Analisis Clustering Paket Data Internet di Indonesia Menggunakan Metode K-Means
on
JNATIA Volume 1, Nomor 1, November 2022
Jurnal Nasional Teknologi Informasi dan Aplikasinya
Analisis Clustering Paket Data Internet di Indonesia Menggunakan Metode K-Means
I Putu Ananta Wijayaa1, I Gede Santi Astawaa2
aProgram Studi Informatika, Universitas Udayana Badung, Indonesia
Abstract
Disruption of technology and the impact of the recent pandemic has made people access the internet longer than before, especially with smartphones. Before accessing the internet, users must purchase a data package provided by an internet service provider. Various data packages are provided by internet service providers. Starting from network coverage, speed, number of quotas, active period, to tariffs are the choices of each operator. These various offerings often make users confused because they have to adjust to economic conditions. The existence of knowledge analysis in the database, grouping data packets can be done using the k-means method. K-means groups data by iterating and creating groups based on the closest distance of the data to the center point. K-means is very widely used because of its simplicity. Before clustering, the data will go through a preprocessing process. The end result is four clusters that have their own characteristics. For example, cluster four has the characteristics of a small quota with a long active period, which is suitable for the typical community who only wants to stay connected to the internet for communication.
Keywords: K-means, Internet Quota, Clustering, Internet Provider Indonesia, Data Mining
Internet menghubungkan banyak orang di seluruh dunia. Di Indonesia, 19,5% masyarakatnya menghabiskan waktu lebih dari 8 jam sehari untuk mengakses internet. Hal ini dibuktikan dengan hasil survei Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) periode 2019-kuartal II/2020. Ditambah lagi, pandemi Covid-19 yang mendisrupsi cara kerja masyarakat menjadi online, membuat internet seakan-akan menjadi kebutuhan primer. We Are Social menyebutkan terjadi peningkatan sebesar 2,1 juta pengguna internet pada Januari 2022 dibandingkan tahun sebelumnya. Per Januari 2022, terdapat 205 juta pengguna internet di Indonesia, yaitu 73,7% dari populasi Indonesia yang telah menggunakan internet. We Are Social juga menyebutkan 94,1% pengguna internet Indonesia mengakses internet menggunakan handphone[2].
Salah satu cara mengakses internet adalah melalui penyedia layanan internet. Banyak penyedia layanan internet di Indonesia. Sebelum mengakses internet, pengguna harus membeli paket data yang disediakan oleh penyedia layanan internet. Akibat kebutuhan internet meningkat pesat, kebutuhan paket data atau kuota internet pun semakin besar. Beragam paket data pun disediakan oleh penyedia layanan internet. Mulai dari cakupan jaringan, kecepatan, jumlah kuota, masa aktif, hingga tarif menjadi pilihan masing-masing operator (penyedia layanan internet). Dengan beragamnya skema tarif internet yang ditawarkan dan penyedia layanan internet yang ada, terkadang pelanggan justru bingung memilih paket data yang ada.
Salah satu langkah analisis dalam penemuan pengetahuan di dalam basis data adalah data mining. Pengetahuan yang dimaksud adalah pola data atau relasi antar data yang tidak diketahui sebelumnya. Dapat dikatakan, data mining adalah teknik analisis data untuk mendapatkan informasi yang tersembunyi dari data yang kompleks dalam jumlah besar. Salah satu tugas data mining berdasarkan fungsionalitasnya adalah clustering (klasterisasi)[3]. Clustering merupakan metode analisis yang bersifat tanpa arahan (unsupervised) yang bertujuan mengelompokkan data sesuai dengan ukuran kemiripannya. Salah satu algoritma pengelompokkan data adalah k-
means. K-means digunakan karena memiliki kelebihan yaitu implementasi algoritma yang mudah, waktu komputasi yang relatif cepat dan telah digunakan secara luas untuk menyelesaikan berbagai persoalan komputasi[4]. Implementasi algoritma k-means dimulai dengan memilih k objek data secara acak sebagai titik pusat (centroid) awal, memasukkan setiap objek yang bukan centroid ke klaster terdekat berdasarkan ukuran jarak, memperbaharui setiap centroid berdasarkan rata-rata dari objek yang ada di setiap klaster, iterasi ulang hingga centroid stabil [5].
Penelitian tentang clustering sebelumnya pernah dilakukan oleh Y. Darmi, dkk(2022) menggunakan klasterisasi dalam mengelompokkan penjualan produk menjadi dua klaster, yaitu produk yang laku dan tidak laku. Selain itu, disimpulkan semakin banyak data di input, maka centroid yang dapat terbentuk semakin banyak[6]. Z. Mustakim, dkk(2021) dalam mengelompokkan kualitas manajemen pendidikan sekolah di Indonesia, dimana mengelompokkan provinsi dengan hasilnya terdapat tiga klaster dengan karakteristik berupa kategori pendidikan yang baik, sedang, dan kurang[7]. Penelitian kali ini mengelompokkan paket data internet menggunakan metode k-means. Hasil dari penelitian ini berupa beberapa klaster dengan karakteristiknya masing-masing. Karakteristik ini bisa digunakan untuk menentukan paket data yang sesuai dengan kebutuhan pembeli.
Penelitian ini bekerja dengan pendekatan kuantitatif dan menggunakan data sekunder yang didapat melalui internet, dengan mengakses website resmi penyedia layanan internet. Data yang didapatkan adalah tarif paket data penyedia layanan internet di Indonesia khususnya untuk pengguna mobile yaitu Tri, Indosat Ooredoo, XL, Axis, Telkomsel, dan Smartfren. Karakteristik data dapat dilihat pada Tabel 1.
Tabel 1. Karakteristik Data Paket Data Internet
|
Provider |
Nama Paket |
Besar Kuota (GB) |
Masa Aktif (Hari) |
Pembagian Waktu Kuota (Ya/Tidak) |
Harga |
4G only (Ya/Tida k) |
Pembagian Kuota ke App Khusus (Tiktok, Facebook, Webex, dll) |
|
3 |
Happy 2GB 1 Hari |
2 |
1 |
Tidak |
4000 |
Tidak |
Tidak |
|
3 |
Happy 7GB 1 Hari |
7 |
1 |
Tidak |
10000 |
Tidak |
Tidak |
|
3 |
Happy 7GB 3 Hari |
7 |
3 |
Tidak |
15000 |
Tidak |
Tidak |
|
3 |
Happy 11GB 30 Hari |
11 |
30 |
Tidak |
30000 |
Tidak |
Tidak |
|
XL |
Xtra On 17GB PB |
17 |
mengikuti masa kartu |
Tidak |
88946 |
Tidak |
Tidak |
|
XL |
Xtra On 20GB PB |
20 |
mengikuti masa kartu |
Tidak |
93862 |
Tidak |
Tidak |
|
Telkomsel |
Telkomsel 4 GB/30 Hari |
4 |
30 |
Tidak |
50300 |
Tidak |
Tidak |
|
Telkomsel |
Telkomsel 5 GB/30 Hari |
5 |
30 |
Tidak |
56550 |
Tidak |
Tidak |
|
Axis |
3 |
60 |
Tidak |
32485 |
Tidak |
Tidak | |
|
Axis |
5 |
60 |
Tidak |
48465 |
Tidak |
Tidak | |
|
Indosat |
Indosat Data Pure 100 MB 30 Hari |
0.1 |
30 |
Tidak |
1200 |
Tidak |
Tidak |
|
Smartfren |
Unlimited Nonstop 6 GB 30 Hari |
6 |
30 |
Tidak |
29500 |
Tidak |
Ya |
Total data yang didapatkan sebanyak 233 baris dengan kolom data berupa nama provider, nama paket, besar kuota, masa aktif, pembagian waktu kuota, harga kuota, cakupan paket (4G saja/tidak), dan pembagian kuota ke aplikasi lain. Data yang diberikan adalah harga paket data provider internet Indonesia per September 2022.
2.2 Flowchart Penelitian
Flowchart algoritma k-means dapat dilihat pada gambar 1.
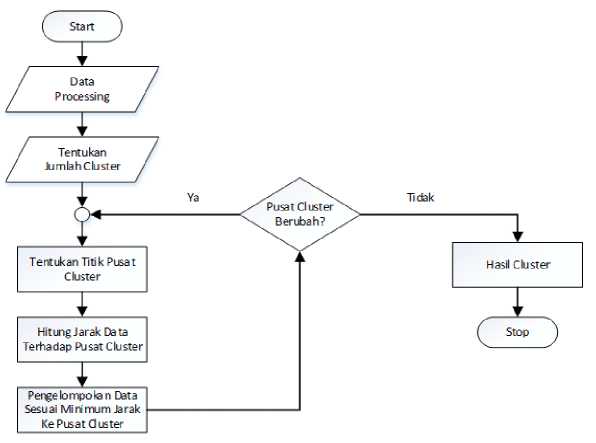
Gambar 1. Flowchart k-means [7]
Algoritma k-means adalah algoritma pengelompokan iteratif yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal. K-means dapat diterapkan pada data yang direpresentasikan dalam r-dimensi ruang[8]. K-means digunakan ketika terdapat data yang belum berlabel (berkategori). Data akan di klasterisasi berdasarkan kesamaan fiturnya. Perhitungan k-means dapat dilakukan dengan langkah-langkah berikut:
-
1. Data Processing
Pada tahap ini dilaksanakan pembersihan data berupa membersihkan data yang duplikat, data yang tidak relevan dan error, kolom yang tidak diperlukan, data yang tidak konsisten, dan outliers. Selain itu, pada tahap ini dilakukan penanganan terhadap data yang hilang, integrasi data, transformasi data, dan reduksi data.
-
2. Tentukan Jumlah Cluster
Algoritma k-means bergantung pada pencarian jumlah cluster dan label data untuk nilai K yang telah ditentukan sebelumnya. Untuk mendapatkan jumlah cluster dalam data, jalankan k-means untuk nilai K dan membandingkan hasilnya. Setelah itu, dipilih nilai K yang optimal (memberikan kinerja terbaik). Ada berbagai teknik yang tersedia dalam menemukan nilai K, salah satu yang paling umum adalah metode elbow.
-
• Metode Elbow
Metode ini memplot nilai fungsi biaya yang dihasilkan oleh nilai K yang berbeda. Secara sederhana, metode ini melakukan perulangan beberapa kali dengan meningkatkan jumlah cluster (misalnya dari 1 hingga 10) dan melakukan plot skor pengelompokan sebagai fungsi dari jumlah cluster. Skor pengelompokan
adalah jumlah kuadrat jarak sampel ke pusat klaster terdekat. Elbow adalah titik pada plot yang nilai pengelompokannya jatuh ke bawah dan nilai cluster pada titik plot memberikan nilai optimum.
-
3. Tentukan Titik Pusat Cluster
Titik pusat cluster dibangkitkan secara acak dari beberapa objek yang tersedia sebanyak jumlah dari k cluster. Untuk menghitung titik pusat cluster ke-i, rumus yang digunakan sebagai berikut.
Σ xi (1)
v = -i≡^- i = 1, 2, 3, ...n
Keterangan
v = titik pusat cluster
xi = objek ke-i
n = banyaknya jumlah objek yang menjadi anggota cluster
-
4. Hitung Jarak Data Terhadap Pusat Cluster
Perhitungan jarak data terhadap pusat cluster dilakukan dengan rumus euclidean distance :
lKx∙ y) ~ ∖x ~ y∖ ~ ^∖∣ ∑ ^χi - ^ ^ i ~ ^' 2, 3, -n (2)
Keterangan
xi = objek ke-i
yi = data y ke-i
n = banyaknya objek
-
5. Pengelompokkan Data sesuai Minimum Jarak Ke Pusat Cluster
Setelah mendapatkan jarak minimum ke pusat cluster, kelompokkan data ke pusat cluster terdekat.
-
6. Lakukan Iterasi
Lakukan iterasi ke-i, ulangi langkah c - e. Perulangan akan berhenti jika rasio tidak lebih besar dari nilai rasio sebelumnya hingga hasil perhitungan di masing-masing data konvergen.
-
3. Hasil dan Pembahasan
-
3.1 Preprocessing Data
-
Pada tahap ini, dilakukan penghapusan kolom yang tidak digunakan saat klasterisasi. Kolom yang dihapus adalah nama provider, pembagian waktu kuota, cakupan paket (4G saja/tidak), dan pembagian kuota ke aplikasi lain. Sehingga kolom yang tersisa adalah nama paket, harga paket, masa aktif, harga paket. Kolom (fitur) ini sudah cukup menjadi indikator utama pertimbangan pelanggan akan membeli paket data tersebut. Selain itu, terdapat dua baris data yang dihapus karena isinya tidak lengkap. Terdapat nilai yang tidak relevan pada data kolom masa aktif karena terdapat paket yang mengikuti masa aktif, akibatnya ditulis “mengikuti masa aktif”. Dilakukan perubahan terhadap data tersebut menjadi 60 hari karena nilai tertinggi data lain ada pada 60 hari serta masa aktif kartu berada pada kisaran 60 hari jika tidak diisi ulang.
|
49 |
Tri 30GB 24 Jam |
30 |
30 |
65,000.00 |
|
50 |
Tri 65GB 24 Jam |
65 |
30 |
100,000.00 |
|
51 |
Tri Rp 25.000 | |||
|
52 |
Rp 10.000 | |||
|
53 |
Tri IlOGB 24 Jam |
110 |
30 |
130,000.00 |
|
54 |
Tri (NEW) 40GB 30 Hari |
40 |
30 |
70,000.00 |
|
55 |
Xtra Combo Mini 1.5GB |
1.5 |
7 |
9,600.00 |
|
56 |
Xtra Combo Mini 2.5GB |
2.5 |
7 |
13,650.00 |
Gambar 2. Dataset Tidak Lengkap
|
31 |
∏AON Full 40GB |
40 |
mengikuti masaak |
99,000.00 |
|
32 |
∣AON Unlimited 26GB |
26 |
30 |
73,000.00 |
|
33 |
Iaon Full 12gb |
12 |
mengikuti masaak |
55,000.00 |
|
34 |
Iaon Full ogb |
9 |
mengikuti masaak |
45,000.00 |
|
35 |
Iaon fu∣i θgb |
6 |
mengikuti masaak |
31,000.00 |
|
36 |
∏AON Full 3.5GB |
3.5 |
mengikuti masaak |
21,000.00 |
|
37 |
Iaon Full 2.sgb |
2.5 |
mengikuti masaak |
15,500.00 |
|
38 |
I Home 15OGB |
150 |
30 |
150,000.00 |
Gambar 3. Dataset pada Kolom Masa Aktif Tidak Relevan
Selain itu dilakukan pengecekan terhadap outlier, dimana bisa dilihat dengan cara mencari mean, median, dan modus, serta melihat hasil visualisasinya.
[32]:
df.describe()
Besar Kuota (GB) Masa Aktif (Hari) Harga
|
count |
231.000000 |
231.000000 |
231.000000 |
|
mean |
20.191775 |
27.008658 |
59609.965308 |
|
std |
31.139864 |
14.365415 |
56752.279439 |
|
min |
0.100000 |
1.000000 |
1200.000000 |
|
25% |
3.000000 |
28.000000 |
16212.500000 |
|
50% |
7.500000 |
30.000000 |
45675.000000 |
|
75% |
24.000000 |
30.000000 |
86180.000000 |
|
max |
235.000000 |
60.000000 |
450000.000000 |
Gambar 4. Deskripsi Dataset
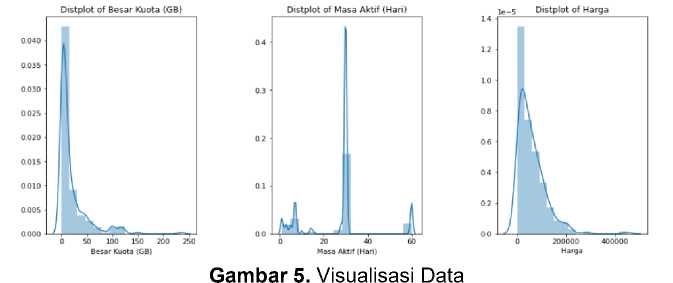
Dari kedua gambar di atas, kolom besar kuota dan harga memiliki outlier. Pada gambar 5 ditunjukan oleh nilai means/75% sangat jauh dengan max. Pada gambar 6 ditunjukkan oleh adanya persebaran data yang tidak merata. Oleh karena itu, dilakukan penghapusan data yang memiliki outliers. Untuk mendeteksi outliers menggunakan pendekatan standar deviasi, yaitu hapus nilai-nilai yang merupakan sejumlah standar deviasi dari rata-rata, jika data memiliki distribusi Gaussian. Praktik industri yang umum adalah menggunakan 3 standar deviasi dari mean untuk membedakan outlier dari non-outlier. Dengan menggunakan 3 standar deviasi dapat menghapus data ekstrim sebanyak 0,3%. Hasilnya, jumlah baris data berubah menjadi 221 baris dengan nilai max yang berubah juga.
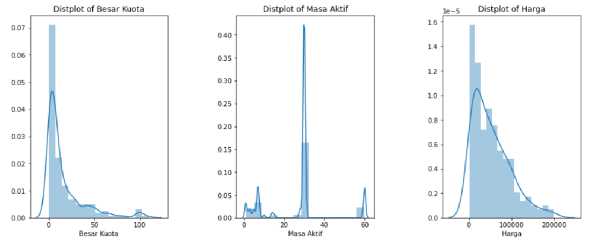
Gambar 6. Visualisasi Dataset Setelah Penghapusan Outliers
|
Besar Kuota |
Masa Aktif |
Harga | |
|
count |
221.000000 |
221.000000 |
221.000000 |
|
mean |
16.164253 |
26 882353 |
52875.823529 |
|
&td |
21.925275 |
14.675109 |
43723.693124 |
|
min |
0.100000 |
1.000000 |
1200.000000 |
|
25% |
3.000000 |
28.000000 |
15500.000000 |
|
50% |
7.000000 |
30.000000 |
44505.000000 |
|
75% |
20.000000 |
30.000000 |
78410.000000 |
|
max |
110.000000 |
60.000000 |
199360.000000 |
Gambar 7. Deskripsi Dataset Setelah Penghapusan Outliers
Tabel 2. Hasil Preprocessing Data
|
Nama Paket Data |
Besar Kuota (GB) |
Masa Aktif (Hari) |
Harga (Rp.) |
|
XL Data Pure 4GB |
4 |
30 |
34050 |
|
Telkomsel 12 GB/30 Hari |
12 |
30 |
103105 |
|
Bronet 8 GB 30 Hari |
8 |
30 |
43850 |
|
Happy 2GB 1 Hari |
2 |
1 |
4000 |
|
Freedom Internet 6,5 GB 30 Hari |
6.5 |
30 |
36125 |
|
Unlimited FUP 500 MB/Hari 28 Hari |
14 |
28 |
50845 |
Penentuan jumlah cluster dilakukan menggunakan metode elbow. Konfigurasi yang digunakan adalah maksimal iterasi per kluster adalah 300. Hasilnya bisa dilihat pada gambar 8. Dari gambar, terlihat nilai yang bisa digunakan (perbedaan sudut garis) adalah 4 cluster.
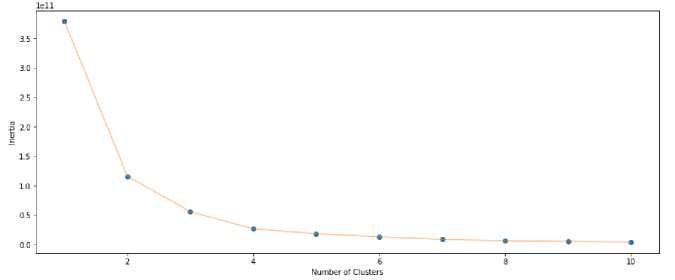
Gambar 8. Grafik Metode Elbow
Dengan menggunakan algoritma k-means didapatkan hasil empat cluster. Klaster pertama dengan karakteristik harga murah hingga sedang (0 - Rp. 32.000), kuota sedikit (0 - 11 GB), masa aktif sebentar hingga lama (1 - 60 hari). Klaster kedua dengan karakteristik harga mahal (Rp. 79.000 - Rp. 110.000), kuota murah hingga mahal (6 - 100 GB), masa aktif sedang hingga lama (7 - 60 hari). Klaster ketiga dengan karakteristik harga sangat mahal (Rp. 125.000 - Rp. 180.000), masa aktif lama (28 - 60 hari), kuota sedang hingga banyak (12 - 110 GB). Klaster keempat dengan karakteristik harga sedang (Rp. 34.000 - Rp. 70.000), masa aktif lama (14 - 60 hari), kuota sedikit hingga sedang (1,5 - 40 GB). Total data pada klaster 1 adalah 94 data, klaster 2 sebanyak 42 data, klaster 3 sebanyak 16 data, klaster 4 sebanyak 59 data. Hasil klasterisasi ditampilkan pada gambar 9, gambar 10, gambar 11, dan gambar 12.
|
1 ∖ |
>Jaιna Paket |
⅝¾⅛¾!⅛⅛ |
VfessAfcLit |
⅛¾Q⅞ |
Na∏>a!⅛)<S_____ |
gg⅞¾!Wri |
JW AfelI |
lri≡ |
Nama R&el | ||||
|
Happy 2GB 1 Hari |
2 |
1 |
4∞0 |
XL Data Pure 0.8GB |
0.8 |
30 |
7025 |
QOMBGB |
4 |
30 |
286∞ | ||
|
3 |
Happy 7GB 1 Hsfcri |
7 1 |
l□∞0 |
XLDataPurelGB |
30 |
8550 |
Freedom Internet 2 GB/1 Hari |
2 |
1 7925 | ||||
|
⅜ |
Happy 7GB 3 Hari |
3 |
15∞0 |
XL Data Pure 2GB |
2 |
30 |
17000 |
Freedom Internet 2,S GB/5 Hari |
2.5 |
5 |
11475 | ||
|
5 |
Happy 11GB 30 ∏ a ri |
11 |
30 |
300∞ |
XL Data Pure 3GB |
3 |
30 |
24450 |
Freedom Internet 5 GB/3 HQji |
5 |
3 |
14925 | |
|
6 |
Happy 7GB 30 Hgri |
7 |
30 |
3000C |
XL HQJggtj 05GB |
0.5 |
7 |
5430 |
Freedom Internet 2 GB/30 IJari |
2 |
30 |
1650C | |
|
7 I |
Happy 3GB 30H,Qri |
3 |
30 |
150∞ |
XL HQtRQd 15GB |
1 |
7 |
8130 |
Freedom Internet 3 GB/30 Hari |
3 |
30 |
177∞ | |
|
8 |
HappyOGB 10 Haji |
9 |
10 |
31∞0 |
XLHQtRQdlSGBJHari |
1.5 |
3 |
9320 |
Freedom internet 7 GB/5 Haji |
5 20895 | |||
|
9 |
Happy 5GB 7 Hapi |
5 |
7 |
20000 |
XLHQdBAdIGe |
1 |
7 |
9345 |
Freedom Internet 4 GB/30 Hari |
30 |
27300 | ||
|
10 |
Happy 1.5GB 7 Hari |
1.5 |
7 |
9∞0 |
XLHqW 1.5GB |
1 |
7 |
9450 |
Freedom Internet 5,5 GB/30 Haji |
S-S |
30 |
27855 | |
|
11 I |
Happy 6GB 5 Hari |
6 |
5 |
21∞0 |
XL HW 25GB |
2.5 |
7 |
11475 |
IiflQSaL Data Pure 100 MB 30 HJ |
0.1 |
30 |
12∞ | |
|
Tl |
Happy 3.5GB 5 Hari |
3.5 |
5 |
16000 |
XLUWHθB |
4 |
7 |
14660 |
DdD5ai Data Pure 200 MB 30 H? |
0.2 |
30 |
2025 | |
|
13 |
Happy 5GB3Hari |
5 |
3 |
150∞ |
XL HW∣ 2GB |
2 |
7 |
14780 |
JldQSril Data Pure 250 MB 30 HR |
0.25 |
30 |
2450 | |
|
1⅛ |
Happy 3GB3 Haq |
3 |
3 |
ll∞O |
XL HQWQdI 3GB |
3 |
1 DIDF |
∏⅛>sal Data Pure 300 MB 30 HJ |
0.3 |
30 |
2950 | ||
|
15 |
Happy SGB 1 HAT! |
5 |
1 |
10∞0 |
XL HqJBqsI 6GB |
s |
7 |
Ddosai Data Pure 500 MB 30 ⅛? |
0.5 |
30 |
45∞ | ||
|
16 |
Happy 2.5GB 1 Hari |
2.5 |
1 |
55∞ |
XL HJW OSGB |
0.8 |
30 |
∣Π⅛P5ai Data Pure 750 MB 30 Har |
0.75 |
30 |
6355 | ||
|
17 |
Happy 1.5GB 1 Hap; |
1.5 |
1 |
4∞0 |
XL Xtpa Combo Flex 4GB |
4 |
30 |
13975 |
∣ntaat Data Pure 1GB 30 Hari |
1 |
30 |
8525 | |
|
18 1? 20 |
AQN Full 6GB AQN Full 35GB AON Full 25GB |
6 3.5 2.5 |
60 60 60 |
31000 21∞0 15500 |
Xl XJra Combo Flex 75» XL xtχa Combo Flex 13G J⅞∣fcW⅞⅞1500 MB∕15⅛ |
7.5 13 0.5 |
30 30 15 |
25005 32500 8650 |
ljy⅛5j⅛ Data Pure 1,5 GB 30 Han QtariJ Data Pure 2 GB 30 HaR dQos,at Data Pure 3 GB 30 Hari |
1.5 2 3 |
30 30 30 |
12500 15850 20100 | |
|
Ri (NEW) 25GB 1 H⅛ri |
2.5 |
1 |
4000 |
R⅜ro⅞s≡ι IGBriJOHari |
1 |
30 |
16425 |
D⅛osqJ Data Pure 5 GB 30 Hjri |
5 |
30 |
31025 | ||
|
Ri(NEW) 4GB 3 HSri |
4 |
3 |
100∞ |
IglfcQIJiSgL 2 GB/30 ∏arj |
2 |
30 |
32350 |
Freedom combo 6 GB |
4 |
30 |
30175 | ||
|
Rj (NEW) 10GB5HSri |
10 |
5 |
20∞0 |
SJQJigt 1GB 30 HSri |
1 |
30 |
9830 |
Yellow 1GB 1 Haji |
1 |
1 4640 | |||
|
24 |
XHa Combo Mini 15GB |
1.5 |
7 |
9600 |
HJQIJgt 1r5 GB 30 HSri |
1.5 |
30 |
13360 |
Yellow 1 GB 2 HaR |
1 |
2 |
53∞ | |
|
25 ∣ |
XHa Combo Mini 25Gf |
2.5 |
13650 |
KSDgJ 2 GB 30 Usri |
2 |
30 |
17355 |
YellOW 1 GB 7 Hari |
97∞ | ||||
|
26 |
XRaCombo Mini 4GB |
4 |
175∞ |
gJQT∣gi 3 GB 30 HSri |
3 |
30 |
23505 |
Yellow 1GB 15 Hari |
IS |
117∞ | |||
|
27 |
XJra Combo Mini 6GB |
6 |
22250 |
KAHgtSGB 30 l∣arι |
5 |
30 |
29873 |
Freedom ‰q⅛ Harijjp 7 GB 7 H? |
7 |
26655 | |||
|
28 |
£«0n 1GB |
1 |
60 |
13450 |
KSDgt 2 GB 60 Ilari |
2 |
60 |
25825 |
SijarJfren 1 GB 7 HQji |
1 |
7 |
75∞ | |
|
28 I |
Xtra on 2GB |
2 |
30 |
14855 |
Bronot 3 GB 60 Hari |
3 |
60 |
32485 |
Smartfren 3 GB/5 HaR |
3 |
5 |
9355 | |
|
30 |
⅜GO∏2GB |
2 |
60 |
225∞ |
Mini 7 Haril GB∕7∏ari |
1 |
7 |
9368 |
Smartfren 1.5 GB 7 Hari |
1.5 |
7 |
9905 | |
|
31 |
XL Data Pure 05GB |
0.5 |
30 |
450C |
Mini 7 Hari 1.5 GB/7 Halt |
1.5 |
7 |
14475 |
UnlimitedFUPiGBjHari 7 Han |
7 |
7 |
22247 | |
|
32 ∣ |
Mini2GB∕l ∏ari |
2 |
1 |
7600 |
unlimited Nonstop 2 GB10 Hari |
2 |
10 |
10192 | |||||
|
33 |
Mini3GB∕l Hari |
3 |
1 |
8500 | |||||||||
|
34 |
STO ⅛ GB |
2 |
30 |
16750 | |||||||||
35
Gambar 9. Klaster 1
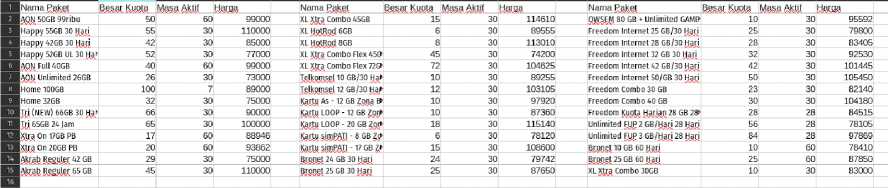
Gambar 10. Klaster 2

Gambar 11. Klaster 3
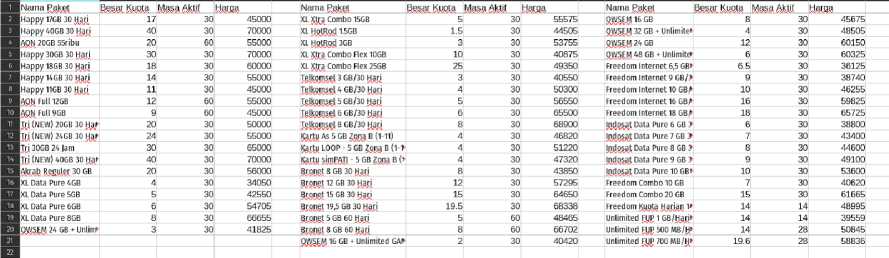
Gambar 12. Klaster 4
4. Kesimpulan
Dari hasil penelitian yang telah dilakukan, dapat diambil beberapa kesimpulan.
-
1. Klasterisasi paket data internet berbagai operator Indonesia dapat dikelompokkan menjadi empat kategori dengan karakteristik berupa harga, besar kuota, dan masa aktif. Klaster pertama cocok bagi pelanggan yang tidak terlalu sering menggunakan internet dan kebutuhan biaya sedikit. Klaster kedua cocok bagi pelanggan yang sering menggunakan internet dan mampu membeli paket data dengan harga mahal. Klaster keempat cocok bagi pelanggan yang menggunakan internet dalam taraf standar.
-
2. Klasterisasi di atas dibentuk menjadi empat kategori, tetapi masih ada data yang berbeda dengan yang lainnya, contohnya pada klaster 1, terdapat satu paket data dengan masa aktif cuma 7 hari sedangkan data yang lain masa aktifnya di atas 28 hari. Disarankan menggunakan jumlah yang lebih dari empat.
-
3. Outliers pada data paket data sangat mungkin terjadi karena karakteristik data paket data internet sangat tidak menyebar. Hal ini dibuktikan saat penggambaran diagram visualisasi. Hal ini dapat diatasi dengan menghilangkan outliers.
Referensi
-
[1] -, “APJII”, 2019. [Online]. Available: https://apjii.or.id/survei2019x [1 Oktober 2022]
-
[2] -, “We Are Social”, 26 January 2022. [Online]. Available:
https://wearesocial.com/uk/blog/2022/01/digital-2022-another-year-of-bumper-growth-2/. [1 October 2022]
-
[3] Suyanto, Data Mining untuk Klasifikasi dan Klasterisasi Data, First ed., Bandung:
Informatika, 2019, pp. 4.
-
[4] D. Triyansyah and D. Fitrianah, “Analisis Data Mining Menggunakan Algoritma K-Means
Clustering Untuk Menentukan Strategi Marketing” IncomTech Jurnal Telekomunikasi dan Komputer, vol. 8, no. 3, p. 164, 2018.
-
[5] Suyanto, Machine Learning Tingkat Dasar dan Lanjut, First ed., Bandung: Informatika,
2018, pp. 205.
-
[6] Y. Darmi and A. Setiawan, “Penerapan Metode Clustering K-Means dalam
Pengelompokkan Penjualan Produk” Jurnal Media Infotama, vol. 12, no. 2, p. 157, 2016.
-
[7] R. Muliono and Z. Sembiring, “DATA MINING CLUSTERING MENGGUNAKAN
ALGORITMA K-MEANS UNTUK KLASTERISASI TINGKAT TRIDARMA PENGAJARAN DOSEN” CESS (Journal of Computer Engineering System and Science), vol. 4, no. 2, p. 274, 2019.
-
[8] F. Nur, M. Zarlis, and B. Benyamin, “PENERAPAN ALGORITMA K-MEANS PADA
SISWA BARU SEKOLAH MENENGAH KEJURUAN UNTUK CLUSTERING JURUSAN” Jurnal Nasional Informatika dan Teknologi Jaringan, vol. 1, no. 2, p. 101, 2017.
416
Discussion and feedback