Klasifikasi Emosi Lirik Lagu dengan Long Short Term Memory dan Word2Vec
on
JNATIA Volume 1, Nomor 4, Agustus 2023
Jurnal Nasional Teknologi Informasi dan Aplikasinya
p-ISSN: 2986-3929
Klasifikasi Emosi Lirik Lagu dengan Long Short-Term Memory dan Word2Vec
I Putu Diska Fortunawan1, Ngurah Agus Sanjaya ER 2
Program Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana
Jalan Raya Kampus Udayana, Bukit Jimbaran, Kuta Selatan, Badung, Bali Indonesia
1diskafortunawan@gmail.com 2agus_sanjaya@unud.ac.id
Abstract
This research focuses on the classification of emotions in song lyrics using LSTM (Long ShortTerm Memory) and Word2Vec embedding. Emotion classification in lyrics plays a crucial role in music recommendation systems, sentiment analysis, and understanding the affective aspects of music. The study explores the effectiveness of LSTM, a type of recurrent neural network (RNN), in capturing the sequential dependencies and patterns in lyrics, combined with Word2Vec embedding to represent the semantic meaning of words.The dataset consists of a collection of song lyrics labeled with 2 emotions. The lyrics are preprocessed and converted into word vectors using the Word2Vec model. The LSTM model is then trained on the preprocessed lyrics data, aiming to predict the corresponding emotion category for a given set of lyrics. Experimental results demonstrate that the proposed approach achieves a maximum accuracy of 72.8% in classifying emotions in song lyrics. The LSTM model leverages the sequential information in the lyrics to capture the emotional context effectively. The Word2Vec embedding enhances the representation of words, allowing the model to understand the semantic relationships between words and better discriminate between different emotional categories.
Keywords: Text Processing, Classification, LSTM, Word2Vec
dah” yang berisikan kumpulan lagu-lagu sedih yang merupakan kebalikan dari emosi Bahagia. Data yang digunakan hanya memiliki label “Bahagia” dan “sedih” dengan nilai 1 pada label jika merupakan lagu Bahagia dan nilai 0 jika merupakan lagu sedih.
-
2.2 Preprocessing
Setelah data didapatkan dan dikumpulkan, perlu dilakukan preprocessing sebelum data siap untuk dijadikan sebagai data training. Proses ini akan menghilangkan noise atau data yang sekiranya tidak penting dan tidak diperlukan. Tahapan preprocessing yang dilakukan adalah:
-
a. Case Folding
Pada tahapan ini, jika ditemukan character yang merupakan uppercase maka character ini akan diubah menjadi lowercase
-
b. Punctuation Removal
Proses ini menghilangkan/menghapus tanda baca yang ada pada lirik lagu seperti koma(,), titik(.) dan tanda baca lain yang tidak diperlukan dalam proses.
-
c. Normalization
Tahapan ini akan mengubah kata-kata yang merupakan bahasa gaul ataupun bahasa yang tidak baku ke dalam bentuk bakunya.
-
d. Stemming
Menghilangkan imbuhan pada kata, imbuhan ini termasuk awalan, sisipan, maupun akhiran. Sehingga kata menjadi kata dasar.
-
e. Stopword Removal
Menghilangkan kata-kata yang sering muncul yang bersifat umum atau tidak memiliki makna terhadap kalimat.
-
f. Tokenization
Kalimat akan dipecah menjadi bagian yang lebih kecil yaitu kata.
-
2.3 Word2Vec Embedding
Untuk mengerti lebih dalam mengenai konteks yang ada dalam lirik lagu, kita memerlukan word embedding khususnya Word2Vec. Word2Vec dapat memecahkan masalah mewakili hubungan kata kontekstual dalam ruang fitur yang dapat dihitung [2]. Metode Word2Vec berfokus pada ide bahwa kata-kata yang sering muncul bersama memiliki kesamaan makna atau konteks. Word2Vec memanfaatkan data teks yang besar untuk melatih model yang dapat menghasilkan representasi vektor kata-kata tersebut. Ada 2 argumen yang akan digunakan yaitu max_input_length dan embed dimension.
-
2.4 Long Short-Term Memory (LSTM)
LSTM merupakan salah satu contoh model RNN (Recurrent Neural Network). LSTM dapat bekerja lebih baik dibandingkan RNN karena LSTM dapat mengatasi masalah vanishing gradient yang ditemukan pada RNN [3]. Masalah ini diatasi dengan menggunakan blok memory-cell yang terdiri dari input gate, forget gate dan output gate untuk mengganti lapisan RNN [4]. LSTM memiliki memiliki koneksi berulang atau struktur yang seperti rantai Fungsi-fungsi tiap gate pada LSTM adalah:
-
a. Forget Gate
Gerbang ini bertugas untuk melupakan beberapa informasi yang tidak relevan dan sudah tidak diperlukan oleh sebuah sistem. Alhasil, LSTM dapat menyajikan kumpulan informasi yang lengkap, tetapi tetap aktual sesuai dengan kebutuhan.
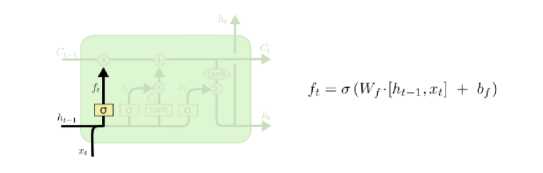
Gambar 1. Forget gate [5]
Untuk menentukan apakah informasi dari state sebelumnya disimpan atau tidak, ditentukan dengan fungsi sigmoid, fungsi ini akan menghasilkan ft antara 0 dan 1. Jika dihasilkan 0 maka semua informasi akan dilupakan, sebaliknya jika dihasilkan 1 maka tidak ada informasi yang dilupakan.
-
b. Input Gate
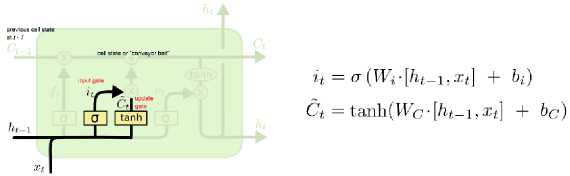
Gambar 2. Input Gate [5]
Tugas input gate adalah untuk menambahkan informasi yang sebelumnya telah diseleksi terlebih dahulu melalui gerbang forget gate. Gerbang ini tidak dimiliki oleh RNN yang hanya memungkinkan satu input data untuk satu output data. Dalam input gate kemudian dikenal istilah input modulation gate. Sesuai namanya, input modulation gate berfungsi untuk memodulasi informasi yang ada, sehingga dapat mengurangi kecepatan konvergensi dari data zero-mean. Pada gate ini juga diaplikasi fungsi sigmoid yang juga akan memiliki nilai antara 0 dan 1. Sekarang informasi baru yang perlu diteruskan ke state cell adalah fungsi dari state tersembunyi pada timestamp t-1 sebelumnya dan masukan x pada timestamp t. Fungsi aktivasi di sini adalah tanh. Karena fungsi tanh, nilai informasi baru akan berada di antara -1 dan 1. Jika nilai Nt negatif, informasi dikurangi dari keadaan sel, dan jika nilainya positif, informasi ditambahkan ke state cell pada timestamp saat ini.
-
c. Output Gate
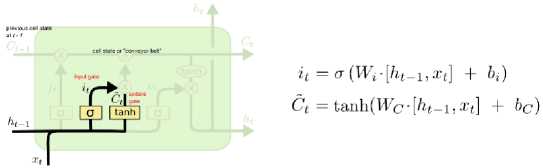
Gambar 3. Output Gate [5]
Output gate menjadi gerbang terakhir untuk menghasilkan informasi data yang komplet dan aktual. Gerbang ini bisa menjadi yang terakhir atas sebuah informasi atau hanya menjadi bagian dari tahap pertama saja, sebelum akhirnya informasi akan diproses lewat input gate di sel berikutnya. Perhitungan pada output gate juga sangat mirip dengan gategate sebelumnya, nilainya juga akan berada diantara 0 dan 1. Untuk menghitung status hidden state saat ini, digunakan Ot dan tanh dari cell state yang diperbarui.
Data yang digunakan diperoleh dari Genius, data yang digunakan hanyalah data teks, yaitu lirik lagu itu sendiri tanpa menggunakan data audio dari lagu. Dataset yang digunakan berjumlah 90 lagu dengan label 1 yang berarti lagu bahagia, sedangkan label 0 yang merupakan lagu sedih, Setiap label terdiri dari masing masing 45 lagu.Data yang dikumpulkan dapat dilihat pada Gambar 4.
Pengambilan Data
lyrics
0 Sandarkan lelahmu dan ceritakan Tentang apapu... 1 Menyesalj tak kusampaikan Cinta monyetku ke K... 2 Kapan terakhir kali kamu dapat tertidur tenan... 3 Salahkah bila ku mencinta Salahkah bila semua ... 4 Kuingin cinta hadir untuk selamanya Bukan han...
85 Biar aku sentuhmu Berikan ku rasa itu Pelukmu ... 86 Hujan tak juga reda Ku harus menyaksikan cinta... 87 Belum sempat ku membagi Kebahagia-anku Belum s... 88 Pedihnya tanya yang tak terjawab Mampu menjat... 89 Tika wangimu saja bisa Memindahkan duniaku Ma...
Gambar 4. Hasil Pengambilan Data
Data yang telah didapatkan tadi kemudian dikenakan preprocessing sebelum diproses lebih lanjut rincian tahapannya dapat dilihat pada Tabel 1.
Tabel 1. Preprocessing data
|
Tahapan |
Hasil |
|
Data Awal |
Menari bersamaku Temani hingga akhir waktu Jalani bersamaku Kau pasti 'kan bahagia Kutemani dirimu Di setiap perjalanan cinta |
|
Case Folding |
menari bersamaku temani hingga akhir waktu jalani bersamaku kau pasti 'kan bahagia kutemani dirimu di setiap perjalanan cinta |
|
Tahapan |
Hasil |
|
Normalization |
menari bersamaku temani hingga akhir waktu jalani bersamaku kau pasti akan bahagia kutemani dirimu di setiap perjalanan cinta |
|
Punctuation Removal |
menari bersamaku temani hingga akhir waktu jalani bersamaku kau pasti akan bahagia kutemani dirimu di setiap perjalanan cinta |
|
Stemming |
menari bersama teman hingga akhir waktu jalani bersama kau pasti akan bahagia teman kamu setiap jalan cinta |
|
Stopword Removal |
menari bersama teman hingga akhir jalani bersama bahagia teman kamu setiap jalan cinta |
|
Tokenization |
menari, bersama, teman, hingga, akhir, jalani, bahagia, kamu, setiap, cinta |
Setelah dilakukan tokenization ditemukan sebanyak 1686 kamus data atau jumlah kata unik dari lirik lagu yang telah dikumpulkan. Setelah itu, data akan dibagi menjadi data latih dan data uji, data uji diambil dari 20% dataset yang telah didapatkan
Pemodelan diawali dengan melakukan penambahan lapisan embedding untuk mengubah kata ke dalam bentuk vector dengan max_input length = jumlah unique word, serta embed dim = 100. Digunakan pula 2 layer LSTM dengan unit masing masing sebanyak 64 unit dan dropout rate 0.1 Detail dari model yang digunakan adalah sebagai berikut:
Tabel 2. Model LSTM
|
Layer |
Jumlah |
Addition |
|
Embedding |
Max_input_length = 1686, embed dim = 100 | |
|
LSTM |
64 Unit |
Dropout Rate = 0.1 |
|
LSTM |
64 Unit |
Dropout Rate = 0.1 |
|
Dense |
1 Unit |
Activation = sigmoid |
Training dilakukan sebanyak 3 kali dengan epoch dan jumlah data yang berbeda-beda, seperti pada tabel berikut:
Tabel 3. Hasil Training
|
Keterangan |
Hasil |
|
Epoch 50 dataset 60 |
52.6% |
|
Epoch 100 dataset 90 |
68.3% |
|
Epoch 50 dataset 60 |
58.8% |
|
Epoch 100 Dataset 90 |
72.8 % |
Dari Penelitian yang telah dilakukan, didapatkan hasil akurasi tertinggi yaitu 72.8 %, nilai tersebut akan berubah sesuai dengan perubahan hyperparameter. Akurasi dapat ditingkatkan dengan menambah dataset dan cleani
Daftar Pustaka
-
[1] Wang, J.H., Liu, T.W., Luo, X. and Wang, L., 2018, October. An LSTM approach to short text sentiment classification with word embeddings. In Proceedings of the 30th conference on computational linguistics and speech processing (ROCLING 2018) (pp. 214-223).
-
[2] Sari, W.K., Rini, D.P., Malik, R.F. and Azhar, I.S.B., 2020. Multilabel Text Classification in News Articles Using Long-Term Memory with Word2Vec. Jurnal RESTI (Rekayasa Sistem dan Teknologi Informasi), 4(2), pp.276-285.
-
[3] Nugroho, K.S., Akbar, I. and Suksmawati, A.N., 2023. Deteksi Depresi dan Kecemasan
Pengguna Twitter Menggunakan Bidirectional LSTM. arXiv preprint arXiv:2301.04521.
-
[4] Fajri, F.N. and Syaiful, S., 2022. Klasifikasi Nama Paket Pengadaan Menggunakan Long
Short-Term Memory (LSTM) Pada Data Pengadaan. Building of Informatics, Technology and Science (BITS), 4(3), pp.1625-1633.
-
[5] Eddine, B.C. (2021) LSTM Model for the Prediction of PM2.5 Concentration in city of Algiers.
1208
Discussion and feedback