Implementasi Algoritma Support Vector Machine dalam Deteksi Depresi Pada Twitter
on
JNATIA Volume 1, Nomor 1, November 2022
Jurnal Nasional Teknologi Informasi dan Aplikasinya
Implementasi Algoritma Support Vector Machine dalam Deteksi Depresi Pada Twitter
Vinna Setiawana1, I Ketut Gede Suhartanaa2
aProgram Studi Informatika, Universitas Udayana Bali, Indonesia
1vinasetti@gmail.com 2ikg.suhartana@unud.ac.id
Abstract
Mental health is an important part of human life. Over time, mental health is getting more attention along with the increasing number of people who experience mental health disorders. For example, in the U.S., 1 in 5 adults has a mental health disorder, with 8% experiencing depression[1]. Social media, one of which is Twitter as a place for opinions and voices, is often a place for people to convey what they feel. Therefore, writings posted on twitter can be an option to detect a person s mental health, namely depression. To classify between writings that have the characteristics of depression and not, the Support Vector Machine method is used. Based on testing on the Support Vector Machine method for depression classification, the highest accuracy value was obtained at 85,6%.
Keywords: Mental Health, Depression, Twitter, Support Vector Machine
Kesehatan mental merupakan bagian penting dari kehidupan manusia. Seiring berjalannya waktu, kesehatan mental semakin mendapat perhatian seiring dengan semakin banyaknya masyarakat yang mengalami gangguan kesehatan mental. Misalnya, di AS, 1 dari 5 orang dewasa memiliki gangguan kesehatan mental, dengan 8% mengalami depresi[1]. Depresi merupakan gangguan mental yang umum dialami oleh manusia, diperkirakan 5% dari populasi global mengalami permasalahan depresi. Bahkan, depresi dapat menjadi alasan seorang memutuskan untuk bunuh diri. Faktanya, lebih dari 700.000 orang meninggal akibat bunuh diri setiap tahunnya[2]. Akan lebih baik jika masyarakat yang mengalami gangguan kesehatan mental dapat dideteksi sejak dini sehingga cepat mendapat bantuan dan penanganan.
Media sosial sebagai wadah berpendapat dan bersuara, seringkali menjadi tempat orang untuk menyampaikan apa yang mereka rasakan. Twitter sebagai media sosial yang banyak digunakan menjadi salah satu platform yang digunakannya. Diperkirakan sebesar 6,1% dari populasi dunia merupakan pengguna twitter[3]. Oleh karena itu, tulisan yang di unggah di twitter bisa menjadi pilihan untuk mendeteksi kesehatan mental seseorang, terutama depresi.
Deteksi depresi pada tulisan twitter seseorang dapat dilakukan secara otomatis menggunakan metode atau algoritma tertentu, algoritma digunakan yakni algoritma Support Vector Machine yang dapat digunakan untuk klasifikasi teks, dalam hal ini apakah teks atau tulisan memiliki ciri depresi atau tidak. Penelitian sebelumnya mengenai klasifikasi teks pernah dilakukan, salah satunya adalah analisis sentimen pemindahan ibu kota Indonesia menggunakan algoritma Support Vector Machine yang menghasilkan akurasi sebesar 96,68%[4]. Penelitian mengenai analisis sentimen Gojek pada media sosial twitter dengan klasifikasi Support Vector Machine menghasilkan akurasi sebesar 79,19%[5].
Berdasarkan Penelitian sebelumnya, metode Support Vector Machine dapat digunakan untuk klasifikasi teks dengan hasil yang cukup baik. Pada penelitian kali ini, digunakan metode Support Vector Machine untuk mengklasifikasikan antara tulisan yang memiliki ciri depresi dan tidak.
-
2. Metodologi Penelitian
2.1. Alur Penelitian
Alur dari penelitian yang dilakukan dapat dilihat pada Gambar 1.
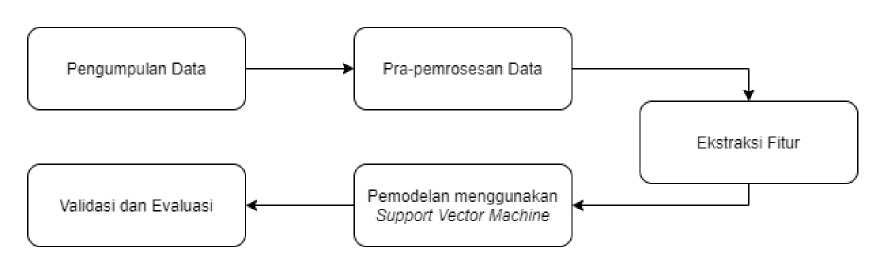
Gambar 1.AlurPenelitian
Penelitian diawali dengan melakukan pengumpulan data yang akan digunakan untuk penelitian yaitu data twitter yang diklasifikasi depresi atau normal. Selanjutnya, data tersebut di inputkan dan dilakukan pra-pemrosesan pada data inputan. Dilakukan proses ekstraksi fitur pada data, lalu dilakukan pemodelan dan pelatihan model menggunakan metode Support Vector Machine. Setelah dilakukan pelatihan pada model, dilakukan validasi dan evaluasi pada model.
Data yang digunakan pada penelitian ini adalah data sekunder. Data sekunder merupakan sumber data yang sudah disediakan dan dikumpulkan oleh pihak lain selain peneliti itu sendiri (Sanusi, 2012). Sumber dataset dari penelitian ini bernama “Depression: Twitter Dataset + Feature Extraction” dari situs Kaggle. Dataset ini diakses pada 24 September 2022 pukul 15:36 WITA yang diakses melalui link https://www.kaggle.com/datasets/infamouscoder/mental-health-social-media dataset terdiri dari 20000 postingan twitter dengan 10000 data ter klasifikasi depresi dan 10000 data ter klasifikasi normal sehingga dataset sudah seimbang.
Tahap awal yang dilakukan setelah kita men-load data adalah melakukan pra-pemrosesan pada dataset. Proses ini dilakukan untuk mempersiapkan data sebelum proses ekstraksi fitur dan pemodelan. Adapun alur dari tahapan pra-pemrosesan data dapat dilihat pada Gambar 2.
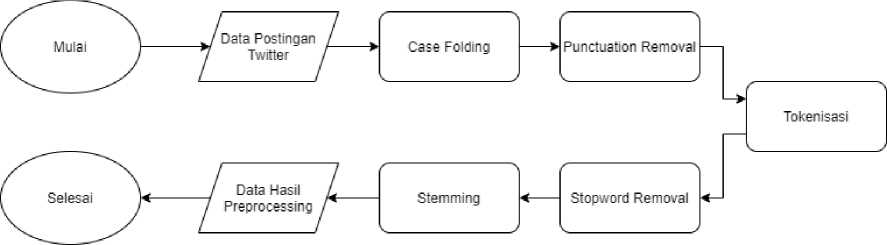
Gambar 2.Alur Preprocessing
Pra-pemrosesan data dilakukan pada data tulisan twitter. Dilakukan proses case folding yaitu membuat teks menjadi seragam menjadi huruf kecil. Selanjutnya, dilakukan proses punctuation removal untuk menghapus tanda baca yang ada dalam data. Untuk memecah kalimat menjadi token yakni setiap kata nya, dilakukan proses Tokenisasi. Setelah kalimat dipisah menjadi token, langkah selanjutnya adalah melakukan stopword removal yang bisa disebut juga dengan filtering
yang digunakan untuk menghapus kata yang banyak muncul tapi kurang memiliki makna. Pra-pemrosesan yang terakhir adalah melakukan stemming untuk mengubah kata atau setiap token menjadi bentuk dasar[6].
Term Frequency Inverse Document Frequency(TF-IDF) merupakan metode ekstraksi fitur dengan menghitung seberapa penting suatu kata dalam suatu dokumen. Term Frequency(TF) dalam TF-IDF mewakili frekuensi kemunculan dari kata dalam suatu dokumen, sedangkan Inverse Document Frequency(IDF) mewakili seberapa banyak dokumen yang memiliki kata tersebut dimana semakin tersebar kata tersebut muncul di semua dokumen dalam dataset, maka IDF nya akan mendekati nol[7].
Rumus untuk menentukan besaran nilai IDF dapat dilihat pada (1).
IDFj= log( D / dj (1)
Dengan D merupakan jumlah semua dokumen dalam dataset dan dfj adalah jumlah dokumen yang memiliki term (tj) didalamnya.
Lalu untuk TF dapat dicari dengan menghitung frekuensi kemunculan term dalam dataset. Sehingga, rumus umum untuk TF-IDF dapat dilihat pada (2) dan (3)
Wjj = tfij × ^ffj (2)
Wij = tfj × log(D/dfj) (3)
-
2.5. Support Vector Machine(SVM)
Support Vector Machine(SVM) merupakan algoritma machine learning yang bertujuan mencari hyperplane terbaik yang memiliki margin maksimal sebagai pemisah antara kelas[7]. SVM termasuk algoritma supervised learning sehingga data yang digunakan pada metode atau algoritma ini adalah data berlabel. Dalam algoritma Support Vector Machine, terdapat beberapa kernel yang dapat digunakan, diantaranya kernel Linear, RBF dan Polynomial. Kernel Linear akan baik digunakan ketika data yang digunakan terpisah secara linier, sedangkan Kernel polynomia dan RBF biasa digunakan saat data yang digunakan tidak dapat terpisah secara linier[8]. Kerne Linear sering digunakan untuk permasalahan klasifikasi pada data berbentuk teks[9].
-
2.6. K-fold Cross Validation
K-fold Cross Validation merupakan metode validasi yang digunakan untuk mengetahui performa model. Metode ini bekerja dengan membagi data menjadi sejumlah k, begitu juga dengan banyaknya perulangan yang dilakukan[4]. Jadi apabila kita mengambil nilai k = 10, maka data akan dibagi menjadi 10 bagian dimana setiap iterasi akan terjadi kombinasi training dan testing yang berbeda sebanyak 10 kali.
Evaluasi dilakukan dengan menghitung nilai akurasi dari model. Pengujian akurasi dilakukan
untuk mengetahui ketepatan model dalam melakukan prediksi. Nilai akurasi dapat kita dapatkan
dengan menggunakan rumus berikut.
. 7 . Jumlah prediksi benar
(7)
Akurasi = ---------------
Jumlah total prediksi
Data tulisan twitter yang berjumlah 20000 melalui tahap preprocessing, hasil dari tahap preprocessing dapat dilihat pada tabel 1.
Table 2. Hasil Preprocessing
|
Process |
Result |
|
Initial Text |
It's just over 2 years since I was diagnosed with #anxiety and #depression. Today I'm taking a moment to reflect on how far I've come since. |
|
Lowercasing |
it's just over 2 years since i was diagnosed with #anxiety and #depression. today i'm taking a moment to reflect on how far i've come since. |
|
Punctuation Removal |
its just over 2 years since i was diagnosed with anxiety and depression today im taking a moment to reflect on how far ive come since |
|
Stopword Removal |
2 years since diagnosed anxiety depression today im taking moment reflect far ive come since |
|
Stemming |
2 year sinc diagnos anxieti depress today im take moment reflect far ive come sinc |
Setelah dilakukan tahap preprocessing, dataset dibagi menjadi 80% Data Latih, dan 20% Data Uji sehingga data latih berjumlah 16000 data dan data uji berjumlah 4000 data. Lalu, dilakukan ekstraksi fitur TF-IDF dan dilakukan pelatihan pada model menggunakan algoritma SVM dan validasi K-fold Cross Validation dengan nilai K sebesar 10. Setelah pelatihan dilakukan didapatkan nilai akurasi sebesar 85,60%. Lalu dilakukan eksperimen yaitu melakukan komparasi perbedaan kernel SVM dan pengaruhnya terhadap nilai akurasi. Hasil akurasi dari masing masing kernel dapat dilihat pada tabel berikut.
Table 3. Hasil Akurasi setiap kerne
|
Kernel |
Akurasi Rata Rata Akurasi Validasi |
|
Linear RBF Polynomial |
86,25% 85,63% 83,65% 85,55% 86,87% 85,60% |
Kernel Linear menghasilkan nilai akurasi sebesar 85,63%, kernel RBF menghasilkan nilai akurasi sebesar 85,55%, sedangkan kernel Polynomial menghasilkan akurasi sebesar 85,60%. Kerne Linear menghasilkan akurasi paling tinggi yaitu 85,63%. Selanjutnya dilakukan eksperimen
dengan mengatur parameter C pada model dengan kernel Linear yang menghasilkan akurasi sebagai berikut.
Table 4. Hasil Parameter C Pada model SVM
|
C |
Akurasi |
|
0.1 |
79,89% |
|
0.2 |
82,31% |
|
0.3 |
83,45% |
|
0.4 |
84,19% |
|
0.5 |
84,67% |
|
0.6 |
84,93% |
|
0.7 |
85,18% |
|
0.8 |
85,50% |
|
0.9 |
85,58% |
|
1.0 |
85,63% |
Berdasarkan pengujian pada parameter C dengan input dari 0 sampai dengan 1 pada tabe diatas. Dihasilkan akurasi tertinggi pada parameter C yang bernilai 1 dan menggunakan kerne linear yaitu dengan nilai akurasi 85,63%.
Berdasarkan hasil evaluasi, didapatkan bahwa kernel linear dalam algoritma Support Vector Machine menghasilkan performa paling baik dibanding kernel lainnya yaitu akurasi sebesar 85,63% dengan nilai C=1. Dari performa tersebut, dapat disimpulkan bahwa algoritma Support Vector Machine dapat mengklasifikasikan dan mendeteksi postingan depresi dan tidak depresi dengan sangat baik.
Daftar Pustaka
-
[1] “Mental Health Statistics Going into 2022 - PDG Rehabilitation Services.”
https://www.pdgrehab.com/mental-health-statistics-2022/ (accessed Sep. 25, 2022).
-
[2] “Depression.” https://www.who.int/news-room/fact-sheets/detail/depression (accessed
Sep. 26, 2022).
-
[3] Datareportal, “The Latest Instagram Statistics: Everything You Need to Know — DataReportal – Global Digital Insights,” Kepios, 2022. https://datareportal.com/essential-instagram-
stats?utm_source=DataReportal utm_medium=Country_Article_Hyperlink utm_campai gn=Digital_2022 utm_term=Indonesia utm_content=Facebook_Stats_Link (accessed Sep. 29, 2022).
-
[4] P. Arsi and R. Waluyo, “Analisis Sentimen Wacana Pemindahan Ibu Kota Indonesia Menggunakan Algoritma Support Vector Machine (SVM),” J. Teknol. Inf. dan Ilmu Komput., vol. 8, no. 1, p. 147, 2021, doi: 10.25126/jtiik.0813944.
-
[5] N. Fitriyah, B. Warsito, and D. A. I. Maruddani, “Analisis Sentimen Gojek Pada Media Sosial Twitter Dengan Klasifikasi Support Vector Machine (Svm,” J. Gaussian, vol. 9, no. 3, pp. 376–390, 2020, doi: 10.14710/j.gauss.v9i3.28932.
-
[6] R. Kusumaningrum, I. Z. Nisa, R. P. Nawangsari, and A. Wibowo, “Sentiment analysis of Indonesian hotel reviews: from classical machine learning to deep learning,” Int. J. Adv. Intell. Informatics, vol. 7, no. 3, pp. 292–303, 2021, doi: 10.26555/ijain.v7i3.737.
-
[7] N. Giarsyani, “Komparasi Algoritma Machine Learning dan Deep Learning untuk Named Entity Recognition: Studi Kasus Data Kebencanaan,” Indones. J. Appl. Informatics, vol. 4, no. 2, p. 138, 2020, doi: 10.20961/ijai.v4i2.41317.
-
[8] H. Al Azies, D. Trishnanti, and E. M. P. H, “Comparison of Kernel Support Vector Machine ( SVM ) in Classification of Human Development Index ( HDI ),” vol. 6, no. 6, 2019.
-
[9] S. Awasthi, “Seven Most Popular SVM Kernels,” 2020. https://dataaspirant.com/svm-kernels/#t-1608054630727 (accessed Sep. 29, 2022).
Halaman ini sengaja dikosongkan
290
Discussion and feedback