CI/CD Implementation On Microservices For Increasing Availability On Big Data Processing
on
Jurnal Elektronik Ilmu Komputer Udayana
Volume 12, No 3. Februari 2024
p-ISSN: 2301-5373
e-ISSN: 2654-5101
CI/CD Implementation On Microservices For Increasing Availability On Big Data Processing
Kompiang Gede Sukadharmaa1, I Putu Gede Hendra Suputraa2
aInformatics, Udayana University
Jl. Raya Kampus UNUD, Bukit Jimbaran, Kuta Selatan, Badung, Bali, Indonesia 1kompiang.sukadharma@gmail.com
Abstract
Big Data Processing needed a reliable system that not let the data loss. But sometimes we need to make the system down for a while because we need to push the newest changes of the system. The automation will help us achieve that. Continuous Integration and Continuous Deployment help us to reduce the downtime and increase the availability of the system. Thus, the implication will be led to reduce of data loss. This research focusses on the implementation of CI/CD Pipeline on single-point-of-failure service on Microservices Architecture. This research use Load-Testing to measure data loss on certain amount of time. The result on this research show that implementing CI/CD Pipeline on the Microservices that we made, make the down time will be less than 45 Second with 20 Virtual user who send the data.
Keywords: Microservices, CI/CD, Load Test, GitHub Actions, Single-Point-of-Failure
Seiring dengan meningkatnya kebutuhan dari industri teknologi, hal tersebut juga membuat banyak perubahan untuk beradaptasi terhadap perubahan yang perlu dilakukan. Tingginya perubahan yang terjadi membuat waktu yang digunakan untuk mengirimkan perubahan terbaru ke pengguna menjadi hal yang krusial. Perubahan yang terjadi memiliki kemungkinan membuat sebuah layanan tidak dapat diakses. Dalam pemrosesan Big Data, diperlukan arsitektur yang andal dan tingkat availability yang tinggi agar data-data dari pengguna tidak hilang. Oleh karena itu, diperlukan metode yang tepat untuk mengirimkan perubahan ke pengguna agar tidak mengganggu layanan yang sedang berjalan. Dalam pemrosesan Big Data, kita tidak bisa melakukannya secara konvensional [1]. Hal tersebut didukung dengan beberapa variabel yang telah teridentifikasi, yaitu (1) volume, (2) velocity, (3) variety, (4) veracity [2]. Variabel tersebut selanjutnya disebut sebagai sifat-sifat yang dimiliki oleh Big Data. Tingginya tingkat velocity dan besarnya volume ketika melakukan pemrosesan Big Data menjadi tantangan untuk mengirimkan rilis terbaru ke pengguna. Untuk itu, praktik continous diharapkan menyediakan beberapa kelebihan, seperti: (1) Mendapatkan tanggapan lebih banyak dan lebih cepat dalam proses pengembangan dan juga dari pengguna, karena perubahan terkirim lebih cepat; (2) Merilis perubahan secara cepat dan reliabel yang mana akan meningkatkan kualitas produk; (3) Continuous Deployment atau CD akan mempercepat proses perubahan lingkungan aplikasi dari development dan production [3]; (4) Layanan yang sedang berjalan tidak mengalami downtime yang lama, jadi data yang sedang terkirim tidak banyak yang hilang.
Grab, salah satu startup yang memiliki layanan superapp yang bergerak di bidang transportasi, pengantaran makanan, dan payment solutions. Pada Agustus tahun 2022 mencatat 23.6 Juta transaksi pengguna [4]. Dengan banyaknya transaksi tersebut perusahaan ini menggunakan praktik Continous untuk mengirimkan perubahan rilis dengan lebih cepat agar operasi ini tidak memengaruhi kecepatan dan stabilitas mereka. Pada artikel yang dirilis oleh Grab, terdapat peningkatan banyaknya perubahan yang dirilis dari staging environment ke production environment sebanyak 14,6% dari hanya 10% perubahan yang diimplementasikan menggunakan metode konvensional pada tahun 2018 menjadi 24.6% perubahan yang diimplementasikan dari staging ke production menggunakan teknik CI/CD. Pada artikel disebutkan bahwa mereka menghemat 5000 hari kerja pda tahun 2020 sendiri. Hal tersebut setara dengan 20 tahun kerja [5].
Penulis mengikuti alur penelitian yang terdapat pada Gambar 1 agar penelitian dapat berjalan secara lancar dan runtut
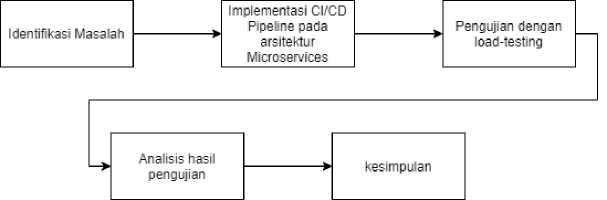
Gambar 1. Alur penelitian
Penjelasan dari alur penelitian di atas sebagai berikut:
-
a. Identifikasi Masalah
Pada awal penelitian, penulis melakukan identifikasi masalah yang ada di lapangan dan juga melakukan riset dengan menggunakan literatur yang dapat membantu penelitian. Lalu, masalah yang ditemukan oleh penulis adalah besarnya kemungkinan data loss pada layanan single point of failure yang terjadi ketika suatu layanan dalam microservices dimatikan untuk mengirimkan perubahan yang terbaru.
-
b. Implementasi CI/CD Pipeline Pada Arsitektur Microservices
Pada tahapan ini, penulis membuat sebuah sistem dengan arsitektur microservices dan juga pipeline CI/CD untuk menyimulasikan bagaimana CI/CD dapat meningkatkan availibility pada sebuah sistem. Implementasi menggunakan beberapa teknologi, untuk membuat sistem dengan arsitektur microservices penulis menggunakan bahasa pemrograman Go dan juga VS Code. Lalu, untuk membuat pipeline CI/CD, penulis menggunakan GitHub Actions dan juga menggunakan compute service dari AWS sebagai instance untuk menerapkan sistem ini.
-
c. Pengujian Dengan Load Testing
Pengujian dilakukan dengan metode Load-Testing menggunakan K6 dan memperhatikan beberapa metriks.
-
d. Analisis Hasil pengujian
Peneliti melakukan analisis terhadap beberapa metriks untuk menarik sebuah kesimpulan e. Kesimpulan
Pada tahap ini, penulis menarik kesimpulan dari beberapa metriks untuk menarik kesimpulkan dari hasil penelitian ini
Pengujian pada metode ini berada pada lingkup proses pengintegrasian dan pengiriman perubahan terbaru pada sistem arsitektur microservices. Proses pengintegrasian dan pengiriman perubahan terbaru dapat dibuat ke dalam sebuah alur kerja yang kita konfigurasikan agar prosesnya berjalan secara otomatis serta dapat meminimalkan downtime dari sebuah service. Selain itu, pada penelitian ini penulis juga menggunakan metode ini untuk meneliti data loss yang diharapkan metode ini dapat meminimalkan hal tersebut. Alat yang digunakan dalam lingkup penelitian ini untuk menjalankan CI/CD Pipeline pada penelitian kali ini adalah GitHub Actions. Gambar 2 menunjukkan alur kerja yang akan kita implementasikan menggunakan CI/CD Pipeline.

Gambar 2. Workflow CI/CD Pipeline
Penelitian ini menggunakan arsitektur microservices untuk melihat dampak sebuah service yang memiliki sifat single point of failure atau sebuah service yang apabila terjadi kegagalan, kegagalan tersebut akan mengganggu kinerja dari sebuah sistem. Hal tersebut merupakan hal yang fatal pada arsitektur microservices. Microservices merupakan sebuah model arsitektur [6]. Ide utama dari
arsitektur jenis ini adalah memecah sistem yang lebih besar menjadi sistem-sistem yang lebih kecil. Hal ini dapat mengurangi kompleksitas dari sistem [3], membuat sistem yang lebih kecil menjadi lebih independen dan dapat membuat hubungan antar sistem atau service menjadi lebih renggang. Selain itu, sistem yang independen berimplikasi terhadap proses pengembangan dan deploy yang lebih mandiri. Lalu, kelebihan lain yang dimiliki oleh microservices adalah ketika sebuah service mengalami kegagalan, kegagalan tersebut hanya terisolasi dan tidak mengganggu service lain, kecuali service tersebut adalah single point of failure. Gambar 3 merepresentasikan arsitektur yang penulis gunakan pada penelitian ini dengan mengimplementasikan microservices serta menjadikan Authentication Service menjadi sebuah single point of failure.
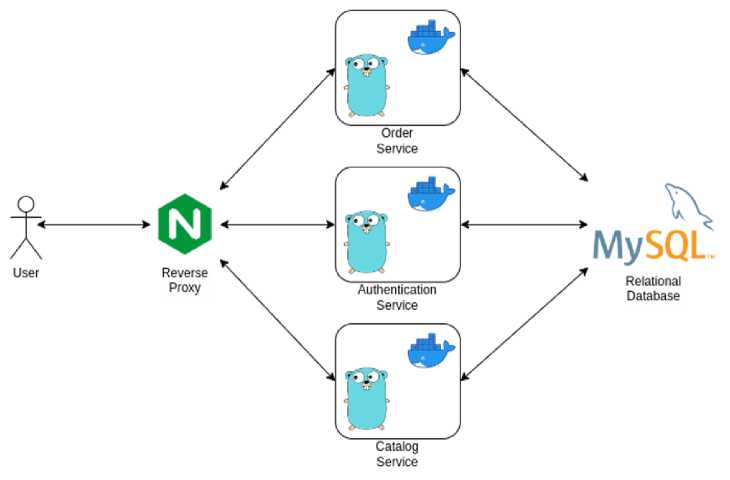
Gambar 3. Arsitektur Microservices
Penelitian ini menggunakan teknologi kontainerisasi untuk melakukan isolasi pada setiap service yang digunakan. Teknologi kontainerisasi memungkinkan kita untuk membuat sebuah virtualisasi pada tingkat aplikasi yang akan berjalan secara konsisten pada setiap infrastruktur. Kontainerisasi juga hanya akan membungkus aplikasi dengan aplikasi yang kita perlukan saja, hal tersebut akan membuat kontainer ini menjadi lebih ringan dan lebih cepat dimulai daripada virtualisasi pada tingkat sistem operasi. Salah satu container engine dan juga yang digunakan pada penelitian ini adalah Docker.
Pengujian yang dilakukan pada penelitian ini menggunakan metode Load-Testing dengan bantuan K6. Metode Load-Testing akan menyimulasikan pengguna yang mengirim request sesuai dengan parameter yang diberikan ke program [7]. K6 merupakan alat bantuan untuk melakukan Load-Testing yang bersifat open-source. Dengan ini kita bisa mengetes performa dan keandalan sistem untuk mencari tahu masalah lebih awal. K6 akan menghasilkan kembalian berupa beberapa metris yang berkaitan tentang request yang telah dikirim. Metris ini akan membantu penulis untuk mengukur data loss yang terjadi pada penelitian ini. Beberapa metris yang digunakan pada penelitian dapat dilihat pada Tabel 1
Tabel 1. Metris Load-Testing
|
Key |
Deskripsi |
|
http_req_failed |
Metris yang merepresentasikan banyaknya data yang berhasil dikirim dan banyaknya data yang gagal dikirim pada HTTP Request |
Berdasarkan alur penelitian yang dijelaskan pada bab sebelumnya. Maka hasil penelitian yang peneliti lakukan dapat dijabarkan sebagai beriku
Pada penelitian ini penulis melakukan identifikasi masalah pada sistem yang menangani pemrosesan Big Data. Dengan mengidentifikasi sifat-sifat yang dimiliki oleh Big Data, seperti volume dan velocity yang dimiliki oleh Big Data serta juga mengidentifikasi perubahan yang terjadi pada industri yang sangat cepat. Penulis mengidentifikasi adanya masalah apabila terdapat perubahan yang diimplementasikan ketika sebuah layanan sedang melakukan pemrosesan data. Ketika mengimplementasikan perubahan pada sebuah layanan, layanan tersebut harus dimatikan terlebih dahulu. Pada layanan yang memproses Big Data, hal tersebut sangat fatal, karena ketika layanan dimatikan, data-data yang dikirimkan dari pengguna layanan akan hilang. Oleh karena itu, penulis memikirkan solusi untuk mempercepat proses pengimplementasian tersebut menggunakan CI/CD pipeline. CI/CD pipeline, akan membantu untuk meningkatkan availibility time dari sebuah layanan ketika dilakukan implementasi dari sebuah perubahan. Oleh karena itu, perubahan yang diimplementasikan akan lebih cepat sampai ke pengguna dengan waktu down time yang sedikit.
Sesuai dengan arsitektur microservices yang sudah penulis jelaskan pada bab sebelumnya, penulis akan melakukan implementasi perubahan terbaru terhadap Authentication Service. Authentication Service pada arsitektur di atas bersifat single point of failure. Oleh karena itu, Authentication Service perlu memiliki down time yang kecil agar layanan ini tidak mengganggu layanan lain bekerja. Untuk itu, penulis mengimplementasikan CI/CD pipeline menggunakan GitHub Actions. Intisari dari implementasi CI/CD pipeline dapat dilihat pada kode di Tabel 2.
Tabel 2. Implementasi CI/CD
|
Kode | |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
name: Deploy Auth Service on: push: tags:
env: DOCKER_IMAGE_REPOSITORY_NAME: snatia-ci-cd DOCKER SERVICE NAME: auth service jobs: build: runs-on: ubuntu-latest steps:
uses: actions/checkout@v2
run: echo "RELEASE VERSION=${GITHUB REF#refs/tags/}" >> $GITHUB ENV
uses: actions/setup-go@v2 with: go-version: 1.18
uses: docker/login-action@v1 with: username: $ password: $
uses: docker/setup-buildx-action@v1
uses: docker/build-push-action@v2 with: |
|
36 37 38 39 |
context: . file: ./auth.Dockerfile push: true tags: $/$:$,$/$:auth-latest |
|
40 41 42 43 44 45 46 47 48 49 50 |
- name: Executing remote command using ssh uses: appleboy/ssh-action@master with: host: $ username: $ password: $ port: 22 script: | cd deploy/ docker compose rm -sf $ docker rmi $/$:auth-latest |
|
51 52 |
docker compose up -d $ name: Deploy Auth Service |
Implementasi dari CI/CD dapat di lihat pada Tabel 2. Penulis akan mengimplementasikan pipeline yang dijelaskan juga pada bab 2.2. Pada baris pertama, penulis memberikan nama terhadap pipeline ini, hanya sebuah metadata. Setelah itu, pada baris ke-3 hingga ke-6, penulis memberitahukan tentang trigger yang perlu didengarkan oleh GitHub Actions. Jadi, ketika trigger atau event tersebut terjadi, workflows ini akan berjalan. Selanjutnya, baris 16 hingga baris 17, penulis melakukan checkout terhadap repository dari GitHub yang terbaru. Baris 18 hingga 19, kita mengambil tag yang akan kita gunakan nantinya. Kemudian, baris ke-20 hingga baris ke-25 hosted runner mempersiapkan lingkungan untuk menjalan bahasa pemrograman Go, kemudian Go akan menjalankan semua test yang ada di project tersebut. Kemudian baris ke-26 hingga baris ke-39, penulis mempersiapkan lingkungan Docker untuk melakukan compile program dan mengirimkannya ke Docker Registry yang akan diambil oleh server nantinya. Lalu, baris ke-40, hingga barus ke-46 berguna untuk mempersiapkan koneksi SSH. Setelah itu, baris ke-47 hingga ke-52 akan melakukan deployment terhadap perubahan yang terbaru.
Pengujian pada penelitian ini dilakukan dengan menggunakan Load-Testing menggunakan K6. K6 menggunakan JavaScript untuk menuliskan test yang akan digunakan. Penggalan kode dari LoadTesting menggunakan K6 sudah penulis lampirkan pada Tabel 3
Tabel 3. Penggalan Kode Load Testing
|
Kode | |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import http from 'k6/http'; export const options = { vus: 20, duration: '45s' } export default function () { const base = { baseUrl: "http://108.136.231.153:8000", auth: "/auth", order: "/order" } const payload = { authPayload: { |
|
17 |
"username": "kompiangg", |
|
18 |
"password": "12345678" |
|
19 |
}, |
|
20 |
orderPayload: { |
|
21 |
"order": [ |
|
22 |
{ |
|
23 |
"item_id": 1, |
|
24 |
"price": 100000, |
|
25 |
"quantity": 2, |
|
26 |
"total_price": 200000 |
|
27 |
} |
|
28 |
] |
|
29 |
} |
|
30 |
} |
|
31 | |
|
32 |
const res = http. post( |
|
33 |
base.baseUrl + base.auth + '/login', |
|
34 |
JSON.stringify(payload.authPayload), { |
|
35 |
headers: {'Content-Type': 'application/json' |
|
36 |
} |
|
37 |
); |
|
38 | |
|
39 |
const accessToken = res.json().data.access_ |
|
40 |
http.post( |
|
41 |
base.baseUrl + base.order + '/orders', |
|
42 |
JSON.stringify(payload.orderPayload), { |
|
43 |
headers: { |
|
44 |
'Content-Type': 'application/json', |
|
45 |
'Authorization': 'Bearer ' + accessToken |
|
46 |
} |
|
47 |
} |
|
48 |
); |
|
49 |
} |
'}
token;
Penggalan kode di atas merupakan Load-Test yang penulis gunakan. Pada baris ke-3 hingga ke-7 dijelaskan parameter yang akan digunakan untuk melakukan Load-Test, yaitu ‘vus’ yang berarti banyaknya user yang akan mengirimkan paket request. Lalu, parameter ‘durations’, yaitu lamanya user akan mengirimkan paket data. Penulis menggunakan 45 detik, karena dari beberapa pengujian, proses yang dihabiskan untuk menjalakan pipeline, yaitu 1 menit dan proses deploy sendiri menghabiskan waktu 30 detik, karena keterbatasan resource yang dimiliki penulis, maka durasi yang digunakan hanya 45 detik. Lalu, di dalam default function terdapat dua buah service yang di-test, yaitu Login dan Order yang berada pada service yang berbeda tapi Order service memiliki ketergantungan terhadap service Login.
running (0m52.1s), 00/20 VUs, 7297 complete and Θ interrupted iterations default ∕ [=================≈] 2θ VUs 45s
data_received..................: 3.4 MB 65 kB/s
data_sent......................: 2.4 MB 46 kB/s
http_req_blocked...............: avg=1.39ms min=Θs med=0s max=l
.Θ3S p(9Θ)=Θs p(95)=Θs http_req_connecting............: avg=1.38ms min=Θs med=0s max=l.Θ3s p(90)=Θs p(95)=Θs
http_req_duration..............: avg=107.77ms min=22.67ms med=32.99ms max=31.55s p(90) =53.71ms p(95)=59.86ms
{ expected_response:true }...: avg=216.07ms min=29.79ms med=46.15ms max=31.55s p(9Θ)=61.38ms p(95)=72.62ms
http_req_failed................: 57.94% √ 5358 X 3888
http_req_receiving.............: avg=137.Θ8μs min=Θs med=0s max=5.2ms p(90)=589.55μs p(95)=973μs
http_req_sending...............: avg=24.15μs min=Θs med=0s max=3ms p(90)=0s p(95)=Θs
http_req_tls_handshaking.......: avg=Θs min=Θs med=0s max=Θs p(90)=0s p(95)=Θs
http_req_waiting...............: avg=107.61ms min=22.67ms med=32.8ms max=31.55s p(90)=53.59ms p(95)=59.71ms
http_reqs......................: 9246 177.608018/s
iteration_duration.............: avg=138.64ms min=22.8ms med=29.84ms max=31.59s p(90) =99.58ms p(95) =112.58ms
iterations.....................: 7297 14θ.l69339∕s
vus............................: 1 min=l max=20
vus_max........................: 20 min=2θ max=2θ
PS E:\SNATIA\snatia-microservices> ∣
Gambar 4. Hasil Load-Testing CI/CD Pipeline
Dalam pengukuran availibility ketika diimplementasikan CI/CD Pipeline pada penelitian ini, dapat kita buatkan sebuah tabel perbandingan data yang berhasil terkirim dan kembali (response) dan yang gagal kembali dalam waktu 45 Detik
Tabel 4. Test Result
|
Key |
Berhasil |
Gagal |
Durasi |
Virtual User |
|
http req failed |
3888 |
5358 |
45 Detik |
20 |
Berdasarkan penelitian dan hasil analisis dari penelitian, dapat dilihat pada tabel 4, bahwa ketika CI/CD Pipeline berjalan ketika masih terdapat data stream yang mengakses server, dalam 45 detik dengan 20 user didapatkan bahwa paket yang masih berhasil kembali sebanyak 3.888 dari 9.246 atau sebesar 42%. Hal ini menunjukkan bahwa CI/CD Pipeline dapat melakukan deployment pada sistem yang dibuat untuk penelitian ini kurang dari 45 detik. Lalu, CI/CD Pipeline dapat memperkecil waktu downtime ketika melakukan deployment daripada metode manual.
Referensi
-
[1] N. Shakhovska, N. Boyko, Y. Zasoba, and E. Benova, “Big data processing technologies in distributed information systems,” Procedia Comput. Sci., vol. 160, no. 2018, pp. 561–566, 2019, doi: 10.1016/j.procs.2019.11.047.
-
[2] P. Muthulakshmi and S. Udhayapriya, “a Survey on Big Data Issues and Challenges,” Int. J. Comput. Sci. Eng., vol. 6, no. 6, pp. 1238–1244, 2018, doi: 10.26438/ijcse/v6i6.12381244.
-
[3] M. Shahin, M. Ali Babar, and L. Zhu, “Continuous Integration, Delivery and Deployment: A Systematic Review on Approaches, Tools, Challenges and Practices,” IEEE Access, vol. 5, no. March, pp. 3909–3943, 2017, doi: 10.1109/ACCESS.2017.2685629.
-
[4] DMR, “Grab Statistics and Facts (2022),” 2022. https://expandedramblings.com/index.php/grab-facts-statistics/.
-
[5] S. Bougerel, “Our Journey to Continuous Delivery at Grab (Part 2),” engineering.grab. com, 2021. https://engineering.grab.com/our-journey-to-continuous-delivery-at-grab-part2.
-
[6] F. Rademacher, S. Sachweh, and A. Zundorf, “Differences between model-driven development
of service-oriented and microservice architecture,” Proc. - 2017 IEEE Int. Conf. Softw. Archit. Work. ICSAW 2017 Side Track Proc., pp. 38–45, 2017, doi: 10.1109/ICSAW.2017.32.
-
[7] H. Schulz, T. Angerstein, and A. Van Hoorn, “Towards automating representative load testing in continuous software engineering,” ICPE 2018 - Companion 2018 ACM/SPEC Int. Conf. Perform. Eng., vol. 2018-January, pp. 123–126, 2018, doi: 10.1145/3185768.3186288.
This page is intentionally left blank.
604
Discussion and feedback