Speed Performance Analysis of Big Data Processing with Micro Batching at the ETL Process for Event-Data
on
Jurnal Nasional Teknologi dan Aplikasinya
Volume 1, Nomor 1, November 2022
Analisis Performa Kecepatan Pemrosesan Big Data Dengan Menggunakan Micro Batching Dalam Tahap Load Pada ETL Untuk Event-Data
Putu Audi Pasuatmadia1, Ida Bagus Made Mahendraa2
aInformatics Department, Udayana University Bali, Indonesia 1audipasuatmadi@gmail.com 2ibm.mahendra@unud.ac.id
Abstract
Speed performance in Big Data Processing is one of the key aspect of presenting a real-time data for a real-time analysis in various use cases. One of such data is an Event-Data or an Activity Data that is often used for making analysis and business decisions in real-time. This research focuses on analyzing the speed performance of Big Data Processing in the Load stage of Extract, Transform, Load using Micro-Batching. The speed performance is evaluated using Load-Testing with K6 and the configuration of 10 VUs and 10000 data. The Load-Testing results of the speed performance shows that implementing Micro-Batching results in 63.63% faster in performing all the request, 59.03% faster in HTTP Request Duration, and 62% faster in HTTP Request Waiting duration.
Keywords: Big Data, ETL, Micro-Batching, Event-Data, Load-Testing, Stream-Processing
Dewasa ini, data merupakan peranan yang sangat penting dalam membuat suatu keputusan. Salah satu dari data ini merupakan Event-Data atau data aktivitas baik aktivitas pengguna atau aktivitas lainnya yang berkaitan dengan waktu dan kejadian. Data aktivitas dapat meliputi pengguna menekan suatu tombol, ataupun aktivitas pemanggilan fungsi pada program. Data ini cenderung menghasilkan jumlah yang sangat besar dan dapat dimasukkan ke kategori Big Data atau Data Besar. Big Data merupakan sebuah data yang berjumlah banyak yang dapat menjadi tolak ukur inovasi dan juga strategi bisnis [1]. Memproses Big Data tidak dapat dilakukan secara tradisional [1], melainkan harus menggunakan konsep seperti Extract, Transform, Load atau ETL [2]. ETL merupakan sebuah teknik yang digunakan untuk mengintegrasikan data dari berbagai tempat ke dalam gudang data atau Data Warehouse [2] [3].
Data yang diproses dapat berupa sebuah data aktivitas, di mana data aktivitas ini salah satu kegunaanya adalah dapat digunakan di bidang sains dan teknologi [4]. Data aktivitas ini pula dapat digunakan di industri yaitu sebagai tolak ukur dan juga basis dari analisis proses bisnis atau business process analysis [5]. Data – data aktivitas pada umumnya merepresentasikan sebuah proses atau aktivitas dengan deskripsi dari aktivitas dan juga waktu aktivitas atau timestamp saat aktivitas tersebut terjadi [5]. Data aktivitas ini dapat berupa banyak hal, salah satunya adalah data logging yang mencatat kejadian error atau kegagalan pada internet yang. Data ini merupakan salah satu data yang penting karena dapat membantu programmer dalam melakukan debugging [6].
Dalam melakukan pemrosesan Big Data, latensi atau performa kecepatan menjadi salah satu tantangan yang besar terutama pada data waktu nyata atau real-time data [7]. Sistem yang tidak cepat dapat membuat pengguna yang terlibat dalam sistem tidak memiliki pengalaman terbaik dalam sistem. Untuk itu, optimisasi dibutuhkan untuk menghindari permasalahan ini terjadi.
Salah satu optimisasi yang dapat dilakukan adalah dengan mengimplementasikan Micro-Batching. Micro-Batching merupakan metode dimana data dibagi dan dikelompokkan menjadi kumpulan data atau batch dan diproses secara bersamaan untuk satu kumpulan data [8]. Micro-Batching diyakini dapat meningkatkan performa sistem dalam ETL Big Data untuk Event-Data pada tahapan Load karena
Pasuatmadi and Mahendra
Analisis Performa Kecepatan Pemrosesan Big Data Dengan Menggunakan Micro Batching Dalam Tahap Load Pada ETL Untuk Event-Data membutuhkan inisialisasi atau persiapan dalam pemrosesan yang lebih sedikit, yaitu satu persiapan proses seperti inisialisasi koneksi untuk satu kumpulan data di mana satu kumpulan data ini akan memiliki banyak data. Micro-Batching pada penelitian lain berhasil menginatkan performa sebanyak 1.63x lebih cepat dalam menjalankan Deep Learning [8], dan juga telah berhasil menginkatkan performa throughput atau performa kecepatan jumlah data yang diproses sebanyak 200% lebih baik pada pemrosesan real-time untuk data Tweet yang merupakan tweets pengguna Twitter dan SynD yang merupakan data sintesis untuk pengujian [9]. Dengan mengetahui hasil dua penelitian tersebut, peneliti memiliki tujuan untuk melakukan penelitian ini demi mengetahui apakah implementasi MicroBatching dapat meningkatkan performa kecepatan dalam Event-Data pada tahap Load dalam ETL.
Penelitian ini mengikuti sebuah alur dan juga tahapan untuk memastikan kelancaran dari penelitian. Kerangka penelitian tersebut dapat dilihat pada Gambar 1 di bawah.
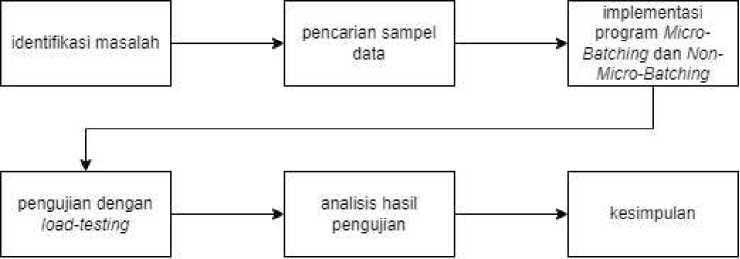
Gambar 1. Alur Penelitian
Alur kerangka penelitian di atas memiliki penjelasan sebagai berikut:
-
a. Identifikasi Masalah: tahapan awal dari penelitian, di mana peneliti mengidentifikasikan masalah yang ada di lapangan dan juga studi literatur penyokong dari masalah yang ditemukan. Permasalahan yang didapatkan dari penelitian ini adalah performa kecepatan dalam fase Load pada ETL untuk Event-Data atau data aktivitas. Pada tahap ini pula peneliti melakukan proses studi literatur sebagai sumber informasi untuk melakukan penelitian.
-
b. Pencarian Sampel Data: pada tahapan ini, data dicari dengan melakukan survey terhadap perusahaan teknologi. Dilakukan wawancara dan observasi untuk mencari tahu seperti apa format logging atau format dari Event-Data yang dapat digenerasikan ulang nantinya dalam penelitian. Hal ini dilakukan agar pengujian performa kecepatan tetap relevan terhadap bentuk dari data yang digunakan.
-
c. Implementasi Program Micro-Batching dan tanpa Micro-Batch: pada tahapan ini, peneliti melakukan implementasi dari program dengan dua metode. Hal ini bertujuan untuk dapat membandingkan performa kecepatan dari dua metode tersebut. Implementasi dilakukan dengan menggunakan bahasa pemrograman Go dan juga Visual Studio Code.
-
d. Pengujian dengan Load-Testing: pada tahapan ini, peneliti melakukan pengujian terhadap dua metode tersebut dengan metode Load-Testing menggunakan K6. Pengujian dilakukan dengan sampel data yang ditemukan dan digenerasikan ulang.
-
e. Analisis Hasil Pengujian: pada tahapan ini, peneliti melakukan analisis dari hasil yang didapatkan dari pengujian terhadap dua metode Micro-Batching dan tanpa Micro-Batching.
-
f. Kesimpulan: pada tahapan ini, peneliti menyimpulkan hasil dari performa kecepatan dari penggunaan Micro-Batching dan juga tanpa Micro-Batching.
Penelitian ini menggunakan metode Micro-Batching sebagai metode yang akan diuji performa kecepatannya. Micro-Batching merupakan sebuah konsep dimana data yang banyak atau datang secara kontinu dikelompokan menjadi beberapa kelompok untuk nantinya pemrosesan dilakukan per-kelompok data tersebut sebagai kesatuan [8]. Micro-Batching mengambil konsep dari Batch Procecssing, dimana Batch Processing merupakan pemrosesan sekumpulan data secara periodik yang biasanya dijalankan pada waktu atau kebutuhan tertentu [10]. Perbedaan dari Micro-Batching dan Batch Processing adalah, Micro-Batching menggunakan konsep Batch Processing pada halnya
memproses sekumpulan data secara bersamaan, namun Micro-Batching melakukannya dengan jumlah data yang jauh lebih sedikit dan juga sering digunakan pada Stream-Processing atau pemrosesan waktu nyata karena dapat dikatakan mengumpulkan data – data yang datang dan memprosesnya kumpulan data – data tersebut secara langsung di waktu tersebut. Konsep MicroBatching kemudian diturunkan dari konsep Windowing. Windowing merupakan metode yang bekerja dengan cara membagi data – data yang datang secara kontinu dan menerus ke dalam segmen – segmen [11] [12]. Salah satu keunggulan dari menggunakan Micro-Batching berada di sisi jaringan. Dengan menggunakan Micro-Batching, kita dapat menghindari Repeated TCP. Repeated TCP adalah sebuah inisiasi komunikasi data pada jaringan yang di mana pada setiap komunikasi tersebut berjalan dengan singkat dan juga berulang [13]. Untuk mendukung konsep ini, terdapat sebuah riset yang menyebutkan bahwa meminimalisir penggunaan koneksi TCP berulang atau Repeated TCP dapat menghasilkan latensi 19 milidetik pada persentil ke-99 untuk 2000 data dengan mengurangi Repeated TCP dengan metode Database Pooling [14].
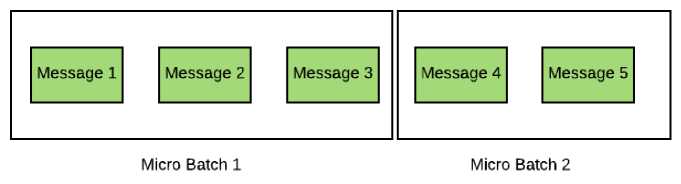
Gambar 2. Ilustrasi Micro-Batching. Sumber: packtpub.com
Penelitian ini beradap pada lingkup proses Extract, Transform, Load atau ETL khususnya pada tahapan Load. ETL merupakan sebuah metode untuk melakukan pemrosesan data besar atau Big Data yang melibatkan tiga tahap, yaitu pengambilan data dari sumber data, transformasi data atau pemrosesan data, dan juga penyimpanan hasil pemrosesan data pada gudang data [2]. Konsep ETL merupakan sebuah pilihan standar yang digunakan untuk mengolah datab esar atau aset – aset Big Data yang berharga dan variatif [7]. Di penelitian kali ini, berfokus pada tahapan Load dalam ETL yaitu proses penyimpanan data yang telah dilakukan proses transormasi ke dalam gudang data atau basis data lainnya.
Pengujian dari metode yang diimplementasikan akan menggunakan Load-Testing dengan K6. LoadTesting merupakan sebuah metode pengujian untuk performa sebuah sistem dengan mengimitasikan pengguna dengan mengirim request sebanyak konfigurasi yang diberikan [15]. Salah satu alat yang dapat digunakan untuk melakukan Load-Testing adalah K6. K6 merupakan sebuah alat open-source yang digunakan untuk Load-Testing sehingga dapat mengevaluasikan performa kecepatan sebuah sistem [16]. Menggunakan Load-Testing dengan K6 menghasilkan beberapa metris yang dapat digunakan sebagai alat ukur. Beberapa metris tersebut dapat dilihat pada tabel di bawah.
Tabel 1. Metris Utama K6 Load-Testing
|
Key |
Deskripsi |
|
total duration |
Total waktu yang dibutuhkan untuk mengirim seluruh data dan menerima respons sesuai konfigurasi. |
|
http_req_duration |
Waktu yang dibutuhkan untuk mengirim data dan menerima respon pada. Dihitung oleh library dengan cara menambahkan lama data dikirim ke tujuan, lama menunggu data diproses oleh tujuan, dan lama data kembali ke pengirim. |
|
http_req_waiting |
Waktu yang dibutuhkan untuk mendapatkan bit pertama respon data setelah mengirim request. Dihitung oleh library dengan menghitung lamanya data saat seluruh data tepat diterima oleh tujuan |
|
sampai dengan bit pertama data tersebut dikembalikan ke pengirim. Penghitungan ini dapat dikatakan merepresentasikan seberapa lama proses tujuan melakukan operasi pemrosesan data. |
Berdasarkan alur penelitian dan juga studi literatur yang telah dijelaskan, maka didapatkan hasil penelitian sebagai berikut.
Penelitian ini melakukan pencarian sampel data ke perusahaan teknologi. Sampel data dicari dengan cara melakukan survey dan juga observasi terhadap pelaku perusahaan. Didapatkan format logging atau format dari Event-Data yang digunakan oleh perusahaan. Format data tersebut dapat dilihat pada Tabel 2 di bawah.
Tabel 2. Struktur Event-Data
|
Key |
Tipe Data |
Deskripsi |
|
level |
String |
Kategori dari Event-Data |
|
message |
String |
Pesan atau intisari dari Event-Data |
|
timestamp |
Date |
Waktu kejadian |
|
project_name |
String |
Nama proyek yang menghasilkan Event-Data |
Kemudian, Key pada Event-Data pada bagian level tersebut yang merepresentasikan kategori dari Event-Data dapat dibagi lagi pada Tabel 3 di bawah.
Tabel 3. Penjabaran Kategori Event-Data
|
Level |
Deskripsi |
|
info |
Jika yang berkaitan dengan informasi seperti logging pada umumnya. |
|
warn |
Jika yang berkaitan dengan informasi seperti peringatan yang tidak fatal seperti error. |
|
error |
Jika berkaitan dengan error yang fatal. |
Peneliti berhasil mengumpulkan 10 data sebagai sampel dari perusahaan teknologi di Denpasar tersebut. Kemudian data ini dijadikan oleh peneliti sebagai basis untuk menguji penelitian terhadap performa Micro-Batching. Hal ini dilakukan dengan melakukan generasi sebanyak 10.000 data berdasarkan 10 sampel data yang dimiliki, dilakukan seperti demikian karena hal yang diuji nantinya adalah kecepatan dari pemrosesan sistem yang memiliki dampak terhadap jumlah data dan besarnya data di lapangan.
Proses implementasi dari Micro-Batching dan juga tanpa Micro-Batching dilakukan pada satu basis kode atau codebase dengan menggunakan bahasa pemrograman Go. Intisari dari implementasi program dapat dilihat pada penggalan kode di Tabel 4 di bawah.
Tabel 4. Penggalan Intisari Kode
Baris
1
2
3
4
5
6
Kode
package service
import ( "time"
|
"github.com/audi- | |
|
7 |
skripsi/snatia_audi_ingestor_be/internal/util/converterutil" |
|
8 Q |
"github.com/audi-skripsi/snatia_audi_ingestor_be/pkg/dto" |
|
10 |
) |
|
func (s *service) StoreEvent(event dto.EventLog, microBatch bool) | |
|
11 |
(err error) { |
|
12 |
if microBatch { |
|
13 |
err = s.processMicrobatch(event) |
|
14 |
} else { |
|
15 |
err = s.processNonMicrobatch(event) |
|
16 |
} |
|
17 | |
|
18 |
if err != nil { |
|
s.logger.Errorf("error processing data of %+v: %+v", | |
|
19 |
event, err) |
|
20 |
} |
|
21 | |
|
22 |
return |
|
23 |
} |
|
24 | |
|
func (s *service) processNonMicrobatch(event dto.EventLog) (err | |
|
25 |
error) { |
|
26 |
eventModel := converterutil.EventDtoToModel(event) |
|
27 |
err = s.repository.InsertEvent(eventModel, "non_microbatch") |
|
28 |
return |
|
29 |
} |
|
30 | |
|
func (s *service) processMicrobatch(event dto.EventLog) (err | |
|
31 |
error) { |
|
32 |
eventModel := converterutil.EventDtoToModel(event) |
|
s.EventBatch.BatchEventData = | |
|
33 |
append(s.EventBatch.BatchEventData, eventModel) |
|
34 | |
|
35 |
if len(s.EventBatch.BatchEventData) == 500 { |
|
36 |
s.EventBatch.Mu.Lock() |
|
err = s.repository.MicrobatchInsertEvent(s.EventBatch, | |
|
37 |
"microbatch") |
|
38 |
s.EventBatch.BatchEventData = nil |
|
39 |
s.EventBatch.Mu.Unlock() |
|
40 |
} |
|
41 | |
|
42 |
return |
|
43 |
} |
|
44 | |
|
45 |
func (s *service) initBatchCron() { |
|
46 |
go func() { |
|
47 |
for { |
|
48 |
if len(s.EventBatch.BatchEventData) > 0 { |
|
49 |
s.EventBatch.Mu.Lock() |
|
err := | |
|
50 |
s.repository.MicrobatchInsertEvent(s.EventBatch, "microbatch") |
|
51 |
if err != nil { |
|
s.logger.Errorf("error batch | |
|
52 |
insert: %+v", err) |
|
53 |
} |
|
54 |
s.EventBatch.BatchEventData = nil |
|
55 |
s.EventBatch.Mu.Unlock() |
|
56 |
} |
|
57 |
time.Sleep(2 * time.Second) |
|
58 |
} |
|
59 |
}() } |
Implementasi dari Micro-Batch dapat dilihat pada kode baris ke-30 sampai dengan baris ke-42. Dapat dilihat bahwa pada bagian tersebut terdapat sebuah penyimpanan data terlebih dahulu ke dalam sebuah array sampai data berjumlah sekiranya 500. Kemudian, setelah data mencapai angka 500, maka akan dilakukan penyimpanan seluruh data yang telah dilakukan batching terhadap basis data pada baris ke-36. Hal serupa dilakukan pula pada baris ke-44 sampai dengan baris ke-59 dimana hal tersebut dilakukan lagi setiap 2 detik untuk memastikan tidak ada data yang tertinggal. Dapat dilihat pula pada baris ke-35 dan juga pada baris ke-38 bahwa terdapat sync.Mutex untuk memastikan tidak terdapat racing condition atau data sama yang diproses oleh dua thread berbeda. Kemudian implementasi dari metode tanpa Micro-Batch dapat dilihat pada baris kode ke-24 sampai dengan baris kode ke-28. Pada bagian kode tersebut dapat dilihat bahwa data yang diterima langsung saja dikirim ke dalam basis data tanpa dilakukan Batching. Pemilihan kedua metode ini ditentukan pada baris ke-10 sampai dengan baris ke-22. Dilakukan pemisahan apakah menggunakan Micro-Batch atau tanpa Micro-Batch dari argumen yang dikirim.
Pengujian dari sistem dapat dilakukan Load-Testing menggunakan K6. Program untuk melakukan Load-Testing ditulis dengan bahasa pemrograman JavaScript. Penggalan kode dari Load-Testing menggunakan K6 dapat dilihat pada penggalan kode di Tabel 5 di bawah.
Tabel 5. Penggalan Intisari Kode Load-Testing
Baris
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
Kode
import http from "k6/http";
export const options = {
vus: 10,
iterations: 10000,
};
const rawData = open("data-sample.json");
const testData = JSON.parse(rawData);
export default function () {
const mode = __ENV.MODE;
let reqPath = "";
if (mode == "microbatch") { reqPath = "/v1/microbatch";
} else if (mode == "non-microbatch") { reqPath = "/v1/non-microbatch";
} else { console.error("ENV should be microbatch or non-microbatch"); return;
}
const randInt = Math.floor(Math.random() * testData.length);
http.post(
"http://localhost:8080" + reqPath, JSON.stringify(testData[randInt]), { headers: {
"Content-Type": "application/json", }, }
);
}
Implementasi dari Load-Testing dapat dilihat pada penggalan kode di atas. Pertama – tama dilakukan
konfigurasi dari skenario pada baris ke-3 sampai dengan baris ke-6. Kemudian sampel data di ambil
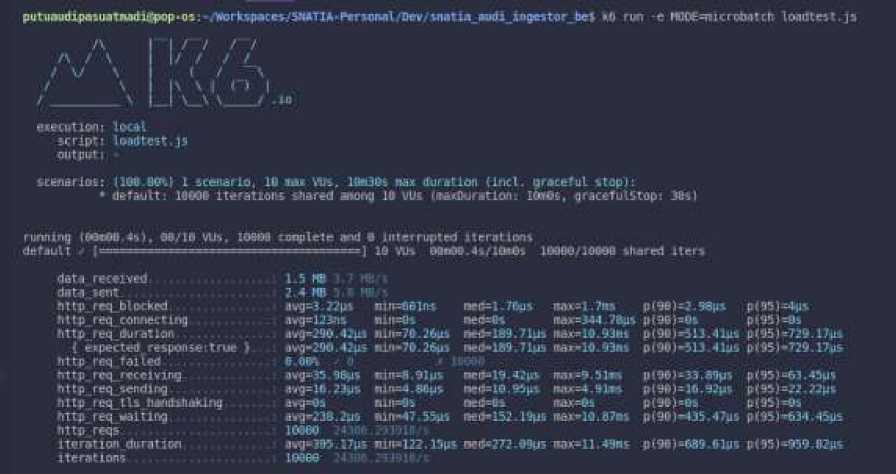
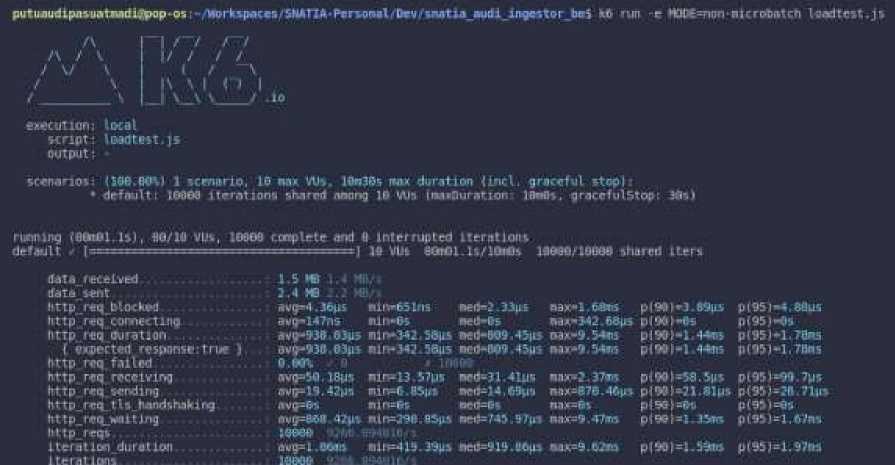
dan diubah menjadi obyek seperti pada baris ke-8 dan baris ke-9. Proses pemilihan apakah akan melakukan Load-Testing terhadap Micro-Batching atau tidak berada pada baris ke-12 sampai dengan baris ke-21. Kemudian pemilihan sampel data dan pengiriman data dapat dijumpai pada baris ke-23 sampai dengan baris ke-33. Kemudian proses Load-Testing dijalankan terhadap Micro-Batch dan tanpa Micro-Batch dengan 10000 data dan juga 10 Virtual User untuk mengetahui performa kecepatan dari kedua metode tersebut. Sehingga didapatkan hasil dari Load-Testing seperti pada Gambar 3 dan juga Gambar 4 di bawah.
PutuaudipaiuaTnadirpop* os Wirktpaces/SMTIA'Morsorwil Dev Λ∏atia Midi xngcitor bel ∙,0 run -e MOOE≡πicγoCj<i! ct I Ofldtes t. j ∙.
IBaBeziOOOd vhared Iten
neftlfi.4*μs
p(9∙)TO89 GWi
w*≡272-<¾∣5
TOX=Ll.4≡M
p(95)TO59.B2μs
TOX=I . 7« TOx=344 78μι Mj≠L0.93ds
Toi-LO 93a s
p(95)=⅜ι⅛ MW)≡8⅛ p r 95 J «729.17*11 p(95)-729.17μs
aed=0⅜ Md∙152.19Mi
OBXTOk TOr-LOiBTli
πιn=0Bim
Dlfl=Gl Dlli=TO. 26m nl∏-70.26uι
p(9∙)TO3.β9μs p(90)=10.92μt P(M)TOk p (90) *435.47us
0VQ"3B5.l7μS m∏≡L22.13m
IME6 ι
∣h∏TO.filμs niπ=4.8βμs tll!l=O⅛ ħlh-47 55μ⅛
p(95)TO3.43μs p(95)=Z2.7Jμβ p(95)TO⅛ p(95)TO34.45μs
e>etution i local script: ITOftiMtJs output I
data received data .>βnt Mtp-req blocked Mtpr eq connect Ing MtpjeqJfcjfatiCm
( expected responsettrue ) http req failed Mtp req receiving Dttp req sending Mtp r eq tis Garirlxfukklng Mti req waiting http reqs Iteretion duration iterations
running (BBTOflfls)a 9β∕lβ VUs, IOBBfl complete and * interrupted iteration1 de fault (==---==-— = -----——=—= ---=-=-=-==] Ifi Ws Mn0B. 4sf IOsBs
SLfefidrlui: Ilfiu W∖) 1 scenario, 19 ιaκ Ws. IttGM MX duration (lncI. graceful stop):
• default: IOfiOB Iterations shared a*ong IB VUs (TOdkjritlon. ItaPs, qrιceTul5top: JOsl
1.5 MB 2 4 MB avg=3.22pι Jivg=IJins ∣vg=29O.'l.,μ avg-290.42μs O-OM ' ovg=35 Mμι Jtvg=Jfi 23μ> a Vg=O s ∂⅛q-238.2uo
ιoew i
BPO=I-TBps aedTO⅞ nTOτlS9. 7Lμa BfeO-LW) 7 Lus
p(WX-5⅜B p(≡)Mh p(90)=51J.41m P (90 MU 41u5
Gambar 3. Hasil Load-Testing dari Micro-Batch K6
PutuaudipnsuaTjuidiJpop
lflθefii'100ββ shared
P(95]>1,97M
wiπ≈1357μι biπ≡6 B5μs
p(W)=56.5μs p<WWl,βlμs
p(95)TO9 7μs p(95>Λ.71∣r p (Mi TOs p(M)≡l,B∕n⅞
p(9∙ M-BSiiS P∣M)→S p(W>-E4*w PlWH TOM
0(95 IM. OflUG p(951-05 p(95)*1.7aαs
P(95)∙I.7Bns
local
Iwrttest ]s
wft31.41μ≡ ∙TO≈14,Wμs ■TOTO» Ded=M5*7μs
mc⅞ιtiαn script output
DBX-I. BttfiS Dβι-342.58μs MX-9.54<⅛ MxTO 54λs
MX*2.37ws nnx=B7e,46μs nnχ=B> nnx=9,47<λ
BiftTOSlns ιtln-βs IliftTOtt, Sβμs
Dlf>-3425BUS
rιwmιng (fiβπ61.1s∣l MZlfi VUs, IBfiBfi cατplete and O interrupted iterations default (—===========—j ∣fl vut etaOl.il/ltafis
(IM WM 1 scenario. Ifi wax Ws. IMfis MX duration (mcl. graceful stop I default! IBBBfl iterations shared naoπg IB Ws imaaDuratior JRwfli1 graceful.Stop
1.5 KB 1.4 Mi 2.4 « avg*4.Jous Rvq-IflTns OVfTOM 6⅛5 avg-938 63u5 O.Wl O avg≡54∣118μs wvg>19.42μι ItvgTOs Ovg=BfiR 42μs JWW . βvg=l. BOsrs
r*ed-'2 .33μs Fietl-Os ∙W-W9,45μs DCd-Wl 45U5
data received rfatfi s*∩t http r∙βq blockM http req"connecting http req duration
( eιperteπ response:true ) http req failed http req receiving http req sending httP-Γcq 11 S-Iwdshaki ng kt tp_ req_wo i tJ ng httpreqs L Ier at Ioridurat Lon
1 Leratltini
Gambar 4. Hasil Load-Testing dari tanpa Micro-Batch K6
Dalam pengukuran kinerja dari metode Micro-Batching dan juga tanpa Micro-Batching pada penelitian ini, dapat menggunakan perbandingan dari hasil Load-Testing pada kedua metode tersebut.
Perbandingan dapat dilihat dengan mudah pada Tabel 6 di bawah.
Tabel 6. Perbandingan Performa Kecepatan
|
Metris |
Micro-Batching |
Tanpa Micro-Batching |
Performa Tertinggi |
|
total waktu |
0.4 detik |
1.1 detik |
Micro-Batching |
|
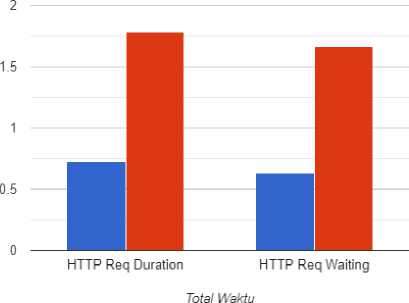
http_req_duration |
729.16 mikrodetik |
1.78 milidetik |
Micro-Batching |
|
http_req_waiting |
634.45 mikrodetik |
1.67 milidetik |
Micro-Batching |
Pada tabel di atas, metris http_req_duration dan juga http_req_waiting menggunakan p(95) atau persentase request pada kecepatan yang jatuh pada persentase ke-95 agar lebih tepat dan menghindari outlier. Nilai – nilai metris ini didapatkan dari hasil pengujian menggunakan Load-Testing. Kemudian hasil penelitian divisualisasikan pada dua grafik di bawah, dan dapat terlihat dengan lebih jelas bagaimana perbandingan dari kedua metode tersebut.
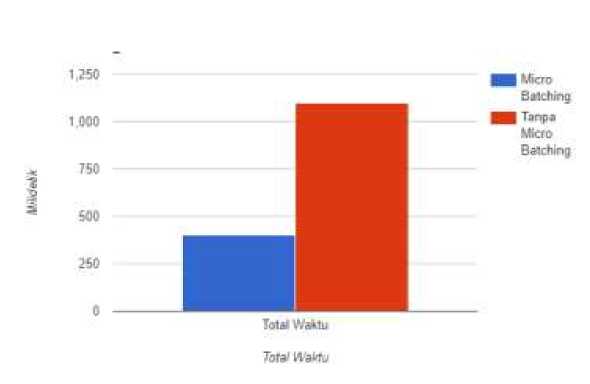
Gambar 5. Grafik visualisasi hasil pengujian total waktu
B Micro Batching
M Tanpa Micro Batching
Gambar 6. Grafik visualisasi hasil pengujian Http Req Duration & Req Waiting
Berdasarkan penelitian, ditemui bahwa menggunakan Micro-Batching memiliki keunggulan performa kecepatan jika dibandingkan dengan tidak menggunakan Micro-Batching atau tanpa Micro-Batching. Didapatkan bahwa menggunakan Micro-Batching lebih cepat dalam hal total durasi sebesar 63.63%, http_req_duration sebesar 59.03%, dan http_req_waiting sebesar 62%. Berdasarkan performa kecepatan yang diperoleh, ditunjukkan bahwa Micro-Batching baik digunakan dalam proses Load pada Extract, Transform, Load atau ETL pada Event-Data karena memiliki performa kecepatan yang lebih unggul. Menggunakan Micro-Batching lebih unggul karena menghindari Repeated TCP karena inisiasi koneksi TCP dilakukan untuk setiap Micro-Batch dan tidak setiap data melakukan inisiasi koneksi TCP.
References
-
[1] N. Shakhovska, N. Boyko, Y. Zasoba e E. Benova, “Big Data Processing Technologies in Distributed Information Systems,” 2019.
-
[2] J. C. Nwokeji, F. Aqlan, A. Apoorva e A. Olagunju, “Big Data ETL Implementation Approaches: A Systematic Literature Review,” 2018.
-
[3] M. Richards e N. Ford, Fundamentals of Software Architecture: An Engineering Approach, O'Reilly Media, Incorporated, 2020.
-
[4] U. Kroehne e F. Goldhammer, “How To Conceptualize, Represent, and Analyze Log Data From Technology-Based Assessments? A Generic Framework and an Application to Questionnaire Items,” Behaviormetrika, vol. 45, nº 2, pp. 527-563, 10 2018.
-
[5] M. Bauer, A. Senderovich, A. Gal, L. Grunske e M. Weidlich, “How Much Event Data Is Enough? A Statistical Framework for Process Discovery,” Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 10816 LNCS, pp. 239-256, 2018.
-
[6] A. R. Chen, “An Empirical Study on Leveraging Logs for Debugging Production Failures,” 2019.
-
[7] A. Sabtu, N. F. M. Azmi, N. N. A. Sjarif, S. A. Ismail, O. M. Yusop, H. Sarkan e S. Chuprat, “The Challenges of Extract, Transform and Loading (ETL) System Implementation For Near RealTime Environment,” Langkawi, Malaysia, 2017.
-
[8] Y. Oyama, T. Ben-Nun, T. Hoefler e S. Matsuoka, “Less is More: Accelerating Deep Neural Networks with Micro-Batching,” IPSJ SIG Technical Report, Vols. %1 de %22017-HPC-162, nº 22, 2017.
-
[9] A. S. Abdelhamid, A. R. Mahmood, A. Daghistani e W. G. Aref, “Prompt: Dynamic Data-Partitioning for Distributed Micro-batch Stream Processing Systems,” 2020.
-
[10] M. Kleppmann, Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems, 1 ed., O'Reilly Media, Inc, 2017.
-
[11] T. Akidau, S. Chernyak e R. Lax, Streaming Systems: The What, Where, When, and how of Large-scale Data Processing, O'Reilly, 2018.
-
[12] A. Bellemare, Building Event-Driven Microservices: Leveraging Organizational Data at Scale, O'Reilly Media, Incorporated, 2020.
Pasuatmadi and Mahendra Analisis Performa Kecepatan Pemrosesan Big Data Dengan Menggunakan Micro Batching Dalam Tahap Load Pada ETL Untuk Event-Data
-
[13] J. Lee, G. Yang, Z. Niu, P. Cheng, Y. Xiong e C. Yoo, “Enhanced control path for repeated TCP connections,” 2020.
-
[14] N. A. Nor Sobri, M. A. H. Abas, A. I. Mohd Yassin, M. S. A. Megat Ali, N. Md Tahir e A. Zabidi, “Database Connection Pool in Microservice Architecture,” Journal of Electrical & Electronic Systems Research, vol. 20, nº APR2022, pp. 29-33, 4 2022.
-
[15] H. Schulz, T. Angerstein e A. Van Hoorn, “Towards Automating Representative Load Testing in Continuous Software Engineering,” 2018.
-
[16] M. Chadha, A. Jindal e M. Gerndt, “Architecture-Specific Performance Optimization of ComputeIntensive FaaS Functions,” 2021.
Please submit paper in doc or docx format. You can directly write your paper in this document. PDF file format is not recommended.
668
Discussion and feedback