Comparison of Use of Music Content (Tempo) and User Context (Mood) Features On Classification of Music Genre
on
p-ISSN: 2301-5373
e-ISSN: 2654-5101
Jurnal Elektronik Ilmu Komputer Udayana
Volume 8, No 2. November 2019
Comparison of Use of Music Content (Tempo) and User Context (Mood) Features on Classification of Music Genre
Putu Rikky Mahendra Prasetyaa1, Gst. Ayu Vida Mastrika Giria2
aInformatics Department, Udayana University Bali, Indonesia
Abstract
The development of technology in the current era in the field of multimedia, music is not just entertainment or pleasure. Nowadays, online music growth is greatly increasing, namely, music can be classified by genre. The music genre is the grouping of music according to their resemblance to each other. In previous studies, the system was built with Naive Bayes Classifier which is useful for predicting songs based on the lyrics of the song. In our study, we used a dataset that was divided into several genera, namely Blues, Electronic, R & B, Christian, Hip Hop / Rap, Rock, Country, Jazz, Ska, Dance, Pop, and Soul which obtained the accuracy of Music Content of 45 % while for Context Users get an accuracy of 60%.
Keywords : Genre, Naive Bayes, Music Content, User Context
-
1. Introduction
The development of technology in the field of multimedia has made music and singing grow very rapidly. Music and Singing are now often used as entertainment media and even become a supporting media in the learning process.
According to Wikipedia "music is sound composed in such a way that it contains rhythm, song, and harmony, especially sound produced from tools that can produce rhythm", whereas according to the large Indonesian dictionary "music is science or art arrange tones or sounds in sequence, combination and temporal relationship to produce a composition (sound) that has unity and continuity ".
In this era, music is not only used as entertainment or pleasure but has been used for various purposes due to its social and physiological effects. Nowadays the growth of online music information is greatly increased.
Automatic and accurate music processing will be an issue/topic that is very important to be of particular concern.
Music can be classified by genre. A music genre is a grouping of music according to their similarities with each other. Music can also be classified according to other criteria, such as geography. A genre can be defined by music technique, style, context, and theme of music.
The most popular topic at this time in the search for automatic music information is the problem of organizing and grouping music according to its genre. The following are some research related to the topic.
In this study, the system was built with the Naive Bayes classifier which is useful for predicting song sentiments based on the song's lyrics alone. The experimental results show that music that suits a happy mood can be detected with high precision based on text features obtained from song lyrics (Sebastian Raschka, 2014).
In addition to song lyrics, some features can be taken from music, the feature is divided into two parts, namely based on user or user context and features that already exist in the music itself or music content.
In this study, we compared the use of two features, namely tempo representing music content and mood representing user context.
Tempo is the speed of playing a piece of music. It is usually represented by beats per minute (BPM). In brief, we calculate it by counting the number of beats for playing the music per minute. (M. F. McKinney, 2004).
Mood is a relatively long-lasting emotional state. Moods differ from emotions in that they are less specific, less intense, and less likely to be triggered by a particular stimulus or event (Thayer, Robert E, 1998)
Researchers show that humans are not only able to recognize the emotional intentions used by musicians but also feel them. When we listen to various music we normally tend to experience a change in blood pressure, heartbeat rate, etc. (P. N. Juslin, 2003)
-
2. Research methods
In conducting this research, defining several needs is as follows:
Here we use a dataset that we took from the Kaggle website, where the dataset we use is in the form of data from music content and music context which will later become a comparison feature in this paper.
We took 200 data, of which 10% were testing data and the rest were training data. The following is a diagram of all the datasets used:
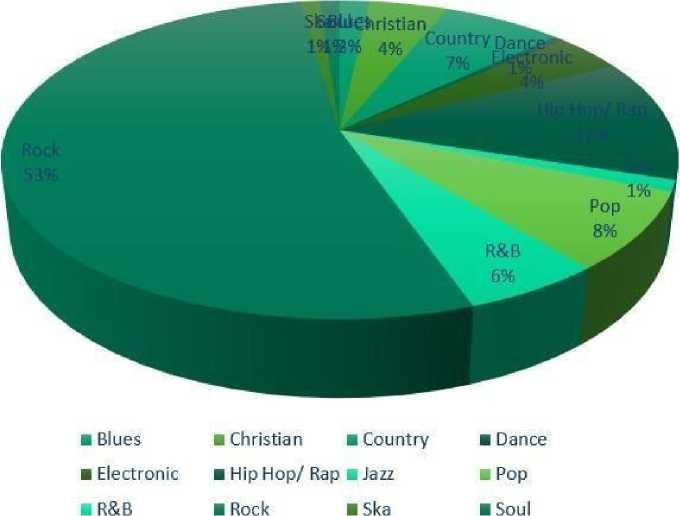
Figure 1. Dataset Diagram
All datasets used have several genres as shown in the picture above, with a different percentage.
Python is a high-level programming language that is interpreted, interactive, object-oriented and can operate on almost all platforms, such as UNIX, Mac, Windows, and others. As a high-level language, Python is one of the easy programming languages to learn because of its clear and
elegant syntax, combined with the use of ready-made modules and high-level data structures that are efficient. (Dewi Rosmala, 2012).
The Naive Bayes classification is a simple probabilistic classifier based on the application of the Bayes theorem with strong independent assumptions.
There are various Classifier text methods such as Decision Trees, Neural Networks, Naïve Bayes and Centroid Based, but Naïve Bayes perform better for different data collection and are easily done computationally. (Gurneet Kaur, 2014).
This technique is a probabilistic classification based on the Bayes theorem with the assumption of independence among the predictor variables. Simply put, the Naïve Bayes grouping assumes that there are certain features in a class that is not related to other features. Bayes's theorem provides a way to calculate the posterior probability P (C | x) of P (C), P (x) and P (x| C) with the following equation:
P(C)p(x | C) p(x)
P(C | x) =
P (c | x) is the posterior probability of the class (c, target) given the predictor (x, (Choirul Anam, 2018) attribute).
P (c) is the probability of the previous class.
P (x | c) is a probability which is the probability of the class given the predictor. P(x) is the probability of the previous predictor. (Choirul Anam, 2018).
-
3. Experiments and results
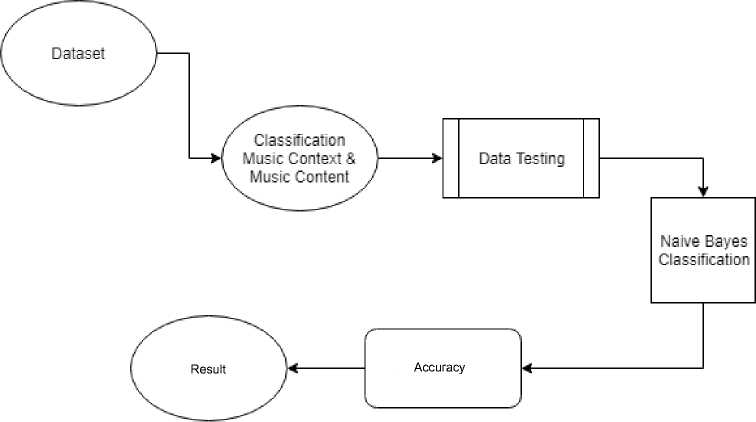
Figure 2. System Architecture
In conducting this research, we conducted several experiments to be able to compare the accuracy of the use of these features.
In this section, the testing data for each feature is processed using the naïve Bayes classifier. The following is the data testing table:
-
3.2. Result
Table 3. Data Testing User Context Result
|
Artist |
Mood |
Genre |
Status |
|
4Him |
happy |
Christian |
1 |
|
Vitamin C |
happy |
Pop |
1 |
|
K's Choice |
sad |
Rock |
1 |
|
Rickie Lee Jones |
sad |
Jazz |
0 |
|
Ronnie Milsap |
sad |
Country |
1 |
|
Goldfinger |
sad |
Rock |
1 |
|
Utopia |
happy |
Electronic |
1 |
|
Korn |
sad |
Rock |
1 |
|
Sister Hazel |
happy |
Rock |
0 |
|
Backstreet Boys |
happy |
Pop |
1 |
|
Kool Moe Dee |
happy |
Hip Hop/Rap |
0 |
|
The Tragically Hip |
sad |
Rock |
1 |
|
Cave & The Bad Seeds |
happy |
Rock |
0 |
|
Usher |
happy |
Hip Hop/Rap |
0 |
|
Michael McDonald |
sad |
Pop |
0 |
|
Red Hot Chili Peppers |
sad |
Rock |
1 |
|
Scar Symmetry |
sad |
Rock |
1 |
|
The Rolling Stones |
happy |
Rock |
0 |
|
Ronnie Milsap |
sad |
Country |
1 |
|
Tesla |
happy |
Rock |
0 |
Table 4. Data Testing Music Content Result
|
Artist |
Tempo |
Genre |
Status |
|
4Him |
150.062 |
Christian |
1 |
|
Vitamin C |
85.023 |
Pop |
1 |
|
K's Choice |
130.007 |
Rock |
0 |
|
Rickie Lee Jones |
125.011 |
Jazz |
1 |
|
Ronnie Milsap |
130.031 |
Country |
1 |
|
Goldfinger |
139.922 |
Rock |
0 |
|
Utopia |
129.004 |
Electronic |
1 |
|
Korn |
119.999 |
Rock |
0 |
|
Sister Hazel |
125.011 |
Rock |
0 |
|
Backstreet Boys |
125.008 |
Pop |
0 |
|
Kool Moe Dee |
120.06 |
Hip Hop/Rap |
1 |
|
The Tragically Hip |
125.004 |
Rock |
0 |
|
Nick Cave & The Bad Seeds |
108.009 |
Rock |
0 |
|
Usher |
129.948 |
Hip Hop/Rap |
1 |
|
Michael McDonald |
125.008 |
Pop |
1 |
|
Red Hot Chili Peppers |
131.952 |
Rock |
0 |
|
Scar Symmetry |
92.002 |
Rock |
0 |
|
The Rolling Stones |
99.977 |
Rock |
0 |
|
Ronnie Milsap |
153.547 |
Country |
1 |
|
Tesla |
132.002 |
Rock |
0 |
From the data above, we do the classification using the naïve Bayes method which gets results, namely User Context gets an accuracy of 60% (status : 1) and Music Content gets an accuracy of 40% (status : 0). The most error data is Gerne Rock data, it is caused by the high frequency of the amount of data with the genre of rock which results in similarities to almost all existing genres.
The calculation of accuracy uses the precision method which has the following formula:
TP precision = t p + pp
TP is True Positive (true result or true result) FP is Positive Positive (lost result or incorrect result) Or in other words, the true amount, divided by the total number of test data.
-
4. Conclusion
From the foregoing, we can conclude that in classifying the music genre using this naïve Bayes method, the mood feature in the User Context gets higher accuracy results when compared to the tempo feature in Music Content.
In the future, we can develop this research by finding data with the same amount of data frequency in each genre or at least not having a very significant amount of frequency difference.
References
-
[1] “Musik.” Wikipedia, Wikimedia Foundation, 13 Feb. 2019, id.wikipedia.org/wiki/Musik.
-
[2] “Precision and recall,” Wikipedia – The Free Encyclopedia. [Online]. Available:
http://en.wikipedia.org/wiki/Precision_and_recall. [Accessed: 1-Jun-2019]
-
[3] Choirul Anam, Harry Budi Santoso. Perbandingan Kinerja Algoritma C4.5 dan Naive Bayes
untuk Klasifikasi Penerima Beasiswa. Universitas AMIKOM Yogyakarta, 2018
-
[4] Dewi Rosmala, Gadya Dwipa L. pembangunan website content monitoring system
menggunakan DIFFLIB PYTHON. Institusi teknologi nasional bandung, 2012.
-
[5] Gurneet Kaur, Er. Neelam Oberai. A review article on naïve bayes classifier with various
smoothing techniques. IJCSMC, vol 3 issue 10, 2014, pg.864-868.
http://iperpin.wordpress.com/2008/03/27/recall- precision/.[Accessed: 1-Jun-2019].
-
[6] M. F. McKinney and D. Moelants, “Deviations from the resonance theory of tempo
induction,” Proceedings of the Conference on Interdisciplinary Musicology (CIM04), Graz, Austria, 2004.
-
[7] P. N. Juslin; P. Laukka, “Communication of emotions in vocal expression and music
performance: Different channels, same code?,” Psychol. Bull.,vol. 129, no. 5, pp. 770814, 2003.
-
[8] putubuku, “Recall & Precision,” Ilmu Perpustakaan & Informasi – diskusi dan ulasan ringkas,
27-Mar-2008. [Online]. Available:
-
[9] Sebastian Raschka. Music mood: predicting the mood of music from song lyric using
machine learning. Michigan state university, 2014.
-
[10] Thayer, Robert E. (1998). “The Biopsychology of Mood and Arousal”. New York, NY: Oxford University Press
197
Discussion and feedback