |
30 |
|
14 |
Naracoba 5 |
Dangdut |
10 |
100 |
20 |
|
15 |
Naracoba 5 |
Pop |
10 |
70 |
30 |
|
16 |
Naracoba 6 |
Klasik |
10 |
90 |
90 |
|
17 |
Naracoba 6 |
Dangdut |
10 |
100 |
10 |
|
18 |
Naracoba 6 |
Pop |
10 |
80 |
- |
|
Rata-rata akurasi |
92 |
46 | |||
-
4. Kesimpulan
Dari penelitian yang dilakukan oleh Nurhamidah, N., Djamal, E.C., dan Ilyas, R., dengan judul penelitian tentang Perintah Menggunakan Sinyal Suara dengan Mel-Frequency Cepstrum Coefficients dan Learning Vector Quantization, dapat ditarik kesimpulan dengan menggunakan maksimum epoch 1000, minimum learning rate 0.0001, α 0.1 dan terdapat pengurangan α 0.1 dari total 180 data uji yang telah dilatih dan menghasilkan akurasi sebesar 92% dengan hasil pengenalan 165 data dikenali dan 15 data tidak dikenali. Dan untuk pengujian data baru menghasilkan akurasi 46% dan data yang berhasil dikenali sebanyak 84 data dan 96 data lainnya tidak dikenali.
References
-
[1] A. Anggoro, S. Herdjunanto dan R. Hidayat, “MFCC dan KNN untuk Pengenalan Suara Artikulasi P”, Avitec, vol. 2, no. 13-17, 2020.
-
[2] A. K. Saputro, M. Ulum, A. Karim and R. Alfita, “Perancangan Smart-TV Menggunakan Perintah Suara dengan Metode Hidden Markov Model”, Jurnal Teknik Elektro dan Komputer Triac, vol. 7, no.2, p. 1-3, 2020.
-
[3] C. Adipradana, T. S. Pamungkas and A. W. Hidayat, “Analisis Spektrum Perintah Suara Berdasarkan Gender menggunakan Algoritma K-Nearest Neighbors”, Tecnoscienza, vol. 4, no. 1, p. 142-146, 2019.
-
[4] E. Susanti1, S. M. A. Sasongko2 and I. G. P. Suta, “Klasifikasi Suara Berdasarkan Usia Menggunakan Mel-Frequency Cepstral Coefficient (MFCC) dan K-Nearest Neighbor (K-NN)”, Dielektrika, vol. 4, no.2, p. 120-126, 2017.
-
[5] F. D. Septria, J. Raharjo and N. Ibrahim, “Klasifikasi Emosi Berdasarkan Sinyal Suara Manusia Menggunakan Metode K-Nearest Neighbor (K-NN)”, e-Proceeding of Engineering, vol.6, No. 2, p. 6-8, 2019.
-
[6] F. N. Suciani, E. C. Djamal, R. Ilyas. “Identifikasi Nama Surat Juz Amma dengan Perintah Suara Menggunakan MFCC dan Backpropagation”, Seminar Nasional Aplikasi Teknologi Informatika (SNATi), p. 19-20, 2018.
-
[7] I. G. Harsemandi, M. Sudarma and N. Pramaita, “Implementasi Algoritma K-Nearest Neighbor pada Perangkat Lunak Pengelompokan Musik untuk Menentukan Suasana Hati”, Teknologi Elektro, vol. 16, no.1, p. 17-19, 2017
-
[8] I. S. Permana, Y. I. Nurhasanah, A. Zulkarnain. “Implementasi Metode MFCC dan DTW untuk Pengenalan Jenis Suara Pria dan Wanita”. MIND Jurnal, vol. 3, No. 1, p. 49-63, 2018.
-
[9] L. Fitria, K. Muttaqin and M. S. Nasution. “Implementasi Speech Recognition pada Kata Kerja Dasar Menggunakan Metode MFCC”, Jurnal Informatika dan Teknologi Komputer, vol. 2, No. 1, p. 43-50, 2021.
-
[10]
. Nurhamidah and E. C. Djamal, “Perintah Menggunakan Sinyal Suara dengan Mel-Frequency Cepstrum Coefficients dan Learning Vector Quantization” Seminar Nasional Aplikasi Teknologi Informasi, ISNN: 1907 – 5022, p. 11-14, 2017.
-
[11]
. Hartayu, C. Anam and D. A. Aziz, “Simulasi Kestraksi Fitur Suara Menggunakan Mel-Frequency Cepstrum Coefficient”, Jurnal Sains dan Informatika, vol. 8, no. 1, p. 83-85, 2022. [12]
. Ariyanti, S. S. Adi and S. Purbawanto, “Sistem Buka Tutup Pintu Otomatis Berbasis Suara Manusia” Electronics, Informatics, and Vocational Education (ELINVO), vol. 3, no. 1, p. 8391, 2018.
-
[13] Safriadi. 2020. “Klasifikasi Gender Berdasarkan Suara dengan Naïve Bayes dan Mel Frequency Cepstral Coefficient”. Vocational Education and Tehnology (VOCATECH), vol. 2, No.1, pp. 19-26, 2020.
-
[14] W. Muldayani, A. R. Chaidir, G. D. Kalando and C. S. Sarwono. “Pengendali Robot Lengan Berbasis Perintah Suara Menggunakan MFCC dan ANN”. Seminar Nasional Teknik Elektro, 2017.
-
[15] Y. Fatman and Islamiyati. “Pengenalan Suku Kata Bahasa Indonesia Menggunakan LPC dan Backpropogation Neural Network”. Journal of Information Technology and Computer Science (Jointecs). Vol. 5, No. 3, pp. 155-166, 2020.
120
Discussion and feedback