Model Partial Least Square Regression (PLSR) Pengaruh Bidang Pendidikan dan Ekonomi Terhadap Tingkat Kemiskinan di Indonesia
on
Jurnal Matematika Vol. 7 No. 1, Juni 2017. ISSN: 1693-1394
Model Partial Least Square Regression (PLSR) Pengaruh Bidang Pendidikan dan Ekonomi Terhadap Tingkat Kemiskinan di Indoneia
Jurusan Matematika, FMIPA, Universitas Udayana, Bukit Jimbaran, Badung (80361) Email: srinadi@unud.ac.id
Abstract: Partial Least Square Regression (PLSR) is one of the methods applied in the estimation of multiple linear regression models when the ordinary least square method (OLS) can not be used. OLS generates an invalid model estimate when multicollinearity occurs or when the number of independent variables is greater than the number of data observations. In conditions that OLS can be applied in obtaining model estimation, want to know the performance of PLSR method. This study aims to determine the model of PLSR the influence of literacy rate, the average of school duration, school enrollment rate, Income per capita, and open unemployment rate to the level of poverty seen from the percentage of poor people in Indonesia by 2015. Estimated model with OLS , Only variable of literacy rate are included in the model with the coefficient of determination R2 = 32.52%. PLSR model estimation of cross-validation, leave-one-out method with one selected component has R2 of 33,23%. Both models shows a negative relationship between poverty and literacy rate. The higher literacy rate will reduce the poverty level, indicating that the success of the Indonesian government in the development of education will support the government's success in reducing poverty level.
Keywords: multicollinearity, cross-validation, leave-one-out, component, coefficient of determination
Model regresi dalam analisis regresi linear berganda dapat digunakan sebagai model prediksi yang bersifat interpolasi. Prediksi bersifat interpolasi dimaksudkan adalah menduga nilai suatu peubah respon pada nilai-nilai peubah bebas yang berada dalam interval nilai dari peubah-peubah bebas yang digunakan dalam pembentukan model. Model regresi linear berganda memuat satu peubah respon (Y) dan peubah bebasnya (X) lebih dari satu. Model estimasi dikatakan cukup baik menggambarkan keragaman data apabila koefisien determinasi (R2) model tersebut untuk bidang sains ≥ 80%, dan untuk bidang sosial nilai R2 ≥65% [1]. Model regresi linear berganda yang diperoleh dengan menggunakan metode kuadrat terkecil (ordinary least square-OLS)
sering menjadi tidak valid apabila terjadi korelasi yang signifikan antar peubah bebas. Korelasi antar peubah bebas disebut sebagai kasus multikolinearitas dalam regresi linear berganda. PLSR merupakan salah satu metode yang dapat diterapkan dalam estimasi model regresi bila terjadi kasus multikolinearitas, tanpa mereduksi peubah yang masuk dalam model. PLSR diperkenalkan oleh Wold (1982) yang digunakan untuk membangun model yang bersifat prediksi [2]. PLSR merupakan analisis regresi bersifat tidak langsung dimana varians dari peubah respon dikaitkan dengan besarnya peubah bebas melalui satu atau beberapa faktor yang didefinisikan sebagai kombinasi linear dari peubah bebas yang disebut dengan komponen. PLSR merupakan salah satu metode yang didesain untuk menyelesaikan regresi linear berganda ketika terjadi permasalahan spesifik pada data, seperti ukuran sampel penelitian yang kecil (microarray data), adanya data yang hilang (missing values), terjadi multikolinearitas, dan dapat diterapkan pada tipe data yang berbeda-beda [3].
Penelitian ini bertujuan untuk menentukan model PLSR pengaruh angka melek huruf (AMH), rata-rata lama sekolah, angka partisipasi sekolah, pendapatan perkapita, dan tingkat pengangguran terbuka terhadap tingkat kemiskinan yang dilihat dari persentase penduduk miskin di Indonesia tahun 2015.
Keterkaitan kemiskinan dan pendidikan sangat besar karena pendidikan memberikan kemampuan untuk berkembang lewat penguasaan ilmu dan keterampilan. Pendidikan juga menanamkan kesadaran akan pentingnya martabat manusia. Mendidik dan memberikan pengetahuan berarti menggapai masa depan. Hal tersebut harusnya menjadi semangat untuk terus melakukan upaya mencerdaskan bangsa [4]. Penelitian yang dilakukan oleh Hermanto Siregar dan Dwi Wahyuniarti menemukan bahwa pendidikan berpengaruh negatif terhadap tingkat kemiskinan. Hal ini menunjukkan bahwa pendidikan sangat penting dalam menurunkan tingkat kemiskinan.
Faktor lain yang juga berpengaruh terhadap tingkat kemiskinan adalah pengangguran. Salah satu unsur yang menentukan kemakmuran suatu masyarakat adalah tingkat pendapatan. Pendapatan masyarakat mencapai maksimum apabila kondisi tingkat penggunaan tenaga kerja penuh (full employment) dapat terwujud. Pengangguran akan menimbulkan efek mengurangi pendapatan masyarakat, dan menurunkan tingkat kemakmuran yang telah tercapai. Semakin turun tingkat kemakmuran akan menimbulkan masalah lain yaitu kemiskinan [5].
Model regresi untuk mengetahui pengaruh angka melek huruf (AMH), rata-rata lama sekolah, angka partisipasi sekolah, pendapatan perkapita, dan tingkat pengangguran terbuka terhadap tingkat kemiskinan pada data amatan yang cukup dapat diestimasi dengan metode kuadrat terkecil. Secara matriks, model regresi linear berganda dinyatakan dalam bentuk:
Y = Xβ+∈
dengan:
|
yi |
' 1 |
x11 |
x12 . |
• x1k |
" βo ’ |
b 1 | |||||
|
Y= |
y 2 ... |
; X = |
1 ... |
x21 ... |
x22 . ... . |
.. x2k . ... |
; β = |
β1 ... |
; ∈= |
∈1 ••• |
dengan p=k+1 |
|
_ yn _ |
n x1 |
_ 1 |
xn1 |
xn2 . |
• xnk _ |
n xp |
[ J |
p x1 |
L∈n J |
nx1 |
Estimasi model regresi identik dengan estimasi parameter atau koefisien regresi (β j), untuk i = 0, 1,.. .,k, misalkan nilai dugaan parameter regresi dinyatakan dengan ( bj) maka estimasi model regresi dinyatakan sebagai:
Y = b0 + b1 X1 + b2 X2 + - + bkXk = Xb
dengan β = b = (XfX)~ 1 XfY. Penduga parameter regresi dengan MKT merupakan penduga yang bersifat tidak bias apabila matriks X'X merupakan matriks tidak singular, yaitu matriks yang memiliki invers yang bersifat unik. Apabila X'X bersifat singular atau dalam kondisi buruk (ill conditions) yaitu nilai determinannya mendekati nol, maka penduga parameternya akan bersifat bias. Kondisi buruk disebabkan salah satunya karena terjadi multikolinearitas antar peubah bebas. Metode alternatif menentukan estimasi model dalam kondisi buruk salah satunya dengan PLSR.
Menurut Esposito [3], metode PLSR memiliki keunggulan dan kelemahan. Keunggulan dari PLSR adalah kemampuan dari model peubah berganda berganda untuk peubah respon tunggal sama baiknya dengan peubah respon berganda, kemampuan dalam menangani kasus multikolinearitas antar peubah bebas, ketahanan dalam menghadapi data yang hilang, dan membuat peubah laten (komponen utama) secara langsung berdasarkan crossproduct yang melibatkan peubah respon untuk membuat prediksi menjadi lebih kuat. Adapun kelemahan dari PLSR adalah kesulitan yang besar dalam menafsirkan loading pada peubah bebas laten (yang didasarkan pada hubungan crossproduct dengan peubah respon, tidak seperti pada analisis faktor berdasarkan matriks kovarians antar peubah bebas.
Komponen pertama pada model PLSR dipilih untuk memaksimalkan nilai kovarian dengan peubah respon dan kemudian digunakan sebagai regressor (peubah bebas) dalam model regresi pada MKT (Ordinary Least Square – OLS). Komponen selanjutnya dipilih untuk memaksimumkan nilai kovarian dengan sisaan pada penduga OLS. Hasil akhir dari model PLSR disajikan sebagai b dari koefisien regresi, dengan model:
Y = Y + b (X — X )+∈
dimana Y adalah vektor yang mengandung nilai-nilai respon, X adalah matriks dari peubah penjelas dan ∈ adalah vektor dari kesalahan yang tidak berkorelasi dengan varians yang sama [6].
Banyaknya peubah laten yang digunakan pada akhir model PLSR dapat ditentukan dengan validasi silang, dengan mempelajari kemampuan model yang berbeda untuk memprediksi peubah respon. Dalam penelitian umumnya pengamatan dibagi menjadi dua set data, satu digunakan untuk kecocokan model dan lainnya untuk validasi model, selanjutnya dibandingkan nilai prediksi dan nilai observasi sebenarnya [7].
Pada kasus multikolinearitas, PLSR menghindari matriks X'X yang bersifat singular dengan dekomposisi X ke dalam orthogonal scores T dan loadings P.
X = TP
dan meregresikan Y tidak pada X itu sendiri, tetapi dengan kolom pertama dari scores T. PLSR bertujuan untuk menggabungkan informasi dari X dan Y yang didefinisikan oleh scores dan loadings. Dalam faktanya, untuk satu versi spesifik dari algoritma Partial Least Square dapat menunjukkan scores dan loadings yang dipilih sedemikian rupa untuk menggambarkan sebanyak mungkin kovarians diantara X dan Y [8].
Bila dimiliki k buah peubah bebas dan sebuah peubah respon, model PLSR dengan m komponen dapat juga dirumuskan sebagai [9]:
m ∕ P ∖
∑ Ch (∑ W∗lχl)+e
Komponen pertama dinyatakan dengan ^i , didefinisikan sebagai:
P
1 Vn r \ 2
⅛ = ∗= ∑Cov (y, xj ) xJ
√∑J=I Cov (y, xi )
Peubah Xj dipilih yang berkorelasi tinggi Y dan keragamannya cukup kuat. Seberapa penting peubah Xj dalam pembentukan komponen utama pertama t1 dilihat dengan membentuk model regresi linier sederhana Y terhadap Xj yang dirumuskan sebagai:
Y= + ∈ 1
Nilai a^j menunjukkan seberapa besar peran Xj pada pembentukan komponen pertama dan jika OfIj tidak signifikan maka peran Xj dapat diabaikan.
Pembentukan estimasi model data Tingkat Kemiskinan di Indonesia tahun 2015 sebagai peubah respon Y dengan lima peubah bebas yaitu X∣(AMH), ^2 (rataan lama sekolah), ■^3 (APS/ angka partisipasi sekolah), X4(pendapatan perkapita), dan ¾ (pengangguran terbuka). Estimasi model dilakukan dengan menggunakan metode
PLSR, dan sebagai pembanding digunakan juga metode kuadrat terkecil (MKT). Data yang digunakan dalam estimasi model adalah data mengenai angka melek huruf (AMH), rata-rata lama sekolah, angka partisipasi sekolah, pendapatan perkapita, dan tingkat pengangguran terbuka terhadap tingkat kemiskinan yang dilihat dari persentase penduduk miskin di Indonesia tahun 2015.
Data sekunder yang diperoleh dari Badan Pusat Statistik Provinsi Bali untuk peubah-peubah penelitian dapat diringkas dalam Tabel 1.
|
Tabel 1. Statistika Deskriptif Data Penelitian | |||||||
|
Peubah |
Rataan |
StDev |
Minimum |
Kuartil 1 |
Median |
Kuartil 3 |
Maksimum |
|
Y |
12,20 |
6,49 |
3,72 |
6,87 |
10,39 |
16,14 |
31,35 |
|
94,63 |
4,80 |
75,92 |
91,70 |
96,85 |
97,70 |
99,56 | |
|
8,30 |
0,91 |
6,05 |
7,58 |
8,27 |
9,06 |
10,60 | |
|
21,82 |
6,61 |
9,46 |
17,46 |
20,25 |
24,11 |
45,86 | |
|
*4 |
40873 |
34906 |
12379 |
24332 |
30063 |
37177 |
157168 |
|
*5 |
5,34 |
2,22 |
1,83 |
3,73 |
4,76 |
6,62 |
10,12 |
|
Sumber: Data diolah (2016) | |||||||
Korelasi linear antar peubah penelitian diuraikan dalam Tabel 2.
Tabel 2. Korelasi Linier Antar Peubah Penelitian
|
Peubah |
Y X1 |
*2 |
*4 | ||
|
Y 1 |
-0,570* |
0,332* |
0,239 |
-0,314 |
-0,113 |
|
0.001 |
0,024 |
0,180 |
0,075 |
0,531 | |
|
*1 |
1 |
0,700* |
0,007 |
0,275 |
0,433* |
|
0,000 |
0,970 |
0,122 |
0,012 | ||
|
*2 |
1 |
0,321 |
0,547* |
0,481* | |
|
0,069 |
0,001 |
0,005 | |||
|
*3 |
1 |
-0,105 |
0,131 | ||
|
0,562 |
0,467 | ||||
|
*4 |
1 |
0,286 | |||
|
0,106 | |||||
|
1 |
Cell Contents: Pearson correlation P-Value
Matriks korelasi memperlihatkan bahwa hanya peubah ^l dan %2 yang signifikan korelasinya terhadap peubah respon Y pada taraf nyata 5%. Korelasi antar peubah bebas yang signifikan diantaranya ^l dan ^2 , ^l dan X^ , ^2 dan X4, serta ^2 dan X^ . Selanjutnya diuraikan proses estimasi model regresi, hasil uji serentak dan uji parsial dengan MKT ditampilkan dalam analisis ragam regresi pada Tabel 3. Tingkat
signifikansi dari suatu analisis untuk kasus bidang sosial umumnya memiliki nilai toleransi yang lebih tinggi dari penelitian bidang sains. Untuk kasus sosial tingkat kemiskinan di Indonesia, masih dimungkinkan untuk menetapkan taraf nyata 10%.
Tabel 3. Analisis Ragam Estimasi Model dengan MKT
Sumber Keragaman Db JK KT F-hit P-Value
|
Regresi *4 Galat/Error |
5 576,46 115,291 4,03 0,007** 1 156,75 156,749 5,48 0,027** 1 3,14 3,138 0,11 0,743 1 48,81 48,811 1,71 0,203 1 13,72 13,721 0,48 0,495 1 31,66 31,661 1,11 0,302 27 772,60 28,615 |
|
Total |
32 1349,05 |
|
Model Summary S R-sq 5,34927 42,73% |
R-sq(adj) R-sq(pred) 32,13% 8,49% |
|
Term |
Coef SE Coef T-Value P-Value VIF |
|
Constant *1 *2 *3 *4 *5 |
80,6 21,4 3,77 0,001 -0,733 0,313 -2,34 0,027 2,53 -0,70 2,12 -0,33 0,743 4,16 0,232 0,178 1,31 0,203 1,55 -0,000025 0,000037 -0,69 0,495 1,84 0,520 0,494 1,05 0,302 1,34 |
Uji parsial memperlihatkan bahwa hanya peubah X∣ yang signifikan masuk dalam model. Peubah %2 tidak masuk dalam model meskipun berkorelasi signifikan dengan peubah respon Y. Hal ini disebabkan karena terjadi multikolinearitas antara ^l dan ^2 sehingga pengaruh ^2 sudah diwakili oleh ^l . Walaupun antara peubah X∣ berkorelasi secara signifikan dengan peubah ^2, namun berdasarkan nilai VIF tidak terjadi multikolinearitas yang kuat. Multikolinearitas dikatakan kuat apabila VIF lebih besar dari 5 [1].
Selanjutnya ditentukan estimasi model hanya dengan peubah ^l , diuraikan dalam analisis ragam regresi pada Tabel 4.
Tabel 4. Analisis Ragam Regresi MKT dengan Peubah Bebas ^l
|
Sumber Keragaman |
Db |
JK |
KT |
F-Value |
P-Value |
|
Regresi |
1 |
438,74 |
438,74 |
14,94 |
0,001 |
|
*1 |
1 |
438,74 |
438,74 |
14,94 |
0,001 |
|
Galat/Error |
31 |
910,31 |
29,36 | ||
|
Lack-of-Fit |
29 |
833,22 |
28,73 |
0,75 |
0,723 |
|
Pure Error |
2 |
77,10 |
38,55 | ||
|
Total |
32 |
1349,05 |
Model Summary
S R-sq R-sq(adj) R-sq(pred)
5,41895 32,52% 30,35% 21,18%
Coefficients
Term Coef SE Coef T-Value P-Value VIF
^l -0,771 0,199 -3,87 0,0011,00
Regression Equation
Estimasi model dengan menggunakan MKT diperoleh: ̂Y=85,1-0,771 dengan koefisien determinasi R2 = 32,52%.
Model ini mengindikasikan bahwa keragaman data persentase jumlah penduduk miskin di Indonesia yang mampu dijelaskan oleh peubah angka melek huruf (AMH) sebesar 32,52%. Koefisien bertanda negatif menunjukkan bahwa semakin tinggi AMH yang mengindikasikan semakin tinggi tingkat pendidikan akan menurunkan persentase penduduk miskin di Indonesia.
Selanjutnya dilihat kinerja PLSR pada data dengan multikolinearitas yang tidak kuat, dengan bantuan software Minitab 17 metode cross-validation: Leave-one-out diperoleh model estimasi yang disajikan dalam analisis ragam pada Tabel 5.
Tabel 5. Analisis Ragam Estimasi Model PLSR
|
Sumber Keragaman |
Db |
JK |
KT |
F P | |
|
Regresi |
1 |
448,90 |
448,897 15 |
,46 0,000 | |
|
Residual Error |
31 |
900,16 |
29,037 | ||
|
Total |
32 |
1349,05 | |||
|
Model Selection |
and Val |
idation Y | |||
|
Components X Variance |
Error |
R-Sq |
PRESS R- |
Sq (pred) | |
|
1 0, |
441302 |
900,155 |
0,332750 |
1124,79 |
0,166233 |
|
2 |
786,392 |
0,417078 |
1155,07 |
0,143789 | |
|
3 |
774,645 |
0,425786 |
1183,05 |
0,123054 | |
|
4 |
773,015 |
0,426994 |
1214,07 |
0,100055 | |
|
5 |
772,595 |
0,427305 |
1234,46 |
0,084941 | |
|
Coefficients | |||||
|
Y | |||||
|
Y |
standardized | ||||
|
Constant |
61,13 |
63 0, |
000000 | ||
|
-0,39640 -0, |
293358 | ||||
|
-1,43550 -0, |
201430 | ||||
|
^3 |
0,120 |
70 0, |
122975 | ||
|
-0,000 |
01 -0, |
161355 | |||
|
*5 |
-0,17020 -0, |
058125 | |||
Estimasi model PLSR persentase penduduk miskin dengan lima peubah bebas yaitu:
̂=61․1363-0․3964 ^l - 1․4355X2 + 0․1207X3 - 0․00001X4 - 0․1702X5
dengan koefisien determinasi R2 sebesar 33,275%, ^l :AMH, ^2 : rataan lama sekolah, ^3 : APS (angka partisipasi sekolah), ^4 :pendapatan perkapita, dan ^5 : pengangguran terbuka.
Hasil ini memperlihatkan bahwa satu komponen yang merupakan kombinasi linier dari peubah bebas mampu menerangkan keragaman data sebenarnya sebesar 33,275%. Hasil estimasi model dan nilai koefisien determinasi memperlihatkan pada data yang tidak mengandung multikolinearitas kuat dan jumlah peubah bebas jauh lebih sedikit dari jumlah data pengamatan, estimasi model dengan MKT dan PLSR memiliki koefisien determinasi yang tidak jauh berbeda. Kecilnya nilai koefisien determinasi dari estimasi model yang diperoleh disebabkan karena ada peubah-peubah bebas yang berpengaruh terhadap persentase penduduk miskin tetapi tidak dilibatkan dalam pembentukan model. Diagnostik model PLSR dengan melihat plot peluang normal galat, keacakan galat, plot galat dengan nilai dugaan seperti dalam Gambar 1.
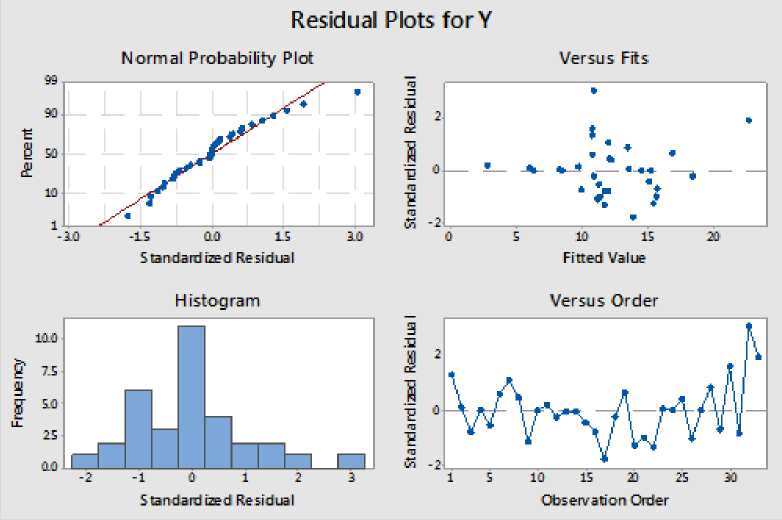
Gambar 1. Plot Diagnostik Galat Estimasi Model
Gambar 1 menunjukkan bahwa kenormalan dan keacakan galat dari estimasi model PLSR telah terpenuhi.
Pada data yang tidak mengalami kondisi buruk (ill condition), jumlah peubah bebas lebih sedikit dari jumlah data amatan, estimasi model regresi yang diperoleh dengan metode PLSR dan MKT menghasilkan koefisien determinasi yang hampir sama. Estimasi model data Tingkat Kemiskinan di Indonesia tahun 2015 yang diukur dengan persentase jumlah penduduk miskin sebagai peubah respon Y dengan lima peubah bebas yaitu ^l (AMH), ^2 (rataan lama sekolah), ∙^3 (APS/ angka partisipasi sekolah), ^4(pendapatan perkapita), dan ^5 (pengangguran terbuka) dengan MKT diperoleh:
̂Y=85,1-0,771X1
dengan koefisien determinasi R2 = 32,52%.
Estimasi model PLSR diperoleh:
-
̂ = 61․1363 - 0․3964 X1 - 1․4355X2 + 0․1207X3 - 0․00001X4 - 0․1702X5 dengan koefisien determinasi R2 sebesar 33,275%.
Daftar Pustaka
-
[1] Montgomery, D.C. and Peck, E.A.(2007) ′Introduction to Linear Regression
Analysis′, 3rd Ed., New York :John Wiley & Sons, Inc.
-
[2] Abdi, H. (2006) ′Partial Least Squares Regression (PLSR)′, University of Texas
-
[3] Esposito, V., Wynee, Henseler, J., and Wang, Huiwen (2010) ′Handbook of Partial least Squares′, Germany: Springer
-
[4] Suryawati,C. (2005) ′Memahami Kemiskinan Secara Multidimensional′,
http://www.jmpk-online.net/Volume_8/Vol_08_No_03_2005.pdf. Diakses 3 Maret 2016
-
[5] Sukirno, S. (1999) ′Makroekonomi Modern′, Jakarta: Penerbit Raja Grafindo Persada.
-
[6] Forsman, A., Andersoon, C., and Grimvall, A. (2003) ′Estimation of the impact of short-term fluctuations in inputson temporally aggregated outputs of process-oriented models′ Journal of Hidroinformatics, 5(3), 169-180.
-
[7] Mevik, H. (2007) ′The PLS Package:Principal Component and Partial Least Square Regression in R′ Journal of Statistical Software, vol 18,1-24.
-
[8] Somnath, D and Susmita, D. (2007) ′Predicting Patient Survival from Microarray Data by Accelerated failure Time Modeling using partial Least Squares and LASSO′. Journal of Biometrics, vol 63, 259-271. United State of America.
-
[9] Subekti, R. dan Rosita, K. (2014) ′Kajian Partial Least Squares (Studi Kasus:
Regresi Cox-PLS) ′, Journal J.Sains Dasar, vol 3 No. 1. Hal. 61-68.
-
[10] Hudaya, D. (2009) ′Faktor-Faktor yang Mempengaruhi Tingkat Kemiskinan di
Indonesia′ Skripsi, Institut Pertanian Bogor. Bogor.
75
Discussion and feedback