Analisis Respon Pelanggan Terhadap Suatu Produk Dengan Metode Support Vector Machine (SVM)
on
JITTER- Jurnal Ilmiah Teknologi dan Komputer Vol. 3, No. 2 Agustus 2022
Analisis Respon Pelanggan Terhadap Suatu Produk Dengan Metode Support Vector Machine (SVM)
Kadek Dede Setiawan, Ni Made Ika Marini Mandenni, Dwi Putra Githa
Program Studi Teknologi Informasi, Fakultas Teknik, Universitas Udayana Bukit Jimbaran, Bali, Indonesia, telp. (0361) 701806
e-mail: 1kadekdededev@gmail.com, 2 made_ikamarini@unud.ac.id , 3dwiputragitha@gmail.com
Abstrak
Perkembangan teknologi informasi membuat terjadinya perubahan metode belanja masyarakat dimana masyarakat dapat berbelanja secara online. penjualan secara online membuat konsumen tidak dapat melihat produk secara langsung dimana konsumen hanya dapat melihat foto dan ulasan produk sebagai pertimbangan dalam berbelanja. Respon pelanggan adalah reaksi pelanggan atau konsumen terhadap suatu produk dimana reaksi ini dapat mempengaruhi tanggapan konsumen terhadap suatu produk. Respon pelanggan dapat berupa data ulasan produk dimana data ulasan produk yang berberntuk teks dapat diklasifikasikan dengan metode text mining dan algoritma Support Vector Machine (SVM). Penelitian ini melakukan klasifikasi berdasarkan data ulasan produk kosmetik pada website https://femaledaily.com/ dimana klasifikasi dikelompokkan berdasarkan jenis kulit dan umur konsumen. Hasil pengujian dengan menggunakan metode SVM menunjukan akurasi tertinggi sebesar 90% dan akurasi terendah sebesar 81%.
Kata kunci: Support Vector Machine, Text Mining , Sentiment Analysis
Abstract
The development of information technology has made changes to people’s shopping methods where now people can shop online. With online sales consumers can’t see product directly where consumers can only see photos and product review as consideration in shopping. Customer response is reaction of customers to a product where this reaction can effect consumer perception to the product. Customer reaction can be review of the product where this review can classified with text mining and Support Vector Machine (SVM) algoritma. this study perform clasification based on cosmetic product review on https://femaledaily.com/ and sociolla.com where clasification result grouped by skin type and age range. The test results using the SVM method show the highest accuracy of 90% and the lowest accuracy of 81%.
Keywords : Support Vector Machine, Text Mining , Sentiment Analysis
yang dibeli konsumen. ulasan produk memiliki pengaruh yang signifikan terhadap minat beli dari konsumen lain [3] Ulasan produk kosmetik dapat dikelompokkan berdasarkan jenis kulit dan umur konsumen. ulasan produk khususnya produk kosmetik dapat digunakan sebagai acuan oleh konsumen sebelum membeli produk yang tepat. selain dapat digunakan oleh konsumen ulasan produk dapat digunakan oleh produsen kosmetik untuk mendapatkan informasi yang dapat digunakan untuk mengembangkan produk ataupun riset produk.
Analisis ulasan produk biasanya dilakukan dengan melihat jumlah bintang yang diberikan konsumen akan tetapi jumlah bintang tidak dapat mewakili keseluruhan isi dari ulasan produk. Selain dengan melihat bintang pada ulasana produk, analisis ulasan produk dapat dilakukan dengan membaca satu persatu ulasan produk akan tetapi jika produk memiliki ulasan produk yang banyak akan lebih baik menggunakan sistem sentimen analisis.
Sentiment analisis dapat dilakukan dengan menggunakan metode text mining. Text minng adalah metode untuk menemukan pola pada suatu data teks [4]. Dalam penerapan text mining digunakan algoritma untuk melakukan klasifikasi data teks. Algoritma yang dapat digunakan untuk melakukan klasifikasi data teks seperti K-Nearest Neighbor (KNN), naive bayes, Support Vector Machine dan lainnya. Support Vector Machine adalah salah satu algoritma yang banyak digunakan untuk melakukan klasifikasi
Klasifikasi data teks dengan menggunakan algoritma Support Vector Machine memiliki kelebihan yaitu dimana algoritma Support Vector Machine dapat melakukan klasifikasi dengan baik pada data yang memiliki dimensi yang besar. Penelitian yang telah dilakukan sebelumnya oleh Siti Nur Asiyah dan Kartika Fithriasari [5] untuk mengelompokkan berita online berdasarkan kategori sport, news, finance dan lainnya dengan menggunakan metode Support Vector Machine dan K-Nearest Neighbor dengan akurasi sebesar 93,2% dengan algoritma SVM dan 60% dengan algoritma K- Nearest Neighbor.
Berdasarkan uraian di atas. Maka diperlukan peneletian terkain analisis respon pelanggan terhadap suatu produk dengan menggunakan algoritma Support Vector Machine dimana data yang digunakan adalah data ulasan produk dan dikelompokkan berdasarkan jenis kulit dan rentang umur dari konsumen. dengan penelitian ini diharapkan dapat digunakan sebagai informasi yang dapat digunakan oleh produsen kosmetik atauapun sebagai acuan konsumen untuk membeli produk yang sesuai.
-
2. Metodelogi Penelitian
Metodelogi penelitian yang digunakan sebagai acuan dalam pengembanga dimulai dari tahapan identifikasi masalah sampai dengan hasil dan kesimpulan. Berikut tahapan pada penelitian.
Gambar 1 Alur Penelitian
Penelitian analisis respon pelanggan terhadap suatu produk dengan menggunakan metode SVM dilakukan dengan melakukan analisis data ulasan produk. Data ulasan produk didapatkan dari produk pada website Sociolla.com dan femaledaily dimana data ulasan akan dilakukan analisis sentiment dan diklasifikasikan menjadi 2 klasifikasi yaitu sentiment negatif dan sentiment positif. data sentiment selanjutnya dikelompokkan berdasarkan jenis kulit dan rentang umur konsumen. data latih yang digunakan untuk membuat model SVM menggunakan 500 data dimana untuk evaluasi menggunakan 100 data test. Komposisi data latih sebanyak 250 data dengan sentiment positif dan 250 data dengan sentiment negatif. Komposisi data testing sebanyak 50 data dengan sentiment positif dan 50 data dengan sentimen negatif.
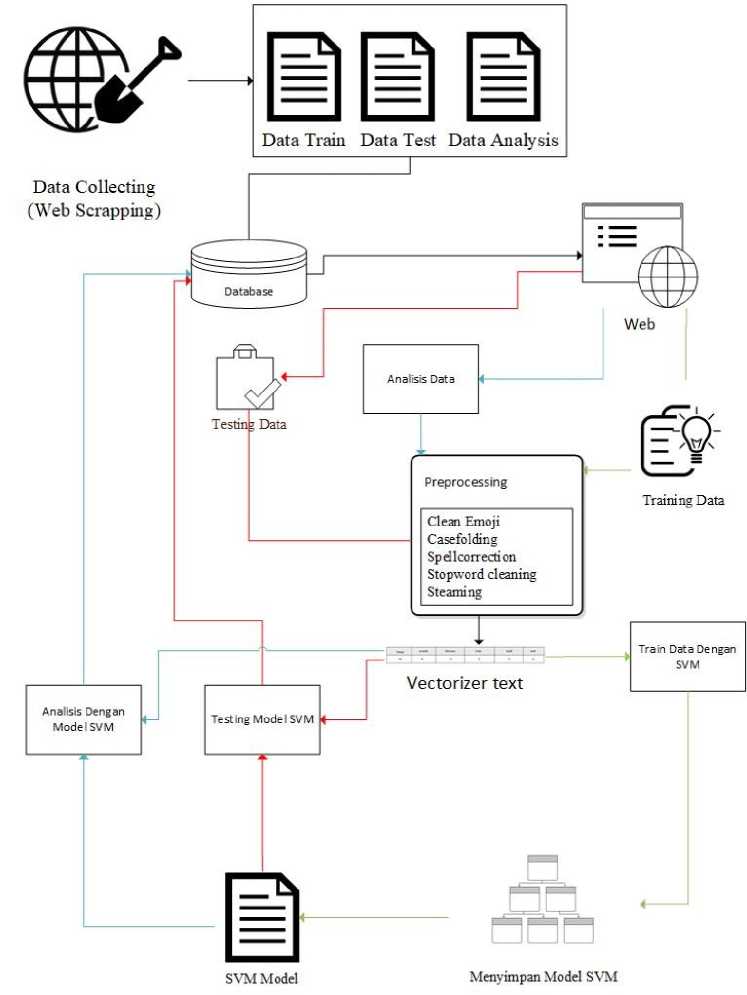
Gambar 2 Gambaran Umum
Gambar 2 adalah gambaran umum sistem dimana sistem dimulai dari pengumpulan data dengan web scrapping. Data yang telah dikumpulkan di seleksi menjadi data train, data test dan data analysis. Data yang telah di kumpulkan selanjutnya akan dimasukkan ke dalam database dimana proses pengolahan data mulai dari pelatihan model svm, testing model svm dan analisis data produk di atur pada website. Proses preprocessing adalah proses yang berfungsi untuk melakukan persiapan data dimana dalam proses preprocessing dilakukan clean emoji yang berfungsi untuk menghapus data emoji pada ulasan produk, casfolding yang berfungsi untuk merubah seluruh teks menjadi huruf kecil, spell correction yang berfungsi untuk memperbaikin kata yang typo dan proses steaming yang berfungsi untuk menghilangkan kata imbuhan. Output dari proses preprocessing adalah berupa data vector dimana proses vectorizer data menggunakan metode TF-IDF. Training data merupakan proses pelatihan model SVM dimanan sebelum proses training data, data sebelumnya dilakukan proses preprocessing untuk mendapatkan data dengan bentuk data vector. Output dari proses pelatihan data adalah berupa model SVM yang berisi nilai hyperplane yang selanjutnya digunakan untuk proses testing model SVM dan analisis data. proses analisis data merupakan tahapan analisis sentiment dari ulasan produk dimana sebelum data ulasan produk di analisis, dilakukan proses preprocessing untuk mempersiapkan data dan mendapatkan data dengan format vector. Tahapan analisis data menghasilkan output berupa sentiment dimana selanjutnya dimasukkan kedalam database dan dilakukan visualisasi hasil analisis pada website. Proses testing data adalah tahapan evaluasi model SVM yang dihasilkan pada proses training data dimana dalam evaluasi model SVM dilakukan perhitungan nilai accuracy, precission, specificity, recall dan F1.
Data yang digunakan dalam analisis didapatkan dari ulasan produk kosmetik pada website https://femaledaily.com dimana dalam penelitian ini digunakan data ulasan dari 10 produk dan data produk yang diambil sebanyak 500 data setiap produk.
Web scraping merupakan teknik yang digunakan untuk melakukakn ekstraksi data yang tersedia pada website dan untuk disimpan kedalam database atau file system [6]. teknik web scraping dilakukan dengan mengambil sumber daya yang ada pada website dan melakukan ekstraksi sumber daya yang didapatkan. Proses web scraping digunakan untuk mengambil data ulasan produk pada halaman website https://femaledaily.com. Berikut flowchart dari web scraping pada gambar 3.
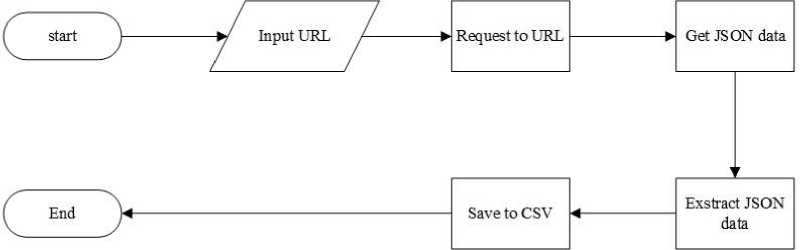
Gambar 3 Flowchart Web Scraping
Gambar 3. Merupakan proses web scraping. Web scraping dimulai dari memasukkan data URL target produk yang akan diambil ulasan produknya dimana URL didapatkan dengan mengambil URL API yang ada pada saat membuka halaman produk pada website https://sociolla.com dan https://femaledaily.com. Selanjutnya melakukan request kepada URL dimana dapat berupa POST. Selanjutnya request POST akan memberikan output berupa data json. Selanjutnya dilakukan ekstraksi data JSON dimana dari data JSON yang telah didapatkan akan diambil beberapa data yang diperlukan seperti data ulasan produk, jenis kulit, rentang
umur dan lainnya. Setelah dilakukan ekstraksi selanjutnya data hasil ekstraksi data JSON akan disimpan kedalam format CSV.
2.4 Preprocessing
Preprocessing merupakan tahapan untuk persiapan data mentah yang selanjutnya di proses untuk perubahan format data yang sesuai dengan kebutuhan. Berikut flowchart dari preprocessing pada gambar 4.
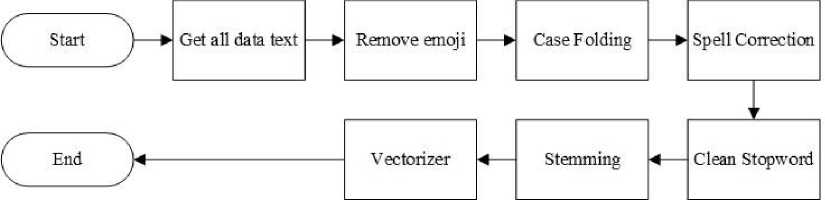
Gambar 4 Flowchart Preprocessing
Gambar 4 merupakan flowchat dari tahapan preprocessing. Tahapan preprocessing dimulai dari mendapatkan seluruh data teks dimana selanjutnya dilakukan clean emoji yang berfungsi untuk membersihkan karakter emoji pada data teks, selanjutnya case folding yang berfungsi untuk merubah seluruh data teks menjadi huruf kecil, selanjutya spell correction yang berfungsi untuk memperbaiki kata yang tidak sesuai atau memiliki kesalahan ejaan, selanjutnya stopword cleaning yang berfungsi untuk menghilangkan kata sambung pada data teks, selanjutnya dilakukan proses stemming yang berfungsi untuk mendapatkan kata dasar dengan menghilangkan imbuhan pada kata dan selanjutnya proses vectorizer yang berfungsi untuk melakukan pembobotan pata data teks dimana pada pembobotan data teks menggunakan metode TF-IDF dan menghasilkan data vektor.
Sentiment analysis merupakan analisis terhadap pendapat, emosi atau sikap yang diutarakan dari sekumpulan teks yang bertujuan untuk melakukan identifikasi atau menemukan karakteristik sentiment. Berikut flowchart dari sentiment analysis pada gambar 5.
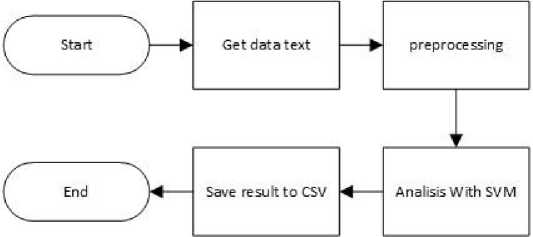
Gambar 5 flowchart Sentiment Analysis
Gambar 5 merupakan flowchart dari sentiment analysis. Sentiment analysis dimulai dari mengambil data text yang akan dilakukan analisis. Selanjutnya data text melalui proses preprocessing dimana hasil preprocessing yang berupa data vektor selanjutnya akan dilakukan analisis dengan algoritma SVM. hasil analisis selanjutnya akan disimpan kedalam file dengan format CSV.
kajian pustaka merupakan materi yang terkait dengan penelitian meliputi kosmetik, kulit, text mining, Support Vector Machine (SVM), dan TF-IDF.
Menurut Badan Pengawas Obat dan Makanan (BPOM) dalam Peraturan Kepala BPOM RI Nomor HK.03.1.23.08.11.07331 tahun 2011 tentang Persyaratan Teknis Bahan Kosmetika menyatakan Kosmetika adalah bahan atau sediaan yang dimaksudkan untuk digunakan pada bagian luar tubuh manusia (epidermis, rambut, kuku, bibir, dan organ genital bagian luar), atau gigi dan membran mukosa mulut, terutama untuk membersihkan, mewangikan, dan mengubah penampilan, dan/atau memperbaiki bau badan atau melindungi atau memelihara tubuh pada kondisi baik.
kulit merupakan jaringan terluar tubuh dan merupaka organ terberat dan terluas pada manusia [7]. Kulit pada tubuh manusia berfungsi sebagai pelindung terluar dari tubuh manusia dimana kulit juga berfungsi sebagai penyeimbang suhu tubuh dan penghalang agar tubuh tidak kehilangan air.
Jenis kulit manusia dipengaruhi oleh faktor lingkungan dan keturunan dimana terdapat 4 jenis kulit yaitu kulit kering, kulit berminyak, kulit normal dan kulit kombinasi. Kulit kering merupaka jenis kulit yang memiliki kadar minyak yang rendah yang menyebabkan kulit cepat kehilangan kelembapan. Kulit berminyak adalah jenis kulit yang memiliki kadar minyak yang tinggi dimana jenis kulit ini disebabkan oleh kelenjar minyak yang terlalu aktif yang menyebabkan produksi minyak atau sebum yang berlebih. Kulit normal adalah jenis kulit yang memiliki kadar minyak dan kadar air yang seimbang. Jenis kulit kombinasi adalah jenis kulit kombinasi antara jenis kulit kering dan jenis kulit berminyak dimana jenis kulit kombinasi memiliki kadar minyak yang tinggi pada bagian hidung, dahi dan dagu.
Text mining merupakan metode yang digunakan untuk menemukan pola pada data tekstual yang besar [4]. Dalam penerapan text mining menggunakan metode Natural Language Processing (NLP) untuk merubah stuktur data text menjadi struktur data text yang dapat digunakan dalam analisis dengan algoritma machine learning.
Support Vector Machine atau SVM adalah algoritma supervised learning dimana algoritma SVM dapat digunakan untuk melakukan klasifikasi dan regresi. Tujuan utama dari algoritma SVM adalah mencari hyperplane terbaik. Hyperplane merupakan margin pemisah antar kelas. Algoritma SVM dapat mengatasi data linear ataupun non linear dengan metode kernel trick.berikut persamaan yang digunakan dalam SVM pada persamaan 1.
w∙xi + b≤ —1 (1)
Persamaan 1 merupakan persamaan dari klasifiksi algoritma SVM dimana jika data masuk kedalam kelas -1. Dalam klasifikasi SVM persamaan 1 merupakan fungsi pemisah untuk data yang memiliki nilai kurang dari 0. Berikut persamaan untuk data yang memiliki nilai lebih dari 0.
w∙xi + b≥ 1 (2)
Persamaan 2 merupakan persamaan untuk memisahkan data yang memiliki nilai lebih besar dari 0. Persamaan 1 dan persamaan 2 disebut sebagai decision function dimana untuk mencari nilai w dan b dengan menggunakan persamaan 3.
L{w,b,α) =1 Ilw∣∣2-∑ αi(yijχi w+b)—1) 2 i=1
Persamaan 3 merupakan persamaan yang digunakan untuk mencari nilai dari w dan b.
dimana persamaan 3 dapat disederhanakan dengan fungsi lagragian pada persamaan 4.
1n n n
L(w,b,α) = 2wτ w—∑ αiyiXlτw+bl∑ αiyi) + ∑ αi
(4)
Persamaan 4 merupakan penyederhaan dari persamaan 3 dimana menggunakan metode lagragian multiple. Penggunaan metode lagragian multiple berfungsi untuk mengatasi permasalahan quadratic programming. Persamaan 4 dapat disederhanakan kembali untuk mencari nilai dari αi pada persamaan 5.
1n n n
α 1 ,.,αn=maxαi_a-2∑ ∑ αiαjyiyj×τxj+∑ αi
Subject to :
n
αi≥0,i ∈ 1 ,.,ndan∑αiyi = 0
(5)
i = 1
Persamaan 5 merupakan penyederhanaa dari persamaan 4 dimana fungsi dari persaman 5 adalah untuk mencari nilai dari αi. Dalam klasifikasi SVM terdapat metode soft margin yang berfungsi untuk memecahkan permasalah untuk data non linear dimana terdapat slack variable yang mengontrol nilai error dari hyperplane. berikut persamaan soft margin pada persamaan 6.
w6t t6,ξi'=minwc>tc1 Ilw∣∣2+C ∑ ξi
-
2 i = 1
Subject to :
yi (w.xi—t)≥ 1— ξi ∧ ξi≥ 0,1 ≤i≤n (6)
Persamaan 5 merupakan persamaan dari soft margin. C merupakan nilai pinalti terhadap error dimana ξimerupakan slack variable. Persamaan 5 dapat disederhanakan untuk mengatasi quadratic programming dengan lagrange multiple seperti pada persamaan 6.
i =1
Subject to :
yi (w.xi—t)≥ 1— ξi ∧ ξi≥ 0,1 ≤i≤n (7)
Persamaan 6 merupakan penyelesaian persamaan 5 dengan metode lagrange multiple. Persamaan 6 dapat disederhanakan dengan menggunakan metode dual problem dimana dengan menggunakan metode dual problem dapat memudahkan dalam mencari nilai dari αi. Berikut dual problem dari persamaan 6.
1n n n
Subject to :
n
0≤αi≤C,i ∈ 1 ,...,ndan∑ αiyi = 0
(8)
i=1
Persamaan 7 merupakan dual problem dari persamaan 6 dimana nilai αi tidak boleh lebih besar dari C. C merupakan variable yang memberikan nilai pinalti terhadapa nilai error dimana jika αi lebih besar dari C makan nilai αi sama dengan nilai C. dalam algoritma SVM
untuk mengatasi data non-linear terdapat metode kernel yang dapat melakukan transformasi data non-linear yaitu pada persamaan 8 sampai dengan persamaan 11.
-
1. Kernel linear
-
2. Kernel Polynomial
-
3. Kernel Gausian atau Radian basis function (RBF)
K (x,xi)=exp Ilx - xH2I
-
4. Kernel Sigmoid
-
3.5 TF-IDF
TF-IDF atau term frequency inverse document frequency adalah metode yang digunakan untuk melakukan pembobotan kata pada suatu dokumen[7]. Berikut persamaan dari TF.
TF = JildiL j ∑f'(dj) =1 (13)
Persamaan 12 merupakan persamaan dari term frequency (TF). fi (dj) adalah kemunculam term ke i pada dokumen ke j dimana dibagi dengan jumlah term pada dokumen ke j. Selanjutnya persamaan inverse document frequency (IDF) pada persamaan 13.
idf (t=log (dfl)+1
(14)
Persamaan 13 merupakan persamaan dari Inverse Document Frequency dimana n merupakan jumlah data dan df (t) merupakan jumlah data yang mengandung term ke t.
-
4. Hasil dan Pembahasan
Pada bagian ini akan membahas mengenai hasil dari penelitian analisis ulaPenelitian dilakukan dengan menggunakan data ulasan produk kosmetik yang di ambil dari website sociolla dan female daily. Data disimpan dengan format CSV dimana data selanjutnya disimpan kedalam database dengan website. Analisis dan visualisasi hasil dilakukan di dalam website. 4.1 Hasil
Hasil dari penelitian ini berupa aplikasi yang dibuat berbasis website dimana dibagi menjadi 5 halaman yaitu halaman data train, halaman data test, halaman data produk, dan halaman analisis produk. Berikut halaman data train pada gambar 6.
ft Dashboard
O master data
-
• DataTraIn
-
• DataTest
Tekstumya cair, dan busanya ga terlalu banyak, pemakean pertamaga begitu terlalu ngefek di aku, tp beneran bikin kulit wajah licin euy kayak porselen
udah pembelian ke 3 sih facial wash Ini so far di aku engga ada masalah apaa2. aku suka produk Ini kama dia Perbentuk gel dan engga mengeluarkan banyak busa, facial wash ini juga enggak membuat wajah aku ketarik kering setelah pemakaiannya dan ada efek brighteningnya si sedikit, i Iovee It
terus ke dia adalah, di aku ampuh buat ngebasmi komedo sih khusus nya di hidung. Jadi halus hidung, mungkin kama ada naturan AHA nya (cmnw). so far, suka udah pasti
Facial wash Ini gentle, busany dikit. tpi ada sensasi ketarik dikit di muka, tapi mantulnya ini malah ngilangin bruntusan ku. aku make udah ada 20ha ria n gtu. Kulitku kombinasi. Daaaan ngurangin minyak dimuka ku ini rekomendasi bgt sih
Pakai ini udah lama, kulit aku berminyak, cocok banget pakai rangkaian yg white secret ini. Aku barengin pakai serumnya dulu sekitar 1-2 bulan, wajah kelihatan lebih cerah dan gak kusam, bagun tidur juga gak banyak minyak di wajah
suka bgt karena busanya sedikit dan enak aja ku suka jatuh cinta dr pertama pakai cocok di aku karena ada kandungan AHA nya yg ngurangin minyak seketika muka langsung seger dan enak banget Iah gamau ganti2 Iagi ttep cinta fw ini dr awal wardah launching T
Semua facial wash Wardah cocok banget dikulitku ngga ngasih reaksi yang aneh2 termasuk ini. Tekstumya gel soft. Ngga bikin wajah kering keset ke tarik habis pakai ini dan malah ngasn efek lembut lembab gitu habis cuci cuma selintas doang, mengingat ini hanya facial wash yg fungsinya cuma membersihkan. Lumayan suka sih sama face wash ini ©
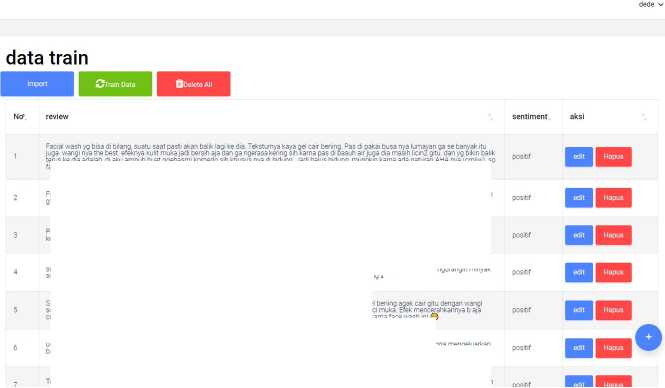
Gambar 6 Halaman Data Train
Gambar 6 merupakan halaman data train. Halaman data train adalah halaman yang berfungsi untuk melakukan pelatihan data dengan metode support vector machine (SVM) dimana dari pelatihan data akan menghasilkan model SVM. pada halaman data train user dapat melakukan perubahan data train dan dapat melakukan import data dengan format CSV. Selanjutnya terdapat halaman data test pada gambar 7.
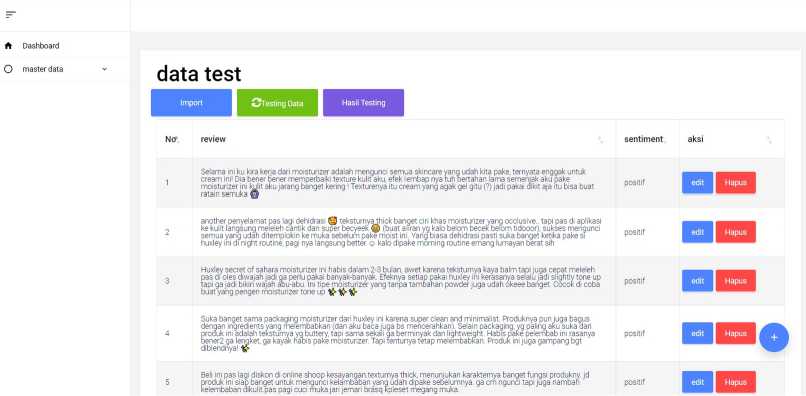
Gambar 7 Halaman Data Test
Halaman data test merupakan halaman yang digunakan untuk melakukan evaluasi model SVM. evaluasi yang dilakukan meliputi perhitungan accuracy, precission, recall, specificity dan F1. Dalam halaman data test user dapat melakukan perubahan data testing dan memasukkan data testing dengan format CSV. Selanjutnya terdapat halam data produk pada gambar 8.
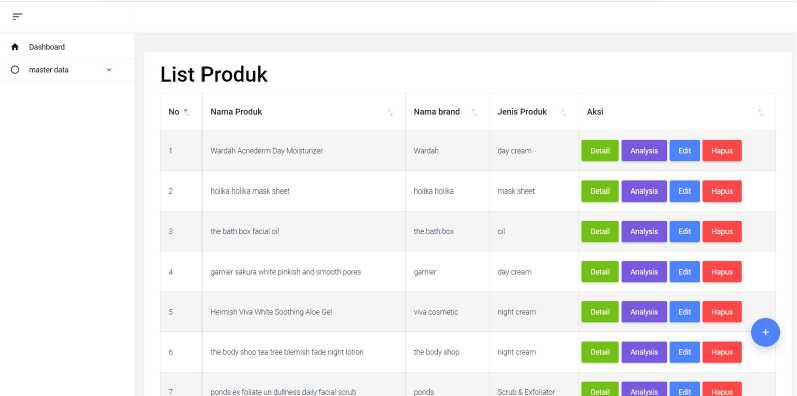
Gambar 8 Halaman Data Produk
Gambar 8 merupakan halaman data produk yang berfungsi untuk menampilkan produk yang tersedia di dalam sistem. Pada halaman data produk user dapat melakukan analisis ulasan produk dengan menekan tombol detail produk dimana tombol detail produk terhubung dengan halaman detail produk seperti pada gambar 9.
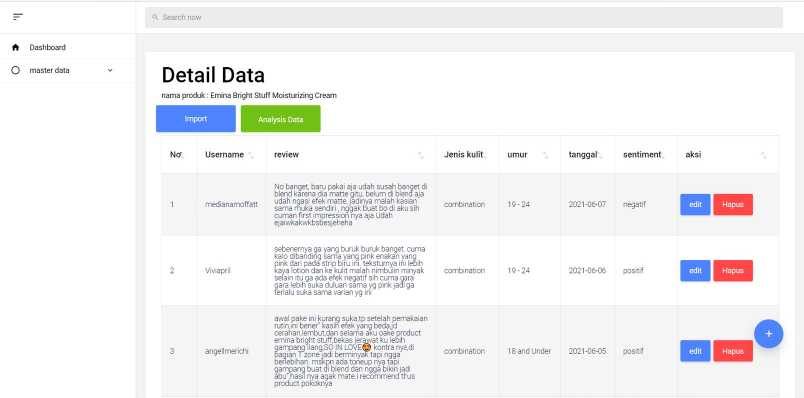
Gambar 9 Halaman Detail Produk
Gambar 9 merupakan halaman detail produk dimana halaman detail produk merupakan halaman yang menampilkan data ulasan produk. Pada halaman detail produk user dapat merubah data ulasan produk dimana user juga dapat melakukan analisis ulasan produk. Selanjutnya pada halaman data produk user dapat melihat hasil analisis dengan menekan tombol analisis dimana tombol analisis terhubung dengan halaman analisis produk.
Analisis Sentiment
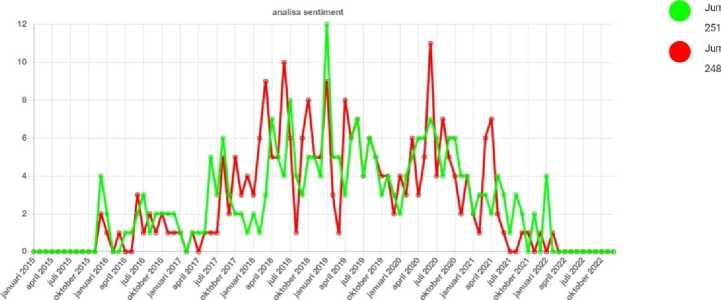
Gambar 10 Halaman Analisis Produk
Gambar 10 merupakan halaman analisis produk dimana halaman analisis produk berfungsi untuk menampilkan analisis produk berdasarkan ulasan produk. Hasil analisis ditampilkan dalam bentuk grafik dimana terdapat grafik sentiment konsumen terhadap produk berdasarkan rentang waktu. Selanjutnya terdapat grafik sentiment dimana data sentiment dikelompokkan berdasarkan jenis kulit konsumen dan rentang umur konsumen. selanjutnya terdapat ranking kata yang memiliki frekuensi tinggi berdasarkan jenis sentiment dimana ranking kata dikelompokkan berdasarkan sentiment negatif dan sentiment positif.
-
4.2 Analisis Hasil Penelitian
Hasil pengujian sistem dengan menggunakan 500 data train dan 100 data test menghasilkan akurasi tertinggi sebesar 90% dimana dalam pengujian sistem menggunakan nilai C sebesar 1 dan ada tahapan pembobotan kata menggunakan minimal TF sebesar 3 dan maxsimal IDF sebesar 9. Berikut tabel pengujian sistem pada tabel 1.
Tabel 1 Hasil Evaluasi
|
No |
C |
TF |
IDF |
Accuracy |
F1 |
Precission |
Recall | |||
|
Positif |
Negatif |
Positif |
Negatif |
Positif |
Negatif | |||||
|
1 |
1 |
3 |
0,9 |
90 |
0,91 |
0,89 |
0,84 |
0,98 |
0,98 |
0,82 |
|
2 |
2 |
5 |
0,7 |
85 |
0,86 |
0,84 |
0,82 |
0,89 |
0,90 |
0,80 |
|
3 |
3 |
7 |
0,5 |
81 |
0,82 |
0,80 |
0,78 |
0,84 |
0,86 |
0,76 |
|
4 |
4 |
9 |
0,3 |
83 |
0,84 |
0,82 |
0,79 |
0,88 |
0,90 |
0,76 |
|
5 |
1 |
3 |
0,3 |
87 |
0,88 |
0,86 |
0,84 |
0,91 |
0,92 |
0,82 |
|
6 |
2 |
5 |
0,5 |
86 |
0,87 |
0,85 |
0,81 |
0,93 |
0,94 |
0,78 |
|
7 |
3 |
7 |
0,7 |
81 |
0,82 |
0,80 |
0,78 |
0,84 |
0,86 |
0,76 |
|
8 |
4 |
9 |
0,9 |
82 |
0,84 |
0,80 |
0,77 |
0,90 |
0,92 |
0,72 |
Tabel 1. Merupakan hasil evaluasi dari sistem. Hasil evaluasi menunjukan data dengan nilai C sebesar 1, nilai TF sebesar 3 dan nilai IDF sebesar 0,9 memiliki nilai akurasi tertinggi dimana menghasilkan akurasi sebesar 90%. Nilai C mempengaruhi akurasi karena C merupakan variable yang memberikan pinalti terhadap nilai aplha dimana jika variable C memiliki nilai yang besar membuat variasi nilai Alpha semakin tinggi dan sebaliknya jika nilai C semakin kecil membuat nilai alpha menggunakan nilai C. nilai TF berfungsi untuk mengatur frekuensi kata minimal yang digunakan dalam pembobotan kata dimana semakin besar nilai TF maka semakin sedikit kata yang dilakukan pembobotan pada penelitian dan juga sebaliknya. Nilai IDF merupakan nilai kecenderungan kata pada kumpulkan data dimana semakin tinggi nilai IDF maka semakin banyak kata yang digunakan dalam pembobotan dan juga berlaku sebaliknya.
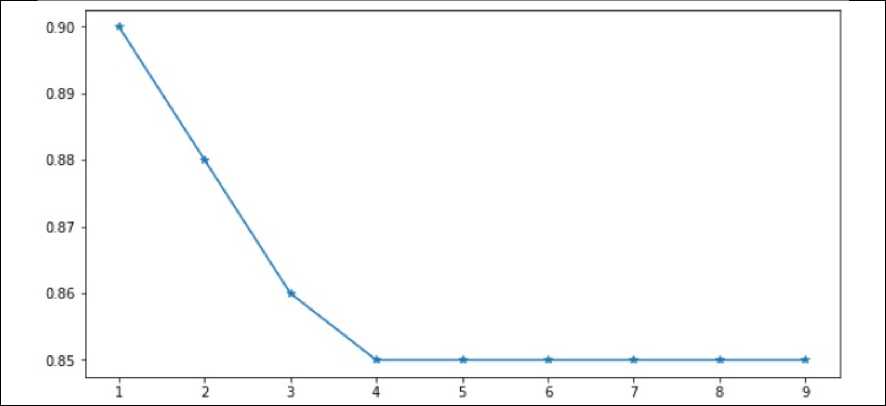
Gambar 11 Perubahan Nilai C
Gambar 11 merupakan pengaruh perubahan nilai C terhadap akurasi yang dihasilkan. Analisis dilakukan dengan menggunakan kombinasi nilai min TF sebesar 3 dan max TF sebesar 0,9. Berdasarkan grafik menunjukan terjadinya penerununan hasil akurasi seiring dengan meningkatnya nilai C dimana hal ini menunjukan training data lebih baik menggunakan metode soft margin daripada hard margin.
Kesimpulan yang dihasilkan berdasarkan penelitian yang telah dilakukan adalah analisis respon pelanggan dapat dilakukan dengan menggunakan metode text mining dan algoritma Support Vector Machine (SVM) dimana data yang dapat digunakan adalah data ulasan produk. Berdasarkan rangkaian proses pengujian didapakan metode text mining dan algoritma Support Vector Machine (SVM) dapat digunakan untuk klasifikasi sentiment dimana menghasilkan akurasi tertinggi sebesar 90% dan akurasi terendah sebesar 81%. Berdasarkan hasil pengujian dengan perubahan nilai indikator, nilai C sangat berpengaruh dalam hasil akurasi dari klasifikasi dimana semakin rendah nilai C menunjukan kenaikan akurasi. Dengan hasil nilai C yang rendah dan menghasilkan akurasi terbaik menandakan algoritma SVM dengan metode soft margin merupakan metode terbaik untuk klasifikasi data teks. Pengembangan penelitian dapat dilakukan dengan menambahkan jumlah data latih dan data test untuk menghasilkan akurasi yang lebih tinggi. Penambahan metode perbaikan kata dan normalisasi data dapat meningkatkan akurasi. Perbandingan hasil dengan algoritma SVM dengan algoritma lainnya dapat dilakukan pada penelitian selanjutnya.
Daftar Pustaka
-
[1] S. Maryama, “PENERAPAN E-COMMERCE DALAM MENINGKATKAN DAYA SAING USAHA,” Jurnal Liquidity, vol. 2, nº 1, pp. 73-79, 2013.
-
[2] R. Yustiani e R. Yunanto, “PERAN MARKETPLACE SEBAGAI ALTERNATIF BISNIS DI ERA,” Junla Ilmiah Komputer dan Informatika (KOMPUTA), vol. 6, nº 2, pp. 43-48, 2017.
-
[3] I. R. Servanda, P. R. K. Sari e N. A. Ananda, “PERAN ULASAN PRODUK DAN FOT PRODUK YANG DITAMPILKAN PENJUAL PADA MARKETPLACE SHOPEE TERHADAP MINAT BELI PRIA DAN WANITA,” JURNAL MANAJEMEN DAN BISNIS, vol. 2, pp. 69-79, 2019.
-
[4] R. &. S. J. Feldman, The Text Mining Handbook : Advanced Approaches in Analyzing Unstructured Data., New York: Cambridge University Press , 2007.
-
[5] “Klasifikasi Berita Online Menggunakan Metode Support Vector Machine dan K- Nearest Neighbor,” JURNAL SAINS DAN SENI ITS, vol. 5, pp. 317-322, 2016.
-
[6] V. A. Flores, P. A. Permatasari e L. Jasa, “Penerapan Web Scraping Sebagai Media Pencarian dan
Menyimpan Artikel Ilmiah Secara Otomatis Berdasarkan Keyword,” Majalah Ilmiah Teknologi Elektro, vol. 19, nº 2, pp. 157-162, 2020.
-
[7] T. Igarashi, K. Nishino e S. K. Nayar, The Appearance of Human Skin, New York: Foundations and Trends in Computer Graphics and Vision, 2005.
Discussion and feedback