Text Summarization terhadap Berita Bahasa Indonesia menggunakan Dual Encoding
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana
Volume 11, No 2. November 2022
Text Summarization terhadap Berita Bahasa Indonesia menggunakan Dual Encoding
Made Dwiki Budi Laksanaa1, AAIN Eka Karyawatia2, Luh Arida Ayu Rahning Putria3, I Wayan Santiyasaa4, Ngurah Agus Sanjaya ERa5, I Gusti Agung Gede Arya Kadnyanana6
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana Badung, Bali, Indonesia
6gungde@unud.ac. id
Abstract
Text summarization or automatic text summarization can make readers receive information quickly without having to read the entire news text, so readers can get more time in reading other news texts. Making text summarization can use two techniques, namely, extractive and abstractive techniques. Abstractive techniques have the aim of producing summary sentences with concepts as humans take the essence of a document that is read. In this study, the author builds an abstractive summarization model using the Dual Encoding method consisting of GRU. The evaluation was carried out using K-Fold Cross Validation, the number of folds used was 5. By using K-Fold Cross Validation, the ROUGE-1, ROUGE-2, and ROUGE-L values were 0.2127749, 0.119851, dan 0.1880595, respectively. For testing when using new data ROUGE-1, ROUGE-2, and ROUGE-L values were 0.3387776, 0.2395176, dan 0.3077376, respectively.
Keywords: Recurrent Neural Network, Text Summarization, Indonesia News, Dual Encoding, Gated Recurrent Unit
-
1. Pendahuluan
Perkembangan informasi pada internet yang tumbuh dengan pesat, dapat menimbulkan pelimpahan informasi di dalam internet. Informasi – informasi yang terus bertambah banyak seiring dengan berjalannya waktu dapat membuat penikmat informasi semakin bingung dalam memilih informasi yang diinginkan untuk dibaca. Salah satu informasi yang terus bertambah adalah teks berita. Teks berita ini bukan ditulis secara singkat tetapi ditulis secara panjang, sehingga membuat pembaca malas dalam membaca. Untuk mempermudah dalam hal membaca, maka diperlukannya sebuah alat. Alat tersebut adalah text summarization. Text summarization atau peringkas teks otomatis dapat membuat pembaca menerima informasi dengan cepat tanpa harus membaca keseluruhan teks berita, sehingga pembaca dapat mendapat waktu lebih dalam membaca teks berita lainnya.
Ada dua metode yang tersedia untuk meringkas teks: teknik ekstraksi dan teknik abstrak. Teknik ekstraksi menggunakan setiap kata dalam teks asli untuk meringkas, mengelompokkan dan mengatur kata-kata dalam teks asli tidak berubah. Pernyataan yang dihasilkan biasanya memiliki struktur yang sama dengan pernyataan pada dokumen aslinya [1]. Metode abstrak merangkum abstrak dengan konsep bagaimana menangkap esensi dari teks yang dibaca orang [1].
Dalam penerapan text summarization menggunakan abstraktif dibutuhkan pendekatan Deep Learning. Dengan deep learning, masukan akan dihitung melalui layer yang lebih banyak dibandingkan dengan Jaringan Syaraf Tiruan sederhana [2]. Deep learning yang digunakan ialah Recurrent Neural Network (RNN). Penelitian mengenai text summarization menggunakan RNN pernah dilakukan oleh beberapa
peneliti sebelumnya seperti penelitian yang dilakukan oleh Yoko, et al. (2018) menghasilkan model terbaik terhadap berita bahasa Indonesia diperoleh dari 6457 dataset dengan jumlah word2vec sebanyak 200 dan jumlah hidden state sebanyak 256 dengan loss sebesar 0.0006654 dan akurasi 99.8810% untuk pengujian sistem dan akurasi sebesar 46,65% untuk pengujian Q&A Evaluation. Kemudian penelitian yang dilakukan oleh Rajput dan Mandre (2020) menghasilkan nilai ROGUE-1 yaitu 41,75 untuk CNN/DailyMail dan 35,12 untuk DUC 2004 terhadap berita bahasa Inggris. Penelitian yang dilakukan oleh Adelia, et al. (2019) menghasilkan model terbaik dengan menggunakan BiGRU dengan nilai ROUGE-1 dan ROUGE-2 sebesar 0.11975 dan 0.01199.
Berdasarkan paparan penelitian sebelumnya, pada penelitian ini akan melakukan text summarization dari berita bahasa Indonesia dengan menggunakan recurrent neural network dengan menggunakan dual encoding model. Penggunaan dual encoding model dapat digunakan dengan baik pada text summarization terhadap berita bahasa Indonesia.
-
2. Metode Penelitian
Penelitian yang dilakukan penulis terdiri dari beberapa tahapan, yaitu data berupa teks berita berbahasa Indonesia. Setelah data atau teks berita berbahasa indonesia telah terkumpul, maka akan melalui tahap text preprocessing. Setelah data telah bersih maka akan masuk ke dalam arsitektur recurrent neural network dengan dual encoding. Dalam dual encoding ini akan menghasilkan abstractive summarization. Setelah menghasilkan abstractive summarization maka akan di evaluasi hasil tersebut. Secara umum, alur penilitian dapat dilihat pada gambar 1.
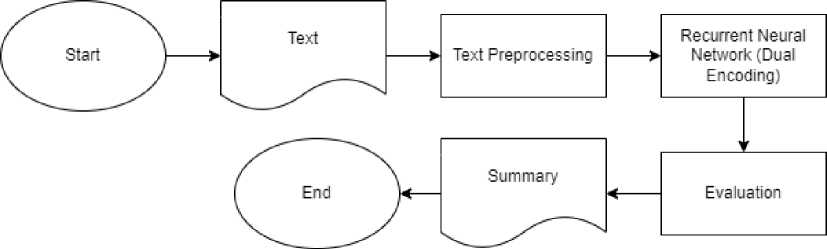
Gambar 1. Alur Umum Penelitian
-
2.1 Data Penelitian
Data yang digunakan adalah data dalam bentuk dataset. Dataset yang digunakan adalah dataset INDOSUM. Dataset yang dikembangkan oleh Kurniawan dan Louvan dari Jurnal INDOSUM: A New Benchmark Dataset for Indonesian Text Summarization tahun 2018. Dataset ini terdiri dari 93.870 artikel berita. Setiap artikel mempunyai judul, kategori, sumber, URL dari berita asli, dan abstractive summary. Dataset ini mempunyai 6 kategori yaitu Inspirasi, Entertainment, Gosip, berita utama, Olahraga, dan Teknologi.
Dalam penelitian ini, data yang diperoleh diolah sebelum masuk ke model. Data yang tidak terkait dengan data tidak terstruktur merupakan kelemahan utama dalam kumpulan data dan dapat meningkatkan waktu pelatihan. Fase ini terdiri dari beberapa langkah, termasuk case folding, Remove Punctuation, dan tokenization. Case Folding akan mengubah semua karakter menjadi huruf kecil. Remove Punctuation adalah teknik untuk menghilangkan tanda baca yang digunakan dalam teks untuk membedakan antara kalimat dan komponennya dan untuk memperjelas maknanya. tokenization untuk memecah kalimat menjadi token yang dalam hal ini berupa kata, dan case conversion untuk mengkonversi bentuk huruf dalam teks menjadi seragam yaitu menjadi huruf kecil [3].
Setelah tahap text preprocessing dan dihasilkan data text preprocessed maka data akan diolah di dalam model. Model yang digunakan yaitu dual encoding model. Data yang dihasilkan melalui dual encoding model ini adalah abstractive summary.
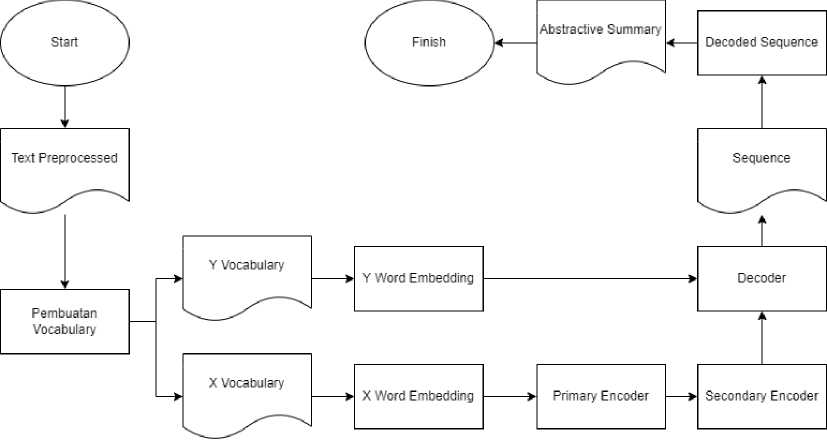
-
Gambar 2. Arsitektur Dual Encoding
Sebelum masuk ke primary encoder maka akan masuk kedalam proses pembuatan vocabulary. Pembuatan vocabulary digunakan untuk menghasilkan x vocabulary (vocabulary untuk teks) sedangkan y vocabulary (vocabulary untuk ringkasan). Setelah pembuatan vocabulary akan diproses di dalam word embedding layer. Untuk x word embedding akan diproses ke dalam primary encoder sedangkan y word embedding akan diproses ke dalam decoder. Dalam primary encoder dilakukannya perhitungan hidden state. Setelah mendapatkan hidden state di primary encoder, mulai menghitung content representation untuk x. Primary encoder menghasilkan semantic vector. Semantic vector berisi hidden state yang telah dihitung dan content representation. Di primary encoder, hidden state representation dibuat hanya sekali dalam model ini. Setelah itu, semantic vector akan diolah di decoder dan secondary encoder.
Dalam decoder, akan dihitung hidden state. Setelah menghitung hidden state lalu akan dihitung content representation of partial generated sequence dan dikirim ke secondary encoder. Lalu secondary encoder akan menghasilkan importance weight. Di dalam secondary encoder, akan dilakukan penghitungan hidden state. Importance weight akan dikirim ke decoder. Setelah itu akan dilakukan perhitungan hidden state dari decoder berdasarkan hidden state yang terakhir dan final state yang baru. Setelah itu akan menghasilkan sequence dan akan masuk ke dalam proses decoded sequence untuk menghasilkan abstractive summary.
Blok primary encoder mengandung bidirectional Gated Recurrent Unit (Bi-GRU) sebagai recurrent unit. Primary encoder membaca panjang variable dari input sequence, menghasilkan hidden state representation menggunakan bidirectional GRU. Untuk setiap posisi kata, forward GRU secara berurut menghitung hidden state representation dan backward GRU menghitung hidden representation dalam reversed sequence. Content representation untuk keseluruhan input sequence dibuat oleh penggabungan hidden state representation dan menggunakan konten untuk menunjukan setiap kata dari input sequence. Primary encoder membuat feature representation disebut semantic vector untuk setiap kata dalam input sequence. Semantic vector berisi hidden state representation dan content representation [4]. GRU bisa secara adaptif menangkap ketergantungan dari skala waktu berbeda, yang terdapat dalam persamaan (1):
r ut = σ(Wu[xt,ht-ι]),
rt = σ(W[xtΛ-ιD, h't = tanh(Wjxt,rt O ht-ι]), hιt = (1 - ut) O ht-1 + ut O ht,
(1)
Keterangan:
Wu,Wr,Wh = matrik parameter
xt = input embedding vector yang sesuai
ht = hidden state vector saat waktu ke-t
O = operator perkalian
Forward hidden state dan backward hidden state didefinisikan dalam persamaan (2).
f Hpt = GRUp(xt,hP-1),
{hp = GRUp(xt,hP-ι), (2)
I hP = [hp, hpt∖,
Keterangan:
hP = hidden state representation yang dihasilkan menggunakan forward GRU untuk setiap posisi kata secara sekuensial berdasarkan current word embedding dan hidden state sebelumnya
hP = hidden state representation yang dihasilkan menggunakan backward GRU untuk setiap kata dari input sentence dalam reversed sequence
hp = gabungan hidden state dari forward GRUdan backward GRU
hp digunakan untuk menunjukkan setiap kata dalam input sequence. Content representation dihitung menggunakan persamaan (3).
Cp = tanh(Wp±∑^ιhp + bp) (3)
Keterangan:
Cp = content representation
Wp dan bp= parameter
N = panjang dari input sequence
Secondary encoder terdiri dari unidirectional GRU sebagai Recurrent Neural Network. Hidden representation, content representation, dan decoded content representation digunakan oleh secondary encoder untuk menghitung importance weight. Menggunakan importance weight, context vector yang sesuai dihitung ulang dan diumpankan ke decoder untuk menghasilkan output yang diinginkan. Secondary encoder melakukan encoding lebih baik di setiap decoding stage [4]. Secondary encoder membaca input sequence dan menghitung importance weight untuk setiap langkah decoding berdasarkan decoded information dari setiap tahap. Untuk setiap kata dalam input sequence, importance weight dihitung berdasarkan informasi itu sendiri. Informasi tersebut ialah saliency dan redundancy. Importance weight dihitung menggunakan persamaan (4).
αt = σ(W2(tanh(W1[hP,Cp,Cd∖ + b1)) + hpτWsCp + hpτWsCd - CpτWrCd + b2) (4)
Keterangan:
αt = importance weight
W1, W2, Ws, Wr, b1, b2 = learning parameter
Cp = content representation dari seluruh input sequence
Cd = content representation dari seluruh output sequence yang dihasilkan oleh decoder
hpτWsCp = saliency antara setiap kata
hVrWsCd = seluruh konten dari teks sumber
CpτWrCd = redundancy antara konten teks sumber dan decoded content dari tahap sekarang
Hidden state di encoded oleh secondary encoder yang mengambil mayoritas dar informasi secara langsung dari previous hidden dan mengabaikan efek dari current word menggunakan (5).
h^ = (l-α)Oh^-1 + αtOGRUs(xt,h^-1) (5)
Keterangan:
h = hidden state
hst-1 = previous hidden
Decoder dilengkapi dengan attention mechanism yang menunjukan decoding operation secara bertahap dan menghasilkan partial fixed length output pada setiap tahap. Partial fixed length output berisi decoded content representation. Decoder menghasilkan output sequence lebih akurat dengan menggunakan semantic context vector yang baru yang dihasilkan oleh secondary encoder [4]. context vector dihitung sebagai weighted sum dari hidden state menggunakan persamaan (6).
Ci= ∑‰αijh (2.6)
Keterangan:
Ci = context vector
aij dari persamaan (6) adalah weight yang dihitung untuk setiap hidden state menggunakan persamaan
(7).
( I J
_ exp(elj')
aij ∑k=ιexp(eik)
(2.7)
Sij = vjtanh(wαhf-ι + Uahp < hf = GRUd(yi,hf-1)
Keterangan:
eij = nilai yang menunjukan seberapa baik input sekitar posisi j yang cocok dengan output di posisi i hf = hidden state
hf_r = hidden state yang terakhir
y i = target word
Partial fixed-length sequence secara bertahap di decode menggunakan persamaan (8).
Cf = tanh(Wd1∑f=ιhf + b J (8)
Keterangan:
Wd dan bd = parameter
L = panjang dari current decode sequence
Final state yang baru dihasilkan setelah setiap fixed length decoding dan decoder yang ditulis ulang dengan menggunakan persamaan sebagai berikut:
hf = (GRUd(yi, [hd-ι,hsm]), if L%K == 0 i I GRUd(yi,hf-1), otherwise
(9)
Keterangan:
hsm = final state
Current context vector dihasilkan melalui primary encoder dan decoder hidden state digabungkan dan diumpankan ke decoder melalui satu linear layer untuk menghasilkan vocabulary distribution menggunakan persamaan (10)
Pv = P(yι∖y1,--.,yι-1^ = softmαx(Wv[hf,Ci] + bv) (10)
Keterangan:
Wv,bv = learning parameter
Pv = conditional probability distributions untuk target word atas semua kata dalam vocabulary saat timestep
ROUGE atau Recall-Oriented Understudy for Gisting Evaluation adalah pengukuran evaluasi otomatis yang diturunkan dari BLEU (BiLingual Evaluation Understudy). ROUGE menggunakan n-gram yang overlap antara system-generated summary dan handwritten gold standard summaries. Nilai dalam DUC corpora digunakan untuk memvalidasi sistem ROUGE. ROUGE biasanya digunakan untuk peringkasan teks karena recall-oriented tidak seperti BLEU yang fokus dalam precision. ROUGE adalah metrik yang umum digunakan untuk mengukur coverage dalam peringkasan. Namun, ROGUE mempunyai batasan yang besar. ROGUE tidak memperhitungkan struktur kalimat atau ketepatan tata bahasa. Ringkasan yang diberi peringkat tinggi menggunakan beberapa kombinasi parameter ROUGE akan tetap memiliki peringkat tinggi jika semua kata – katanya bercampur aduk yang menghasilkan kata – kata tidak berarti. ROUGE juga tidak memperhitungkan lexical variations yang memiliki kemiripan secara semantik. Namun, karena kemudahan penggunaan dan tidak adanya yang bisa diandalkan dalam teknik evaluasi otomatis sehingga ROUGE cukup popular [5].
ROUGE-N pada dasarnya adalah perhitungan penarikan berdasarkan perbandingan N-gram dari ringkasan standar emas dan teks ringkasan mesin. Jumlah n-gram yang digunakan bervariasi. Namun, n-gram dengan angka n = 1 (ROUGE-1) dan n = 2 (ROGUE-2) paling sering digunakan [6]. Maka ROGUE-N dapat dihitung dengan persamaan (11).
ROUGE-N= - (11)
q
Keterangan:
p = jumlah n-gram yang sama dengan gold standard summary dan teks hasil peringkasan mesin
q = jumlah n-gram pada gold standard summary
ROUGE-L mengevaluasi ringkasan teks dengan membandingkan common subsequence length (LCS) atau hasil ringkasan teks mesin dengan urutan kata terpanjang yang sama antara ringkasan standar emas [6]. ROUGE-L dapat dihitung menggunakan persamaan (12)
(12)
ROUGE -L=-m
Keterangan:
LCS = longest common subsquence
m = jumlah kata pada gold standard summary
Pada penelitian ini, untuk mengetahui performa abstractive summarization pada teks berbahasa
Indonesia menggunakan Dual Encoding, maka akan dilakukan pengujian atau evaluasi untuk
mendapatkan nilai dari ROUGE-1, ROUGE-2, dan ROUGE-L. Pada pengujian ini, menggunakan data artikel berita bahasa Indonesia dataset yang akan dibagi dengan perbandingan 90% untuk data training dan validasi, dan untuk 10% termasuk data testing. Selanjutnya validasi model dilakukan dengan menggunakan metode K-Fold Cross Validation, dengan jumlah fold sebesar 5 dan berdasarkan konfigurasi hyperparameter (Learning Rate, Batch Size, dan Epoch)
Dalam melakukan K-Fold Cross Validation. Jumlah unit pada GRU digunakan sebesar 100 dan untuk dimensi pada word embedding sebesar 300. Hyperparameter yang digunakan ialah learning rate, batch size, dan epoch. Learning rate yang diuji sebesar 0.01 dan 0.001. Batch size yang diuji sebesar 8, 16, dan 32. Epoch yang diuji sebesar 5, 10, dan 20. Parameter – parameter tersebut akan dikombinasikan dan menghasilkan 18 nilai setiap rata – rata ROUGE-1, rata - rata ROUGE-2, dan rata - rata ROUGE-L. Hasil dari validasi model Dual Encoding dapat dilihat pada Tabel 1.
Tabel 1. Hasil dari K-Fold Cross Validation
|
Learning Rate |
Batch Size |
Epoch |
Avg ROUGE 1 |
Avg ROUGE 2 |
Avg ROUGE L |
|
0.01 |
8 |
5 |
0.0620598 |
0.0020986 |
0.0467862 |
|
10 |
0.0859643 |
0.0004356 |
0.0612732 | ||
|
20 |
0.0799099 |
0.0018761 |
0.0585936 | ||
|
16 |
5 |
0.0722505 |
0.001867 |
0.052169 | |
|
10 |
0.0837565 |
0.001233 |
0.0583148 | ||
|
20 |
0.0817789 |
0.0028873 |
0.0600106 | ||
|
32 |
5 |
0.090794 |
0.0024744 |
0.0647594 | |
|
10 |
0.100424 |
0.003337 |
0.0685092 | ||
|
20 |
0.07696 |
0.002076 |
0.0548748 | ||
|
0.001 |
8 |
5 |
0.1113044 |
0.0106942 |
0.0794237 |
|
10 |
0.2168853 |
0.117364 |
0.1879771 | ||
|
20 |
0.2127749 |
0.1198551 |
0.1880595 | ||
|
16 |
5 |
0.1091135 |
0.0065141 |
0.078212 | |
|
10 |
0.1473753 |
0.0446482 |
0.1151162 | ||
|
20 |
0.1876084 |
0.0845609 |
0.1576544 | ||
|
32 |
5 |
0.0937695 |
0.0048913 |
0.0712081 | |
|
10 |
0.1100292 |
0.0056799 |
0.0773099 | ||
|
20 |
0.1209372 |
0.0261349 |
0.0966511 |
Pada Tabel 1 di atas dapat dilihat nilai ROUGE-1, ROUGE-2, dan ROUGE-L yang didapatkan melalui pengujian Learning Rate, batch size dan epoch. Selanjutnya dari hasil pengujian tersebut akan dianalisis untuk menemukan model dengan performa terbaik yang selanjutnya akan diuji kembali menggunakan data testing.
■ ROUGE-1 ■ ROUGE-2 ■ ROUGE-L 0.125
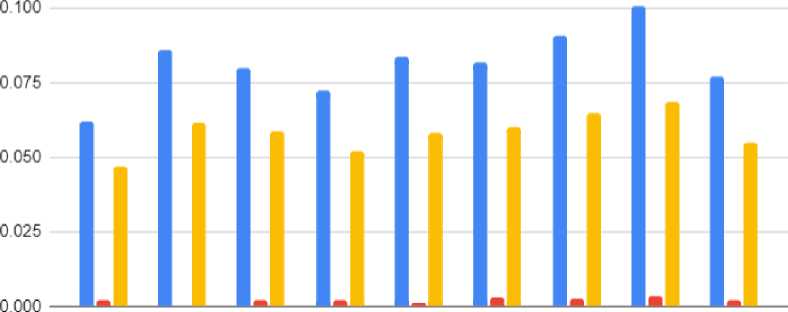
Gambar 3. Hasil K-Fold-Cross Validation dengan Learning Rate 0.01
Gambar 3 menunjukkan perbandingan hasil pengujian pada setiap batch size dan epoch terhadap learning rate 0.01. Dapat dilihat bahwa pengujian dengan batch size 8 dan epoch 5 memperoleh hasil terendah dengan nilai Rouge-1, Rouge-2, dan Rouge-L yaitu 0.0620598, 0.0020986, dan 0.0467862. Kemudian pengujian dengan batch size 32 memperoleh hasil tertinggi dengan Rouge-1 0.100424, Rouge-2 0.003337, dan ROUGE-L 0.0685092.
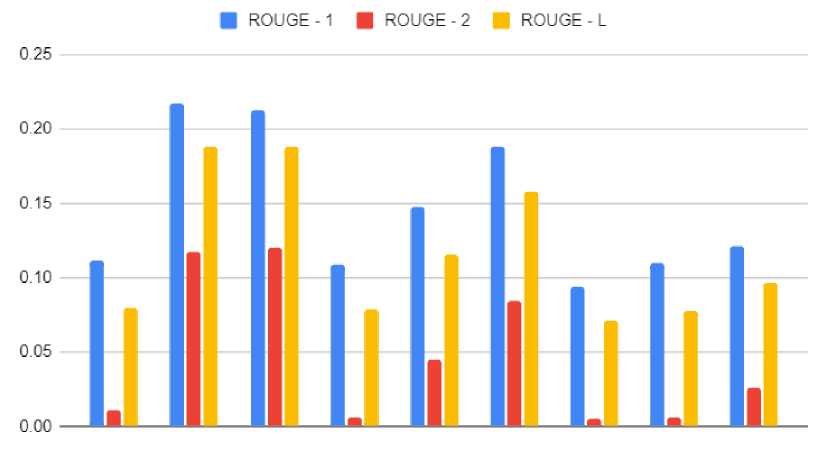
Gambar 4. Hasil K-Fold-Cross Validation dengan Learning Rate 0.001
Gambar 4 menunjukkan perbandingan hasil pengujian pada setiap batch size terhadap learning rate 0.001. Dapat dilihat bahwa pengujian dengan batch size 128 memperoleh hasil terendah dengan nilai Rouge-1, Rouge-2, dan Rouge-L yaitu 0.0937695, 0.0048913, dan 0.0712081. Kemudian pengujian dengan batch size 32 memperoleh hasil tertinggi dengan Rouge-1 0.2127749, Rouge-2 0.1198551, dan ROUGE-L 0.1880595.
Berdasarkan analisa diatas didapatkan bahwa setiap kenaikan batch size akan mengalami penurunan nilai ROUGE. Sehingga batch size yang paling baik digunakan sebesar 8 dan epoch 20. Untuk learning rate yang digunakan ialah 0.001 dapat dilihat pada Gambar 4 memiliki grafik yang paling tinggi dari pada Gambar 3.
-
3.2. Hasil Pengujian Model Terbaik dengan Data Baru
Berdasarkan analisis yang telah dilakukan hasil pengujian model dengan K-Fold Cross-Validation, didapatkan model abstractive summarization menggunakan Dual Encoding dengan performa terbaik pada learning rate 0.001 dan batch size 32. Kemudian model terbaik ini diuji kembali menggunakan data baru yang belum pernah melewati pelatihan dan validasi sebelumnya. Hasil pengujian menggunakan data baru dapat dilihat pada Tabel 2.
Tabel 2. Hasil dari Pengujian Data Baru
|
Pengujian |
ROUGE-1 |
ROUGE-2 |
ROUGE-L |
|
Training Validasi |
0.2127749 |
0.1198551 |
0.1880595 |
|
Testing |
0.3387776 |
0.2395176 |
0.3077376 |
-
3.3. Hasil Perbandingan Ringkasan Mesin dengan Ringkasan Asli
Berikut merupakan hasil dari ringkasan mesin dengan ringkasan aslinya dapat dilihat pada tabel 3. Hasil ringkasan dari mesin sudah meringkas dengan membuat sebuah kalimat dan kata – kata unik dari teks. Terdapat kata – kata yang sama dari original summary dan generate summary seperti Gionee pabrikan ponsel asal tiongkok telah mengumumkan. Setiap kata – kata unik akan mempengaruhi nilai ROUGE-1 dan ROUGE-2.
Tabel 3. Hasil dari Ringkasan Mesin dengan Ringkasan Aslinya
Teks
Original Summary
Generate Summary
harus diakui smartphone dengan bezel tipis dan rasio layar 189 atau yang disebut i nfi nity display fullvision edge to edge dan fullview memiliki daya tarik yang luar biasa gionee pabrikan ponsel asal tiongkok ini pun telah mengumumkan 8 smartphone terbaru di mana 6 smartphone menggunakan layar penuh fullview display gionee membagi 8 smartphone barunya itu dalam beberapa seri seperti seri premium m7 yang dirancang untuk para profesional series s yang …
gionee pabrikan ponsel asal tiongkok telah mengumumkan 8 smartphone terbaru di mana enam smartphone menggunakan layar penuh fullview display gionee membagi delapan smartphone barunya itu dalam beberapa seri seperti seri premium m7 yang dirancang untuk para profesional series s yang ditunjukkan untuk kalangan muda dan series f yang hadir dengan harga terjangkau
gionee pabrikan ponsel asal tiongkok telah mengumumkan waktu dua bulan disebutkan diklaim menjadi salah satu perangkat yang diminati oleh dua perangkat yang diluncurkan dalam menu e commerce atau mini vr pengumuman tersebut dikabarkan akan mel uncur ke perangkat android menegaskan ai adalah fitur bernama ti meline kehadiran google kemudian bisa meneri ma akun pooka video maupun google assistant
-
4. Kesimpulan
Berdasarkan penelitian yang telah dilakukan dan hasil yang diperoleh selama melakukan penelitian, dapat ditarik kesimpulan sebagai berikut
-
1. Recurrent Neural Network menggunakan model Dual Encoding dalam text summarization terhadap berita Bahasa Indonesia untuk membuat abstractive summary menghasilkan nilai ROUGE-1 sebesar 0.2127749, ROUGE-2 sebesar 0.119851, dan ROUGE-L sebesar 0.1880595 setelah melalui pengujian model menggunakan K-Fold Cross Validation. Dengan konfigurasi learning rate 0.001, batch size 8, dan epoch 20 menghasilkan model terbaik.
-
2. Model recurrent neural network dengan menggunakan dual encoding terbaik akan diuji dengan data yang baru untuk menghasilkan abstractive summary. Hasil pengujian tersebut menghasilakn nilai ROUGE-1, ROUGE-2, ROUGE-L sebesar 0.3387776, 0.2395176, dan 0.3077376.
Daftar Pustaka
-
[1] K. Ivanedra and M. Mustikasari, Implementasi Metode Recurrent Neural Network pada Text Summarization dengan Teknik Abstraktif, Jurnal Teknologi Informasi dan Ilmu Komputer, 2019.
-
[2] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning, 2016.
-
[3] A. E. Karyawati, P. A. Utomo, and I. G. A. Wibawa, “Comparison of SVM and LIWC for Sentiment Analysis of SARA,” IJCCS (Indonesian Journal of Computing and Cybernetics Systems), vol. 16, no. 1, p. 45, 2022, doi: 10.22146/ijccs.69617
-
[4] M. H. Rajput and B. R. Mandre, Abstractive Summarization of Document using Dual Encoding Framework, International Journal of Computer Applications, 2020, vol. 176, no. 39.
-
[5] P. Mehta and P. Majumder, From Extractive to Abstractive Summarization: A Journey, Springer, 2019.
-
[6] Yuliska and Syaliman, Literatur Review Terhadap Metode, Aplikasi dan Dataset Peringkasan Dokumen Teks Otomatis untuk Teks Berbahasa Indonesia, 2020, vol. 5, no. 1, pp. 19-31.
348
Discussion and feedback