Implementasi Algoritma Apriori untuk Menemukan Pola Pembelian Konsumen pada Perusahaan Retail
on
JITTER- Jurnal Ilmiah Teknologi dan Komputer Vol. 1, No. 2 Desember 2020
Implementasi Algoritma Apriori untuk Menemukan Pola Pembelian Konsumen pada Perusahaan Retail
Ulfadiyah Nir Kumalasaria1, I Ketut Gede Darma Putraa2, I Putu Arya Dharmaadia3
aDepartment of Information Technology, Udayana University, Indonesia e-mail: 1ulfadiyahkumalasari@gmail.com, 2ikgdarmaputra@unud.ac.id, 3aryadharmaadi@unud.ac.id
Abstrak
Persaingan bisnis yang semakin ketat membuat perusahaan retail harus mencari terobosan baru untuk menentukan strategi yang tepat dalam menjalankan bisnis. Data transaksi penjualan dapat dimanfaatkan oleh pihak manajemen perusahaan untuk menganalisis kebiasaan belanja pelanggan mengenai barang-barang yang sering dibeli secara bersamaan dengan menerapkan analisis keranjang belanja (market basket analysis) menggunakan teknik data mining. Asosiasi merupakan salah satu metode data mining yang digunakan untuk menemukan hubungan menarik antara suatu kombinasi item. Apriori adalah salah satu algoritma dari metode asosiasi yang digunakan untuk menambang frequent itemset (kombinasi item yang sering muncul) dalam membentuk aturan asosiasi. Data yang digunakan dalam penelitian ini adalah sampel 200 data transaksi penjualan. Aturan asosiasi final yang diperoleh dari data transaksi tersebut adalah “Jika konsumen membeli chocolatos chocolate drink28g, maka akan membeli CUP COFFE + AIR SEDUH” dengan persentase support sebesar 2,5% dan confidence sebesar 100%. Hasil penelitian ini membuktikan bahwa Algoritma Apriori cocok diterapkan untuk menemukan pola pembelian konsumen pada data transaksi penjualan. Aturan asosiasi yang dihasilkan dapat digunakan sebagai pendukung dalam pengambilan keputusan oleh manajemen perusahaan.
Kata kunci: Algoritma Apriori, Data Mining, Market Basket Analysis, Metode Asosiasi
Abstract
Retail companies require to find new solutions in running a business amid increasing competition. Company management used sales transaction data to analyzed customer buying behaviour regarding items that are often purchased simultaneously by applying market basket analysis using data mining techniques. Association is a data mining method used to find interesting relationships between the combination of items. Apriori is an algorithm of the association method used to mine frequent itemsets in forming association rules. The data used in this study is a sample of 200 sales transaction data. The final association rule obtained from the transaction data is "If buy chocolatos chocolate drink28g, then buy CUP COFFE + AIR SEDUH" with a support percentage of 2.5% and a confidence of 100%. The results of the study proved Apriori Algorithm suitable for finding consumer purchasing patterns in sales transaction data. The resulting association rules used as a support in decision making by company management.
Keywords: Apriori Algoritm, Association, Data Mining, Market Basket Analysis
Dewasa ini, persaingan bisnis yang semakin ketat membuat perusahaan retail harus mencari terobosan baru untuk menentukan strategi yang tepat dalam menjalankan bisnis. Data transaksi penjualan yang terus bertambah setiap hari menghasilkan laporan harian yang monoton, sehingga memunculkan fenomena “data rich but information poor”, artinya data yang berjumlah besar tidak diikuti dengan peningkatan informasi yang diperoleh dari data tersebut. Oleh karena itu, data transaksi perlu dimanfaatkan oleh pihak manajemen perusahaan untuk
menemukan informasi atau pengetahuan baru yang berguna sebagai pendukung dalam pengambilan keputusan. Informasi atau pengetahuan baru dapat ditemukan dengan menggunakan teknik data mining. Data mining adalah proses untuk mengekstraksi atau menggali pengetahuan dari data yang berjumlah besar [1].
Analisis keranjang belanja (market basket analysis) dapat dilakukan oleh perusahaan retail untuk menganalisis kebiasaan belanja pelanggan dengan menemukan asosiasi antara berbagai item yang ditempatkan oleh pelanggan dalam “keranjang belanja” [1]. Metode data mining yang dapat digunakan untuk analisis keranjang belanja adalah metode asosiasi. Analisis asosiasi digunakan untuk menemukan hubungan menarik antara suatu kombinasi item yang tersembunyi dalam suatu basis data. Hubungan ini dapat digambarkan dalam suatu bentuk aturan asosiasi [2]. Bentuk dari aturan asosiasi adalah if antecedent then consequent. Kekuatan hubungan suatu aturan asosiasi dapat diukur dengan dua parameter yaitu support dan confidence. Support (nilai penunjang) adalah persentase kombinasi item tersebut dalam basis data, sedangkan confidence (nilai kepastian) adalah kekuatan hubungan antar-item dalam aturan asosiasi [3]. Apriori adalah algoritma untuk menambang frequent itemset untuk aturan asosiasi Boolean. Algoritma apriori didasarkan pada fakta bahwa algoritma tersebut menggunakan pengetahuan sebelumnya tentang properti frequent itemset. Apriori menggunakan pendekatan berulang (iteratif) yang dikenal sebagai pencarian level-wise, k-itemsets digunakan untuk mengeksplorasi (k+1)-itemsets [1].
Penelitian sejenis yang menggunakan algoritma Apriori telah dilakukan untuk sistem pengelolaan daerah rawan banjir yang dapat memberikan peringatan dini kepada warga di daerah rawan banjir, sehingga dapat menyelamatkan lebih banyak jiwa dan harta benda [4], penelitian lain dengan algoritma Apriori adalah sistem rekomendasi perpusatakaan di perguruan tinggi yang secara efektif meningkatkan kualitas layanan di perpustakaan [5]. Penelitian ini menggunakan sampel 200 data transaksi penjualan perusahaan retail. Hasil analisis dapat digunakan untuk mengetahui pola pembelian konsumen berupa kombinasi item yang sering dibeli secara bersamaan, sehingga dapat membantu perusahaan dalam mengambil keputusan dan menetapkan kebijakan.
Penelitian tentang implementasi algoritma Apriori untuk mencari pola belanja konsumen dilakukan melalui beberapa tahap, seperti pada Figure 1.

Figure 1. Flowchart Algoritma Apriori
Aturan asosiasi yang dibentuk sesuai dengan tahapan pada flowchart algoritma Apriori dapat dijelaskan sebagai berikut.
-
1. Algoritma Apriori menggunakan pendekatan iteratif dimana k-itemset digunakan untuk
mengeksplorasi (k+1)-itemset.
-
2. Langkah pertama adalah input basis data yang digunakan untuk melakukan
perhitungan algoritma Apriori, kemudian menentukan nilai minimum support dan nilai minimum confidence.
-
3. Langkah selanjutnya yaitu mencari frequent 1-itemset dengan melakukan scanning
basis data untuk mengakumulasi jumlah kemunculan dari setiap item pada setiap transaksi.
-
4. Selanjutnya frequent 1-itemset digunakan untuk menemukan calon kandidat 2-itemset.
Calon kandidat 2-itemset ditemukan dengan cara saling memasangkan satu item dengan item lainnya sehingga dapat menghasilkan kombinasi yang memungkinkan untuk 2 buah item.
-
5. Kemudian kombinasi 2-itemset dihitung jumlah kemunculannya pada setiap transaksi
untuk menemukan frequent 2-itemset. Frequent 2-itemset digunakan untuk menemukan calon kandidat 3-itemset dan seterusnya hingga tidak ada lagi frequent (k+1)-itemset yang bisa ditemukan.
-
6. Jika tidak ada kombinasi k-itemset yang memenuhi nilai minimum support dan nilai
minimum confidence, maka akan kembali dilakukan proses scanning basis data untuk mencari jumlah kemunculan masing-masing k-itemset pada setiap transaksi.
-
7. Frequent 2-itemset dan frequent 3-itemset yang memenuhi nilai minimum support dan
nilai minimum confidence yang telah ditentukan digunakan sebagai aturan asosiasi.
-
8. Selanjutnya hitung nilai support dan confidence yang terdapat pada semua aturan dari
frequent (k+1)-itemset yang terbentuk. Hasil perkalian dari nilai support dan confidence yang paling tinggi merupakan aturan asosiasi yang paling baik dari keseluruhan transaksi yang ada dalam basis data.
Contoh berikut diberikan lima buah data transaksi penjualan barang seperti yang dijabarkan pada tabel berikut:
Table 1. Data Transaksi Penjualan
|
Tid |
Tanggal Transaksi |
Nama Barang |
|
1 |
01 Desember 2017 |
Cokelat, Biscuit |
|
2 |
01 Desember 2017 |
Kopi, Gula, Biscuit |
|
3 |
01 Desember 2017 |
Susu, Gula, Cokelat, Kopi |
|
4 |
01 Desember 2017 |
Kopi, Gula |
|
5 |
01 Desember 2017 |
Biscuit, Kopi, Gula |
Data transaksi tersebut dijabarkan dalam bentuk tabular menjadi 1-itemset yang berfungsi untuk mendapatkan calon (k+1) itemset berikutnya seperti tabel dibawah ini.
Table 2. Data Transaksi Bentuk Tabular 1-itemet
|
Tid |
Cokelat |
Biscuit |
Kopi |
Gula |
Susu |
|
1 |
1 |
1 |
0 |
0 |
0 |
|
2 |
0 |
1 |
1 |
1 |
0 |
|
3 |
1 |
0 |
1 |
1 |
1 |
|
4 |
0 |
0 |
1 |
1 |
0 |
|
5 |
0 |
1 |
1 |
1 |
0 |
|
Jumlah |
2 |
3 |
4 |
4 |
1 |
Selanjutnya, mencari frequent 2-itemsets dengan cara membangun satu set Ck dari kandidat k-itemsets dengan memasangkan satu item dengan item lainnya. Calon kandidat 2-itemset yang telah dibentuk kemudian dihitung jumlah kemunculannya pada setiap transaksi.
Table 3. Calon Kandidat 2-itemset
Kombinasi Jumlah
|
Cokelat |
Biscuit |
1 |
|
Cokelat |
Kopi |
1 |
|
Cokelat |
Gula |
1 |
|
Cokelat |
Susu |
1 |
|
Biscuit |
Kopi |
2 |
|
Biscuit |
Gula |
2 |
|
Biscuit |
Susu |
0 |
|
Kopi |
Gula |
4 |
|
Kopi |
Susu |
1 |
|
Gula |
Susu |
1 |
Jika ditetapkan nilai threshold minimum support = 2, maka frequent 2-itemset (F2) = {Biscuit, Kopi}, {Biscuit, Gula}, dan {Kopi, Gula}. Calon kandidat 3-itemset juga dibentuk dengan cara yang sama yaitu dengan memasangkan satu item dengan item lainnya. Calon kandidat 3-itemset yang telah dibentuk kemudian dihitung jumlah kemunculannya pada setiap transaksi seperti yang terdapat pada Tabel 4.
Table 4. Calon Kandidat 3-itemset
|
Kombinasi |
Jumlah | ||
|
Cokelat |
Biscuit |
Kopi |
0 |
|
Cokelat |
Biscuit |
Gula |
0 |
|
Cokelat |
Biscuit |
Susu |
0 |
|
Cokelat |
Kopi |
Gula |
1 |
|
Cokelat |
Kopi |
Susu |
1 |
|
Cokelat |
Gula |
Susu |
1 |
|
Biscuit |
Kopi |
Gula |
2 |
|
Biscuit |
Kopi |
Susu |
0 |
|
Biscuit |
Gula |
Susu |
0 |
|
Kopi |
Gula |
Susu |
1 |
Jika nilai threshold minimum support = 2, maka frequent 3-itemset (F3) = {Biscuit, Kopi, Gula}. Selanjutnya, membuat aturan asosiasi berupa antecedent dan consequent menggunakan frequent itemsets yang telah didapatkan pada proses sebelumnya. Calon aturan asosiasi dari frequent 2-itemset (F2) data transaksi penjualan dapat dilihat pada Tabel 5.
Table 5. Calon Aturan Asosiasi dari F2
|
Aturan (If Antecendent, then Consequent) |
Support |
Confidence |
|
If Biscuit, then Kopi |
3/5 = 60% |
2/3 = 67% |
|
If Kopi, then Biscuit |
4/5 = 80% |
2/4 = 50% |
|
If Biscuit, then Gula |
3/5 = 60% |
2/3 = 67% |
|
If Gula, then Biscuit |
4/5 = 80% |
2/4 = 50% |
|
If Kopi, then Gula |
4/5 = 80% |
4/4 = 100% |
|
If Gula, then Kopi |
4/5 = 80% |
4/4 = 100% |
Calon aturan asosiasi dari frequent 3-itemet (F3) data transaksi penjualan juga dibentuk dengan cara yang sama seperti sebelumnya, seperti yang dapat dilihat pada Table 6.
Table 6. Calon Aturan Asosiasi dari F3
|
Aturan (If Antecendent, then Consequent) |
Support |
Confidence |
|
If Biscuit and Kopi, then Gula |
2/5 = 40% |
2/2 = 100% |
|
If Biscuit and Gula, then Kopi |
2/5 = 40% |
2/2 = 100% |
|
If Gula and Kopi, then Biscuit |
2/5 = 40% |
2/4 = 50% |
Jika ditetapkan nilai threshold minimum confidence adalah 70%, Aturan asosiasi yang dipilih adalah aturan yang mempunyai nilai confidence yang lebih besar atau sama dengan dari nilai minimum confidence, maka aturan asosiasi final yang dapat dibentuk dapat dilihat pada Table 7.
Table 7. Aturan Asosiasi Final
|
Aturan (If Antecendent, then Consequent) |
Support |
Confidence |
Support x Confidence |
|
If Kopi, then Gula |
4/5 = 80% |
4/4 = 100% |
0.80 |
|
If Gula, then Kopi |
4/5 = 80% |
4/4 = 100% |
0.80 |
|
If Biscuit and Kopi, then Gula |
2/5 = 40% |
2/2 = 100% |
0.40 |
|
If Biscuit and Gula, then Kopi |
2/5 = 40% |
2/2 = 100% |
0.40 |
Aturan asosiasi final dari algoritma apriori dengan nilai minimum confidence 70% yang terdapat pada Table 7. diurutkan berdasarkan support × confidence. Aturan asosiasi merupakan hasil akhir yang bertujuan untuk memilih aturan yang paling cocok digunakan sebagai pedoman dalam pengambilan keputusan dan strategi pemasaran yang lebih baik. Tahap ini menghasilkan output berupa frequent itemset atau aturan asosiasi, dan menjelaskan bahwa aturan asosiasi yang mempunyai pengaruh paling kuat adalah aturan yang memiliki nilai perkalian support dan confidence yang paling tinggi [6].
Kajian pustaka berisi tentang teori-teori penunjang yang digunakan sebagai dasar dalam melakukan penelitian.
-
3.1 Data Mining
Data mining adalah proses untuk menemukan pola, dan informasi yang berguna secara otomatis dalam penyimpanan data besar dan memberikan kemampuan untuk memprediksi hasil pengamatan [2]. Gagasan untuk menemukan pola yang berguna dalam data telah ada sejak dahulu dan disebut dengan berbagai macam nama, termasuk data mining, ekstraksi pengetahuan, penemuan informasi, pengumpulan informasi, arkeologi data, dan pengolahan pola data. Data mining dan knowledge discovery in database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. KDD mengacu pada keseluruhan proses untuk menemukan pengetahuan yang berguna dari data, dan data mining mengacu pada algoritma tertentu dalam proses ini.
-
3.2 Market Basket Analysis
Data mining dan model asosiasi khususnya dapat digunakan untuk mengidentifikasi produk-produk terkait yang biasanya dibeli bersamaan. Model-model ini dapat digunakan untuk analisis keranjang belanja (market basket analysis) dan untuk mengungkapkan kumpulan produk atau jasa yang dapat dijual bersamaan [7]. Analisis keranjang belanja (market basket analysis) tidak mengacu pada satu teknik, sesuai dengan namanya, hal ini merujuk pada sekumpulan masalah bisnis yang berkaitan dengan pemahaman titik penjualan data transaksi. Penerapan teknik analisis keranjang belanja (market basket analysis) telah diperluas ke
berbagai bidang, sebagai contoh: aplikasi analisis keranjang belanja yang lebih baru adalah untuk memahami bagian-bagian situs web yang dikunjungi pelanggan [8].
Analisis asosiasi didefinisikan sebagai suatu proses untuk menemukan semua aturan asosiasi yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence). Analisis asosiasi dibagi menjadi dua tahap [3] yaitu:
-
1. Analisa pola frekuensi tinggi
Tahap ini akan mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam basis data. Nilai support sebuah item diperoleh dengan rumus berikut:
JumlahTransaksiuntukA
(1)
(2)
Support(A) = -------—-----τ------
TotalTransaksi
Sementara nilai support dari 2 item diperoleh dari rumus berikut.
∑ Transaksi untuk A dan B
Support(A1B) =-----—----—-----
Transaksi
-
2. Pembentukan aturan asosiasi
Setelah semua pola frekuensi tinggi ditemukan, kemudian akan dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan asosiatif “Jika A maka B” = A→B. Nilai confidence dari aturan A→B diperoleh dari rumus sebagai berikut:
, ∑ TransaksiuntukAdanB
Confidence = P(B∣A) = (3)
∑ TransaksiuntukA
Apriori adalah algoritma yang diusulkan oleh R. Agrawal dan R. Srikant pada tahun 1994 untuk menambang frequent itemset untuk aturan asosiasi Boolean. Nama algoritma apriori didasarkan pada fakta bahwa algoritma tersebut menggunakan pengetahuan sebelumnya tentang properti frequent itemset. Apriori menggunakan pendekatan berulang (iteratif) yang dikenal sebagai pencarian level-wise, k-itemsets digunakan untuk mengeksplorasi (k+1)-itemsets. Adapun proses utama yang dilakukan dalam algoritma Apriori, antara lain sebagai berikut [1].
-
1. Join Step (Penggabungan)
Proses ini akan mengombinasikan setiap item dengan item lainnya sampai tidak terbentuk kombinasi lagi.
-
2. Prune Step (Pemangkasan)
Hasil dari kombinasi item akan dipangkas dengan minimum support yang telah ditentukan oleh user.
Penelitian ini menggunakan data transaksi perusahaan retail sebanyak 200 data transaksi yang terdapat dalam satu bulan. Pengujian dilakukan dengan menentukan nilai minimum support dan nilai minimum confidence terlebih dahulu sebelum menjalankan algoritma Apriori agar menghasilkan aturan asosiasi yang baik.
Minimum support adalah nilai ambang / nilai kemunculan item tersebut dalam basis data. Minimum confidence adalah nilai ambang / nilai kekuatan hubungan antar item dalam aturan asosiasi yang terbentuk [6]. Nilai minimum support dan minimum confidence ditentukan melalui proses percobaan beberapa kali pada basis data yang digunakan. Penentuan nilai tersebut disesuaikan agar menghasilkan aturan asosiasi yang baik. Nilai minimum support yang ditentukan dalam penelitian ini adalah 2, karena dalam beberapa kali percobaan jumlah
kemunculan suatu kombinasi yang paling sering adalah 2 kali dalam keseluruhan transaksi. Nilai minimum confidence yang ditentukan adalah 75% untuk menghasilkan aturan asosiasi yang baik, karena keterkaitan antar item lebih kuat dengan kemungkinan kemunculan sebesar 75% dalam keseluruhan transaksi.
Identifikasi Perhitungan


Figure 2. Identifikasi Perhitungan
Proses selanjutnya adalah pencarian frequent itemset yang memenuhi nilai minimum support dan minimum confidence.
-
4.2 Pencarian Frequent Itemset
Pencarian frequent 1-itemset dilakukan dengan melewati proses scanning yang berulang-ulang untuk mengakumulasi jumlah kemunculan dari setiap item pada setiap transaksi. chocolates chocolate drink28g cu p coffe + Airseduh abc kopi susu 31g cheetos bbq 10gr coklat 250 silver queen milk chocolate Iuwak white kopi 20g cloud9 Crunchychocolate 10g Good Time Rainbow 16g TEH PUCUK HARUM 500ml
Figure 3. Frequent 1-itemset
Figure 3. adalah beberapa frequent 1-itemset yang ditampilkan dengan jumlah kemunculan sama dengan atau lebih besar dari nilai minimum support yang telah ditentukan sebelumnya. Kemudian, frequent 1-itemset dipasangkan antara satu item dengan item lainnya untuk mendapatkan kombinasi calon kandidat itemset. Kombinasi calon kandidat itemset yang dibentuk adalah kombinasi tanpa pengulangan, sehingga setiap item yang ada hanya bisa dipilih sekali. Berikut adalah beberapa kombinasi calon kandidat itemset yang dibangkitkan dari dalam data transaksi.
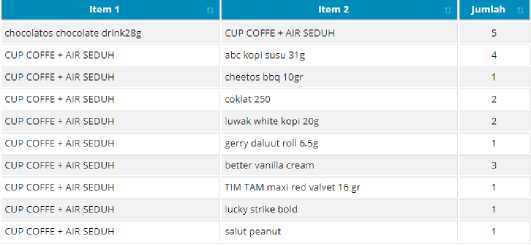
Figure 4. Calon Kandidat 2-itemset
|
teh pucuk harum 350ml |
salut peanut |
better vanilla cream |
1 |
|
choc□latos chocolate driπk28g |
cup coffe + Airseduh |
better vanilla cream |
1 |
|
abc kopi susu 31g |
cup coffe +airseduh |
coklat 250 |
2 |
|
abc kopi susu 31g |
cup coffe + airseduh |
better vanilla cream |
2 |
|
CUP COFFE+ AIR SEDUH |
cheetos bbq 10gr |
abc kopi susu 31g |
1 |
|
CUP COFFE+ AIR SEDUH |
coklat 250 |
better vanilla cream |
1 |
|
abc kopi susu 31g |
coklat 250 |
better vanilla cream |
1 |
|
CUP COFFE+ AIR SEDUH |
cheetos bbq 10gr |
coklat 250 |
1 |
|
abc kopi susu 31g |
cheetos bbq 10gr |
coklat 250 |
1 |
|
POP MIE rasa ayam |
gerry saluut malkist keju 18g |
AIR HANGAT |
1 |
Figure 5. Calon Kandidat 3-itemset
Kombinasi calon kandidat itemset yang telah dibangkitkan selanjutnya dihitung jumlah kemunculannya pada setiap transaksi. Kombinasi-kombinasi calon kandidat itemset tersebut kemudian dipilih yang mana termasuk frequent itemset dengan cara memilih yang memiliki nilai kemuculan sama dengan atau lebih besar dari nilai minimum support yang telah ditentukan dalam keseluruhan transaksi. Berikut adalah beberapa kombinasi yang termasuk frequent itemset dalam data transaksi.

Chocolatos chocolate dπnk28g
CUP COFFE+ AIR SEDUH
CUP COFFE+ AIR SEDUH
CUP COFFE+ AIR SEDUH Iuwak white kopi 20g 2
CUP COFFE+ AIR SEDUH better vanilla cream 3
abckopi susu 31 g coklat 250 3
abc k□pi susu 31 g better vanilla cream 2
cheetos bbq 10gr cheetos net 10g 2
cl□ud9crunchychocolate1Og OAsiSairminumOOOmI 2
clouds Crunchychocolate IOg
SerrysaluutmaIkistkeJu 18g
Figure 6. Frequent 2-itemset

abc kopi susu 31g
CUP COFFE+ AIR SEDUH
better vanilla cream
Figure 7. Frequent 3-itemset
Hasil diatas menunjukkan beberapa kombinasi itemset yang memenuhi syarat sebagai frequent itemset dengan nilai kemunculan 2 kali atau lebih dalam 200 transaksi. Frequent itemset tersebut kemudian dibuatkan calon aturan asosiasi.
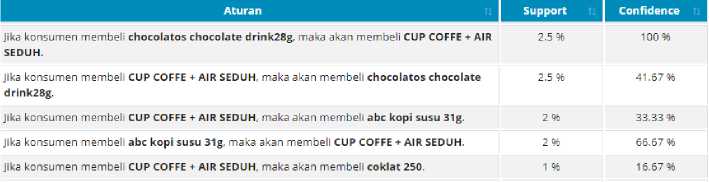

Figure 9. Calon Aturan Asosiasi F3
Calon aturan asosiasi yang dibuat berdasarkan frequent itemset tersebut, kemudian dihitung persentase nilai support dan nilai confidence dari masing-masing frequent itemset. Perhitungan nilai support dan nilai confidence menggunakan rumus yang telah dipaparkan pada teori sebelumnya.
Aturan asosiasi yang dipilih adalah calon aturan yang mempunyai nilai confidence sama dengan atau lebih besar dari nilai minimum confidence. Nilai minimum confidence yang telah ditentukan adalah 75%, maka beberapa aturan asosiasi final yang dapat dibentuk sebagai berikut.
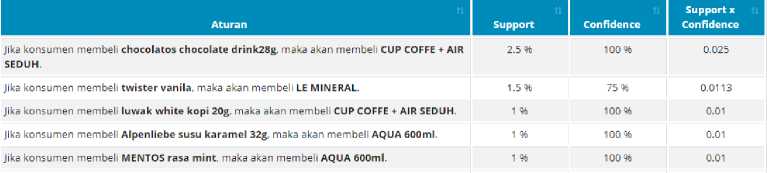
Figure 10. Aturan Asosiasi Final
Aturan asosiasi yang mempunyai pengaruh paling kuat dari beberapa aturan asosiasi yang dihasilkan adalah aturan yang memiliki nilai perkalian support dan confidence yang paling tinggi yaitu 0.025 terdapat pada aturan “Jika konsumen membeli chocolatos chocolate drink28g, maka akan membeli CUP COFFE + AIR SEDUH”. Jadi dapat disimpulkan bahwa kebanyakan pelanggan membeli chocolatos chocolate drink28g, juga akan membeli CUP COFFE + AIR SEDUH dan juga sebaliknya.
Algoritma Apriori cocok diterapkan untuk menemukan pola pembelian konsumen pada data transaksi penjualan perusahaan retail. Data yang digunakan dalam penelitian ini adalah sampel 200 transaksi dari data transaksi penjualan. Aturan asosiasi final yang dihasilkan dari data transaksi tersebut adalah “Jika konsumen membeli chocolatos chocolate drink28g, maka akan membeli CUP COFFE + AIR SEDUH” dengan persentase support sebesar 2,5% dan confidence sebesar 100%. Jadi dapat disimpulkan bahwa kebanyakan konsumen membeli chocolatos chocolate drink28g, juga akan membeli CUP COFFE + AIR SEDUH dan juga sebaliknya. Aturan asosiasi yang dihasilkan dapat digunakan sebagai pendukung dalam pengambilan keputusan oleh manajemen perusahaan, seperti membantu untuk menentukan strategi pemasaran, menentukan pengaturan tata letak produk, dan menetapkan diskon untuk kombinasi barang-barang tertentu yang sering dibeli bersamaan oleh konsumen.
References
-
[1] Han J, Kamber M, Pei J. Data Mining Concepts and Techniques. Third Edition. Waltham: Elsevier Inc. 2012.
-
[2] Tan PN, Steinbach M, Kumar V. Introduction to Data Mining. Boston: Pearson Education,Inc. 2006.
-
[3] Kusrini, Luthfi ET. Algoritma Data Mining. Yogyakarta: Penerbit Andi. 2009.
-
[4] Harun NA, Makhtar M, Aziz AA, Zakaria ZA, Abdullah FS, Jusoh JA, The Application of Apriori Algorithm in Predicting Flood Areas, International Journal on Advanced Science Engineering Information Technology. 2017: 7(3).
-
[5] Xueyuan W, Bo Y. Design and Implementation of An Apriori-based Recommendation System for College Libraries, International Conference on Engineering Simulation and Intelligent Control. 2018.
-
[6] Gama AWO. Algoritma Apriori Modifikasi Dengan Teknik Combination Reduction Dan Iteration Limitation Pada Keranjang Belanja. Thesis MT. Denpasar: Postgraduate Universitas Udayana; 2016.
-
[7] Tsiptsis K, Chorianopoulos A. Data Mining Techniques in CRM: Inside Customer
Segmentation. West Sussex: John Wiley & Sons, Ltd. 2009.
-
[8] Linoff GS, Berry MJA. Data Mining Techniques: For Marketing, Sales, and Customer Relationship Management. Third Edition. Indianapolis: Wiley Publishing, Inc. 2011.
Discussion and feedback