Klasifikasi Musik Berdasarkan Genre dengan Metode eXtreme Gradient Boosting
on
Jurnal Elektronik Ilmu Komputer Udayana
Volume 12, No 1. August 2023
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Klasifikasi Musik Berdasarkan Genre dengan Metode Extreme Gradient Boosting
Muhammad Luqman Aristioa1, I Ketut Gede Suhartanaa2
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam,Universitas Udayana Kampus Unud Bukit Jimbaran, Bali, Indonesia
Abstrak
Perkembangan musik diseluruh dunia saat ini menyebabkan peningkatan jumlah musik yang ada dibandingkan dengan era sebelumnya. Hal tersebut menimbulkan dampak baru yakni sulitnya dalam pengidentifikasian genre musik secara manual. Dengan memanfaatkan teknologi yang sudah berkembang saat ini, klasifikasi genre musik dapat dilakukan secara otomatis dengan memanfaatkan fitur-fitur yang dimilikinya. Penelitian ini akan melakukan klasifikasi genre musik dengan menggunakan metode eXtreme Gradient boosting (XGBoost) dengan hyperparameter tuning Grid Search. Terdapat 10 label dan 28 fitur yang akan digunakan dalam penelitian ini yakni tempo, beats, chroma, RMSE, spectral centroid, bandwidth, rolloff, zero crossing rate dan mfcc 1 sampai 20. Dari semua fitur tersebut, pada tahap pengujian dilakukan tahapan reduksi dimensi fitur dengan teknik Principal Component Analysis (PCA). PCA akan menggabungkan beberapa fitur yang berkolerasi tinggi sehingga dapat meningkatkan kecepatan pengklasifikasian. Dari hasil evaluasi menghasilkan nilai validasi akurasi sebesar 67%. Dari hasil evaluasi tersebut menunjukan bahwa metode XGBoost dapat melakukan klasifikasi musik berdasarkan genre walaupun memiliki akurasi cukup rendah.
Kata kunci: Klasifikasi Musik, eXtreme Gradient Boosting, Genre Musik, Grid Search
Musik adalah karya cipta berupa bunyi atau suara yang memiliki nada, irama dan keselarasan. Saat ini diseluruh dunia jumlah musik yang berkembang mungkin sudah tidak terhitung jumlahnya, namun setiap musik pasti akan memiliki kemiripan. Kemiripan tersebut biasanya berasal dari ritme, frekuensi dan latar belakang musik tersebut [1]. Kemiripan inilah yang disebut dengan genre musik. Genre musik merupakan hal yang penting untuk diketahui dikarenakan melalui genre inilah para pendengar atau penikmat musik dapat mencari jenis musik yang sesuai keinginan mereka dalam suatu basis data musik yang besar. Oleh karena itu dibutuhkan teknologi atau sistem yang dapat memberikan label genre secara otomatis sehingga dapat memudahkan pengguna dari segi waktu dan usaha.
Pada penelitian [2] sebelumnya, klasifikasi genre musik dilakukan dengan menggunakan metode K-Nearest Neighbor dengan 10 label dan 11 fitur. Pada penelitan tersebut akurasi rata-rata cukup rendah yakni sebesar 44,8% dikarenakan perbedaan akurasi antar label yang cukup besar. Perbedaan tersebut diakibatkan karena terdapat fitur yang tidak dapat merepresentasikan genre musiknya sehingga mengakibatkan model tidak dapat memprediksi dengan baik. Oleh karena itu pemilihan fitur yang akan digunakan harus lebih diperhatikan lagi untuk meningkatkan akurasi model. Kemudian pada penelitian [3], digunakan model Hidden Markov yang berbasis peluang dan probabilitas yang menghasilkan akurasi 80%. Akurasi yang diperoleh cukup tinggi dikarenakan model Hidden Markov merupakan algoritma yang sangat kompleks dan lama namun algoritma ini merupakan teknik dasar untuk automatic speech recognition dan part-of-speech tagging.
Pada penelitian ini, penulis akan melakukan klasifikasi genre musik menggunakan metode eXtreme Gradient boosting dengan hyperparameter tuning Grid Search dengan fitur yang berbeda dan lebih
banyak dibandingkan penelitian sebelumnya. Metode XGBoost merupakan jenis algoritma yang dapat digunakan untuk klasifikasi maupun regresi yang cukup powerful. Pada dasarnya, algoritma ini sama dengan algoritma gradient boost hanya saja menggunakan beberapa proses tambahan.
Dataset yang digunakan dalam penelitian ini merupakan data sekunder yang diperoleh dari GTZAN -Music Genre Classification Data Set berjumlah 1000 sampel dengan 10 label genre yakni Blues, Classical, Country, Disco, Hiphop, Jazz, Metal, Pop, Reggae dan Rock. Setiap label memiliki jumlah sampel yang sama yakni 100 sampel. File berfomat .csv yang berisi hasil preprocessing berbagai fitur pada data musik GTZAN yang berdurasi 30 detik. Sehingga pada tahapan klasifikasi nanti tidak akan dilakukan preprocessing data lagi. Jumlah fitur awal dataset adalah 30 diantaranya yakni filename, tempo, beats, chroma, RMSE, spectral centroid, bandwidth, rolloff, zero crossing rate, mfcc yang berjumlah 20 dan label. Pada fitur filename tidak akan digunakan karena merupakan fitur yang berisi nama file yang tidak relevan. Sehingga tersisa 29 fitur saja, seluruh fitur selain label merupakan fitur numerik yang berupa angka negatif dan positif. Dataset akan dibagi menjadi 80% data training dan 20% data testing.

Gambar 1. Flowchart Desain Klasifikasi
Gambar 1 merupakan flowchart desain penelitian. Pertama data penelitian akan dimasukan kedalam model yang akan dikembangkan. Kemudian data tersebut akan dibagi menjadi 80% data training dan 20% data testing. Pada tahapan ini juga fitur dan label dipisahkan dari dataset dan kemudian masuk ke tahapan pengembangan model. Pertama akan dilakukan hyperparameter tuning dengan teknik grid search. Dengan teknik ini, model dapat menggunakan berbagai kombinasi hyperparameter dengan range yang sudah ditentukan dan kemudian memilih kombinasi terbaik dari range tersebut.
Setelah mengatur hyperparameter, selanjutnya masuk ke tahapan pelatihan dan klasifikasi model dengan XGBoost Classifier. Setelah pelatihan model selesai, akan ditampilkan parameter terbaik pada tahapan grid search kemudian hasil akurasinya. Berikut yakni tahapan evaluasi model, pada evaluasi ini akan menggunakan matriks konfusi dengan melihat nilai presisi, recall dan f1-score.
Pada penelitian ini, klasifikasi genre musik akan dilakukan menggunakan metode XGBoost dengan hyperparameter tuning Grid Search. XGBoost merupakan algoritma machine learning yang dapat digunakan untuk kasus klasifikasi maupun regresi [4]. XGBoost adalah algoritma yang ditingkatkan berdasarkan gradient boosting decision tree dan dapat membangun boosted trees secara efisien dan beroperasi secara paralel [5]. Pada dasarnya, algoritma ini sama dengan algoritma gradient boost hanya saja menggunakan beberapa proses tambahan sehingga lebih powerful.
Dalam algoritma ini, pohon keputusan dibuat dalam bentuk sekuensial. Bobot memainkan peran penting dalam XGBoost. Bobot diberikan ke semua variabel independen yang kemudian dimasukkan ke dalam pohon keputusan yang memprediksi hasil. Bobot variabel yang diprediksi salah oleh pohon dinaikkan dan variabel-variabel ini kemudian diumpankan ke pohon keputusan kedua. Skor prediksi masing-masing pohon keputusan kemudian dijumlahkan. Secara matematis, dapat dijabarkan pada persamaan (1).
9i = ∑k=ιfk(x∂>fkεF (1)
Kemudian terdapat fungsi objektif dari XGBoost yakni fungsi loss dan regularisasi pada iterasi t yang harus diminimalkan pada persamaan (2).
!tt>= ∑f=ιi(yiyt-1)+ft(.χi)) + ∩(ft) (2)
Pada algoritma machine learning, biasanya terdapat beberapa nilai parameter yang diperkirakan dapat meningkatkan kinerja model yang disebut hyperparameter. Hyperparameter digunakan untuk meningkatkan hasil kinerja algoritma, yang mana cukup mempengaruhi berbagai uji model. Hyperparameter dilakukan secara fisik atau dengan menguji sekelompok hyperparameter pada batas yang telah ditentukan. Pencarian hyperparameter dilakukan secara manual atau dengan menguji kumpulan hyperparameter pada parameter yang ditentukan sebelumnya. Pada XGBoost, terdapat 7 parameter yang digunakan yang dapat dilihat pada Tabel 1.
Membantu mempersingkat langkah dalam pembaruan model
Table 1. Parameter XGBoost
|
Parameter |
Rentang Nilai |
|
max_depth |
Tingkat kedalaman pohon |
|
n_estimators |
Banyaknya pohon yang digunakan untuk proses klasifikasi |
learning_rate
random_state
menghasilkan angka acak yang diambil dari berbagai distribusi probabilitas
Selanjutnya yakni menentukan nilai pada parameter tersebut, terdapat proses tuning hyperparameter dengan teknik Grid Search dengan nilai seperti pada Tabel 2.
Table 2. Hyperparameter Tuning
|
Parameter |
Rentang Nilai |
|
max_depth n_estimators learning_rate random_state |
2 – 10, interval 1 60 – 220, interval 40 0,1 0 |
Keuntungan dari menggunakan Grid Search adalah nilai hyperparameter dapat dibuatkan range beserta interval kemudian setiap nilai akan dilakukan kombinasi dan hanya hyperparameter terbaik yang akan digunakan pada model akhir nanti.
-
2.4 Principal Component Analysis (PCA)
Pada pengujian penelitian ini, akan dilakukan teknik reduksi dimensi yakni Principal Component
Analysis (PCA). Teknik ini bertujuan untuk mereduksi dimensi, mengekstraksi fitur, dan
mentransformasi data dari “n-dimensional space” ke dalam sistem berkoordinat baru dengan dimensi m, di mana m lebih kecil dari n. PCA bekerja menggunakan metode aljabar linier. Ia mengasumsikan bahwa sekumpulan data pada arah dengan varians terbesar merupakan yang paling penting (utama). PCA umumnya digunakan ketika variabel dalam data memiliki korelasi yang tinggi. Korelasi tinggi ini menunjukkan data yang berulang atau redundant.
Evaluasi dilakukan dengan matriks konfusi dengan menghitung akurasi, recall, presisi dan f1-score. Matriks konfusi dapat digunakan untuk mengevaluasi kualitas classifier [6]. Pada confusion matrix dua
kelas, matriks menunjukkan true positives, true negatives, false positives, dan false negatives. Matriks konfusi untuk 2 kelas ditunjukan pada Tabel 2.
Table 3. Matriks Konfusi
|
Kelas Sebenarnya |
Prediksi Kelas | |
|
Positif |
Negatif | |
|
Positif |
TP |
FN |
|
Negatif |
FP |
TN |
Keterangan :
TP = True Positive (total prediksi benar dari data positif)
FN = False Negative (total prediksi salah dari data positif)
TN = True Negative (total prediksi benar dari data negatif)
FP = False Positive (total prediksi salah dari data negatif)
Berikut persamaan untuk menghitung akurasi, presisi, recall dan f1-score [7] :
|
TP+FP Akurasi =----------- (3) TP+FP+TN+FN ' ' „ . . TP Presisi =----- (4) TP+FP ' ' n TP Recall = (5) TP+FN ' ' „ 2 × recall ×presisi F1 Score = (6) recall+presisi |
Pada penelitian ini dilakukan penerapan metode Extreme Gradient Boosting pada pengklasifikasian musik berdasarkan genre. Dataset diperoleh dari GTZAN - Music Genre Classification Data Set berjumlah 1000 sampel dengan 10 label genre. Dalam pengujian kali ini terdapat 2 jenis percobaan yang dilakukan yakni dengan metode XGBoost yang dilakukan reduksi dimensi dengan PCA dan XGBoost tanpa dilakukan reduksi dimensi. Selain itu juga, kedua pengujian tersebut akan dilakukan dengan menggunakan hyperparameter tuning dan tanpa hyperparameter tuning. Kemudian digunakan juga K-Fold Cross Validation untuk proses validasi dan pelatihan, dengan k = 5
Pada pengujian ini, dilakukan pelatihan model dengan metode XGBoost tanpa menggunakan PCA untuk mereduksi dimensi dari fitur yang ada pada dataset. Oleh karena itu seluruh fitur pada dataset digunakan secara langsung dalam pelatihan. Dataset dibagi menjadi 80% data training dan 20% data testing untuk memvalidasi hasil prediksi. Pengujian ini akan dicoba menggunakan hyperparameter tuning dan tanpa hyperparameter tuning untuk melihat hasil terbaik.
Table 4. Hasil Evaluasi Model dengan Hyperparameter Tuning Grid Search
|
Label |
Presisi |
Recall |
F1-Score |
|
blues |
57% |
72% |
63% |
|
classical |
91% |
91% |
91% |
|
country |
56% |
48% |
51% |
|
disco |
47% |
58% |
52% |
|
hiphop |
57% |
54% |
55% |
|
jazz |
71% |
56% |
63% |
|
metal |
89% |
83% |
86% |
|
pop |
76% |
81% |
79% |
|
reggae |
68% |
65% |
67% |
|
rock |
43% |
47% |
45% |
|
Rata-rata |
65,5% |
65,5% |
65,2% |
Bisa dilihat pada Tabel 4. Untuk hasil evaluasi dari model dengan hyperparameter tuning memperoleh akurasi sebesar 67% dengan nilai presisi, recall dan F1-Score 65%. Adapun parameter terbaik dari hasil tuning tersebut bisa dilihat pada Tabel 5.
Tabel 5. Nilai Parameter Terbaik
|
Learning Rate |
Max Depth |
N_estimators |
N_jobs |
Random_state |
|
0.1 |
4 |
180 |
-1 |
0 |
Berikutnya akan dilakukan pengujian model XGBoost tanpa dilakukan hyperparameter tuning dengan grid search. Hasilnya bisa dilihat pada Tabel 6.
Table 6. Hasil Evaluasi Model tanpa Hyperparameter Tuning Grid Search
|
Label |
Presisi |
Recall |
F1-Score |
|
blues |
67% |
67% |
67% |
|
classical |
96% |
92% |
94% |
|
country |
50% |
53% |
52% |
|
disco |
64% |
62% |
63% |
|
hiphop |
54% |
68% |
60% |
|
jazz |
56% |
88% |
68% |
|
metal |
93% |
67% |
78% |
|
pop |
71% |
65% |
68% |
|
reggae |
61% |
50% |
55% |
|
rock |
38% |
36% |
37% |
|
Rata-rata |
65% |
64,8% |
64,2% |
Dari hasil tersebut diperoleh akurasi keseluruhan sebesar 66% dengan nilai presisi 65%, recall 64,8% dan F1-Score 64,2%. Akurasi yang dihasilkan jika dibandingkan dengan yang menggunakan hyperparemeter tuning tidak jauh berbeda. Hal ini menunjukan bahwa perubahan parameter dalam model tersebut tidak memberikan dampak yang signifikan pada hasil. Berikut perbandingan hasil evaluasi kedua pengujian yang ditunjukan pada Gambar 3.
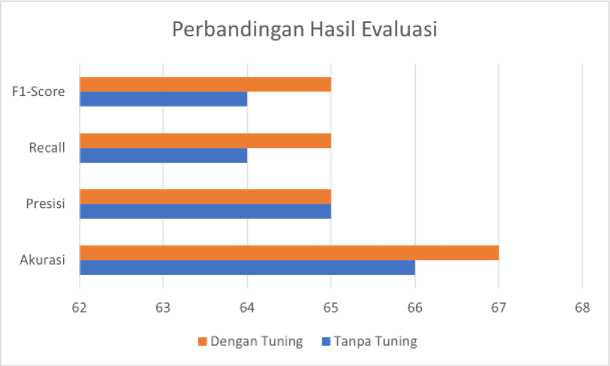
Gambar 2. Perbandingan Hasil
Pada pengujian ini dilakukan teknik reduksi dimensi fitur dengan memanfaatkan teknik PCA. Teknik PCA akan menggabungkan beberapa nilai fitur jika memiliki korelasi yang tinggi. Oleh karena itu untuk melihat korelasi digunakan heatmap fitur. Hasil heatmap ditunjukan pada Gambar 3.
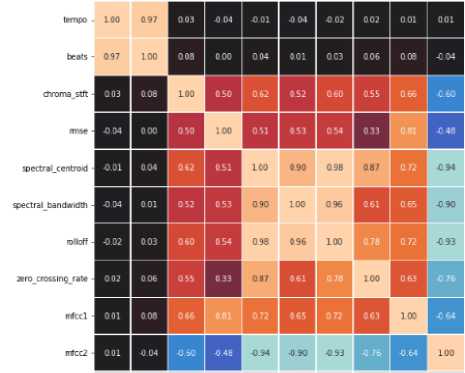
Gambar 3. Heatmap Korelasi Fitur
Pada gambar 2, bisa dilihat terdapat beberapa fitur yang memiliki korelasi sangat tinggi mencapai 0.9. Fitur-fitur tersebut diantaranya tempo dengan beats mencapai 0.97 kemudian spectral centroid, spectral bandwith, rolloff, dan mfcc2. Dari hasil tersebut kita dapat melakukan reduksi dimensi dengan PCA untuk menggabungkan fitur-fitur tersebut menjadi 1 fitur yang relevan. Sehingga jumlah fitur yang digunakan pada pengujian ini berjumlah 25. Setelah reduksi dimensi tersebut, berikutnya dilakuka pelatihan model berdasarkan 25 fitur tersebut. Berikutnya akan dilakukan pengujian dengan menggunakan hyperparameter tuning terlebih dahulu. Hasilnya ditunjukan pada Tabel 7.
Table 7. Hasil Evaluasi Model dengan Hyperparameter Tuning Grid Search
|
Label |
Presisi |
Recall |
F1-Score |
|
blues |
60% |
41% |
49% |
|
classical |
100% |
82% |
90% |
|
country |
46% |
61% |
52% |
|
disco |
62% |
42% |
50% |
|
hiphop |
58% |
70% |
64% |
|
jazz |
50% |
67% |
57% |
|
metal |
83% |
93% |
88% |
|
pop |
75% |
94% |
83% |
|
reggae |
53% |
48% |
50% |
|
rock |
33% |
30% |
32% |
|
Rata-rata |
62% |
62,8% |
61,5% |
Bisa dilihat pada Tabel 7. Untuk hasil evaluasi dari model dengan hyperparameter tuning memperoleh akurasi sebesar 62% dengan nilai presisi 62%, recal 62% dan F1-Score 61%. Adapun parameter terbaik dari hasil tuning tersebut bisa dilihat pada Tabel 8.
Tabel 8. Nilai Parameter Terbaik
|
Learning Rate |
Max Depth |
N_estimators |
N_jobs |
Random_state |
|
0.1 |
2 |
180 |
-1 |
0 |
Berikutnya akan dilakukan pengujian model XGBoost dengan PCA tanpa hyperparameter tuning dengan grid search. Hasilnya bisa dilihat pada Tabel 9.
Table 9. Hasil Evaluasi Model tanpa Hyperparameter Tuning Grid Search
|
Label |
Presisi |
Recall |
F1-Score |
|
blues |
75% |
60% |
67% |
|
classical |
100% |
74% |
85% |
|
country |
45% |
74% |
56% |
|
disco |
62% |
62% |
62% |
|
hiphop |
71% |
52% |
60% |
|
jazz |
69% |
69% |
69% |
|
metal |
87% |
83% |
85% |
|
pop |
77% |
85% |
81% |
|
reggae |
56% |
43% |
49% |
|
rock |
18% |
27% |
22% |
|
Rata-rata |
66% |
62,9% |
63,6% |
Dari hasil tersebut diperoleh akurasi keseluruhan sebesar 63% dengan nilai presisi 66%, recall 62,9% dan F1-Score 63,6%. Akurasi yang dihasilkan jika dibandingkan dengan yang menggunakan
hyperparemeter tuning tidak jauh berbeda juga. Berikut perbandingan hasil evaluasi kedua pengujian yang ditunjukan pada Gambar 4.
Perbandingan Hasil Evaluasi
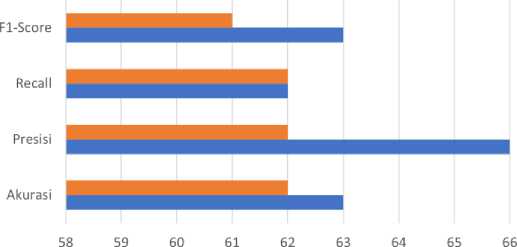
BDenganTuning BTanpaTuning
Gambar 4. Perbandingan Hasil
Dari hasil penelitian ini dapat disimpulkan bahwa klasifikasi genre musik menggunakan metode XGBoost dengan hyperparameter tuning Grid Search tanpa menerapkan PCA memperoleh akurasi tertinggi sebesar 67%. Selain itu juga diperoleh nilai parameter yang digunakan pada model terbaik berdasarkan Grid Search yang ditunjukan pada Tabel 10.
Table 10. Nilai Hyperparameter Model Terbaik
|
Learning Rate |
Max Depth |
N_estimators |
N_jobs |
Random_state |
|
0.1 |
4 |
180 |
-1 |
0 |
Hasil ini diperoleh dengan menggunakan seluruh fitur pada 10 label genre yang ada yakni tempo, beats, chroma, RMSE, spectral centroid, bandwidth, rolloff, zero crossing rate dan mfcc 1 sampai 20 tanpa melakukan reduksi dimensi. Dari model tersebut diperoleh beberapa nilai dari hasil evaluasi yakni nilai akurasi 67%, presisi 65,5%, recall 65,5% dan F1-Score 65,2%. Nilai evaluasi masih tergolong rendah, hal tersebut dikarenakan terdapat fitur-fitur yang tidak dapat merepresentasikan genre musik dengan baik seperti nilai MFCC yang berjumlah 20.
Pada penelitian selanjutnya diharapkan model yang dikembangkan menggunakan metode klasifikasi lainnya yang lebih sesuai seperti dengan memanfaatkan jaringan syaraf tiruan atau neural network. Selain itu juga sangat penting untuk melakukan reduksi dimensi fitur khususnya fitur MFCC dengan teknik lain seperti Linear Discriminant Analysis (LDA) yang lebih sesuai sehingga fitur yang digunakan dapat menghasilkan model yang lebih baik lagi.
Referensi
-
[1] D. Lionel, R. Adipranata dan E. Setyati, "Klasifikasi Genre Musik Menggunakan Metode Deep
Learning Convolutional Neural Network dan Mel-Spektogram" Jurnal Infra, vol. 7, no. 1, 2019.
-
[2] G. Ayu Vida Mastrika Giri, " Klasifikasi Musik Berdasarkan Genre dengan Metode K-Nearest
Neighbor" Jurnal Ilmu Komputer, vol. XI, no. 2, p. 103-108, 2017.
-
[3] R. Rahmawati, R. Magdalena dan I. N. A. Ramatryana, "Perbandingan dan Analisis K- Nearest
Neighbor dan Linear Discriminant Analysis Untuk Klasifikasi Genre Musik" eProceedings of Engineering, vol. 3, no. 2, p. 1831-1837, 2016.
-
[4] S. Ramaneswaran, K. Srinivasan dan P. M. Durai Raj Ramatryana, "Hybrid Inception v3 XGBoost Model for Acute Lymphoblastic Leukemia Classification" Hindawi, p. 1-10, 2021
-
[5] T. Chen dan C. Guestrin, XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. KDD '16. New York, NY, USA: ACM, pp. 785–794.
-
[6] M. Audina et al, "Klasifikasi Berita Hoaks Covid-19 Menggunakan Kombinasi Metode K-Nearest Neighbor dan Information Gain" Jurnal Elektronik Ilmu Komputer Udayana, vol. 10, no. 4, p. 319328, 2022.
-
[7] S. Narkhede, "Toward Data Science”, 9 Mei 2018. [Online]. Available: https://towardsdatascience.com/understanding-confusion-matrix-a9ad42dcfd62. [2 Oktober 2022]
Halaman ini sengaja dibiarkan kosong
122
Discussion and feedback