Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan Perbandingan Seleksi Fitur
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana
Volume 11, No 1. August 2022
Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan Perbandingan Seleksi Fitur
Farin Istighfarizkya1, Ngurah Agus Sanjaya ERa2, I Made Widiarthaa3, Luh Gede Astutia4, I Gusti Ngurah Anom Cahyadi Putraa5, I Ketut Gede Suhartanaa6
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana Bali, Indonesia
1farin79.istighfarizky@gmail.com 2agus_sanjaya@unud.ac.id 3madewidiartha@unud.ac.id 4 lg.astuti@unud.ac.id 5 anom.cp@unud.ac.id 6ikg.suhartana@unud.ac.id
Abstract
Classification is a process that automatically places text documents into a text based on the content of the text. Classification can help us classifying many text documents that have been published, with the classification, these text documents can be reached easily and quickly. Feature selection can be used to improve the performance of text classification in terms of learning speed and effectiveness. In the Chi-Square feature selection experiment, a 1% threshold combination with a parameter value of k=6 is the combination chosen to be the best model. In testing the new data, the K-Nearest Neighbor model by selecting the Chi-Square feature produces precision performance, recall, F1-Score, and accuracy respectively, namely 85%, 83.3%, 88.2%, and 92.3%. In the Gini Index feature selection experiment,1% threshold combination with a parameter value of k=4 is the combination chosen to be the best model. This threshold selects about 31 features with the highest Gini Index value. In testi ng the new data, the K-Nearest Neighbor model by selecting the Gini Index feature produces precision performance, recall, F1-Score, and accuracy respectively, namely 81.2%, 80.3%, 81.6%, and 86.6%.
Keywords: Classification, Chi-Square, Gini Index, Features Selection, K-Nearest Neighbor
-
1. Pendahuluan
Penemuan dibidang informatika mengalami perkembangan yang sangat pesat. Ratusan penelitian dilakukan di berbagai bidang disetiap tahunnya yang mana dengan harapan hasil penelitian tersebut dapat digunakan untuk penemuan berikutnya. Tidak semua penemuan akan relevan terhadap penelitian yang dilakukan oleh seseorang, oleh karena itu diperlukannya pengelompokan penelitian agar lebih mudah dalam mencari penelitian yang kita inginkan atau butuhkan. Jumlah studi yang dipublikasikan ada ratusan bahkan ribuan penelitian setiap tahunnya, seseorang akan membutuhkan terlalu banyak usaha dan dana yang besar dalam mengelompokkan jurnal-jurnal penelitian. Masalah ini dapat diselesaikan dengan klasifikasioteks.
Klasifikasi adalahoproses menempatkanoodokumenoteksosecaraoootomatisokeodalamokategori berdasarkan teks [1]. Klasifikasi membantu mengklasifikasikan jumlah dokumen teks yang diterbitkan. Klasifikasi membuatnya cepat dan mudah untuk mengelompokkan dokumen tekstual. Dasar dari algoritma seleksi fitur adalah untuk menemukan semuaokemungkinanokombinasioatributodalam data. Ini digunakan untuk menemukan subset terbaik untukprediksi. Pemilihan fitur dapat digunakanountuk meningkatkan kinerja klasifikasi teks dalam hal kecepatan dan efektivitas pembelajaran [2].
Studi klasifikasi telah dilakukan oleh beberapa peneliti, seperti tentang mengkategorikan soal ujian secara otomatis. Pada penelitian tersebut, penulis menggunakan metode KNN dengan seleksi fitur Chi-Square. oHasil pada penelitian tersebut menunjukkan bahwa metode seleksi fitur Chi-Square terbukti mampu meningkatkan performa dari metode KNN [3]. Penelitian selanjutnya adalah
Istighfarizky, dkk
Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan Perbandingan Seleksi Fitur membahas tentang kognitif soalopadaotaksonomi bloom denganoKNN. Hasil yang didapatkan dari algoritma KNN dengan seleksi fitur Gini Index pada penelitian tersebut adalah akurasi sebesar 68,37% dan kappa tertinggi sebesar 0,607. Berdasarkanohasil tersebut, GinioIndex mampu mengurangi dimensi fitur yang tinggi [4].
Seleksi fitur Chi Square menggunakan teori statistik untuk menentukan independensi suatu term dari kategorinya. Dalam seleksi fitur Chi Squareoberdasarkanoteori statistika, duaoperistiwa dioantaranya adalahokemunculan dari fiturodan kemunculan dari kategori yang kemudian nilai termodiurutkan dari yangotertinggi. Sedangkanoseleksi fitur Gini Indexomampu mengurangiodimensi fitur yang tinggi pada klasifikasi teks. o
Berdasarkan penelitian yang dilakukan sebelumnya, pada penelitian kali ini penulis melakukan klasifikasi jurnal menggunakan metode K-Nearest Neighbor dengan menggunakan dua seleksi fitur yaitu Chi-Square dan Gini Index. Penulis berharap bahwa dengan menggunakan kombinasi metode ini dapat menghasilkan performa precision, recall, f1-score, dan akurasi yang lebih baik dibandingkan penelitian sebelumnya.
-
2. Metode Penelitian
-
2.2. Dataset
-
Data yang digunakanopadaopenelitianoini adalah jurnal yang dipublikasikan oleh SINTA (Science and Technology Index) dan Google Scholar, data dapat diperoleh dari website SINTA (Science and Technology) (https://sinta.ristekbrin.go.id/) dan Google Scholar (https://scholar.google.com) Kemudian data yang digunakan untuk proses klasifikasi adalah pada bagian teks abstrak jurnal yang berbahasa Indonesia yang disimpan dalam bentuk (.xlsx) untuk digunakan sebagai data latih dan data uji. Dokumen yang digunakan berjumlah 100 data per kelas disetiap artikel ilmiah yaitu: pendidikan, ekonomi, dan informatika. Data testing yang diuji sebanyak 60 data jurnal dan data training sebanyak 240 data jurnal. Data pada penelitian ini adalah data sekunder.
Preprocessing proses pertama mempersiapkan dataset sebelum pembobotan, tujuannya adalah untuk menyederhanakan pemrosesan data dan juga untuk mendapatkan tingkat performa yang tinggi. Proses preprocessing dapat dilihat pada gambar 1.
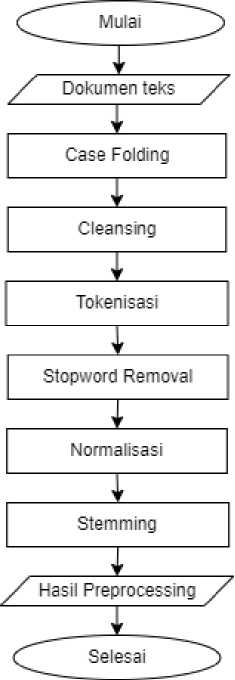
Gambar 1. Proses preprocessing
Padaotahapoini, terdapat beberapa proses yaitu case folding, cleansing, tokenisasi, stopword, normalisasi, dan stemming. Case folding yaitu proses mengubah semua huruf menjadi huruf kecil. Cleansing merupakan proses penghapusan karakter yang tidak relevan dengan klasifikasi jurnal. Tokenisasi yaitu pemisahan kata-kata paragraf atau kalimat menjadi token-token tertentu. Stopword removal yaitu penghapusan kata yang tidak mempengaruhi klasifikasi jurnal. Proses normalisasi yaitu mengubah dan mengembalikan bentuk penulisan tidak baku ke bentuk penulisan yang sesuai dengan KBBI. Proses terakhir adalah stemming, yaitu mengekstrak kata yang dilampirkan ke dalam kata dasar [5].
Metode Term FrequencyoInvers DocumentoFrequency adalahometodeoopembobotan yang menggabungkan frekuensi istilah dalam satu set dokumen dan kelangkaannya. Metodejini menggabungkanxduajkonsep pembobotan, yaitujfrekuensijkemunculanjkatajdalamjdokumenjtertentu danjfrekuensijkebalikan dari dokumen yang berisi kata tersebut. Berapa kali sebuah kata muncul dalam dokumen tertentu menunjukkanopentingnyajkataotersebut dalam dokumen itu. Frekuensi dokumen yang berisiokata-kata menunjukkan seberapa sering kata-kata itu muncul. Sehingga bobot hubunganjantarajsebuahjkatajdanjsebuahjdokumenjakanjtinggijapabilaofrekuensi kataotersebut tinggi di dalamodokumen dan frekuensiokeseluruhan dokumen yang mengandung kata tersebut yang rendah pada kumpulan dokumen. Proses TF-IDFodapatodilihatopadaogambar 2.
Istighfarizky, dkk
Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan Perbandingan Seleksi Fitur
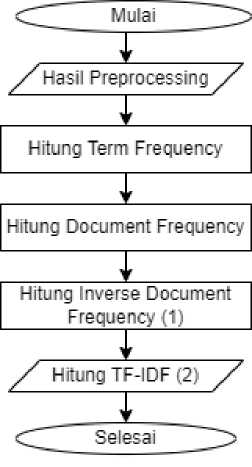
Gambar 2. TF-IDF
-
a. Hitung jumlahokemunculan term i dalam dokumen j (tfi,j).
-
b. Hitung jumlah dokumen yangpmengandung term i (df)
-
c. Menghitung nilai bobot inverse document frequency (idf) dengan menggunakan persamaan:
idfi = log g (1)
Keterangan:
N = jumlah dokumen secara keseluruhan
-
d. Menghitung nilai bobot TF-IDF dengan menggunakan persamaan:
wi,j = tfi.j x idfi (2)
Keterangan:
wi,j = bobot term i terhadap dokumen jo t f- i' = frekuensi term i pada dokumen jo
Iafi = nilai bobot IDF pada term i
AlgoritmaoK-Nearest Neighboroadalahometodeountuk mengklasifikasi objekoberdasarkanodata latih yang palingodekatodenganoobjekotersebut. Metode K-Nearest Neighbor adalahoalgoritma pembelajaran terawasi, dan hasil dari query instance baru dikategorikan berdasarkan sebagaian besar kategori algoritma K-Nearest Neighbor. Kelasoyangopaling sering ditampilkan adalah kelas yang diperoleh dari hasil klasifikasi. Kedekatan didefinisikan dalam jarak metrik, seperti jarak Euclidean [6].
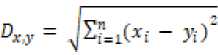
(3)
Keterangan: o
D = jarak kedekatano
x = data trainingl
y = data testingo
n = jumlah atribut individu antara 1 s.d n
i = atribut individu antara 1 s.d no
Chi-Square adalah metode untukomenghitung ketergantungan fitur. Pada pemrosesanoteks biasanya menggunakan dua kelasountukomengukur ketergantungan antara dua label dan kata – antara kelas tertentuoc.Tahapan Chi-Square dapatodilihat padaogambar 3. o

Gambar 3. Chi-Square
Berikut inioadalah rumus yangodigunakan untukomenerapkan metode seleksi fitur Chi-Square [7].
⅛c) =
WlJW-CgJz iΛ+C∣ ⅛+θ) (A+3J(C+DJ
(4)
Keterangan:
t = katao
c = kelas/kategorio
N = jumlah data latih
A = jumlah dokumen pada kelas c yang memuat t,
B = jumlah dokumen yang tidak ditemukan pada kelas c tapi memuat t,
C = jumlah dokumen pada kelas c yang tidak memuat t,
D = jumlah dokumen yang bukan merupakan dokumen kelas c dan tidak memuat term t
Gini Index adalah kriteria berbasis ketidakmurnian datajjyangjjmengukur perbedaan antarajjdistribusi probabilitasjjdarijjnilai atribut. Gini Indexjjumumnya dipakai dalamjjAlgoritma Classification and RegressionjjTreesjjyang merepsentasikanjjukuran seberapa acak pilihan objek darijjdata latih. Ukuran ketidak murnianjjmencapai 0 ketika hanya 1 kelasjjsaja yangjjadajjpada sebuahjjtitik. Namun sebaliknyajjakan mencapaijjmaksimumjjketika ukuran kelas padajjtitik tersebut seimbang. Gini Index dapat dianggapjjsebagai probabilitas dari duajjdata yangjjdipilih secara acak darijjkelasjjyang berbeda akan digunakan dalam penelitianjjini untuk mengukur divergensijjyang digunakan sebagai dasar bobot setiap. Cocokjjuntuk pemilahan, sistemjjbiner, nilaijjnumerik terus menerus, dan lain-lain. Tahapan Gini Index dapat dilihat pada gambar 4.
Istighfarizky, dkk
Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan Perbandingan Seleksi Fitur
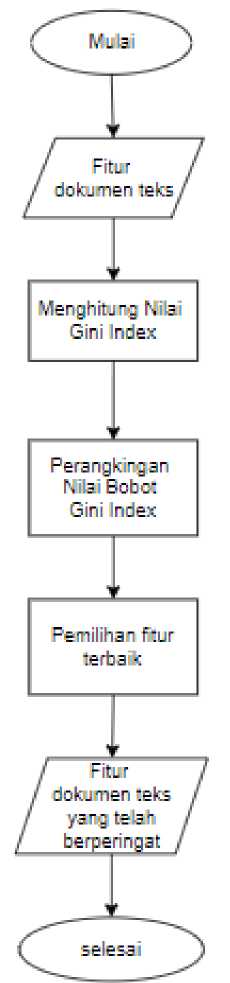
Gambar 4. Gini Index
Berikut inioadalah rumus yangodigunakan untukomenerapkan metode seleksi fitur Gini Index [8].
Gi(t) = i - ∑^1[pGlt)]2
(5)
Keterangan:
C = total kelas
t = termo
p(i|t) = peluang kelas i terhadap term t
-
2.7. Evaluasi
Confusionomatrixomerupakansalah satu metodeoyang dapat digunakanuntuk mengukur performansi suatuometodeoklasifikasi. Pada dasarnyaoconfusionomatrix ini berisi informasi yang membandingkan hasil klasifikasi yang dilakukan oleh sistem dengan hasil klasifikasi sebagaimana mestinya. Saat mengukur kinerja menggunakan confusion matrix, ada empatjjistilahjjyangjjmenggambarkanjjhasil darijjprosesjjklasifikasi. KeempatjjistilahjjtersebutjjadalahjjTrue Positive, True Negative, False Positive,
dan False Negative. NilaijTruejNegative (TN) adalah jumlah data negatif yangjjterdeteksijjdengan benar, jdanjjFalse Positive (FP) adalah data negatif tetapi terdeteksijjsebagaijjdata positif. Sementara itu, True Positive (TP) di sisi lain adalah dataopositif yang dikenali denganobenar. False Negative (FN) adalah kebalikan dari True Positive, sehingga datanya positif tetapi dikenali sebagai data negatif. Tabel Confusion matrix dapat dilihat pada tabel 1 [9].
-
Tabel 1. Confusion Matrixo
Kelaso
oTerklarifikasi Positifo
oTerklarifikasi Negatifo
Positifo
oTP (True Positive) o
oFN (False Negative) o
Negatifo
oFP (False Positive) o
oTN (True Negative) o
Dimana:
-
• True Positive, jumlahodata positif yang diklasifikasikan dengan benarooleh sistem.
-
• True Negative, jumlahodata negatif yangodiklasifikasikan dengan benarooleh sistem.
-
• False Negative, jumlahodata negatifonamun diklasifikasikan salah oleh sistem.
-
• False Positive, jumlahodata positifonamun diklasifikasikan salah oleh sistem.
BerdasarkanjjnilaijjTrue Negative (TN), False Positive (FP), False Negative (FN), dan True Positive (TP) dapatodiperolehnilai akurasi, presisiodanrecall. Nilaioakurasi menggambarkan seberapa akuratjjsistemjjdapatjjmengklasifikasikanjjdatajjsecarajjbenar. Denganjjjkatajjlain, nilaijjjakurasijjjmerupa kan perbandingan antara data yang terklasifikasi benar dengan keseluruhan data. Nilai akurasi dapat diperolehjdenganjjpersamaanjj(6). Nilaijjpresisijjmenggambarkanjjjumlahjdatajjkategorijjjpositif yang diklasifikasikan secara benar dibagi dengan total data yang diklasifikasi positif. Presisi dapat diperolehodenganjpersamaano(7)jsementara itu, recall menunjukkanoberapajpersenjdatajkategori positif yang terklasifikasikanjdengan benar oleh sistem. Nilai recall diperoleh denganjpersamaan 8.
Setelah mendapat nilai recall dan precision, makaodilakukanoperhitunganomenggunakanoF1-score. F1-scoreodigunakanountukomengukurokombinasiohasil precision dan recall, sehingga menjadi satu nilai pengukuran. F1-Score dapat dihitung menggunakan persamaan 9:
2
F1 = - ------- (9)
Precission Recall
-
3. Hasil dan Pembahasan
Pada penelitian yang dilakukan ada 80%ototal data digunakan selama tahap pelatihan dan juga validasi. Perubahan nilai k pada percobaan adalah k = 4, k = 6, k = 7, k = 9, dan k = 11. Uji threshold dilakukan dengan menggunakan seleksi fitur Gini Index dan seleksi fitur Chi-Square. Thresholdoadalah persentasemjumlah fitur yang dipilih dari semua fitur yang diurutkan. Threshold yang digunakan adalah 10%, 5%, 2%, 1%, 0.5%, dan 0.2%. Pada setiap iterasi dari 10-Fold Cross Validation, akan dihitung rata-rata performa F1-Score dan akurasi dengan menggunakan persamaan (9) dan (6). Nilai k dengan kinerja F1-Score tertinggi akan dipilih sebagai model yang terbaik. Nilai k dengan F1-Score tertinggi berarti hasil klasifikasi jurnal lebih akurat. Setelah melakukan proses pelatihan dan validasi pada model K-Nearest Neighbor menggunakan uji 10-Fold Cross Validation,
Istighfarizky, dkk
Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan Perbandingan Seleksi Fitur didapatkan nilai k dengan performansi F1-Score terbaik. Uji kombinasi threshold Chi-Square dan Gini Index dan nilai k yang sudah dilakukan menghasilkan beragam performa yang berbeda. Dari hasil pengujian yang diperoleh, dapat dilihat pengaruh dari threshold yang digunakan untuk performansi dari metode K-Nearest Neighbor, seperti yang ditunjukkan pada tabel 5.
Tabel 5. Hasil Evaluasi Pengujian KNN dengan Seleksi Fitur Chi-Square dan Gini Index
|
Threshold |
Ukuran Evaluasi (Rata-Rata Fold) | |||
|
F-1 Score Chi-Square |
F1-Sscore Gini Index |
Akurasi Chi-Square |
Akurasi Gini Index | |
|
10% |
82,2% |
75,2% |
82% |
75% |
|
5% |
81,4% |
81,7% |
81,2% |
81,6% |
|
2% |
81,6% |
82,2% |
81,2% |
82% |
|
1% |
81,8% |
81,4% |
81,6% |
80,8% |
|
0.5% |
81,6% |
71,5% |
81,2% |
71,6% |
|
0.2% |
74,1% |
47,9% |
74,1% |
48,3% |
Pengujian kombinasi threshold Chi-Square dan Gini Index dan nilai k yang sudah dilakukan menghasilkan beragam performa yang berbeda. Dari hasil pengujian yang diperoleh dapat diketahui pengaruh threshold yang digunakan terhadap evaluasi kinerja metode K-Nearest Neighbor, hal tersebut dapat dilihat pada gambar 5 dan gambar 6.
PENGARUH THRESHOLD TERHADAP Fl
SCORE
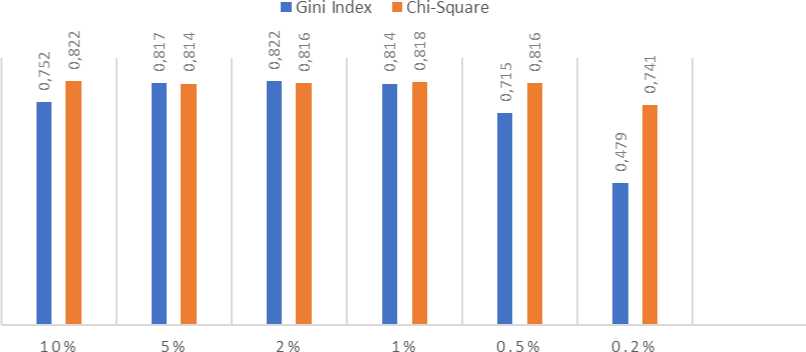
Gambar 5. Pengaruh Threshold terhadap F1-Score
Gambar 5 menunjukkan pengaruh threshold terhadap performa F1-Score metode K-Nearest Neighbor dengan seleksi fitur Chi-Square dan seleksi fitur Gini Index. F1-Score yang tertera pada Gambar 5 adalah nilai F1-Score dari kombinasi nilai k dengan akurasi tertinggi. Nilai threshold diketahui memiliki pengaruh terhadap F1-Score.
PENGARUH THRESHOLD TERHADAP AKURASI
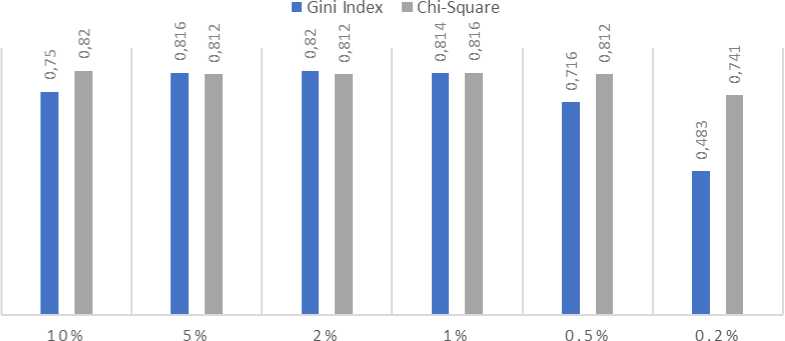
Gambar 6. Pengaruh Threshold terhadap akurasi
Akurasi yang tertera pada Gambar 6 adalah akurasi tertinggi dari kombinasi nilai k yang sudah diuji. Nilai threshold diketahui memiliki pengaruh terhadap akurasi. Model dengan threshold yang menghasilkan akurasi di atas nilai rata-rata tersebut dapat dikatakan sebagai model dengan performa yang baik dalam mengklasifikasikan jurnal.
-
4. Kesimpulan
Berdasarkan penelitian yang telah dilakukan, ditarik kesimpulan bahwa implementasi seleksi fitur dapat meningkatkan performa precision, recall, F1-Score, dan akurasi dari metode K-Nearest Neighbor dalam mengklasifikasikan jurnal dan seleksi fitur Chi-Square lebih unggul daripada seleksi fitur Gini Index. Pada eksperimen seleksi fitur Chi-Square, kombinasi threshold 1% denganoparameter nilaiok=6 adalah kombinasi yang dipilih menjadi model terbaik. Threshold ini menyeleksi sekitar 31 fitur dengan nilai Chi-Square tertinggi. Pada pengujian data baru, model K-Nearest Neighbor dengan seleksi fitur Chi-Square menghasilkan performa precision, recall, F1-Score, dan akurasi secara berturut-turut yaitu 85%, 83.3%, 88.2%, dan 92.3%. Pada eksperimen seleksi fitur Gini Index, kombinasi threshold 1% dengan parameter nilai k=4 adalah kombinasi yang dipilih menjadi model terbaik. Threshold ini menyeleksi sekitar 31 fitur dengan nilai Gini Index tertinggi. Pada pengujian data baru, model K-Nearest Neighbor dengan seleksi fitur Gini Index menghasilkan performa precision, recall, F1-Score, dan akurasi secara berturut-turut yaitu 81.2%, 80.3%, 81.6%, dan 86.6%
Daftar Pustaka
-
[1] Z. XIONG, J. JIANG and Y. ZHANG, "New feature selection approach (CDF) for text categorization", Journal of Computer Applications, vol. 29, no. 7, pp. 1755-1757, 2009. Available: 10.3724/sp.j.1087.2009.01755.
-
[2] H. Alshalabi, S. Tiun, N. Omar and M. Albared, "Experiments on the Use of Feature Selection and Machine Learning Methods in Automatic Malay Text Categorization", Procedia Technology, vol. 11, pp. 748-754, 2013. Available: 10.1016/j.protcy.2013.12.254.
-
[3] I. Listiowarni and N. Puspa Dewi, "Pemanfaatan Klasifikasi Soal Biologi Cognitive Domain Bloom’s Taxonomy Menggunakan KNN Chi-Square Sebagai Penyusunan Naskah Soal", Digital Zone: Jurnal Teknologi Informasi dan Komunikasi, vol. 11, no. 2, pp. 186-197, 2020. Available:
Istighfarizky, dkk Klasifikasi Jurnal menggunakan Metode KNN dengan Mengimplementasikan
Perbandingan Seleksi Fitur 10.31849/digitalzone.v11i2.4798.
-
[4] T. Setiyorini and R. Asmono, "PENERAPAN METODE K-NEAREST NEIGHBOR DAN GINI INDEX PADA KLASIFIKASI KINERJA SISWA", Jurnal Techno Nusa Mandiri, vol. 16, no. 2, pp. 121-126, 2019. Available: 10.33480/techno.v16i2.747.
-
[5] K. Yonatha Wijaya and A. Karyawati, "The Effects of Different Kernels in SVM Sentiment Analysis on Mass Social Distancing", JELIKU (Jurnal Elektronik Ilmu Komputer Udayana), vol. 9, no. 2, p. 161, 2020. Available: 10.24843/jlk.2020.v09.i02.p01.
-
[6] H. Hadi and T. Sukamto, "Klasifikasi Jenis Laporan Masyarakat Dengan K-Nearest Neighbor Algorithm", JOINS (Journal of Information System), vol. 5, no. 1, pp. 77-85, 2020. Available: 10.33633/joins.v5i1.3355.
-
[7] C. Suharno, M. Fauzi and R. Perdana, "Klasifikasi Teks Bahasa Indonesia Pada Dokumen Pengaduan Sambat Online Menggunakan Metode K-Nearest Neighbors Dan Chi
square", Systemic: Information System and Informatics Journal, vol. 3, no. 1, pp. 25-32, 2017. Available: 10.29080/systemic.v3i1.191.
-
[8] C. Aggarwal, Data Mining: The Textbook. Springer International Publishing Switzerland, 2015. Available: 10.1007/978-3-319-14142-8.
-
[9] M. Imron and B. Prasetyo, "Improving Algorithm Accuracy K-Nearest Neighbor Using Z-Score Normalization and Particle Swarm Optimization to Predict Customer Churn", Shmpublisher.com, 2022. [Online]. Available: https://shmpublisher.com/index.php/joscex/article/view/7.
176
Discussion and feedback