Klasifikasi Penyakit Paru-Paru Berdasarkan Suara Paru-Paru Menggunakan Metode MFCC dan SVM
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana
Volume 11, No 3. February 2023
Klasifikasi Penyakit Paru-Paru Berdasarkan Suara Paru-Paru Menggunakan Metode MFCC dan SVM
Ni Putu Subhasini Dewi Sukmaa1, I Gede Arta Wibawaa2, I Gusti Ngurah Anom Cahyadi Putraa3, I Gusti Agung Gede Arya Kadyanana4, I Gede Santi Astawaa5, Agus Muliantaraa6
Program Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana Bukit Jimbaran, Badung, Bali, Indonesia 1subhadewi59@gmail.com
Abstract
The lungs are vital organs that function as a place for oxygen exchange. The lungs are one of the organs that have an important role for humans to survive. The importance of maintaining lung health to avoid dangerous diseases. If the health of the lungs is not taken care of properly, it will make the lungs unable to function normally and can cause disturbances in the respiratory system. The types of lung diseases that are suffered by many people in the world such as cough, asthma, bronchitis, tuberculosis, and so on. Therefore, this study will classify lung diseases based on lung sounds using the MFCC method which will be used at the feature extraction stage and the SVM method used at the data classification stage. The testing phase used is K-Fold Cross Validation and also Confusion Matrix to determine the amount of data that is identified correctly and to determine the level of accuracy generated. After going through several processes to classify the lungs based on the sound of the lungs, the accuracy rate is quite good, which is 80%.
Keywords: Classification, Lung Sound, Lung Disease, MFCC, SVM, Accuracy
Pada sistem pernafasan manusia terdapat beberapa macam organ penting yang bekerja dengan fungsinya masing-masing dalam proses pernafasan. Paru-paru merupakan bagian dari sistem pernafasan manusia yang bekerja sebagai tempat pertukaran oksigen. Bagi manusia kesehatan paru-paru sangat penting untuk diperhatikan dengan baik. Setiap orang perlu untuk mengetahui gejala penyakit paru-paru guna menghindari munculnya penyakit yang dapat membahayakan kesehatan manusia terutama kesehatan paru-paru sehingga dapat berakibat fatal bahkan hingga menyebabkan kematian.
Penyakit paru-paru adalah suatu kondisi yang menyebabkan paru-paru tidak dapat bekerja dengan baik atau normal. Gejala penyakit yang dianggap biasa saja ketika seseorang sedang mengalami kondisi seperti batuk berdahak, bau mulut, demam, berat badan turun, dan lainnya yang ada kemungkinan beberapa gejala yang disebutkan adalah tanda-tanda dari penyakit paru-paru [8]. Di kehidupan sehari-hari terdapat banyak yang menderita penyakit paru-paru seperti bronkitis, TBC, asma, hingga batuk serta demam. Adapun penyebab dari penyakit paru-paru seperti polusi udara, virus, bakteri, dan sebagainya [5].
Beberapa penyakit paru-paru memiliki indikasi yang sama, maka agar dapat mengetahui macam-macam penyakit yang dialami penderita, diperlukan seorang dokter yang ahli dalam ilmu kesehatan paru-paru. Seorang dokter dalam melakukan pemeriksaan pada seorang pasien biasanya menggunakan alat berupa stetoskop untuk mendengarkan suara pernafasan paru-paru. Suara paru-paru merupakan suatu informasi penting yang dibutuhkan oleh seorang dokter dalam menentukan tingkat kesehatan pernafasan seseorang [4].
Beberapa peneliti sebelumnya telah melakukan penelitian dengan mengembangkan berbagai metode dalam mendiagnosis penyakit paru-paru melalui suara paru-paru. Peneliti sebelumnya melakukan penelitian dengan menggunakan Autoencoder yang merupakan salah satu arsitektur DNN dan diuji oleh SVM untuk mengklasifikasi suara paru-paru yang normal dan abnormal menghasilkan tingkat
akurasi sejumlah 82,38% [1]. Terdapat penelitian yang melakukan pengelompokan suara paru-paru menggunakan CNN, di mana penelitian ini menyinggung data suara paru-paru yang berupa spektrogram suara paru-paru yang kemudian diklasifikasi dengan CNN yang memperoleh tingkat keakuratan yang didapat sejumlah 74% [7]. Sebuah penelitian menggunakan Probabilistic Neural Network dan SVM One Against All, SVM One Against One dalam membandingkan suara paru-paru yang normal dan abnormal dengan memperoleh tingkat keakuratan rata-rata SVM One against all sejumlah 47,55%, dengan tingkat ketepatan sejumlah 70%. Akurasi rata-rata SVM One Against One sejumlah 50.92%, dengan tingkat ketepatan sejumlah 75%. Akurasi rata-rata Probabilistic Neural Network sejumlah 70%, dengan tingkat ketepatan sejumlah 70% [3].
Pada penelitian ini berfokus untuk meneliti dan mencoba metode MFCC dan SVM untuk klasifikasi penyakit paru-paru berdasarkan suara paru-paru. Beberapa tahapan penelitian ini yaitu tahap akuisisi data, selanjutnya akan dilakukan tahap ekstraksi ciri menggunakan metode MFCC, kemudian mengklasifikasi data menggunakan metode SVM, dan dilakukan tahap pengujian dengan menggunakan K-Fold Cross Validation dan Matriks konfusi. Terakhir akan mendapatkan hasil berupa tingkat akurasi.
Dataset yang digunakan yaitu data sekunder yang didapat dari website ICBHI 2017. Dataset ini berisi file rekaman suara paru-paru dengan format .wav. Dataset tersebut diambil dari 126 subjek yang berisi rekaman suara paru-paru sebanyak 6898 siklus pernafasan, di mana dataset akan dibagi menjadi 2 yaitu data training dan data testing dengan proporsi data adalah 80:20.
Ekstraksi ciri merupakan proses yang digunakan untuk mengekstraksi ciri atau fitur dari suatu objek yang dapat membuat karakteristik dari objek tersebut. Pada tahap ekstraksi ciri menggunakan metode MFCC. MFCC merupakan metode yang digunakan untuk representasi fitur sinyal suara dalam bentuk angka [10].
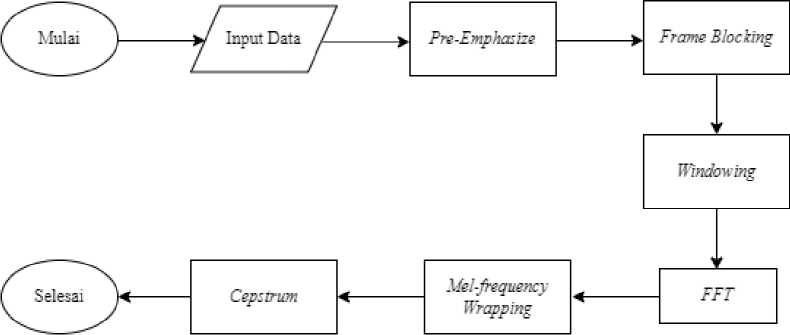
Gambar 1. Tahap Ekstraksi Ciri
Gambar 1 merupakan tahap ekstraksi ciri MFCC, di mana akan dilakukan beberapa tahap. Diawali dengan tahap pre-emphasize dilakukan untuk meningkatkan frekuensi tinggi pada spektrum. Selanjutnya tahap frame blocking dilakukan untuk memotong sinyal audio menjadi beberapa frame. Kemudian berikutnya tahap windowing dilakukan untuk meminimalisasi terjadinya efek diskontinuitas dari potongan-potongan sinyal. Dilanjutkan ke tahap FFT, di mana tahap ini dilakukan guna mengubah domain waktu sinyal ke domain frekuensi. Selanjutnya tahap mel-frequency wrapping dilakukan untuk penyaringan atau filter dari spectrum pada setiap frame. Tahap terakhir adalah tahap cepstrum dilakukan untuk mendapatkan koefisien MFCC dengan mengubah mel spectrum menjadi domain waktu.
Klasifikasi merupakan proses mendeteksi model yang mendeskripsikan dan memilah suatu kelas data yang bertujuan supaya model tersebut dapat berfungsi untuk memprediksi kelas objek yang label pada kelasnya tidak diketahui [7]. Pada tahap klasifikasi menggunakan metode SVM yang bertujuan untuk
mendapatkan hyperplane pemisah klaster data yang memaksimalkan margin antar support vector [2]. Data yang telah diperoleh fiturnya pada saat tahap ekstraksi ciri maka akan dilanjut ke tahap klasifikasi.
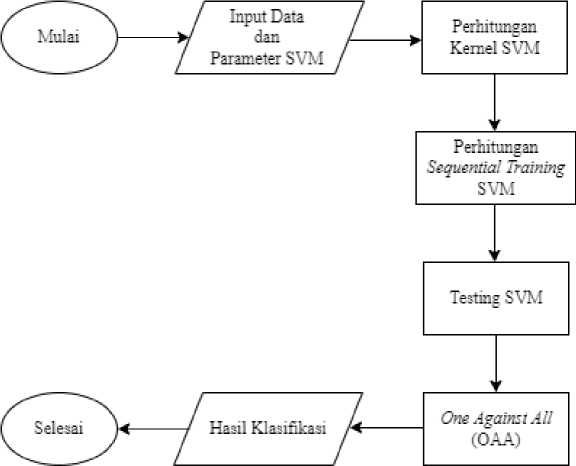
Gambar 2. Tahap Klasifikasi
Gambar 2 merupakan tahap klasifikasi SVM, di mana diawali dengan tahap menginput data dan menentukan parameter yang akan digunakan, pada penelitian ini menggunakan parameter Complexity C dan γ (gamma). Kemudian dilanjutkan dengan menghitung kernel SVM, di mana pada penelitian ini menggunakan kernel Radial Basis Function (RBF), Linear, dan Polynomial. Berikutnya dilakukan perhitungan Sequential Training SVM untuk proses training dan selanjutnya dilakukan proses testing SVM pada data uji. Kemudian dilakukan tahap one against all guna mengatasi permasalahan multi class. Terakhir akan mengeluarkan hasil klasifikasi.
Tahap pengujian menggunakan metode K-Fold Cross Validation yang bertujuan untuk mengukur ketepatan hasil analisis generalisasi pada dataset independent [6] dan Matriks konfusi merupakan metode yang diperlukan untuk mengukur akurasi dalam konsep data mining [9]. Pada tahap K-Fold Cross Validation akan dilakukan pembagian terhadap seluruh data menjadi beberapa bagian untuk testing dan training. Di mana pengujian akan dilakukan percobaan sebanyak 5 tahapan (5 Fold CV). Kemudian hasil dari 5 Fold Cross Validation ini akan dicatat nilai evaluasi performa dari model tersebut menggunakan Matriks Konfusi untuk dapat mengetahui jumlah data yang teridentifikasi benar serta mengetahui akurasi sistem tersebut.
Tabel 1. Matriks Konfusi
|
Matriks Konfusi |
Kelas Hasil Prediksi | ||
|
Positif |
Negatif | ||
|
Kelas Asli |
Positif |
TP |
FN |
|
Negatif |
FP |
TN | |
Adapun 4 output yang dihasilkan dari matriks ini yaitu recall, precission, f1-score dan accuracy. Rumus untuk menghitung 4 output tersebut dapat dilihat pada persamaan berikut.
F1 - score = - = - (--1— + ) × 100%
F1 2 Kpreci-Sioii recall/
Accuracy =
T P+T N
TP+FN+FP+TN
× 100%
(4)
Di mana,
TP (True Positive) = jumlah data positif yang tergolong benar TN (True Negative) = jumlah data negatif yang tergolong salah FP (False Positive) = jumlah data positif yang tergolong benar FN (False Negative) = jumlah data negatif yang tergolong salah
Penelitian ini menggunakan dataset rekaman suara paru-paru yang didapat dari website ICBHI 2017.
Rekaman suara paru-paru disimpan dalam format .wav.
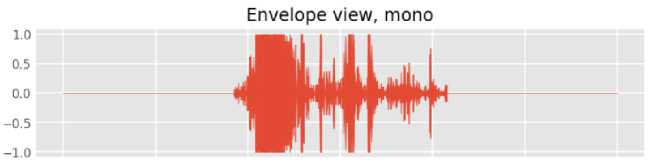
-
Gambar 3. Grafik Sinyal Suara Paru-Paru
Gambar 3 merupakan salah satu grafik sinyal suara paru-paru dari rekaman audio pada dataset. Data rekaman suara ini diperoleh dari 126 subjek yang berisi 6898 siklus pernafasan paru-paru. Di mana suara tersebut terbagi menjadi 1864 suara crackle, 886 suara wheeze, dan 506 gabungan dari suara crackle dan wheeze. Data akan dibagi menjadi data train dan data test dengan proporsi data train sejumlah 80% dan data test sejumlah 20%.
Kemudian dilakukan tahap ekstraksi ciri menggunakan Mel Frequency Cepstral Coefficient (MFCC) dengan hasil akhir berupa koefisien MFCC yang selanjutnya akan digunakan pada tahap klasifikasi. Tahap pertama dalam ekstraksi ciri MFCC ini dilakukan tahap pre-emphasize. Output dari tahap preemphasize dapat dilihat pada gambar 4.
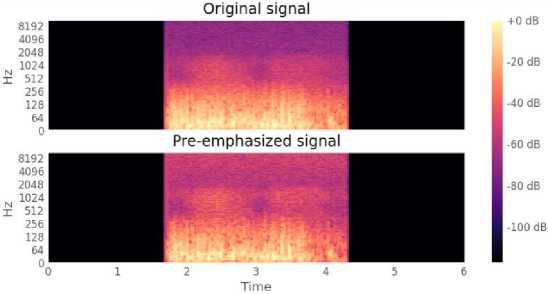
Gambar 4. Output Tahap Pre-Emphasize
Gambar 4 merupakan output dari tahap pre-emphasize guna meningkatkan energi sinyal pada frekuensi tinggi.
Tahap berikutnya yaitu tahap frame blocking, di mana sinyal suara akan disegmentasi mejadi beberapa frame yang kemudian akan dilanjutkan pada tahap windowing. Output dari tahap windowing dapat dilihat pada gambar 5.
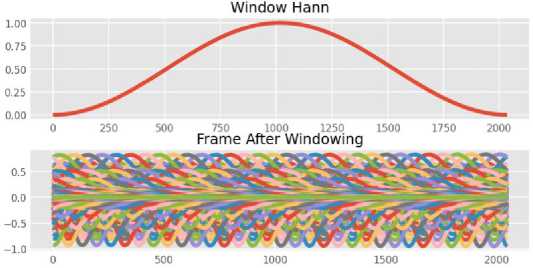
Gambar 5. Output Tahap Windowing
Gambar 5 merupakan output dari tahap windowing guna mengurangi atau meminimalisasi efek diskontinuitas dari potongan-potongan sinyal tersebut.
Selanjutnya adalah tahap FFT, di mana sinyal akan diubah dari domain waktu menjadi domain frekuensi. Setelah sinyal diubah ke dalam domain frekuensi, berikutnya akan masuk pada tahap mel-frequency wrapping. Output dari tahap mel-frequency wrapping dapat dilihat pada gambar 6.
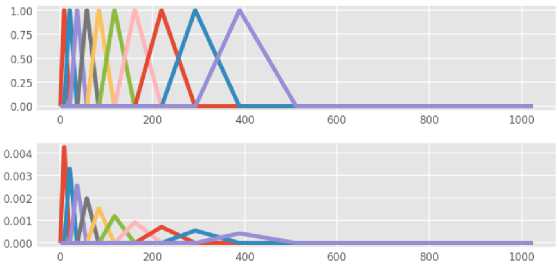
Gambar 6. Output Tahap Mel-Frequency Wrapping
Gambar 6 merupakan output dari tahap mel-frequency wrapping, di mana tahap ini pada umumnya menggunakan filterbank untuk penyaringan atau filter yang bertujuan untuk mengetahui energi dari frequency band.
Setelah melalui tahap mel-frequency wrapping, selanjutnya tahap terakhir yaitu tahap cepstrum. Output dari tahap cepstrum dapat dilihat pada gambar 7.
Time
Gambar 7. Output Tahap Cepstrum
Gambar 7 merupakan output dari tahap cepstrum yang bertujuan untuk mengubah mel spectrum menjadi domain waktu dengan tahap ini akan diperoleh koefisien MFCC.
Hasil akhir dari ekstraksi ciri MFCC tersebut selanjutnya akan diaplikasikan pada tahap klasifikasi. Selanjutnya mengklasifikasi data menggunakan metode SVM dan pengujian dari data menggunakan parameter yang telah ditentukan yaitu parameter Complexity C dan γ (gamma), serta terdapat 3 kernel yang digunalan yaitu RBF, Linear, dan Polynomial. Hasil training setiap parameter SVM dapat dilihat pada tabel 2.
Tabel 2. Hasil Training Parameter SVM
|
params |
split0_te st_score |
split1_te st_score |
split2_te st_score |
split3_te st_score |
split4_te st_score |
mean_te st_score |
std_tes t_score |
rank_te st_scor e |
|
{'SVM_ _C': 0.1, 'SVM__ gamma' : 1, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 10, 'SVM__ gamma' : 0.01, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 10, 'SVM__ gamma' : 0.1, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 10, 'SVM__ gamma' : 1, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 1, 'SVM__ gamma' : 0.001, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 100, 'SVM__ gamma' : 1, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 1, 'SVM__ gamma' : 0.01, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
|
{'SVM_ _C': 1, 'SVM__ gamma' : 0.1, 'SVM__ kernel': 'linear'} |
0.77083 3 |
0.82291 7 |
0.79166 7 |
0.79166 7 |
0.80729 2 |
0.79687 5 |
0.0174 3 |
1 |
Tabel 2 merupakan hasil training setiap parameter SVM. Pada tabel terdapat kolom params yang di mana berisi parameter yang digunakan, dengan nilai yang berbeda-beda dari setiap parameter. Kemudian pada kolom berikutnya terdapat split test score yang di mana berisi nilai hasil pengujian yang dilakukan menggunakan K-Fold Cross Validation dengan 5 kali iterasi. Pada kolom selanjutnya terdapat mean test score yang berisi nilai rata-rata dari split test score. Berikutnya terdapat kolom std test score merupakan nilai hasil standar deviasi dari model. Terakhir terdapat kolom rank test score yang merupakan hasil peringkat dari setiap parameter yang digunakan. Hasil training tersebut menunjukkan
parameter terbaik untuk SVM model yaitu parameter SVM__C : 0,1 , SVM__gamma : 1, serta
SVM__kernel : linear dengan mendapatkan score terbaik sebesar 0.7968749999999999.
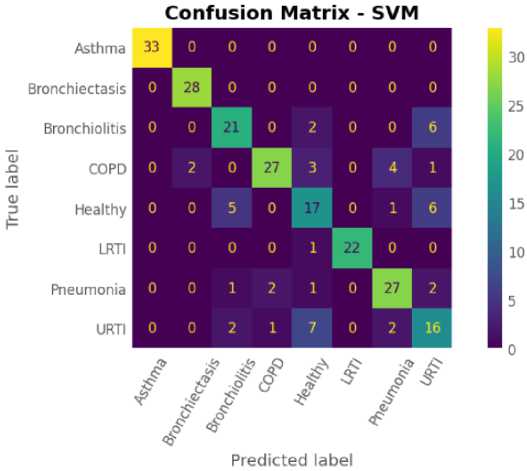
Gambar 8. Hasil Matriks Konfusi
Gambar 8 merupakan hasil tahap pengujian dengan Matriks Konfusi. Di mana dari hasil tersebut terlihat bahwa hasil yang terbanyak terdapat 33 data yang teridentifikasi benar dengan diagnosis asma dan beberapa diagnosis penyakit paru masih ada yang teridentifikasi salah dikarenakan hasil identifikasi dari beberapa data asli dengan hasil prediksi diagnosis masih terdapat ketidaksesuaian ciri-ciri dari beberapa penyakit yang diprediksi.
|
precision |
recall |
fl-score |
support | |
|
Asthma |
1.00 |
1.00 |
1.00 |
33 |
|
Bronchiectasis |
0.93 |
1.00 |
0.97 |
28 |
|
Bronchiolitis |
0.72 |
0.72 |
0.72 |
29 |
|
COPD |
0.90 |
0.73 |
0.81 |
37 |
|
Healthy |
0.55 |
0.59 |
0.57 |
29 |
|
LRTI |
1.00 |
0.96 |
0.98 |
23 |
|
Pneumonia |
0.79 |
0.82 |
0.81 |
33 |
|
URTI |
0.52 |
0.57 |
0.54 |
28 |
|
accuracy |
0.80 |
240 | ||
|
macro avg |
0.80 |
0.80 |
0.80 |
240 |
|
weighted avg |
0.80 |
0.80 |
0.80 |
240 |
Gambar 9. Hasil Akurasi
Gambar 9 merupakan hasil akurasi dari klasifikasi paru-paru berdasarkan suara paru-paru menggunakan metode MFCC dan SVM dengan memperoleh tingkat akurasi sebesar 80%. Pada masing-masing diagnosis penyakit paru-paru memperoleh hasil yang berbeda-beda, di mana diagnosis penyakit asma memperoleh hasil tertinggi sebesar 100%.
Pada penelitian yang telah dilakukan dapat disimpulkan bahwa penelitian dengan menggunakan metode MFCC dan SVM untuk mengklasifikasi penyakit paru-paru berdasarkan suara paru-paru memperoleh hasil yang cukup baik setelah melalui beberapa proses dengan tingkat akurasi yang dihasilkan yaitu sebesar 80%.
Daftar Pustaka
-
[1] A. H. Falah dan Jondri, “Klasifikasi Suara Paru Normal Dan Abnormal Menggunakan Deep Neural Network dan Support Vector Machine”, e-Proceeding of Engineering, vol. 6, no.1, hlm. 2451 – 2459, April 2019.
-
[2] A. R. Isnain, A. I. Sakti, D. Alita dan N. S. Marga, “SENTIMEN ANALISIS PUBLIK TERHADAP KEBIJAKAN LOCKDOWN PEMERINTAH JAKARTA MENGGUNAKAN ALGORITMA SVM”, JDMSI, vo. 2, no. 1, hlm. 31 – 37, 2021.
-
[3] C. Aridela, A. Rizal, dan Y. S. Hariyani, “PERBANDINGAN SUARA PARU NORMAL DAN ABNORMAL MENGGUNAKAN PROBABILISTIC NEURAL NETWORK DAN SUPPORT VECTOR MACHINE”, e-Proceeding of Engineering, vol. 4, no. 1, hlm. 165 – 172, April 2017.
-
[4] D. S. Wiradikusuma, J. Jondri dan A. Rizal, “Klasifikasi Suara Paru-Paru menggunakan Jaringan Syaraf Tiruan dan Wavelet Transform”, e-Proceeding of Engineering, vol. 8, no. 2, hlm. 3224 – 3231, April 2021.
-
[5] E. R. Ritonga dan M. D. Irawan, “SISTEM PAKAR DIAGNOSA PENYAKIT PARU-PARU PADA ANAK DENGAN METODE DEMPSTER-SHAFER”, CESS (Journal Of Computer Engineering, System And Science), vol. 2, no. 1, hlm. 39 – 47, Januari 2017.
-
[6] F. Rabani, Jondri dan A. Rizal, “Klasifikasi Suara Paru Normal dan Abnormal Menggunakan Ekstraksi Fitur Discrete Wavelet Transform dengan Klasifikasi Menggunakan Jaringan Saraf Tiruan yang Dioptimasi dengan Algoritma Genetika”, Jurnal ELEMENTER, vol. 7, no. 1, hlm. 20 – 34, Mei 2021.
-
[7] I. H. Wafii, Drs. Jondri dan Dr. A. Rizal, “Klasifikasi Suara Paru-Paru Menggunakan Convolutional Neural Network (CNN)”, e-Proceeding of Engineering, vol. 8, no. 2, hlm. 3218 – 3223, April 2021.
-
[8] Karimah, Z. I. Nikmah, S. K. Aditya dan E. G. Wahyuni, “Aplikasi Web Untuk Pendeteksi Penyakit Paru – Paru Menggunakan Metode Certainty Factor”, Seminar Nasional Informatika Medis (SNIMed), hlm. 86 – 91, 2019.
-
[9] M. F. Rahman, M. I. Darmawidjadja dan D. Alamsah, “KLASIFIKASI UNTUK DIAGNOSA DIABETES MENGGUNAKAN METODE BAYESIAN REGULARIZATION NEURAL NETWORK (RBNN)”, JURNAL INFORMATIKA, vol. 11, no. 1, hlm. 36 – 45, Januari 2017.
-
[10]
. A. Sadewa, T. A. Budi W dan S. Sa’adah, “IMPLEMENTASISPEAKER RECOGNITIONUNTUKOTENTIKASI MENGGUNAKAN MODIFIED MFCC–VECTOR
QUANTIZATIONALGORITMA LBG”, e-Proceeding of Engineering, vol. 2, no. 1, hlm. 1453 – 1463, April 2015.
This page is intentionally left blank.
562
Discussion and feedback