The Sistem Rekomendasi Musik Menggunakan Metode K-Nearest Neighbor
on
Jurnal Elektronik Ilmu Komputer Udayana
Volume 11 No 4, Mei 2023
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Sistem Rekomendasi Musik dengan Menggunakan Metode K-Nearest Neighbor (KNN)
Marcellino Rivaldo Pelaupessya1, I Ketut Gede Suhartanaa2
aProgram Studi Teknik Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana Kampus UNUD Bukit Jimbaran, Bali, Indonesia
1pel4upessy@email.com 2ikg.suhartana@unud.ac.id
Abstrak
Musik adalah hobi yang sudah menjadi kebiasaan sehari – hari kita, dimanapun dan kapanpun kita berada mengakses untuk mendengarkan music melalui aplikasi yang sudah tersesdia di berbagai platform. Dengan itu sangatlah dibutuhkan sistem pemberi rekomendasi music untuk membantu pengguna aplikasi dapat mendengar musik sesuai dengan selera masing masing. Metode K-Nearest Neighbor (KNN) adalah algoritma yang popular digunakan dalam banyak penelitian. Tapi dengan penelitian ini dapat direncanakan akan juga menggunakan String Matching untuk mendapatkan hasil yang lebih optimal lagi.
Keywords: Musik, Sistem Rekomendasi, KNN, String Matching
Musik adalah kumpulan dari suara, irama, tempo, yang akan membuat sebuah rangkaian nada yang terdengar harmonis, pada awal abad pertengahan music diciptakan untuk acara Religi dan hal duniawi menggunakan alat music, dengan perkembangannya jaman music dapat dibuat oleh suara manusia saja, bahkan teknologi yang sudah berkembang.
Dengan adanya teknologi yang berkembang, pada tahun 1877 diciptakan sebuah mesin penyimpan lagu yang terbuat dari aluminium foil dan yang ditusuk oleh jarum yang bernama fonograf, perkembangan semakin pesat hingga membuat aluminium foil berubah menjadi piringan yang biasanya ditaruh ke dalam gramofon, hingga dengan teknologi berkembang lagu dapat bisa disimpan di dalam aplikasi dan tidak perlu repot untuk membuat piringan (Compact Disk)
Teknologi dan Pengguna sedang sangat berkembang pesat, terutama pada bagian Musik yang sudah mempunyai akses yang luas dan gratis dimana saja. Untuk pengguna yang suka mendengarkan music melalui aplikasi yang tersedia, membutuhkan efisiensi untuk mencari music sesuai dengan seleranya dari data yang sangat banyak jumlahnya, jadi dengan system pencarian rekomendasi music dapat membantu pengguna untuk lebih nyaman dengan aplikasinya sesuai dengan selera yang diinginkan
Salah satu rekomendasi metode yang digunakan agar lebih efisien ialah menggunakan algoritma K-Nearest Neighbor (KNN). K-Nearest Neighbor (KNN) merupakan pengelompokan suatu data baru berdasarkan jarak data ke beberapa data. Metode ini dapat menyederhanakan algoritma perhitungan sehingga berpengaruh pada efisiensi waktu [1]. Penulis akan mencoba melakukan penelitian menggunakan metode K-Nearest Neighbor(KNN) guna untuk mendapatkan rekomendasi lagu agar lebih optimal
Sebelum memulai penelitian, dibuat rancangan penelitian sebagai alur untuk memudahkan dalam melakukan penelitian
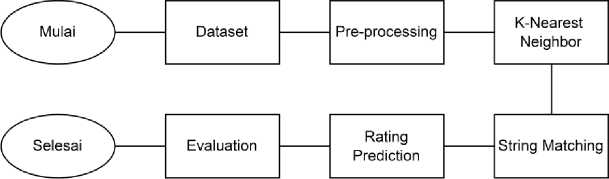
Gambar 1. Flowchart Konsep Sistem
-
2.2. Dataset
Dataset yang digunakan berasal dari website Kaggle, dimana dataset ini berformat file CSV. Dataset ini memiliki 232726 data lagu yang bersumber dari Spotify.
(’A Capella': βj 'Alternative': 1, 'Aπime': 2, 'Country': 3, ’Dance’: 4, 'Electronic': genre artist_name track-naae track_id popularity acousticness d
Mwii c'es, t*au
0 6 i . Cfefaireun OBRjObgaSRKCKjfDqeFgWV 0 0.611
Show
Perdu
-
1 6 “Wi"^ ^^ BsciNtaeoouslysImIlUdP 1 0.244
EImaIehJ
Don't Let
-
2 6 M≡J lm⅛ OCdSC^NIKCfislidsHoTO, 3 O3SS
Tonight
Dis-moi
-
3 6* ^T" m2"⅛,γ 0Gc6TVm52BwZD07Kι6tlwf 0 0.703
Salvador Gordon
Cooper
-
4 6 FabienNataf Ouverture OlusixpMROHdEPvSIirQK 4 0.950
Gambar 2. Dataset Kaggle
-
2.3. K-Nearest Neighbor
K-Nearest Neighbor adalah metode melakukan klasifikasi terhadap suatu object yang akan diklasifikasikan bedasarkan yang paling terdekat dengan object itu, Semua data juga bisa diklasifikasikan, bedasarkan teks, gambar, bahkan audio atau suara.
Rumus :
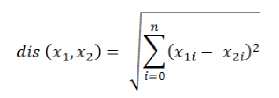
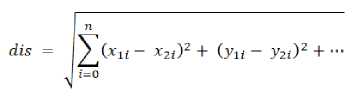
Gambar 3. KNN 1-dimension, KNN Euclidean distance
-
2.4. String Matching
String Matching adalah suatu algoritma pencocokan string pattern yang dibagi menjadi tiga yaitu Brute Force, Knuth-Morris-Pratt, dan Boyer-Moore, dan membandingkannya
|
Jurnal Elektronik Ilmu Komputer Udayana Volume 11 No 4, Mei 2023 |
p-ISSN: 2301-5373 e-ISSN: 2654-5101 |
menggunakan Regular Expression. Hasil dari pencarian string tergantung dari teknik pencocokannya. [2]
Dataset yang sudah ada akan di-label untuk memudahkan kita pada nantinya memperhitungkan menggunakan K-Nearest Neighbor, karena pada nantinya data akan dibuat dalam bentuk matrix
{,0002IWyfeAyMbLPltqij86e': 0, ’00ΘCzNKCBPEtlyCBL8dqwV': 1, '000xQL6t2NLJzIrt⅛xqSl, : 2,
|
genre |
artist_name |
trackname |
track-id |
popularity |
acousticness |
danceability du | |
|
0 |
6 |
Henri Salvador |
Cest beau de fare un Show |
817 |
0 |
0.611 |
0 389 |
|
1 |
6 |
Martin & Ies fees |
Perdu davance (par Gad Elmaleh) |
832 |
I |
0.246 |
0.590 |
|
2 |
6 |
Joseph Williams |
Don't Let Me Be Lonely Tnnirjhr |
918 |
3 |
0.952 |
0.663 |
|
3 |
6 |
Henri Salvador |
Dis-moi Monsieur Gordon Cooper |
1206 |
0 |
0.703 |
0.240 |
dfuser = df.pivot(iπdex="genre", c□lumns="trackid",values="popularity”).fillπa(0) df-user.head()
track-id βl 2 3 4 5 6 7 8 9... 35683 35684 35685
genre 0 0.0 0.0 00 00 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0 49.0 0.0 0.0 0.0 0.0 55.0 ... 0.0 46.0 54.0
2 1 3 0 0 0 0 0 0.0 0.0 0.0 0.0 33 0 0 0 0.0 ... 0.0 0.0 0.0
3 0.0 0.0 00 00 0.0 0.0 0.0 0.0 0.0 0.0 ... 36.0 0.0 0.0
4 0.0 0.0 700 570 0.0 66.0 0.0 0.0 68.0 0.0 ... 0.0 0.0 0.0
5 rows * 35693 columns
-
Gambar 4. Pre-processing
Pada penelitian ini, implementasi penggunaan K-Nearest Neighbor dilakukan menggunakan algoritma bruteforce yang dimana mengambil sample matriks yang distancenya paling kecil
Penggunaan string matching pada penelitian kali ini ialah untuk mencari suatu pola yang satu dengan yang lain sehingga memudahkan kita menggunakan pendekatan melalui teks. String matching lebih tertuju pada satu pencarian atau lebih, semua kehadiran sebuah kata (lebih umum disebut pattern) dalam sebuah teks
Pengukuran kinerja sistem yang telah dibangun sangat penting karena merupakan bentuk evaluasi kinerja algoritma yang telah dipilih, bagi peneliti yang ingin meningkatkan algoritma pembelajaran mesin pada domain masalah yang berbeda dan membandingkan hasil pengujian dengan yang lain untuk memahami metrik kinerja dan memilih kinerja yang paling tepat dari beberapa kemungkinan
Pada tahap ini akan dilakukan penghitungan system rekomendasi music dengan menggunakan sebuah nama track input yang akan dibandingkan dengan 4 track judul lagu rekomendasi dari
output dengan mengambil contoh judul lagu “Dis-moi Monsieur Gordon Cooper” yang akan dijadikan sebagai input, langkah ini bertujuan untuk mengetahui akurasi dari data tersebut [3]
Q retQmender{'Dis-moi Monsieur Gordon Cooper' ,mat-Husicj5)
Q Select the Movie : Dis-moi Monsieur Gordon Cooper Index : 3 Searching Recommendation for You...
-
3 NaN
22 Monsieur Boum Boum
24 Quand je monte chez toi
11 The Hanging (Maverick - Original Motion Pictur...
14 Keys of Love
Name: track-name, dtype: object
Gambar 5. Hasil Evaluasi
Dengan Hasil kita dapatkan melalui system yang kita buat, maka hasil close distance yang kita peroleh dari 4 judul yaitu
|
Track Lagu |
Close Distance |
|
Monsieur Boum Boum |
0.89 |
|
Quand je monte chez toi |
0.92 |
|
The Hanging (Maverick -Original Motion Pictures) |
0.93 |
|
Keys of Love |
0.95 |
Tabel 1. Hasil Close Distance
Dari hasil perhitungan yang sudah diperhitungkan menggunakan sistem, maka tingakat akurasi akan diperhitungkan secara normal, akurasi nilai yang sesuai dengan sebelumnya dibagi dengan jumlah data latih kemudian dikali dengan 100, maka keakurasian sistem yang dibuat adalah
3.69
—— × 100 = %92.25
4
Berdasarkan hasil penelitian yang diperoleh dari menggunakan metode K-Nearest Neighbor pada dataset playlist dari aplikasi Spotify berjumlah 232726 track lagu dengan close distance dapat menjadi metode sistem rekomendasi yang baik bagi pengguna karena yang direkomendasikan sebagian besar serupa dengan item yang menjadi input.
References
-
[1] R Yessivirna, Marji, D E Ratnawati. “Klasifikasi Suara Bedasarkan Gender
(Jenis Kelamin) dengan Metode K-Nearest Neighbor (KNN)” 3-4.
-
[2] Ernawati, A Johar, S Setiawan, “Implementasi Metode String Matching untuk Pencarian Portal
Berita Berbasis Android (Studi Kasus : Harian Rakyat Bengkulu)”
-
[3] F Shidiq, E W Hidayat, N I Kurniati, “Penerapan Metode K-Nearest Neighbor (KNN) Untuk
Menentukan Ikan Cupang Dengan Ekstraksi Fitur Ciri Bentuk Dan Canny”
680
Discussion and feedback