Pengelompokkan Provinsi di Indonesia Berdasarkan PDRB atas Dasar Harga Konstan Tahun 2013
on
Jurnal Matematika Vol. 7, No. 2, Desember 2017, pp. 76-84 ISSN: 1693-1394
Article DOI: 10.24843/JMAT.2017.v07.i02.p84
Pengelompokkan Provinsi di Indonesia Berdasarkan PDRB atas Dasar Harga Konstan Tahun 2013
Ferry Kondo Lembang
Jurusan Matematika Universitas Pattimura Ambon ferrykondolembang@gmail.com
Patresya Yulita Lessil
Jurusan Matematika Universitas Pattimura Ambon e-mail: lessil@yahoo.com
Salmon Notje Aulele
Jurusan Matematika Universitas Pattimura Ambon salmon.aulele@yahoo.com
Abstract: Regional gross domestic product is one of the important indicators to determine economic conditions in an area. Therefore it is very interesting to discuss and to determine the economic progress of a region. Cluster anlysis aims to classify objects based on the characteristics into cluster that have the properties that are relatively similar and clearly distinguish between one cluster agains another. The main objective of the research that classifies 33 provinces based on the value of regional gross domestic product at constant price in 2013 using hierarchical cluster analysis for average linkage method. The results showed that the cluster were carried out on 33 provinces in Indonesia formed 3 cluster with details of that cluster 1 consisting of Sumatera, Kalimantan, Sulawesi, Nusa Tenggara, Bali, Papua, Maluku and Jawa Tengah, DI Yogyakarta, and Banten, cluster 2 consisting of 1 provinces of DKI Jakarta and cluster 3 which consists of 2 provinces namely Jawa Barat dan Jawa Timur.
Keywords: Regional Gross Domestic Product at constant prices, Hierarchical Cluster Analysis, Method of Average Linkage
Indonesia merupakan salah satu negara di dunia yang sedang giat dalam melakukan pembangunan di segala bidang, salah satunya adalah pembangunan dalam bidang ekonomi. Sampai saat ini Indonesia terus melakukan pembangunan di daerah-daerah untuk mengubah struktur perekonomiannya ke arah yang lebih baik. Perkembangan ekonomi yang dilakukan dengan tujuan untuk pemerataan pembangunan yang dirasakan oleh semua masyarakat yang tersebar di provinsi di Indonesia baik dengan meningkatkan kesempatan kerja dan pemerataan pendapatan serta mampu mengurangi
ketimpangan antarprovinsi di Indonesia. Ketimpangan yang terjadi menjadi salah satu perhatian pemerintah dalam mengatasi dan mencari solusi terhadap masalah tersebut. Untuk itu fokus untuk mengatasi masalah tersebut haruslah dilakukan pada kondisi ekonomi di setiap provinsi dengan memperhatikan indikator penting yakni Nilai Produk Domestik Regional Bruto (PDRB).
PDRB merupakan salah satu indikator penting untuk mengetahui kondisi ekonomi di suatu daerah dalam suatu periode tertentu, baik atas dasar harga berlaku maupun atas dasar harga konstan. PDRB pada dasarnya merupakan jumlah nilai tambah yang dihasilkan oleh seluruh unit usaha dalam suatu daerah tertentu, ataupun merupakan jumlah nilai barang dan jasa akhir yang dihasilkan oleh seluruh unit ekonomi pada suatu daerah. PDRB atas dasar harga konstan merupakan jumlah seluruh nilai barang dan jasa akhir yang dihasilkan oleh unit-unit produksi dalam tahun berjalan yang dinilai atas dasar harga pada tahun dasar. Oleh karena itu, diperlukan suatu kajian tentang penge-lompokkan provinsi di Indonesia berdasarkan indikator PDRB sebagai upaya pemerataan pembangunan ekonomi di setiap wilayah. Salah satu metode pengelompokkan yang populer adalah dengan menggunakan analisis cluster.
Analisis cluster merupakan suatu analisis data eksploratori yang bertujuan untuk mengelompokkan objek-objek berdasarkan karakteristik di antara objek-objek itu menjadi kelompok-kelompok yang mempunyai sifat-sifat yang relatif sama serta untuk membedakan dengan jelas antara satu kelompok dengan kelompok lainnya. Berdasarkan penjelasan tersebut maka peneliti berkeinginan melakukan penelitian untuk meneliti pembentukan kelompok provinsi-provinsi terhadap PDRB atas dasar harga konstan dengan mengunakan pendekatan analisis cluster hirarki metode pautan rata-rata (average linkage). Pada metode ini, jarak antara dua cluster dianggap sebagai jarak rata-rata antara semua anggota dalam satu cluster dengan semua anggota cluster lain. Metode ini telah diterapkan pada beberapa penelitian antara lain oleh Laeli [1] tentang pembandingan metode average linkage dan metode ward untuk pengelompokkan responden terkait alasan memutuskan untuk membeli produk Asuransi Jiwa Unit Link. Hasil penelitian diperoleh bahwa kinerja metode average linkage lebih baik daripada metode Ward berdasarkan kriteria simpangan baku dalam kelompok (SW) dan simpangan baku antar kelompok (SB) terkecil. Selanjutnya penelitian yang dilakukan oleh Barus, et al.[2] tentang pengelompokkan kabupaten di Provinsi Bali berdasarkan perkembangan fasilitas wisata menggunakan pendekatan analisis cluster hirarki metode average linkage dan analisis biplot.
Analisis multivariat adalah analisis statistik yang digunakan untuk menganalisis data yang terdiri beberapa variabel dan variable-variabel tersebut saling berkorelasi satu sama lain. Secara umum analisis multivariat terbagi atas dua bagian yakni analisis dependensi dan analisis interdependensi. Ciri khas analisis dependensi yaitu terdapat satu atau beberapa variabel yang berfungsi sebagai variabel terikat dan variable bebas
antara lain analisis regresi berganda, analisis diskriminan, analisis multivariat varians, analisis logit. dan analisis korelasi kanonikal. Sedangkan ciri analisis interdependensi adalah semua variable bersifat bebas contohnya analisis faktor, analisis cluster dan multidimensional scalling [3].
Analisis cluster adalah analisis untuk pengelompokkan elemen yang mirip sebagai objek penelitian untuk menjadi kelompok atau cluster yang berbeda dan mutually exclusive. Analisis cluster termasuk dalam analisis statistik multivariat metode interde-penden, dan oleh karena itu tujuan analisis cluster tidak untuk menghubungkan ataupun membedakan dengan sampel atau variabel lain. Analisis cluster berguna untuk meringkas data dengan jalan mengelompokkan objek-objek berdasarkan kesamaan karakteristik tertentu di antara objek-objek berdasarkan kesamaan karakteristik tertentu di antara objek-objek yang akan diteliti. Analisis cluster terbagi atas dua metode yaitu metode hirarki dan metode non-hirarki [4].
Metode hirarki dimulai dengan pengelompokkan dua atau lebih objek yang mempunyai kesamaan yang paling dekat. Kemudian proses diteruskan ke objek lain yang mempunyai kedekatan kedua. Demikian seterusnya sampai cluster akan membentuk semacam “pohon” hirarki (tingkatan yang jelas antarobjek dari yang paling mirip sampai yang paling tidak mirip. Dendogram biasanya digunakan untuk membantu memperjelas proses hirarki tersebut. Metode-metode pengelompokkan hirarki dibedakan berdasarkan konsep jarak antarkelompok, penentuan jarak, antarkelompok untuk metode-metode tersebut adalah :
-
1. Single-lingkage (pautan tunggal), metode dengan prinsip jarak minimum.
-
2. Complete linkage (pautan lengkap), metode dengan prinsip jarak maksimum.
-
3. Average linkage (pautan rata-rata), metode dengan prinsip jarak rata-rata
-
4. Ward’s method, metode ini menggunakan perhitungan yang lengkap dan memaksimumkan homogenitas di dalam satu kelompok.
-
5. Centroid method (metode titik pusat), metode yang menggunakan rata-rata jarak pada sebuah kelompok yang diperoleh dengan cara menghitung rata-rata pada setiap variabel untuk semua objek.
Pada metode non-hirarki, digunakan jarak euclid untuk menetapkan nilai kedekatan antarobjek. Bakal cluster pertama adalah observasi pertama dalam set data. Bakal kedua adalah observasi lengkap berikutnya yang dipisahkan dari bakal pertama oleh jarak minimum khusus.
Adapun ciri-ciri analisis cluster yaitu homogenitas (kesamaan) yang tinggi antar anggota dalam satu cluster dan heterogenitas (perbedaan) yang tinggi antar cluster yang satu dengan cluster yang lain.
Beberapa proses pembuatan cluster dengan metode hirarki yaitu menentukan ketakmiripan antara kedua objek. Proses terutama yaitu mengukur seberapa jauh ada kesamaan antarobjek. Dengan memiliki sebuah ukuran yang kuantitatif untuk menga-
takan dua objek tertentu lebih mirip dibandingkan dengan objek lain, akan mempermudah proses pengclusteran. Salah satu yang bisa menjadi ukuran ketidakmiripan adalah fungsi jarak antara objek a dan b, yang biasanya dinotasikan dengan d( a, b ). Adapun
sifat-sifat ketidakmiripan adalah :
-
1. da a, b ) ≥ 0
-
2. d( a, b) = 0
-
3. d(a, b) = d(b,a)
-
4. aa> b )meningkat seiring semakin tidak mripnya kedua objek a dan b.
-
5. d( a, b) ≤ d(a, b) + d(b,e')
Jarak paling umum digunakan yaitu Euclidian. Ukuran jarak atau ketidaksamaan antar objek ke- i dengan objek ke-⅛, dapat disimbolkan dengan d^l. Adapun nilai di
diperoleh dengan perhitungan jarak kuadrat sebagai berikut:
dih = ∑χχ--χ)?
(1)
dengan :
d i h = jarak kuadrat Euclidian antar objek ke- i dengan objek ke-⅛ xij = nilai dari objek ke- i pada variabel ke-j
xhj = nilai dari objek ke-h pada variabel ke-j
Selanjutnya yaitu pembuatan cluster dengan menggunakan metode hirarki. Pada metode ini dilakukan dengan mengelompokkan data yang mempunyai kesamaan yang paling dekat. Kemudian diteruskan ke objek lain yang mempunyai kedekatan kedua. Demikian seterusnya sehingga kelompok akan membentuk semacam pohon, dimana ada hirarki yang jelas antar objek, dari yang paling mirip sampai yang paling tidak mirip. Hasil average linkage clustering dapat disajikan dalam bentuk suatu dendogram atau diagram pohon. Cabang-cabang pohon menunjukan cluster. Cabang-cabang tersebut bertemu bersama-sama pada simpul yang posisinya sepanjang suatu sumbu jarak (kemiripan). Ini menunjukkan tingkat di mana penggabungan terjadi. Setelah cluster terbentuk, selanjutnya yaitu melakukan interpretasi terhadap cluster yang terbentuk [5].
Data yang digunakan dalam penelitian ini adalah data sekunder yang diperoleh dari Badan Pusat Statistik (BPS) Provinsi Maluku yaitu data PDRB Atas Dasar Harga Konstan tahun 2013 di seluruh Provinsi di Indonesia.
Dalam penelitian ini digunakan data PDRB atas dasar harga konstan tahun 2013 yang terdiri dari variabel-variabel sebagai berikut :
-
a) Pengeluaran Konsumsi Rumah Tangga / Households Consumption Expenditure
-
(X1).
-
b) Pengeluaran Konsumsi Lembaga Swasta Nirlaba Yang Melayani Rumah Tangga / Non-Profit Institutions Serving Household Comsumption Expenditure (X2)
-
c) Pengeluaran Konsumsi Pemerintah / General Government Consumption Expenditure (X3)
-
d) Pembentukan Modal Tetap Bruto / Gross Fixed Capital Formation (X4)
-
e) Perubahan Persediaan / Change In Inventories (X5)
-
f) Ekspor Barang Dan Jasa / Export Of Goods And Services (X6)
-
g) Dikurangi Impor Barang Dan Jasa / Less Import Of Goods And Services (X7). Metode analisis yang digunakan berkaitan dengan tujuan penelitian ini adalah sebagai berikut :
-
a) Perumusan Masalah
-
b) Melakukan proses standarisasi data jika diperlukan
-
c) Menetapkan ukuran antar jarak antar data menggunakan rumus jarak euclid
-
d) Melakukan proses clustering
-
e) Melakukan penamaan cluster-cluster yang terbentuk
-
f) Melakukan validasi dan profiling cluster
-
g) Membuat Kesimpulan
Analisis cluster digunakan untuk melihat pengelompokkan Provinsi di Indonesia berdasarkan PDRB atas dasar harga konstan. Di dalam analisis cluster ini teknik yang digunakan adalah berhirarki dengan metode average linkage (pautan rata-rata). Berikut ini akan disajikan hasil pengelompokkan dalam bentuk tabel dan dendogram.
Tabel 1. Tabel Cluster dan Anggotanya
|
Cluster |
Provinsi anggota 3 cluster |
Provinsi anggota 2 cluster |
|
cluster 1 |
Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Sumatera Selatan, Bengkulu, Lampung, Kepulauan Bangka Belitung, Kepulauan Riau, Jawa Tengah, DI Yogyakarta, Banten, Bali, Nusa Tenggara Barat, Nusa Tenggara Timur, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Sulawesi Utara, Sulawesi Tengah, Sulawesi selatan, Sulawesi Tenggara, Gorontalo, Sulawesi Barat, Maluku, Maluku Utara, Papua, Papua Barat |
Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Sumatera Selatan, Bengkulu, Lampung, Kepulauan Bangka Belitung, Kepulauan Riau, JawaTengah, DI Yogyakarta, Banten, Bali, Nusa Tenggara Barat, Nusa Tenggara Timur, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Sulawesi Utara, Sulawesi Tengah, Sulawesi Selatan, Sulawesi Tenggara, Gorontalo, Sulawesi Barat, Maluku, Maluku Utara, Papua, Papua Barat |
|
cluster 2 |
DKI Jakarta |
DKI Jakarta, Jawa Barat dan Jawa Timur. |
|
cluster 3 |
Jawa Barat dan Jawa Timur. |
Dendrogram using Average Linkage (Betueen Groups)
CASE
|
LalDel |
Niun |
|
Sulawesi Barat |
29 |
|
Haluku |
30 |
|
Haluku Utara |
31 |
|
Gorontalo |
28 |
|
Bengkulu | |
|
Kepulauan Bangka Belitung |
9 |
|
Sulawesi Tenggara |
27 |
|
Nusa Tenggara Barat |
18 |
|
Sulawesi Tengah |
25 |
|
Nusa Tenggara Timur |
19 |
|
Papua Barat |
32 |
|
DI Yogyakarta |
14 |
|
Sulawesi Utara |
24 |
|
Kalimantan Tengah |
21 |
|
Jambi |
5 |
|
Aceh |
1 |
|
Siunatera Barat |
3 |
|
Kalimantan Selatan |
22 |
|
Papua |
33 |
|
Kalimantan Barat |
20 |
|
Laiupung |
8 |
|
Bali |
17 |
|
Sulawesi Selatan |
26 |
|
Kepulauan Riau |
10 |
|
Siunatera Selatan |
5 |
|
Riau |
4 |
|
Banten |
16 |
|
Kalimantan Timur |
23 |
|
Siunatera Utara |
2 |
|
Jawa Tengah |
13 |
|
Jawa Barat |
12 |
|
Jawa Timur |
15 |
|
DKI Jakarta |
11 |

Gambar 1. Dendogram Analisis Cluster Hirarki Metode Average Linkage
Tabel 1 dan dendogram di atas merupakan penggabungan objek-objek untuk membentuk suatu cluster. Objek Sulawesi Barat, Maluku, Maluku Utara, Gorontalo, Bengkulu, Kepulauan Bangka Belitung, Sulawesi Tenggara, Nusa Teggara Barat, Sulawesi Tengah, Nusa Tenggara Timur, Papua Barat, DI Yogyakarta, Sulawesi Utara, Kalimantan Tengah, Jambi, Aceh, Sumatera Barat, Kalimantan Selatan, Papua, Kalimantan Barat, Lampung, Bali, Sulawesi Selatan, Kepulauan Riau, Sumatera Selatan, dan Riau bergabung menjadi 1 cluster, sedangkan objek Banten dan Kalimantan Timur bergabung menjadi cluster 16, kemudian Sumatera Utara dan Jawa Tengah bergabung dengan cluster 16 menjadi cluster 2 yang terdiri dari Sumatera Utara, Jawa Tengah, Banten dan Kalimantan Timur. Jawa Timur dan Jawa barat bergabung menjadi cluster 12. Cluster 2 bergabung dengan cluster 1 menjadi cluster 1 yang terdiri dari Sulawesi Barat, Maluku, Maluku Utara, Gorontalo, Bengkulu, Kepulauan Bangka Belitung, Su-
lawesi Tenggara, Nusa Tenggara Barat, Sulawesi Tengah, Nusa Tenggara Timur, Papua Barat, DI Yogyakarta, Sulawesi Utara, Kalimantan Tengah, Jambi, Aceh, Sumatera Barat, Kalimantan Selatan, Papua, Kalimantan Barat, Lampung, Bali, Sulawesi Selatan, Kepulauan Riau, Sumatera Selatan, Riau, Banten, Kalimantan Timur, Sumatera Utara dan Jawa Tengah, sedangkan DKI Jakarta membentuk cluster sendiri.
Dendogram mempermudah untuk melihat anggota tiap cluster sesuai banyak cluster yang diinginkan. Jika ingin mengetahui anggota cluster yang terdiri dari 3 cluster maka dapat dilihat pada dendogram diperoleh cluster 1 (Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Sumatera Selatan, Bengkulu, Lampung, Kepulauan Bangka Belitung, Kepulauan Riau, Jawa Tengah, DI Yogyakarta, Banten, Bali, Nusa Tenggara Barat, Nusa Tenggara Timur, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Sulawesi Utara, Sulawesi Tengah, Sulawesi Selatan, Sulawesi Tenggara, Gorontalo, Sulawesi Barat, Maluku, Maluku Utara, Papua Barat, Papua, sedangkan cluster 2 (DKI Jakarta) dan cluster 3 (Jawa Barat dan Jawa Timur).
Untuk mengetahui karakteristik setiap cluster maka perlu dihitung nilai rata-rata untuk setiap cluster.
Tabel 2. Tabel Rata-rata Cluster
|
Variabel |
Rata-rata Cluster | ||
|
1 |
2 |
3 | |
|
*1 |
23.215.663,24 |
245.006.734,00 |
264.215.012,10 |
|
424.394,22 |
5.661.298,06 |
2.494.921,14 | |
|
5.235.200,75 |
22.169.160,27 |
24.018.779,94 | |
|
10.791.394,27 |
174.440.893,30 |
73.381.594,26 | |
|
*5 |
1.333.826,53 |
2.653.148,14 |
7.614.113,13 |
|
*6 |
27.703.836,62 |
327.535.757,30 |
196.104.703,00 |
|
^7 |
21.660.510,90 |
300.181.745,70 |
164.663.980,90 |
Dari deskripsi pada tabel 2 diatas, secara umum diketahui bahwa variabel-variabel yang ada memiliki karakteristik yang berbeda tiap cluster. Perbedaan tampak pada cluster 2 yang memiliki rata-rata tinggi pada pengeluaran konsumsi lembaga swasta nirlaba yang melayani rumah tangga dibandingkan cluster 1 dan cluster 3. Selain itu juga cluster 2 memiliki rata-rata tinggi pada ekspor barang dan jasa dan dikurangi impor barang dan jasa namun begitu cluster 2 termasuk dalam cluster sedang karena rata-rata cluster 3 lebih tinggi dari cluster 2 yaitu pada variabel pengeluaran konsumsi rumah tangga,
pengeluaran konsumsi pemerintah, pembentukan modal tetap bruto dan perubahan persediaan sedangkan cluster 1 merupakan cluster dengan rata-rata rendah pada semua variabel.
Dengan demikian dapat disimpulkan bahwa cluster 1 merupakan objek-objek yang pengeluran konsumsi rumah tangga, pengeluaran konsumsi lembaga swasta nirlaba yang mewakili rumah tangga, pengeluaran konsumsi pemerintah, pembentukan modal tetap bruto, perubahan persediaan, ekspor barang dan jasa, dan dikurangi impor barang dan jasa dalam tingkat yang rendah sedangkan cluster 3 pada tingkat yang tinggi dan cluster 2 dalam tingkat yang tidak terlalu tinggi atau dapat dikatakan merupakan cluster dengan tingkatan sedang. Berikut dibawah ini disajikan gambar pengelompok-kan provinsi berdasarkan 3 cluster yang terbentuk.
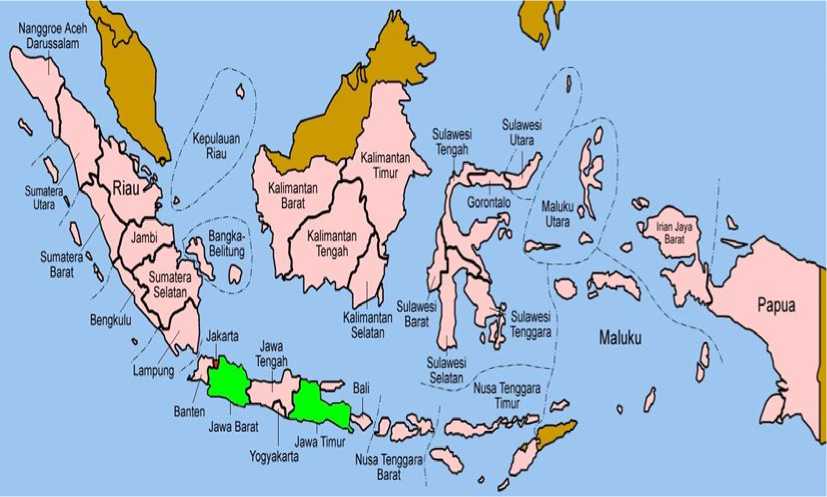
Gambar 2. Hasil Cluster Provinsi di Indonesia
: daerah dengan PDRB rendah
• : daerah dengan PBRB sedang
: daerah dengan PDRB tinggi
Pada pengelompokkan Provinsi berdasarkan PBRB Atas Dasar Harga Konstan menggunakan pendekatan analisis cluster hirarki metode average linkage diperoleh 3 cluster sebagai berikut : cluster 1 yang terdiri dari 30 Provinsi: Aceh, Sumatera Barat, Sumatera Utara, Riau, Jambi, Sumatera Selatan, Bengkulu, Lampung, Kepulauan
Bangka Belitung, Kepulauan Riau, Jawa Tengah, DI Yogyakarta, Banten, Bali, Nusa Tenggara Barat, Nusa Tenggara Timur, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Sulawesi Utara, Sulawesi Tengah, Sulawesi Selatan, Sulawesi Tenggara, Gorontalo, Sulawesi Barat, Maluku, Maluku Utara, Papua dan Papua Barat yang merupaka kelompok dengan PDRB rendah. Cluster 2 yang terdiri dari 1 Provinsi: DKI Jakarta dengan PDRB sedang. Cluster 3 yang terdiri dari 2 Provinsi: Jawa Barat dan Jawa Timur dengan PDRB tinggi.
Daftar Pustaka
-
[1] Laeli, S. 2014. Analisis Cluster dengan Average Linkage Method dan Ward’s Method untu Data Responden Nasabah Asuransi Jiwa Unit Link. Skripsi. Program Studi Matematika. Jurusan Pendidikan Matematika. FMIPA. Universitas Negeri Yogyakarta.
-
[2] Barus, N. S., Kencana, I. P. E. N, dan Sukarsa, K. G., 2013. Pengelompokkan
Kabupaten di Provinsi Bali Berdasarkan Perkembangan Fasilitas Pariwisata. E-Jurnal Matematika Vol. 2. No.3. pp 53-58. FMIPA-Universitas Udayana.
-
[3] Sarwono, J., 2007. Analisis Jalur Untuk Riset Bisnis Dengan SPSS. Yogyakarta: Andi Offset.
-
[4] Hair, et al., 2006. Multivariate Data Analysis. Sixth Edition. New Jersey: Pearson Education
-
[5] Fadhli, 2011. Analisis Cluster Untuk Pemetaan Mutu Pendidikan di Aceh. Tesis.
PPs-UGM
84
Discussion and feedback