Penerapan Metode MFCC dan Naive Bayes untuk Deteksi Suara Paru-Paru
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana Volume 11, No 1. August 2022
Penerapan Metode MFCC dan Naive Bayes untuk Deteksi Suara Paru-Paru
Ni Made Ayu Suandewi a1, I Gede Arta Wibawa a2, I Gusti Ngurah Anom Cahyadi a3, I Komang Ari Mogi a4Ngurah Agus Sanjaya ER a5, Cokorda Rai Adi Pramartha a6
aProgram Studi Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana
Badung, Bali, Indonesia 1suandewi72@gmail.com 2 gede.arta@unud.ac.id 3 anom.cp@unud.ac.id 4 arimogi@unud.ac.id 5 agus_sanjaya@unud.ac.id 6 cokorda@unud.ac.id
Abstract
Lung disease is an unpleasant illness that can be dangerous if not treated properly. This is because lung disease can infect others. The lungs are an important part of the human organ that distributes oxygen throughout the body, so this lung disease needs to be treated with proper procedures. Lung disease problems can be solved using an expert system. Expert systems can help doctors work to provide an early diagnosis of ear diseases. The method used in this study is the MFCC method, which provides compelling information about lung disease and provides treatment solutions based on the symptoms of each existing disease. This system is performed by calculating the symptom weights of the disease, which is obtained from expert experience, and produces the optimum value in the form of the maximum value. The highest value data provides the results of the disease diagnosis at the level of confidence in the form of percentage values. Based on the test results, the goodness of fit between the system diagnostics using the system validation test method and the expert diagnostic results is 90%. The results of the tests performed show that the system is operating normally according to its capabilities.
KeyWords: MFCC, Lung Health, Machine Learning
Paru-paru merupakan salah satu organ tubuh yang sangat vital bagi manusia yang berperan dalam sistem pernapasan karena dapat memenuhi kebutuhan oksigen tubuh. Jika terjadi sebuah gangguan pada paru – paru dapat menyebabkan kecacatan hingga kematian [1]. Banyak orang di seluruh dunia menderita kerusakan paru-paru dan sering mengalami kecacatan, yang bahkan dapat menyebabkan kematian pasiennya. Diperkirakan ratusan ribu hingga jutaan orang di seluruh dunia menderita penyakit paru-paru setiap tahun, menyebabkan 19% kematian dan 15% cacat seumur hidup di seluruh dunia (FIRS2010).
Penemuan mengenai gangguan pada paru-paru biasanya dimiliki oleh dokter dengan melakukan diagnosa apakah paru-paru seseorang normal atau abnormal[2]. Untuk mendapatkan perawatan yang tepat, Anda perlu tahu persis apa yang dilakukan paru-paru Anda. Orang dengan penyakit saluran napas kronis membutuhkan perangkat yang dapat mendeteksi kondisi paru-paru secara real time. Penelitian ini berfokus pada kajian dan uji coba metode naive bayesian yang dimodifikasi dalam menentukan kondisi paru-paru seseorang.
Penelitian sebelumnya mengenai gangguan paru-paru menggunakan metode Convolutional Neural Network (NFCC) untuk melakukan klasifikasi suara paru-paru untuk mengetahui sebuah paru-paru apakah dalam keadaan normal atau tidak. Klasifikasi suara paru-paru dikelompokkan dalam 3 jenis suara yaitu normal, crackel, wheeze, dan crackel-wheeze/both. Hasil akhir yang
Suandewi, dkk.
Penerapan Metode MFCC dan Naive Bayes untuk Deteksi Suara Paru-Paru didapatkan untuk akurasi dari masing-masing class sebesar 74% dari seluruh dataset yang diuji [2].
Penelitian lainnya juga membahas mengenai pengenalan suara paru-paru dengan metode MFCC. Pada penelitian ini dilakukan klasifikasi suara paru-paru normal dan abnormal dengan MFCC sebagai ekstraksi ciri dan Backpropagation sebagai metode pengelompokannya dengan menghitung Coeffiesient Ceptral dari suara paru-paru. Hasil akhir yang didapatkan untuk hasil klasifikasi dengan akurasi yang diperoleh sebesar 93,97% untuk data latih dan 92,66% untuk data uji [1].
Langkah-langkah yang dilakukan dalam penelitian ini adalah pengolahan data paru, ekstraksi ciri, dan klasifikasi. Langkah yang digunakan untuk mendeteksi kondisi paru-paru pada penelitian ini adalah file audio yang pertama. wav melakukan langkah pra-pemrosesan yang terdiri dari normalisasi data, pengurangan kebisingan dan penghilangan keheningan. Data tersebut terdiri dari ekstraksi fitur seperti Premphasize, frame blocking, windowing, fast folia conversion, mel frequency wrapping, mel frequency wrapping, dan DCT (discrete cosine transform). Mendapatkan nilai koefisien yang diproses oleh proses klasifikasi naive bay yang dimodifikasi oleh proses ini.
Untuk mendukung penelitian yang dilakukan, melakukan kajian terhadap penelitian sebelumnya sangat penting dilakukan dan merupakan kebutuhan bagi peneliti yang menjadikan penelitian sebelumnya sebuah acuan untuk kedepannya. Salah satu penelitian mengungkapkan bahwa pengenalan suara paru-paru dapat membantu dokter dalam mengenali suara paru-paru normal dengan penelitian yang dilakukan menggunakan metode LPC dan JST di mana suara paru-paru dianggap sebagai speech dan menghitung koefisien LPC. Akurasi yang didapatkan dengan JST yaitu 100% [3].
Penelitian lain juga dilakukan mengenai analisa kelainan suara paru-paru menggunakan media android sebagai media implementasi yang merupakan pembaharuan dari teknik auskultasi yang dilakukan oleh dokter dengan hasilnya adalah menampilkan suara paru-paru saat ekspirasi dan inspirasi [4].
Pada penelitian ini, data yang digunakan adalah data sekunder yang didapatkan melalui website ICBHI dengan jumlah data latih sebanyak 3000 data dan data uji sebanyak 300 data dengan pembagian kelas sebanyak 4 kelas yakni wheeze, Tracheal, Vesicular, dan Crackle.
-
2.2 Preprocessing
Processing adalah proses yang bertujuan memperbaiki rekaman suara input agar menghasilkan sinyal suararekaman yang baik, pada penelitian ini proses preprocessing terbagai menjadi 3 tahap yaitu normalisasi data,silence removal dan noice reduction.pada tahap normalisasi merupakan melakukan penyetaraan amplitude setiap sinyal yang terekam.setelah dilakukan normalisasi,setiap sampel rekaman suara yang terbentuk pasti mengandung daeran silence.oleh karena itu tahap kedua pada proses preprocessing yaitu silence removal dimana sinyal suara yang merupakan silence akan dihilangkan.selanjutnya tahap noise reduction merupakan prose untuk mengurangi besar noise pada sinyal suara input.hasil dari proses preprocessing ini adalah sinyal suara yang tidak memiliki noise dan silence.flowchart proses preprocessing ini dapat dilihat pada gambar 1.
Jurnal Elektronik Ilmu Komputer Udayana Volume 11, No 1. August 2022
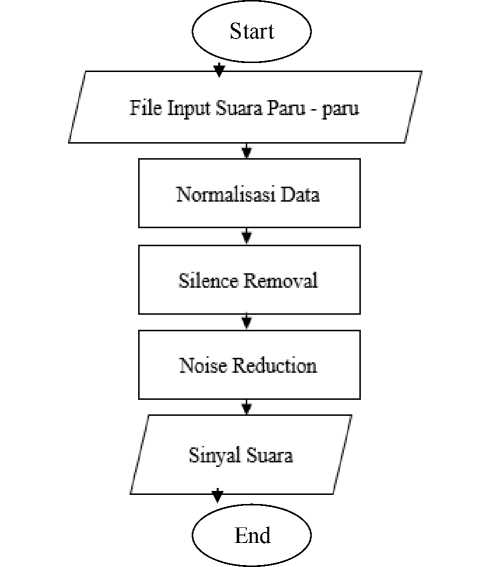
Gambar 1. Gambar Proses Preprocessing
-
2.3 Ekstraksi Fitur
Setelah pretreatment untuk ekstraksi ciri, digunakan metode MFCC.Ini dilakukan dalam beberapa tahap: pre-emphasis, frame blocking, windowing, dan Fast Fourier Transform (FFT). Pembungkus frekuensi mel, dan transformasi kosinus diskrit DCT. Pada tahap pertama, preemphasis dilakukan untuk meningkatkan frekuensi tinggi untuk meningkatkan akurasi ketika ekstraksi fitur diperoleh. Selanjutnya, tahap frame blocking dimana sinyal audio tersegmentasi menjadi beberapa frame. Pada tahap ini, efek sinyal terputus-putus terjadi. Tahap pemrosesan jendela dijalankan untuk meminimalkan diskontinuitas sinyal pada awal dan akhir setiap frame. Kemudian dilanjutkan ke tahap FFT. Tahap ini menerjemahkan dari domain waktu ke domain frekuensi setiap N frame sampel. Setelah data dikonversi ke domain frekuensi, langkah selanjutnya adalah pembungkusan frekuensi mel. Di sini, sinyal diplot terhadap spektrum mel, meniru pendengaran manusia. Selanjutnya, langkah terakhir adalah transformasi cosinus diskrit. Ini adalah tahap mengubah spektrum mel menjadi domain waktu yang digunakan untuk mendapatkan koefisien. Koefisien cepstrum frekuensi Mel (MFCC). Proses ekstraksi fitur dapat dilihat pada gambar 2 untuk memperoleh Discrete Courier Transform.
Suandewi, dkk.
Penerapan Metode MFCC dan Naive Bayes untuk Deteksi Suara Paru-Paru
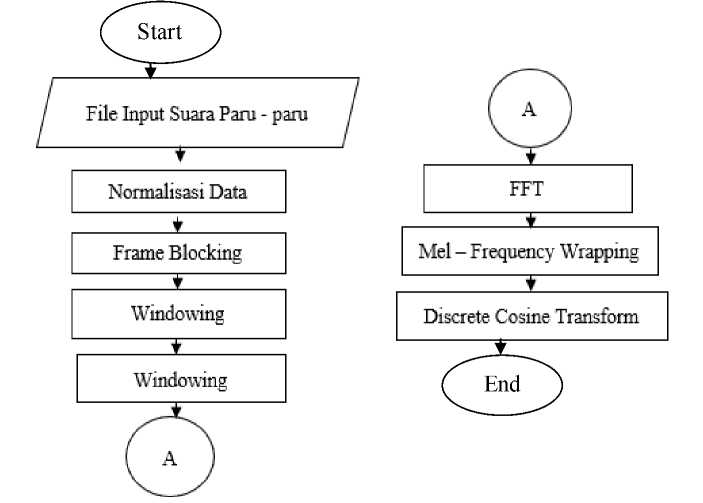
Gambar 2 . Proses Ekstraksi MFCC suara data latih paru paru
-
2.4 Klasfikasi
Pada proses klasifikasi Naïve Bayes yang dimodifikasi, data fitur yang dihasilkan oleh proses ekstraksi fitur akan menjadi nilai input untuk proses klasifikasi ini. Klasifikasi Naïve Bayes memiliki dua proses tambahan: proses validitas data-ke-data. Bobot voting data sampel audio yang digunakan dalam proses pelatihan meningkatkan tingkat keberhasilan sistem ini dalam klasifikasi. Sebaliknya, semakin sedikit data sampel audio yang digunakan dalam proses pelatihan, semakin rendah tingkat kesalahan atau kesalahan klasifikasi. Kemudian normalkan data latih dan uji untuk mengurangi jarak antar data. Kemudian hitung jarak terakreditasi antara data pelatihan dan validasi setiap data pelatihan. Selanjutnya menghitung nilai validitas yang diperoleh dari perhitungan jarak adhesi antar data latih. Kemudian menghitung jarak koneksi antara data latih dengan data uji dan nilai yang diolah dengan proses pembobotan. Memilih. Setelah mendapatkan nilai dari perhitungan jarak inklusi antara data latih dan data uji, maka dilakukan proses voting bobot. Proses pembobotan diambil dari perhitungan jarak inklusi antara data latih dengan data uji dan validitas data latih, yaitu nilai maksimum yang diperoleh untuk menentukan kelas klasifikasi. Proses klasifikasi dapat dilihat pada gambar 3.
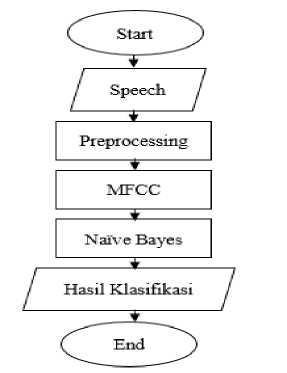
Gambar 3. Diagram alir proses klasifikasi
Jurnal Elektronik Ilmu Komputer Udayana Volume 11, No 1. August 2022
Bagian pengujian ini dilakukan dengan menggunakan K-Fold Cross Validation. Di sini, semua data yang digunakan dibagi menjadi beberapa bagian untuk pengujian dan beberapa untuk pelatihan. Proses ini dijalankan beberapa kali dengan menggabungkan dataset yang berbeda. Tes dijalankan menggunakan validasi silang 5 kali lipat. Ini berarti menjalankan eksperimen 5 kali secara bertahap. Pada percobaan pertama, kami membuat partisi pertama untuk data pengujian dan partisi lainnya untuk data pelatihan. Pada percobaan kedua, partisi kedua digunakan sebagai data uji dan partisi lainnya digunakan sebagai data latih. Pada percobaan ketiga, kami membuat partisi ketiga untuk data uji dan partisi lain untuk data pelatihan. Dari kelima hasil eksperimen tersebut, nilai evaluasi kinerja model dicatat dengan menggunakan matriks konfusi yang dapat menentukan jumlah data yang teridentifikasi dengan benar dan menghitung keakuratan sistem yang dibuat. Untuk mencoba atau menguji metode klasifikasi saat melakukan pembelajaran mesin, Anda memerlukan sistem validasi yang digunakan untuk memvalidasi data yang diprediksi oleh mesin. Hitung apakah prediksi tersebut benar atau salah, dan seberapa akurat prediksi tersebut dari model dan kumpulan data yang ada (Chandra et al, 2020). Pada tahap ini digunakan metode confusion matrix untuk menghitung tingkat akurasi.
Table 1. Confussion Matrix
|
TrueLabel |
Kelas hasil matriks | ||
|
positif |
negatif | ||
|
positif |
TP |
FN | |
|
negatif |
FP |
TN | |
Dalam menentukan akurasi terdapat 3 rumus yang digunakan adalahakurasi, precision, dan recall dimana dapat dilihat dibawah persamaan ini
TP+ TN
(1)
Akurasi = ———————x 100% TP+ FN+ FP + TN
Akurasi = τp + pp x 100% (2)
TP
Akurasi = Tp + pN x 100% (3)
Dimana:
TP(True Positives) = jumlah objek positif yang benar diklasifikasikan TN(True Negatif) = Jumlah objek negative yang salah diklasifikasikan FP(False Positives) =jumlah objek negative yang benar diklasifikasikan FN(False Negatives) = jumlah objek positif yang salah diklasifikasikan
Sebanyak 80% dari total data digunakan pada tahap pelatihan dan validasi. Beberapa Aplikasi yang telah dirancang dan diimplementasikan berbasis sistem yang memungkinkan dalam menampilkan data yang berbentuk audio, dimana frontend serta backend utama aplikasi ini dikembangkan berbasis web dengan penggunaan Bahasa pemrograman phyton, Penggunaan Bahasa pemrograman phyton dalam pembuatan sistem kemudian dilakukan ekstraksi data yang bertujuan untuk mempermudah dalam mengatasi noise pada inputan audio data suara paru paru yang di ambil melalui web penyedia data suara yang merupakan web free service. Pembuatan sistem juga menggunakan algoritma MFCC, Mel Frequency Cepstrum Coefficients digunakan sebagai fitur dari klip suara. MFCC banyak digunakan dalam sistem pengenalan suara. Mereka
Suandewi, dkk.
Penerapan Metode MFCC dan Naive Bayes untuk Deteksi Suara Paru-Paru juga digunakan secara luas dalam pekerjaan sebelumnya pada deteksi suara pernapasan tambahan karena mereka menyediakan ukuran spektrum daya jangka pendek dari sinyal domain waktu. Baik konten frekuensi maupun waktu penting untuk membedakan antara suara tambahan yang berbeda, karena suara tambahan yang berbeda dapat ada dalam satu klip pada periode waktu yang berbeda dan durasinya berbeda. Oleh karena itu, MFCC sangat membantu dalam menangkap perubahan konten frekuensi sinyal dari waktu ke waktu. Frekuensi ditempatkan pada skala mel, yang merupakan skala frekuensi nonlinier yang jaraknya dianggap sama oleh sistem pendengaran manusia. Keluaran MFCC berupa vektor fitur 2 dimensi (waktu dan frekuensi), yang kemudian diratakan menjadi larik satu dimensi sebelum diproses lebih lanjut. Proses penghitungan MFCC dapat dilihat pada gambar 4.
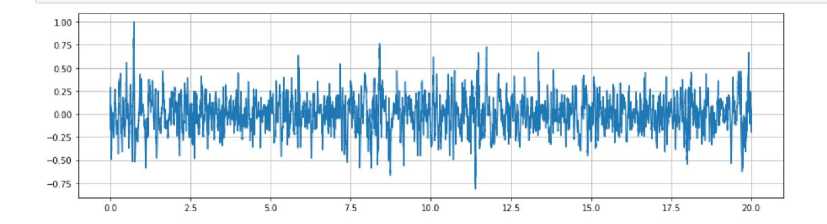
Gambar 4. Tampilan MFCC
Berdasarkan gambar 4, audio paru-paru memiliki durasi 20 detik dengan amplitude maksimal dari suara paru-paru adalah 1.00. Hasil MFCC memudahkan membaca fitur yang ada pada file audio dan memudahkan dalam melakukan audio windowing untuk mencari suara paru-paru tanpa adanya suara tambahan lainnya. Hasil dari penelitian ini adalah hasil pengujian akurasi MFCC terhadap penentuan hasil prediksi paru-paru. Berdasarkan hasil yang didapatkan, dari proses pengujian akurasi MFCC diperoleh dua buah analisa yang dirangkum dari proses pengujian serta dari hasil pengujian yang didapatkan, berikut merupakan analisa yang dirangkum dari pengujian pada penelitian ini :
Pertama dari observasi awal terhadap interaksi audio selama proses pengambilan data dan pengujian, kelima responden anak menunjukan interaksi yang berbeda – beda , dimana masing – masing anak tersebut menunjukan tingkat antusias dan terutama rasa ingin tahu yang tinggi ketika diminta menggunakan aplikasi saat proses pengambilan data maupun pengujian, dimana secara keseluruhan kelima audio tersebut memberikan respons yang positif selama kedua proses tersebut dan terutama terhadap sistem.
-
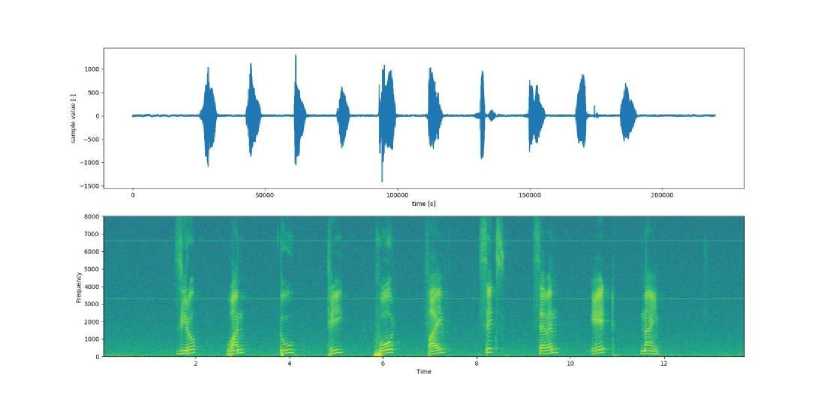
Gambar 5. Tampilan Audio Windowing
Pada gambar 5, merupakan hasil dari proses windowing yang hanya memetakan suara paru-paru dengan melihat amplitude pada proses MFCC sebelumnya dan pada proses windowing
Jurnal Elektronik Ilmu Komputer Udayana Volume 11, No 1. August 2022
merupakan tahapan untuk mengidentifikasi apakah inputan suara sudah dapat di input pada sistem atau masih perlu adanya tahapan lain, tahapan ini bertujuan untuk mengetahui inputan audio melalui pengecekan audio suara paru-paru serta hasil dari proses windowing.
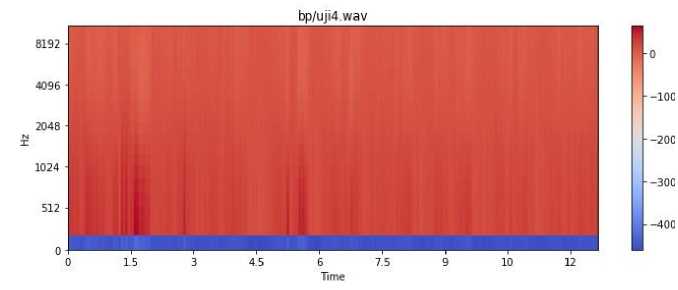
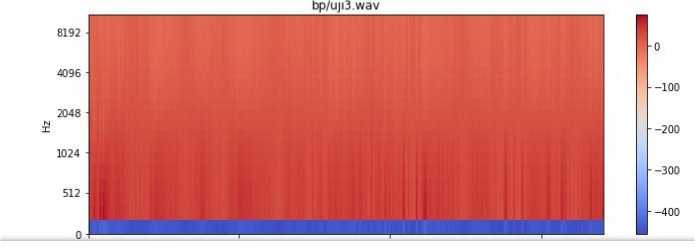
Gambar 6. Iterasi MFCC
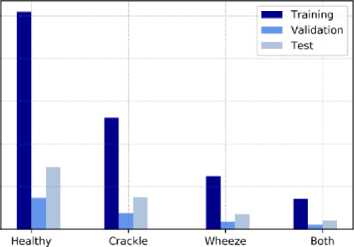
Kedua, berdasarkan hasil pengujian tingkat akurasi yang diperoleh, jika rata-rata tingkat akurasi audio adalah 88% secara keseluruhan, maka kesamaan minimum yang digunakan adalah pengenalan karakter yang diperoleh dalam penelitian ini. ketepatan. Berdasarkan kedua analisis tersebut, dapat disimpulkan bahwa hasil yang diperoleh adalah metode MFCC yang melebihi tingkat akurasi yang diharapkan yang dapat dilihat pada gambar 7.
Class Distribution of the Dataset 2500 2000 * 1500 U 1000 500 0
Class
-
Gambar 7. Hasil Pengujian
Pada gambar 7, merupakan tampilan hasil dari pengujian di mana setiap class dilakukan data training dan data testing yang menunjukkan bahwa class healthy memiliki data sebanyak 500 hingga 1000 data suara paru-paru termasuk ke dalam class healthy kurang dari 500 termasuk class crackel. Sehingga hasil akurasi dapat dikatakan sangat baik dengan nilai akurasi yang
Suandewi, dkk.
Penerapan Metode MFCC dan Naive Bayes untuk Deteksi Suara Paru-Paru diperoleh sebesar 88%.
Sistem prediksi suara paru-paru menggunakan MFCC dan Naïve Bayes dalam melakukan proses dan output keadaan paru-paru menggunakan audio sebagai media melakukan prediksi dapat dilakukan dengan baik melalui beberapa proses iterasi dan proses normalisasi. Akurasi sistem prediksi paru-paru menggunakan MFCC dan Naïve bayes menggunakan metode uji dan data latih yang telah di sediakan.
REFERENSI
-
[1] F. Syafria, A. Buono, and B. P. Silalahi, “Pengenalan Suara Paru-Paru dengan MFCC sebagai Ekstraksi Ciri dan Backpropagation sebagai Classifier,” J. Ilmu Komput. dan Agri-Informatika, vol. 3, no. 1, p. 27, 2017, doi: 10.29244/jika.3.1.27-36.
-
[2] I. W. Hasanain and A. Rizal, “Klasifikasi Suara Paru-Paru Menggunakan Convolutional Neural Network (CNN),” e-Proceeding Eng., vol. 8, no. 2, pp. 3218–3223, 2021.
-
[3] A. Rizal, L. Anggraeni, and V. Suryani, “Pengenalan Suara Paru-Paru Normal Menggunakan LPC dan Jaringan Syaraf Tiruan Back-Propagation,” Preceeding Int. Semin. Electr. Power, Electron. Commun. Control. Informatics ( EECCIS 2006 ), pp. 6– 10, 2006.
-
[4] D. Kurniawan, “Rancang Bangun Alat Deteksi Suara Paru-Paru Untuk Menganalisa Kelainan Paru-Paru Berbasis Android,” Elinvo (Electronics, Informatics, Vocat. Educ., vol. 2, no. 2, pp. 156–168, 2017, doi: 10.21831/elinvo.v2i2.17309.
-
[5] D. Ilmu and F. Ugm, “Klasifikasi Suara Paru-Paru Berdasarkan Ciri MFCC,” no. x, pp. 1– 12, 2012, doi: 10.22146/ijeis.xxxx.
-
[6] F. Ramadhana, F. Fauziah, and W. Winarsih, “Aplikasi Sistem Pakar untuk Mendiagnosa Penyakit ISPA menggunakan Metode Naive Bayes Berbasis Website,” STRING (Satuan Tulisan Ris. dan Inov. Teknol., vol. 4, no. 3, p. 320, 2020, doi: 10.30998/string.v4i3.5441.
-
[7] A. Wijayanto and P. J. R, “Deteksi Kelainan Parenkim Paru Berdasarkan Power Spectra Density Suara Paru Dengan Metode Welch,” vol. 2011, no. Ies, pp. 978–979, 2011.
82
Discussion and feedback