Analisis Ancaman COVID-19 Varian XBB di Indonesia Pada Jejaring Media Sosial Twitter Menggunakan Text Mining
on
JITTER- Jurnal Ilmiah Teknologi dan Komputer Vol. x, No. x month 202x
Analisis Ancaman COVID-19 Varian XBB di Indonesia Pada Jejaring Media Sosial Twitter Menggunakan Text
Mining
Akhmad Rezki Purnajayaa1, Verya2, Oscar Noverioa3, Charlos Alvaroa4 aProgram Studi Teknik Perangkat Lunak, Universitas Universal, Indonesia e-mail: 1rezkipurnajaya@gmail.com, 2verylie02@uvers.ac.id, 3oscarnoverio6@gmail.com, 4charlosalvaro01@gmail.com
Abstrak
Semakin cepatnya mutasi penyakit Covid-19 menyebabkan munculnya subvarian baru yang dikenal varian XBB pertama kali di Afrika Selatan pada tanggal 24 November 2021. Subvarian ini memiliki kekhasan khusus daripada subvarian lain dalam kecepatan penyebarannya yang sangat cepat, tetapi sebagian besar gejala yang didampakkan masih skala ringan. Hal ini menyebabkan kepanikan kembali oleh masyarakat Indonesia yang telah kembali melakukan aktivitas outdoor dengan normal dengan munculnya subvarian ini. Oleh karena itu penelitian ini bertujuan untuk menganalisis ancaman subvarian COVID-19 bernama XBB di Indonesia yang paling banyak dibicarakan orang di media sosial Twitter. Penelitian ini menggunakan metode Text Mining. Model yang digunakan dalam penelitian ini bervariasi, seperti matriks, word cloud, dan hierarchical clustering. Hasilnya menunjukkan bahwa dua kota di Indonesia terancam varian baru XBB yaitu Kota Bogor, Jawa Barat dan Kota Batam, Kepulauan Riau. Ditambah hasil analisa menunjukkan pemerintah Indonesia memberikan respon cepat untuk mencegah penyebaran dari subvarian XBB ini.
Kata kunci: Covid-19, XBB, Text Mining, Social Network Analysis, Twitter
Abstract
The rapid mutation of the Covid-19 disease led to the emergence of a new subvariant known as the XBB variant for the first time in South Africa on November 24 2021. This subvariant has a special feature compared to other subvariants in its very fast spread speed with most of the symptoms it affects are still on a mild scale. This has caused panic again by the Indonesian people who have returned to normal outdoor activities with the appearance of this subvariant. This study aims to analyse the threat of the new variant of COVID-19 called XBB in Indonesia that is most talked about by people on social media, Twitter. This study uses the text mining method. The models used in this study are varies, such as matrixes, word cloud, and hierarchical clustering. The results show that two cities in Indonesia are under threat of the new SARS-COV2 XBB variant which is, Bogor, West Java, and Batam, Riau Islands. In addition, the results of the analysis show that the Indonesian government has responded quickly to prevent the spread of this XBB subvariant.
Keywords : Covid-19, XBB, Text Mining, Social Network Analysis, Twitter
akibat COVID-19. Pemerintah Indonesia telah menetapkan penyakit COVID-19 sebagai darurat kesehatan di Indonesia untuk dilaksanakan sesuai dengan ketentuan peraturan perundang-undangan. Dampak COVID-19 di Indonesia terhadap segala aspek, baik politik, aspek ekonomi, sosial, budaya, pertahanan dan keamanan, serta kesejahteraan masyarakat di Indonesia [4].
Secara global, jumlah kasus baru mingguan menurun sebesar 15% pada minggu 17-23 Oktober 2022 dibandingkan dengan minggu sebelumnya, dengan lebih dari 2,6 juta kasus baru dilaporkan. Jumlah kematian mingguan baru turun 13 persen dibandingkan minggu sebelumnya, dengan lebih dari 8.500 kematian dilaporkan. Per 23 Oktober 2022, ada lebih dari 624 juta kasus yang dikonfirmasi dan lebih dari 6,5 juta kematian dilaporkan di seluruh dunia. Di tingkat regional, jumlah kasus baru yang dilaporkan setiap minggu menurun atau stabil di enam wilayah WHO: Wilayah Afrika (-41%), Wilayah Eropa (-23%), Wilayah Mediterania Timur (-9%), Wilayah Pasifik Barat (-5%), Wilayah Asia Tenggara (-4%) dan Wilayah Amerika (+2%)). Jumlah kematian mingguan baru turun di empat dari enam wilayah: Wilayah Afrika (-72%), Wilayah Eropa (-24%), Wilayah Asia Tenggara (-13%) dan Wilayah Pasifik Barat (-8%); Angkanya tetap stabil di Amerika (-1%) dan meningkat di Mediterania Timur (+9%) [5].
Pemerintah yang memimpin perang melawan penyebaran COVID-19 di Indonesia melalui Kementerian Kesehatan RI setiap hari memberikan berita atau informasi terbaru mengenai pandemi COVID-19 melalui media sosial termasuk Twitter. Namun dalam praktiknya, komunitas pengguna Twitter mengomentari mutasi COVID-19 khususnya varian XBB [6] & [7]. Komentar yang diberikan tidak hanya bersifat positif tetapi juga bersifat negatif, sehingga komentar dari komunitas Twitter merupakan data yang dapat diolah dan dijadikan bahan dalam penelitian ini
Untuk penelitian ini, terdapat beberapa alur yang akan dilakukan. Alur ini disusun secara terstruktur dan digambarkan secara berurutan yang dimulai dari tahapan pengumpulan data, data preprocessing, pemodelan teks mining, dan sampai pada tahapan analisa hasil. Alur penelitian dapat dilihat pada gambar berikut:
Pengumpulan Data
Data Preprocessing
Pemodelan Text Mining
Analisa Hasil
Gambar 1. Tahapan Penelitian
Varian Omicron pada penyakit COVID-19 sebenarnya memiliki beberapa subvarian atau turunan yaitu BA.1, BA.2, BA.5. Sedangkan XBB merupakan rekombinasi dari dua turunan BA.2, yaitu BA.2.10.1 dan BA.2.75. Subvarian XBB Covid-19, turunan dari Omicron SARS-CoV-2 atau B.1.1.529, menunjukkan kekhususan dalam kecepatan penyebaran, tetapi sebagian besar gejala yang dilaporkan ringan. Pada Omicron, varian itu memiliki 32 mutasi titik, sebagian besar di bagian gen yang mengkode protein lonjakan. Dengan demikian, varian Omicron yang mengandung sub varian XBB cenderung menyebar cukup cepat dibandingkan varian sebelumnya. Sebagian besar pasien yang terinfeksi XBB memiliki gejala ringan yaitu gejala
infeksi saluran pernapasan atas seperti batuk, pilek, demam dan terkadang nyeri menelan atau sakit tenggorokan. Subvarian XBB yang masih satu varian dengan Omicron tidak memiliki perbedaan yang terlalu signifikan. Berbeda halnya dengan varian Delta yang menyebar dengan cepat dan memiliki gejala yang parah, membuat banyak pasien dirawat di rumah sakit dan meninggal [8].
-
3.1 Preprocessing
Teknik pra-pemrosesan yang terdiri dari pembersihan data diterapkan untuk menghilangkan kebisingan dan memperbaiki konflik data. Integrasi data, menggabungkan data dari berbagai sumber menjadi satu kesatuan penyimpanan data. Kemudian pengurangan data untuk mengurangi ukuran data seperti agregasi fitur yang berlebihan. Terakhir, transformasi data yang dapat digunakan saat menskalakan data ke rentang yang lebih kecil seperti 0,0 hingga 1,0 [9].
Metode preprocessing dalam penelitian ini digunakan untuk menghilangkan kata-kata yang tidak bermakna dalam penelitian seperti mengandung pengunaan karakter special, tanda baca dan lain sebagainya. Penggunaan teknik ini diketahui mampu mempermudah proses kerja text mining untuk menganalisa kata dalam kelompok data teks. Tahapan preprocessing memiliki beberapa proses, yaitu case folding, stopwords removing, tokenizing, dan stemming, selanjutnya data yang sudah mengalami preprocessing akan diubah menjadi bentuk numerik dengan tahap term weighting [10].
-
3.2 Clustering
Clustering adalah teknik untuk mengelompokkan data dengan karakteristik yang sama. Tujuan utama dari metode clustering adalah untuk mengelompokkan data ke dalam suatu kelompok (cluster) sedemikian rupa sehingga setiap cluster berisi data dengan kesamaan yang signifikan.
Penelitian ini menggunakan dendrogram klaster, dimana plot klaster merupakan plot berbentuk pohon dimana dendrogram mengelompokkan 2 data menjadi klaster berdasarkan penjumlahan kuadrat dari gabungan data. Jarak untuk membagi atau menggabungkan data juga dikenal sebagai ketinggian [11].
Social Network Analysis (SNA) adalah konstruksi sosial menggunakan jaringan dan teori grafik. SNA mencirikan struktur jaringan sesuai dengan node dan edge yang memiliki hubungan atau interaksi di antara keduanya. Node adalah data yang disimpan sedangkan edge adalah garis hubungan antar hubungan [12].
Text mining adalah proses penggalian informasi dalam bentuk teks, dimana sumber informasi biasanya diambil dari dokumen, dan tujuannya adalah untuk menemukan kata-kata yang dapat mewakili isi dokumen, sehingga memungkinkan dilakukannya analisis konektivitas. antara dokumen dimungkinkan untuk diaktifkan. [13].
Algoritma yang umum digunakan setelah proses langkah penambangan teks adalah Term-Frequency Inverse Document Frequency (TF-IDF). Suatu cara untuk menambah bobot hubungan suatu kata (term) dengan suatu dokumen [14] & [15].
Rumus TF-IDF:
IDFt = ∖θ^D∕d∩
(1)
(2)
Wd,t=tfdft*IDFt
Keterangan Persamaan (1)
IDF = Inversed Document Frequency
t = kata ke-t dari kata kunci
D = total dokumen
df = banyak dokumen yang mengandung kata yang dicari
Keterangan Persamaan (2):
Pada persamaan (1) digunakan untuk mencari nilai IDF
d = dokumen ke-d
t = kata ke-t dari kata kunci
W = bobot dokumen ke-d terhadap kata ke-t
tf = banyak kata yang dicari pada sebuah dokumen
Data teks dikumpulkan melalui sosial media Twitter pada tanggal 11 November 2022 yang merupakan hasil pencarian cuitan dengan kata kunci “covid-19 XBB”. 50 cuitan dari hasil pencarian tersebut diambil teksnya dan disimpan dalam bentuk dokumen Microsoft Excel (XLSX) dalam satu kolom seperti contoh pada Tabel 1 berikut.
Tabel 1. Data Teks Cuitan Covid-19 XBB
|
No. |
Teks |
|
1 |
Di tengah lonjakan kasus Covid-19 di Jawa Barat, petugas menemukan dua kasus subvarian XBB dari Kabupaten Bogor. Virus ini disebut bisa menular dengan cepat sehingga masyarakat diminta lebih waspada. #Nusantara #AdadiKompas |
|
2 |
Belanda mengkonfirmasi adanya peningkatan jumlah kasus baru Covid-19 di negaranya jelang akhir tahun.perdana menteri Belanda Mark Rutte, meminta warganya untuk tidak melakukan perjalanan ke luar negeri dalam waktu dekat ini, terutama ke Asia tenggara, karena adanya varian XBB. |
|
3 |
Subvarian Omicron XBB, pemicu kasus COVID-19 RI naik lagi disebut lebih menular dari yang lainnya. Lantas masa inkubasi Omicron XBB berapa hari? Ini faktanya. |
|
50 |
Dari data Kemenkes hingga saat ini, tren kenaikan kasus Covid-19 terlihat seiring dengan dilaporkannya varian XBB yang mulai mendominasi. |
-
4.2 Data Preprocessing
Data teks yang telah dikumpulkan kemudian diimport ke dalam program Rstudio dan sekaligus diubah kedalam bentuk corpus sehingga dapat dilakukan data preprocessing. Tahapan data preprocessing terdiri dari:
-
1. Case Folding
Case Folding merupakan prosedur untuk menyeragamkan ukuran huruf pada data menjadi huruf kecil menggunakan fungsi tolower. Karakter yang merupakan bukan huruf seperti angka, tanda baca, dan URL akan dihapus menggunakan fungsi removePunctuation, removeNumbers, dan removeURL.
-
2. Tokenizing
Tokenizing merupakan prosedur untuk memotong data sebuah cuitan menjadi potongan-potongan kata.
-
3. Filtering
Filtering merupakan prosedur penghapusan kata-kata bahasa Indonesia yang tidak penting seperti kata ganti dan kata sambung. Maka diperlukan sebuah basis data yang sudah berisikan 811 kata di dalamnya sehingga program dapat menghapus katakata tidak penting sesuai dengan basis data yang sudah diberikan.
Pada penelitian ini digunakan data yang ditarik dari media sosial Twitter secara manual dengan kata kunci “covid-19 xbb” yang dimasukkan ke sebuah lingkungan pemrograman bahasa R yaitu RStudio. Digunakan juga paket perpustakaan pendukung pemrograman yaitu tm untuk mendukung proses pemodelan text mining, wordcloud untuk mendukung visualisasi word cloud, dan igraph untuk analisis jaringan keterhubungan antar kata. Selanjutnya, data-data tersebut melalui proses pre-processing sehingga mempermudah pemrosesan analisis kata yang sering muncul di setiap sampel.
Pemodelan dilakukan dengan membangun matriks keterhubungan antara term (kata) dengan sebuah document (dokumen atau data sampel, pada kasus ini adalah 50 cuitan) yang mana baris mewakili term dan kolom mewakili document seperti pada Gambar 2 berikut.
-C-STeriiDocuiientMatrix (terms: 212, documents: 50}» Non-∕sparse entries: 518/10082
Sparsity : 95%
Maximal term length: 16
Weighting : term frequency (tf}
Sample :
Does
|
Terms |
12 |
15 2 23 4 41 |
46 |
5 |
6 |
7 | ||||
|
bat am |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
covid |
1 |
1 |
1 |
3 |
1 |
2 |
2 |
1 |
1 |
2 |
|
i ndonesia |
0 |
0 |
0 |
2 |
0 |
1 |
2 |
0 |
0 |
0 |
|
jawa |
0 |
0 |
0 |
0 |
2 |
0 |
0 |
1 |
2 |
0 |
|
□ micron |
2 |
2 |
0 |
0 |
2 |
1 |
1 |
3 |
2 |
2 |
|
persen |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
ri |
1 |
3 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Subvarian |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
varian |
0 |
0 |
1 |
1 |
2 |
2 |
2 |
3 |
2 |
1 |
|
xbb |
2 |
2 |
1 |
1 |
3 |
1 |
3 |
3 |
2 |
1 |
Gambar 2. Matriks Term-Document
Dari matriks relasi term-document tersebut dijelaskan bahwa ada 212 kata dalam 50 cuitan dengan tingkat persebarannya sebesar 95% dan jumlah karakter maksimal dari 212 kata tersebut sebanyak 16 karakter.
Analisa hasil yang pertama dilakukan adalah melakukan analisis kata yang memiliki frekuensi tinggi, yang artinya kata yang sering digunakan pada cuitan. Frekuensi pada analisis kali ini digunakan lebih dari atau sama dengan 15 kali. Lima kata dengan frekuensi terbanyak ada pada kata “covid” sebanyak 58, kata “subvarian” sebanyak 22, kata “xbb” sebanyak 66, kata “varian” sebanyak 32, dan kata “omicron” sebanyak 28 yang seperti ditunjukkan oleh Tabel 2 dan Gambar 3 di bawah.
Tabel 2. Kata dan Frekuensi
|
Kata |
covid |
subvarian |
xbb |
varian |
omicron |
|
Frekuensi |
58 |
22 |
66 |
32 |
28 |
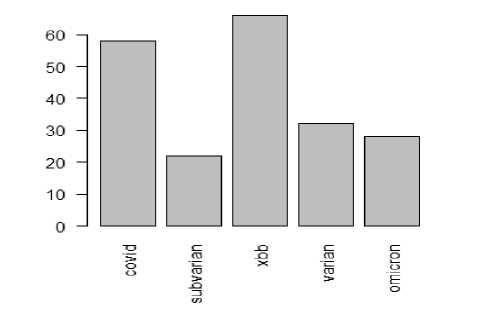
Gambar 3. Grafik Batang Frekuensi Kata
Analisis selanjutnya yaitu menvisualisasikan sebuah model frekuensi kata menggunakan model Word Cloud yang terlihat hasilnya pada Gambar 4. Model ini merupakan model yang paling sering digunakan dengan bantuan paket perpustakaan pendukung pemrograman wordcloud pada program RStudio. Hasilnya, kata “covid”, “xbb”, “varian”, “subvarian”, dan “omicron” memiliki frekuensi besar pada percakapan twitter karena kata-kata tersebutlah yang menjadi objek pencarian teks. Selanjutnya, kata “batam” merupakan kata dengan frekuensi terbesar selanjutnya yang merupakan kata yang sering ditulis oleh pengguna twitter.
pemerintah menyebut meπkes jat>ar masyarakat KenaikanSUbvarian
-“novi d
W (D
Singapura v^/ V I ^^1 persen barat |
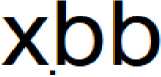
lonjakan jawa 5
bogor ⊂positif
pasien dinkes eα+∙∩αo
lb≡ Vananbatamdinas9
■ omicronkesehatan indθΠΘSia kabupaten ditemukan wilayahnya provinsi
Gambar 4. Visualisasi Word Cloud
Frekuensi kata tersebut dapat dikelompokkan juga dengan Model Hierarchical Clustering yang dimana ada 9 kelompok kata pada cuitan Covid-19 XBB seperti pada Gambar 5, yaitu:
-
1. Kelompok 1: “varian”
Kelompok ini memperlihatkan kata “varian” sering dicuitkan karena kata tersebut sangat berkaitan dengan kata kunci “covid-19 xbb” yang merupakan varian covid-19 sendiri.
-
2. Kelompok 2: “covid”, “xbb”
Kelompok ini memperlihatkan kata tersebut sering dicuitkan karena kata tersebut adalah kata kunci yang dicari.
-
3. Kelompok 3: “barat”, “jawa”, “bogor”, “kabupaten”
Kelompok ini memperlihatkan Jawa Barat dan Kabupaten Bogor memiliki dampak dari Covid-19 XBB.
-
4. Kelompok 4: “ri”, “indonesia”, “kemenkes”, “kenaikan”, “lonjakan”, “pemerintah” Kelompok ini memperlihatkan pemerintah negara Indonesia memberikan respon cepat terhadap kenaikan lonjakan dari Covid-19 XBB.
-
5. Kelompok 5: “cepat”, “masyarakat”, “prokes”, “dinkes”, “jabar”,
“ditemukan”, “menkes”, “wilayahnya”, “provinsi”, “dinas”, “kesehatan”, “menyebut”, “satgas”, “singapura”, “pasien”, “virus”, “positif”
Kelompok ini memperlihatkan masyakat segera melakukan prokes yang diimbau oleh Dinas Kesehatan saat telah ditemukan pasien positif pertama Covid-19 XBB yang terjadi di Provinsi Jawa Barat.
-
7. Kelompok 7: “subvarian”
Kelompok ini menunjukkan kata “subvarian” sangat berelasi dengan kata kunci “covid-19 xbb” yang merupakan varian covid-19 sendiri.
Cluster Dendrogram
Kelompok 8: “omicron”
Kelompok ini menunjukkan kata “omicron” sangat berelasi dengan kata kunci “covid-19 xbb” yang merupakan varian covid-19 sendiri.
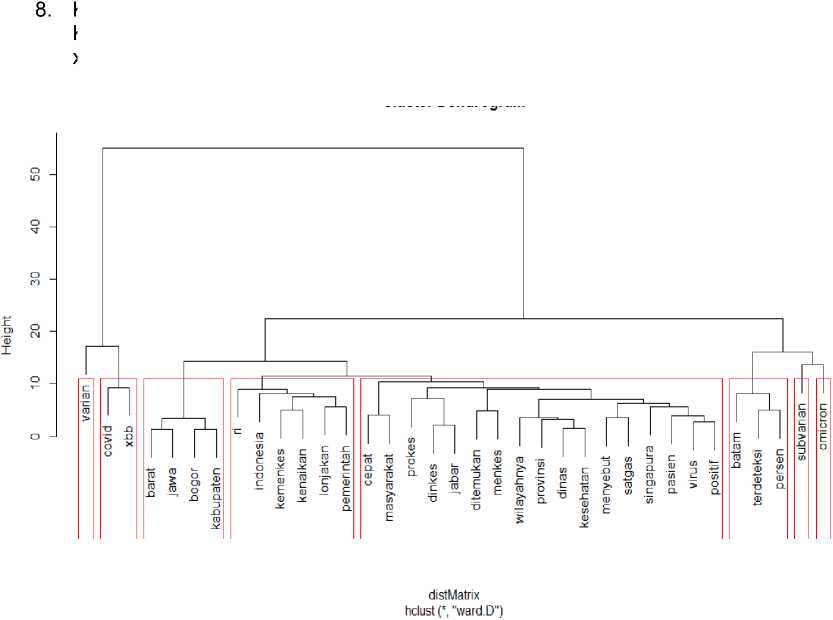
Gambar 5. Visualisasi Pengelompokan Kata Menggunakan Hierarchial Clustering
Setelah analisis antara kata dengan cuitan, dapat dilakukan juga analisis antara kata dengan kata lainnya atau disebut juga Network of Terms.
IGRAPH 6b24090 UNW- 35 312 —
+ attr: name (v∕c), label (v∕c), degree (v∕n), weight (e∕n)
+ edges from 6b24090 (vertex names):
-
[1] barat—bogor barat—cepat barat—covid barat—jawa barat—kabupaten barat—Ionjakan
-
[7] barat—masyarakat barat—subvarian barat—virus barat—xbb barat—varian barat—omicron
-
[13] barat—pasien barat—positif barat—Singapura barat—dinas barat—kesehatan barat—provinsi
-
[19] barat—wilayahnya barat—dinkes barat—ditemukan barat—jabar bogor—cepat bogor—covid
-
[25] bogor—jawa bogor--kabupaten bogor—lonjakan bogor—masyarakat bogor--subvarian bogor—virus
-
[31] bogor—xbb bogor—varian bogor—omicron bogor—pasien bogor—positif bogor—Singapura
-
[37] bogor—dinas bogor—kesehatan bogor—provinsi bogor—wilayahnya bogor—ditemukan cepat—covid
-
[43] cepat—jawa cepat—kabupaten cepat—lonjakan cepat—masyarakat cepat—subvarian cepat—virus
+ ... omitted several edges
-
Gambar 6. Analisis Keterhubungan Antar Kata
Analisis tersebut dapat divisualisasikan jaringan keterhubungan setiap katanya melalui aplikasi RStudio menggunakan model Fruchterman Reingold seperti pada Gambar 7 berikut dengan bantuan paket perpustakaan pendukung igraph. Kata-kata yang berada ditenggah gambar Fruchterman Reingold menunjukkan kata yang paling sering berkaitan dengan katakata lain pada cuitan twitter, seperti kata “covid”, “xbb”, “varian”, “subvarian”, “omicron”, “indonesia”, “lonjakan”, “batam”, “kesehatan”, “jawa”, dan “barat”.
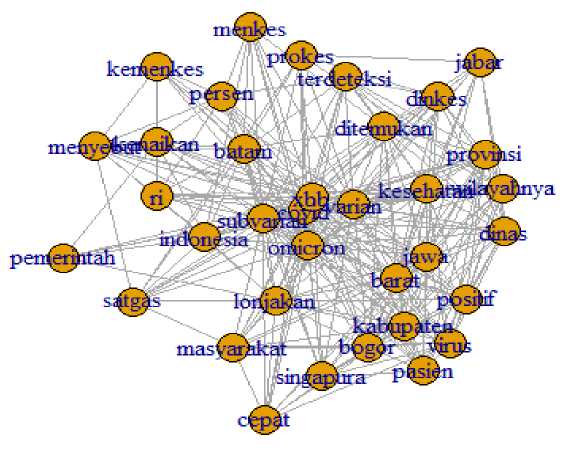
Gambar 7. Visualisasi Model Fruchterman Reingold
Selain model ini, dapat digunakan juga fitur tkplot yang disediakan oleh igraph untuk mengkonfigurasi serta mengubah model visualisasi sesuai dengan keinginan seperti yang ditampilkan pada gambar berikut menggunakan model lingkaran.
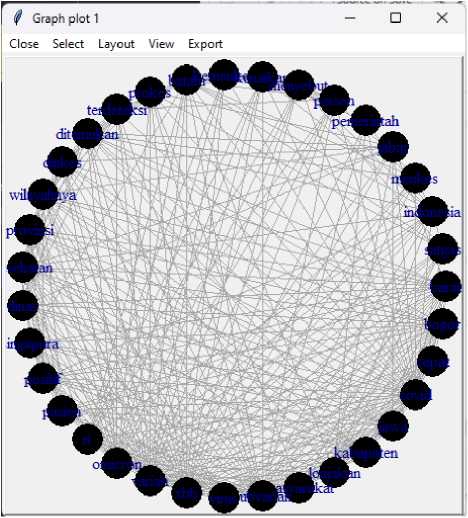
Gambar 8. Visualisasi model lingkaran menggunakan fitur tkplot
Berdasarkan hasil pada penelitian yang dilakukan di atas, dapat disimpulkan bahwa metode Text Mining ini dapat digunakan untuk analisis kota yang sedang dalam ancaman serangan SARS-CoV2 (COVID-19) Varian Omicron Subvarian XBB dari sosial media Twitter. Untuk hasil analisis dapat disimpulkan bahwa terdapat 2 kota yang sedang dalam ancaman serangan yaitu Bogor, Jawa Barat dan Batam, Kepulauan Riau. Namun begitu, Pemerintah Indonesia terutama Kementerian Kesehatan Republik Indonesia beserta dinas-dinas kesehatan memberikan tanggapan yang cepat dengan menghimbau masyarakat agar mencegah penyebaran Covid-19 Subvarian XBB yang begitu cepat.
Daftar Pustaka
-
[1] E. T. Handayani and A. Sulistiyawati, “ANALISIS SENTIMEN RESPON MASYARAKAT TERHADAP KABAR HARIAN COVID-19 PADA TWITTER KEMENTERIAN KESEHATAN DENGAN METODE KLASIFIKASI NAIVE BAYES”, Jurnal Teknologi dan Sistem Informasi (JTSI), vol. 2, no. 3, pp. 32–37, 2021.
-
[2] H. Amalia, “Omicron penyebab COVID-19 sebagai variant of concern”, Jurnal Biomedika dan Kesehatan, vol. 4, no. 4, pp. 139–141, Dec. 2021, doi: 10.18051/jbiomedkes. 2021.v4.139-141.
-
[3] E. Parwanto, “Virus Corona (SARS-CoV-2) penyebab COVID-19 kini telah bermutasi”, Jurnal Biomedika dan Kesehatan, vol. 4, no. 2, pp. 47–49, Jun. 2021, doi: 10.18051/jbiomedkes. 2021.v4.47-49.
-
[4] A. Pragholapati, “NEW NORMAL ‘INDONESIA’ AFTER COVID-19 PANDEMIC”, 2020.
-
[5] World Health Organization, “Special Focus: Update on SARS-CoV-2 variants of interest and variants of concern,” COVID-19 Weekly Epidemiological Update, Edition 115, pp. 5, Oct. 2022.
-
[6] A. Dewandaru, J. Sasongko Wibowo, and A. History, “Analisis Sentimen dan Klasifikasi Tweet Terkait Mutasi COVID-19 Menggunakan Metode Naïve Bayes Classifier”, Jurnal Teknologi dan Manajemen Informatika, vol. 8, pp. 32–38, 2022.
-
[7] Y. Sahria, “Analisis Jejaring Penelitian Kesehatan Indonesia Menggunakan Text Mining”, 2020.
-
[8] WHO, “TAG-VE statement on Omicron sublineages BQ.1 and XBB”, 2022. https://www.who.int/news/item/27-10-2022-tag-ve-statement-on-omicron-sublineages-bq.1-and-xbb. (diakses 12 Desember 2022).
-
[9] J. Han, M. Kamber, and J. Pei, “Data Mining. Concepts and Techniques, 3rd Edition”, The Morgan Kaufmann Series in Data Management Systems, 2011.
-
[10] F. S. Jumeilah, “Penerapan Support Vector Machine (SVM) untuk Pengkategorian Penelitian,” Jurnal RESTI, vol. 1, no. 1, 2017.
-
[11] D. D. C. Nugraha, Z. Naimah, M. Fahmi, and N. Setiani "Klasterisasi Judul Buku dengan Menggunakan Metode K-Means", Seminar Nasional Aplikasi Teknologi Informasi, 2014.
-
[12] E. Otte and R. Rousseau, “Social network analysis: a powerful strategy, also for the information sciences”, Journal of Information Science, vol. 28, no. 6, pp. 441–453, Dec. 2002, doi: 10.1177/016555150202800601.
-
[13] R. Feldman and J. Sanger, “The text mining handbook: advanced approaches in analyzing unstructured data”, Cambridge University Press, 2007.
-
[14] M. Nurjannah, Hamdani, I. F. Astuti, “PENERAPAN ALGORITMA TERM FREQUENCYINVERSE DOCUMENT FREQUENCY (TF-IDF) UNTUK TEXT MINING”, Journal Informatika Mulawarman, vol. 8, no. 3, Sep 2013.
-
[15] M. A. Rofiqi, A. C. Fauzan, A. P. Agustin, and A. A. Saputra, “Implementasi TermFrequency Inverse Document Frequency (TF-IDF) Untuk Mencari Relevansi Dokumen Berdasarkan Query”, ILKOMNIKA: Journal of Computer Science and Applied Informatics, vol. 1, no. 2, pp. 58–64, Dec. 2019, doi: 10.28926/ilkomnika.v1i2.18.
Discussion and feedback