ANALISIS & IMPLEMENTASI ALGORITMA KELELAWAR SEBAGAI FITUR SELEKTOR DALAM KLASIFIKASI DERMATOLOGY
on
Jurnal Ilmiah
ILMU KOMPUTER
Universitas Udayana
Vol. IX, No. 2, September 2016
ISSN 1979 - 5661
ANALISIS & IMPLEMENTASI
ALGORITMA KELELAWAR SEBAGAI FITUR SELEKTOR
DALAM KLASIFIKASI DERMATOLOGY
Ketut Ardha Chandra1, I Made Widiartha2, Agus Muliantara 3
1,2,3 Program Studi Teknik Informatika, Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana Jalan Kampus Udayana Bukit Jimbaran, Badung-Bali Email: ketutardhachandra@gmail.com1, imadewidiartha@cs.unud.ac.id2, muliantara@cs.unud.ac.id3
ABSTRAK
Penyakit kulit merupakan salah satu penyakit yang perlu ditangani secara serius baik dalam pencegahan maupun pengobatan.Di Indonesia, penyakit kulit merupakan penyakit yang menjangkit terbanyak kedua sejumlah 501.280 kasus. Sebagai upaya pencegahan dan pengobatan perlu diketahui klasifikasi penyakit kulit apa yang sedang diderita. Untuk mengetahui klasifikasi penyakit yang tepat perlu diketahui fitur-fitur yang tepat pula. Salah satu jenis penyakit kulit yaitu Erythemato-squamou sangat sulit untuk deteksi karena fitur klinis maupun histopatologis menampilkan 90% fitur serupa. Solusi untuk mengoptimasi kinerja klasifikasi dan memilih fitur yang tepat bisa menggunakan metode bio-inspired salah satunya algoritma kelelawar.Pada penelitian sebelumnya algoritma kelelawar mampu memberikan perfoma yang lebih baik bila dibandingkan dengan algoritma genetika, Particle Swarm Optimization dan Geometric Particle Swarm Optimization. Oleh karena Algoritma Kelelawar memberikan hasil yang baik dalam penelitian komparasi sebelumnya, pada penelitian ini Algoritma Kelelawar digunakan sebagai feature selector untuk membantu proses klasifikasi Dermatology menggunakan Naive Bayes dan Backpropagation dengan harapan akurasi yang dihasilkan klasifier lebih optimal. Penelitian ini menggunakan dua skenario dimana skenario pertama klasifikasi berjalan tanpa menggunakan algoritma kelelawar, dan skenario kedua menggunakan algoritma kelelawar.Hasil penelitian ini mendapatkan kesimpulan bahwa dengan menggunakan algoritma kelelawar akurasi klasifikasi Dermatolgy dapat meningkat. Pada klasifier Naive Bayes akurasi meningkat dari 81,81% menjadi 97,27% dan klasifier Backpropagation meningkat dari 61.40% menjadi 92.39% dengan menggunakan variabel yang paling optimal yaitu α=0,75, β=1 dan γ=0,25. Dari kedua klasifier yang digunakan, algoritma kelelawar mampu memberikan hasil yang konsisten sebagai feature selector dengan menghasilkan pemilihan fitur optimal yang sama yaitu fitur : itching, PNL infiltrate, Parakeratosis, Elongation of the rete ridges, Munro microabcess, dan Follicular horn plug.
Kata Kunci: Algoritma Kelelawar, Feature selector, Dermatology, Naive Bayes, Backpropagation
ABSTRACT
Student is an individual transition from adolescence to adulthood. So that the student is still not stable level of emotion in terms of management.
Keywords: Financial Applications, Mobile, Android
Penyakit kulit merupakan salah satu penyakit yang perlu ditangani secara serius baik dalam pencegahan maupun pengobatan.Berdasarkan laporan Organisasi Kesehatan Dunia (WHO) pada tahun 2011, penyakit kulit masih sering terjadi pada masyarakat pedesaan di negara-negara berkembang dengan konsekuensi ekonomi dan sosial yang serius.
Indonesia yang merupakan salah satu negara berkembang dan banyak memiliki wilayah pedesaan, harus memiliki sarana medis yang memadai guna mengatasi permasalahan penyakit kulit yang sering terjadi.Menurut Direktur Jenderal Pelayanan Medik Departemen Kesehatan Republik Indonesia tahun 2006 penyakit kulit dan jaringan subkutan berdasarkan prevalensi 10 penyakit terbanyak pada masyarakat Indonesia menduduki peringkat kedua setelah infeksi saluran penapasan akut dengan jumlah 501.280 kasus (Tuti, 2010). Penanganan sejak dini tentunya akan mengurangi jumlah kasus penyakit kulit yang akan terjadi di masyarakat.
Dalam penanganan dini penyakit kulit perlu diperhatikan gejala-gejala yang timbul agar klasifikasi jenis penyakit kulit dapat diketahui oleh masyarakat dan dapat dilakukan proses pencegahan maupun
penyembuhan. Namun pada kenyataannya penyakit kulit memiliki gejala-gejala yang hampir serupa sehingga proses klasifikasi menjadi sulit.Minimnya akurasi disebabkan hasil pengukuran yang salah maupun fitur-fitur yang tidak diperlukan yang justru menganggu hasil dari klasifikasi penyakit kulit tersebut. Salah satu tantangan dalam bidang dermatology yaitu membedakan Erythemato – Squamous Diseases (ESD) (Olatunji,2013).Dalam pendeteksian ESD fitur klinis maupun histopatologis menampilkan 90% fitur serupa (Badrinath,2013). Hal ini memicu penelitian bagaimana mengoptimasi kinerja klasifikasi agar keakuratannya dapat lebih meningkat.
Untuk mendapatkan hasil diagnosa penyakit kulit membutuhkan berbagai proses untuk memperoleh fitur-fitur yang diperlukan untuk mendapat hasil klasifikasi akhir. Salah satu jenis penyakit kulit yaitu Erythemato – SquamousDiseases melewati tahapan proses klinis dan histopatologis untuk mendapatkan fitur-fitur dalam klasifikasi dermatology. Proses klinis diperoleh melalui diagnosa secara langsung seperti sejarah keturunan, usia, hingga penampakan kulit secara langsung. Sementara proses histopatologis diperoleh melalui pengamatan melalui mikroskop menggunakan sampel kulit pasien. Proses
histopatologis memerlukan waktu yang lama hingga mendapat fitur-fitur yang dibutuhkan. Proses pendeteksian yang lama akan mengakibatkan pencegahan dini sulit untuk dilakukan sehingga proses penyembuhan akan terhambat sampai putusan diagnosa telah dihasilkan.
Terdapat berbagai macam metode klasifikasi modern menggunakan komputasi sehingga proses klasifikasi bisa dilakukan lebih cepat dibandingkan proses klasifikasi secara konvensional. Tetapi tidak hanya kecepatan klasifikasi yang dibutuhkan, tingkat akurasi yang tinggi juga diperlukan utamanya dalam klasifikasi di bidang kesehatan, sebab bila terdapat kesalahan akan berpengaruh buruk terhadap kesehatan pasien. Salah satu penelitian komparasi klasifikasi penyakit kulit menggunakan metode Naive – Bayes hanya menghasilkan tingkat akurasi sebesar 72.85% (Kundu, dkk, 2010). Sehingga proses klasifikasi penyakit kulit khususnya menggunakan Naive – Bayes memerlukan suatu optimalisasi agar akurasinya meningkat.
Berdasarkan fakta yang telah dijelaskan di atas, dapat disimpulkan bahwa proses klasifikasi Dermatology atau penyakit kulit menghadapi dua permasalahan yaitu akurasi yang minim serta proses diagnosa yang lama. Solusi permasalahan tersebut dapat diatasi dengan menggunakan diagnosa komputasi yang biasa dikenal dengan istilah Bio – Informatika. Dengan Bio – Informatika
proses diagnosa dapat dilakukan lebih cepat sehingga lebih efisien dari segi waktu maupun finansial (Andi, 2003).
Salah satu metode optimasi Bio – Inspired terbaru adalah Bat Algorithm atau Algoritma Kelelawar. Secara umum algoritma kelelawar meniru tingkah laku kelelawar dalam mencari makanan dan dapat membedakan jenis-jenis serangga walaupun dalam kegelapan total (Yang, 2010). Algoritma kelelawar merupakan metode optimasi metaheuristik yang dapat digunakan sebagai feature selector dalam kasus klasifikasi. Algoritma Kelelawar memberikan perfoma yang lebih baik bila dibandingkan dengan beberapa algoritma lainya seperti Algoritma Genetika, Particle Swarm Opimization dan Geometric Particle Swarm Optimization (Ahmad, 2013). Selain itu Algoritma Kelelawar dapat memberikan akurasi menggunakan Naive Bayes sebagai evaluatornya yang cukup menjanjikan sebesar 98,29 % bila dibandingkan dengan metode Exhaustive Search dan Genetic Search yang secara berurutan memberikan hasil 82,97% dan 82,55% (Pallavi, 2013). Oleh karena Algoritma Kelelawar memberikan hasil yang baik dalam penelitian komparasi sebelumnya, Algoritma Kelelawar akan digunakan sebagai feature selector untuk membantu proses klasifikasi Dermatology menggunakan Naive Bayes dan Backpropagation dengan harapan akurasi
yang dihasikan klasifier dapat berjalan lebih optimal.
-
2 METODE, DESAIN, DAN
DATASET
Terdapat tiga metode yang digunakan dalam penelitian ini yaitu Algoritma Kelelawar, Naive Bayes dan Backpropagation. Algoritma kelelawar digunakan sebagai feature selector, sementara Naive Bayes dan Backpropagation digunakan sebagai klasifier untuk mengukur seberapa besar akurasi yang dihasilkan dari fitur terpilih.
Algoritma kelelawar pertama kali diperkenalkan oleh Xin – She Yang pada tahun 2010 dalam jurnalnya yang berjudul A New Metaheuristic Bat – Inspired Algorithm.
Kemampuan kelelawar dalam menangkap mangsanya merupakan hal yang sangat unik.Kelelawar mempunyai kemampuan handal dalam echolocation.Echolocation adalah kemampuan menentukan suatu lokasi dengan menggunakan echo atau gelombang. Kemampuan echolocation ini digunakan untuk mencari mangsa, menghindari penghalang dan menentukan kelelawar.
Semua kelelawar menggunakan echolocation lokasi pada celah untuk
bertengger dalam kegelapan (Yang, 2010). Kelelawar memancarkan kadar pulsa suara yang sangat nyaring dan mendengar gelombang yang memantul dari objek di sekelilingnya. Kadar pulsa dapat bervariasi dan berkorelasi dengan strategi memburu segerombolan kelelawar. Berikut adalah representasi kemampuan kelelawar dalam algoritma kelelawar :
-
1. Kemampuan kelelawar dalam echolocation dapat dikembangkan secara variasi menjadi bat – inspiredalgorithm atau algoritma kelelawar. Sebagai contoh dapat digunakan beberapa rule atau aturan dari kemampuan untuk menentukan jarak dan kelelawar ‘mengetahui’ perbedaan mangsa dan penghalang.
-
2. Kelelawar terbang secara acak dengan kecepatan (Vi) pada posisi (Xi), dengan frekuensi (f), panjang gelombang (Λ ) dan kenyaringan (A) dalam mencari mangsa. Kelelawar mempunyai kemampuan untuk menyesuaikan panjang gelombang (λ) dari dari pancaran pulsa dan mengatur kadar dari dari emisi pulsa (r) ∈ [0,1] yang sangat penting menentukan target terdekat.
-
3. Walaupun kenyaringan dapat bervariasi berapapun itu, tapi diasumsikan kenyaringan dapat bervariasi dari bilang positif yang maksimum sampai bilang konstan minimum.
Adapun implementasi algoritma kelelawar sebagai feature selector pada kasus klasifikasi direpresentasikan sebagai berikut :
a. Posisi
Masing – masing posisi kelelawar direpresentasikan sebagai string biner dengan panjang N dimana N merupakan total fitur dalam dataset. Bit ‘1’ mengindikasikan fitur tersebut dipilih dan bit ‘0’ tidak dipilih seperti yang terlihat pada Gambar 2.1.

Gambar 2.1 Ilustrasi Posisi Kelelawar
Persamaan berikut adalah formulasi penyesuaian posisi kelelawar dimana adalah posisi kelelawar ke – i, merupakan nilai kelelawar ke – i sebelumya dan adalah kecepatan kelelawar ke – i pada suatu kurun waktu.
xtl = x[~1 + vti
Dimana:
: posisi kelelawar ke – i pada iterasi ke – t
: posisi kelelawar ke – i pada iterasi t-1
: kecepatan kelelawar ke – i pada iterasi ke – t
b. Kenyaringan
Kenyaringan (A) merupakan perubahan jumlah fitur dalam suatu iterasi selama pencarian lokal di sekitar kelelawar terbaik global dan pencarian lokal pada setiap kelelawar
x∏ew = ×oid + ^t
Dimana:
: posisi kelelawar baru
: posisi kelelawar sebelumnya
: kenyaringan rata-rata semua kelelawar dalam satu iterasi
-
: bilangan acak diantara -1 dan 1
Ketika kelelawar mulai mendekati solusi terbaik, kenyaringan akan berkurang. Berikut adalah formula untuk konfigurasi nilai kenyaringan :
-
- V 1 - α -^
Dimana:
: kenyaringan kelelawar ke – i untuk iterasi ke t + 1
: kenyaringan kelelawar ke – i pada iterasi ke – t
α : variabel konstan diantara 0 dan 1
Kenyaringan berada di rentang nilai maksimum dan minimum yang telah ditentukan.Penentuan nilai maksimum dan minimun bergantung pada domain aplikasi dan ukuran dataset. Secara empiris, penentuan nilai maksimum yaitu 1/5 N dimana N merupakan total fitur (Pallavi, 2013).
-
c. Frekuensi
Frekuensi merupakan elemen bilangan real yang akan mempengaruhi
nilai kecepatan. Pemilihan nilai minimum
dan maksimum disesuaikan dengan domain aplikasi.
fi f min + (fmax-fmin)β
Dimana:
fi : frekuensi kelelawar ke - i
: variabel konstan diantara 0 dan 1
fmax : nilai maksimum frekuensi
min
: nilai minimumfrekuensi
-
d. Kecepatan
Kecepatan masing-masing kelelawar direpresentasikan dengan bilangan integer positif. Kecepatan akan mempengaruhi berapa jumlah fitur yang harus berubah dalam suatu kurun waktu. Kelelawar berkomunikasi satu dengan yang lainnya melalui solusi global terbaik dan bergerak menuju solusi terbaik global.
-
vi = vΓ1 + (χ, - xDfi
Dimana:
: kecepatan kelelawar ke – i pada iterasi ke-t
: kecepatan kelelawar ke – i pada iterasi ke-(t — 1)
(r, — xf): merupakan perbedaan posisi kelelawar global (*) dengan kelelawar ke – i pada iterasi ke – t.
-
e. Pulse Rate
Pulse rate (r) mempunyai peran untuk menentukan kapan pencarian lokal dari kelelawar terbaik global dilewati. Besar nilai pulse rateakan mengurangi kemungkinan melakukan pencarian lokal dan begitu pula sebaiknya. Maka, ketika
kelelawar mendekati solusi terbaik, pulse rateakan perlahan – perlahan berkurang.
rt+1 = r0[1 - exp(-yt)]
Dimana :
: pulse rate kelelawar pada iterasi t+1 : nilaipulse rate awal pada kelelawar : variabel konstan diantara 0 dan 1
Dimana merupakan kadar pulsa kelelawar dengan solusi baru, merupakan kadar pulsa kelelawar dengan solusi sebelumnya, t adalah kurun waktu, adalah nilai konstan.
-
f. Fungsi Fitness
Fungsi fitness digunakan pada setiap kandidat solusi dimana dalam penelitian ini menggunakan Naive Bayes sebagai evaluatornya.
TF -SF
Fi = δ. accurate + φ . ———
Dimana:
: nilai Fitness kelelawar ke – i
: paramater dengan rentang diantara 0 dan 1 untuk bobot akurasi
φ : paramater dimana = = — -U untuk bobot jumlah fitur
: hasil akurasi yang dihasilkan klasifier
Thomas Bayes yaitu ilmuwan asal inggris menemukan suatu metode klasifikasi melalui pendekatan probabilitas dan statistik yang dikenal dengan ‘Naive Bayes’. Thomas Bayes memprediksi
peluang yang akan datang dengan kejadian atau pengalamaan sebelumnya yang akhirnya dikenal sebagai teorema Bayes. Teorema tersebut dikombinasikan dengan ‘naive’ dimana diasumsikan kondisi antar atribut saling bebas.
^=∑a½∙ -ι.....‘
Dimana :
: probabilitas nilai kelas
: probabilitas kelas dengan suatu nilai atribut
∑f-1 P(Fi)P(X∣Vi) : total dari seluruh
probabilitas kelas (P (Yi)) dikali dengan seluruh probabilitas kelas dengan suatu nilai atribut X P(X∖Yi)
Backpropagation merupakan salah satu bagian dari Neural Network. Backpropagation merupakan metode pelatihan terawasi (supervised learning), dalam artian mempunyai target yang akan dicari. ciri dari Backpropagation adalah meminimalkan error pada output yang dihasilkan oleh jaringan. dalam metode backpropagation, biasanya digunakan jaringan multilayer. Jaringan multilayer yang dimaksud adalah layer yang terdiri dari input layer (layer masukan), hidden layer (layer tersembunyi), output layer (layer keluaran). Dalam pengembangannya, hidden layer dapat terdiri dari satu atau lebih unit hidden layer.
Arsitektur jaringan back
propagation adalah sebagai berikut :

Gambar 2.2 Arsitektur Backpropagation
Pada gambar 2.2 diperlihatkan arsitektur jaringan backpropagation dengan satu unit hidden layer.Xi adalah unit input layer, Zj adalah unit hidden layer, dan Yk adalah unit output layer. Setiap unit memiliki bobotnya masing-masing.Vij adalah bobot dari unit input layer ke unit hidden layer dan Wjk adalah bobot dari unit hidden layer ke unit output layer.
Penggunaan BackPropagation
terdiri dari dua tahap :
-
1. Tahap Belajar atau pelatihan, dimana pada tahap ini pada backpropagation neural network diberikan sejumlah data pelatihan dan target.
-
2. Tahap pengujian atau penggunaan, pengujian dan penggunaan dilakukan setelah Backpropagation selesai
belajar.
Setiap umpan maju (feedforward), setiap unit input (Xi) akan menerima sinyal input dan akan menyebarkan sinyal tersebut pada tiap hidden unit(Zj). Setiap hidden unit kemudian akan menghitung aktivasinya dan mengirim sinyal (zj) ke tiap unit output.Kemudian setiap unit output
(Yk) juga akan menghitung aktivasinya (yk) untuk menghasilkan respon terhadap input yang diberikan jaringan.
Saat proses pelatihan (training), setiap unit output membandingkan aktivasinya (yk) dengan nilaui target (tk) untuk menentukan besarnya error. Berdasarkan error ini, dihitung faktor delta k, dimana faktor ini digunakan untuk mendistribusikan error dari output ke layer sebelumnya. Dengan cara yang sama, faktor delta j juga dihitung pada hidden unit Zj, dimana faktor ini digunakan untuk memperbaharui bobot antara hidden layer dan input layer. Setelah semua faktor delta ditemukan, bobot untuk semua layer diperbaharui.
Gambar 2.3 merupakan diagram alir dari sistem. Pertama-tama user memasukan paramater yang dibutuhkan. Selanjutnya yaitu proses pemilihan fitur algoritma kelelawar dengan menggunakan dataset yang ada, dimana bagian ini merupakan training section. Setelah training section didapatkan tabel bayangan dari dataset sementara menggunakan fitur-fitur yang telah dipilih oleh setiap kelelawar. Tabel bayangan akan diuji menggunakan Naive Bayes Classifier untuk memperoleh nilai akurasi yang akan digunakan dalam mencari nilai fitness setiap kelelawar, bagian ini merupakan testing section.
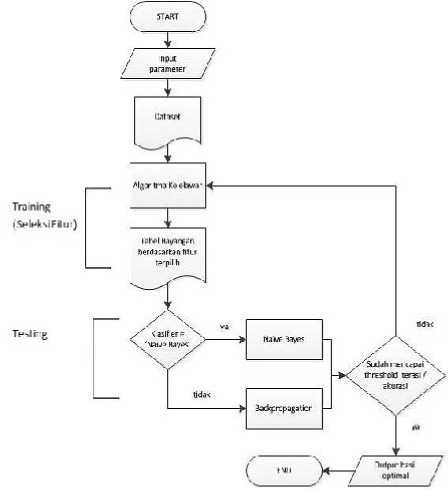
Gambar 2.3 Flowchart alur sistem
Dalam penelitian ini digunakan datasets yang berasal dari University of California Irvine (UCI) Repository yaitu Dermatology database. Terdapat 366 sampel pasien yang masing – masing memiliki 34 atribut. Dermatology database mempunyai jumlah fitur yang cukup banyak sehingga sesuai dengan penelitian ini.
Dalam dataset Dermatology pasien pada mulanya didiagnosa secara klinis dengan 12 fitur.Setelah itu, sampel kulit pasien diambil sebagai diagnosa 22 fitur histopatologis.Hasil dari fitur Histopatologis didapatkan melalui analisa sampel menggunakan mikroskop.Atribut klinis maupun histopatologis dapat dilihat pada Tabel 1.
Dataset Dermatology terdiri atas 34 atribut, 33 merupakan linier dan satu
merupakan nominal.Pada fitur family history, nilai ‘1’ mengandung makna bahwa keluarga pasien pernah mengalami riwayat penyakit kulit sementara nilai ‘0’ mengandung makna keluarga pasien tidak ada yang memiliki riwayat penyakit kulit. Fitur – fitur lainnya baik klinik maupun histopatologis diberikan rentang nilaii dari 0 – 1 dimana 0 memberkan makna fitur tersebut nihil, 3 memberikan makna nilai yang paling tinggi dan 1 atau 2 memberikan makna nilai tengah – tengah.
Tabel 2.1 Distribusi kelas pada database Dermatology
|
Kode Kelas |
Kelas |
Jumlah Sampel |
|
1 |
Psoriasis |
112 |
|
2 |
Seboreic Dermatitis |
61 |
|
3 |
Lichen planus |
72 |
|
4 |
Pityriasis rosea |
49 |
|
5 |
Cronic dermatitis |
52 |
|
6 |
Pityriasis rubra pilaris |
20 |
Pada sub bab ini akan dipaparkan mengenai hasil pengujian yang telah dilakukan sertai analisis dari hasil pengujian yang diperoleh. Adapun tahapan pengujian yang dilakukan pada penelitian ini sebagai berikut :
-
a. Menghitung berapa akurasi yang mampu dihasilkan algoritma kelelawar melalui fitur seleksinya dengan menggunakan dua klasifier yaitu Naive Bayes dan Backpropagation.
-
b. Mencari variabel -, dan γ yang paling optimal.
-
c. Menguji konsistensi terhadap fitur
terpilih dari dua klasifier berbeda (Naïve Bayes & Backpropagation). Konsistensi tercapai bilamana fitur terpilih diantara kedua klasifier merupakan fitur yang sama.
-
d. Menghitung kompleksitas waktu dari
sistem dan membandingkannya efisiensi waktu yang diperoleh dengan metode Brute Force.
-
e. Membandingkan akurasi dan waktu proses pada klasifikasi dermatolgy yang diperoleh dengan algoritma kelelawar dan dengan tanpa menggunakan algoritma kelelawar.
-
f. Analisis karakteristik fitur yang cocok dengan algoritma kelelawar.
Karakteristik paramater untuk pengujian dalam penelitian ini yaitu sebagai berikut :
-
a. Bobot fitness yang digunakan yaitu δ = 0,9 dan = 0,1. Bobot " merujuk kepada tingkat akurasi dan merujuk kepada jumlah fitur.
-
b. Penelitian ini menggunakan varian variabel ”, dan γ dengan rentang
nilai diantara 0 dan 1 dengan
increment 0,25 sehingga didapatkan varian ■ ■, ' dan γ sebanyak 64 varian.
-
c. Kelelawar yang dibangkitkan berjumlah 30 kelelawar, iterasi maksimal berjumlah 50 iterasi.
-
d. Metode Brute Force yang digunakan sebagai perbandingan efisiensi waktu akan menjalankan seluruh search space pada penelitian ini, dimana search space dalam penelitian ini yaitu seluruh kombinasi fitur pada data dermatology. Data dermatology memiliki 34 fitur sehingga kombinasi yang akan dieksekusi oleh Brute Force sebanyak 234 - 1 = 17.179.869.184 kombinasi.
Pengujian telah dilakukan sebanyak 10 kali percobaan pada setiap klasifier dengan 64 kombinasi fitur α, β dan γ menggunakan parameter yaitu 30 kelelawar dan 50 iterasi. Dari 10 percobaan yang telah dilakukan lalu dirata-ratakan dan disajikan pada tabel.
Hasil penelitian menunjukan bahwa hasil paling optimal terdapat pada variabel dengan nilai α=0,75, β=1 dan γ=0,25. Tingkat akurasi yang didapatkan pada klasifier Naive Bayes yaitu sebesar 97,27% dengan jumlah fitur yang dipilih enam dan nilai fitness sebesar 0.95725. Sementara Backpropagation menghasilkan akurasi sebesar 92.392% dengan jumlah fitur yang dipilih enam dan nilai fitness 0.9133.
kedua klasifier yang digunakan yaitu: Naive Bayes dan Backpropagation, terbukti bahwa algoritma kelelawar mampu berikan hasil yang konsisten terhadap pemilihan fiturnya. Masing-masing klasifier menunjukan bahwa hasil paling optimal yaitu menggunakan enam fitur terpilih pada posisi kelelawar :
0001000000000100001010010000010000 atau dalam kata lain fitur terpilih yaitu fitur ke : 4, 14, 19, 21, 24, dan 30.
Algoritma kelelawar mempunyai karakteristik kompleksitasi Uf ^) atau kompleksitas linear yaitu kompleksitas bertumbuh seiring dengan pertumbuhan data. Dalam pengujian didapatkan bahwa algoritma kelelawar membutuhkan waktu proses sebanyak 544 detik atau 9 menit 4 detik untuk mendapatkan hasil akurasi paling optimal seperti pada tabel 4.12. Sementara itu hasil analisis menggunakan Brute Force menghasilkan hasil akurasi yang sama dengan algoritma kelelawar namun membutuhkan waktu proses hingga 72735 detik atau 20 jam 12 menit 15 detik. Maka secara signifikan algoritma kelelawar mampu menghasilkan akurasi yang serupa dengan Brute Force namun dalam segi waktu sangat jauh lebih efisien. Untuk selengkapnya bisa dilihat pada tabel 4.1
Tabel 4.1 Perbandingan Algoritma Kelelawar dengan Brute Force
|
Algeritnu Kelelanai |
BroteFerte | ||||||||
|
Nane Sayss |
Batxorooialiot |
Naπ,e Eayes |
BaEkpripasitiiQ | ||||||
|
,1 Waktu (M |
n- Ftur |
Akurei |
Waktu r- (da⅛) Fitur |
Atjrisi |
WaLtJ (detik) |
3- Fitif |
Akurei |
Waktu (detik) |
Firtr |
|
97.27% .'-.56 |
6 |
92 55% |
2769» 6 |
5’27% |
’2755.73 |
6 |
92.53% |
29CS4292 |
6 |
Pada Tabel 4.2 terdapat hasil analisa pada klasifikasi dermatology dengan dan tanpa Algoritma Kelelawar. Hasil dari pengujian didapatkan bahwa bila menggunakan algoritma kelelawar klasifier Naive Bayes menghasilkan akurasi sebesar 97,27% dengan waktu proses selama 544,66 detik dan klasifier Backpropagation menghasilkan akurasi 92,53% dengan waktu proses selama 2769,86 detik. Sementara bila tanpa menggunakan algoritma kelelawar hasil klasifikasi dermatology menggunakan Naive Bayes sebesar 81,81% dengan waktu proses selama 0,15 detik dan Backpropagation menghasilkan akurasi sebesar 61,40% dengan waktu proses selama 2,96 detik. Maka dapat disimpukan bahwa dengan menggunakan kelelawar hasil klasifikasi menjadi lebih baik walaupun waktu proses relatif lebih lama bila dibandingan dengan tanpa menggunakan algoritma kelelawar.
Tabel 4.2 Perbandingan dengan dan tanpa Algoritma Kelelawar
|
Mengfljnatcii Ajoritma Kelelawar |
Taopa Mengg JnatenAgxtma Kelelnvci | ||||||
|
Mite Baves |
Bxkproxgatoo |
Neive Eayes |
Bactorcpageticr | ||||
|
Akinsi |
WsktL(Oetik) |
Akuras |
Uacuidatik; |
AtJfeJi |
Waktu (detik) |
Akxasi |
Waktu (oetik) |
|
9727% |
544.56 |
92.5:* |
2769 86 |
8181% |
015 |
6140% |
2.96 |
Berdasarkan hasil penelitian mengenai analisis dan implementasi
algoritma kelelawar sebagai feature selector dalam klasifikasi dermatology dapat ditarik kesimpulan sebagai berikut.
-
1. Algoritma kelelawar mampu menyelesaikan permasalahan fitur seleksi dalam klasifikasi dermatology. Dari hasil pengujian, algoritma kelelawar bila menggunakan Naive Bayes classifier mendapatkan tingkat akurasi klasifikasi sebesar 97,27%. Sementara itu Backpropagation classifier mendapatkan tingkat akurasi klasifikasi sebesar 92.39%. Hasil penelitian menunjukan bahwa hasil paling optimal terdapat pada variabel dengan nilai α = 0,75, β = 1 dan y = 0,25.
-
2. Pada penelitian ini algoritma kelelawar mampu memberikan hasil yang konsisten sebagai feature selector dalam klasifikasi dermatology dengan dua metode klasifier yang berbeda yaitu : Naive Bayes dan Backpropagation. Dari penelitian didapatkan bahwa pemilihan fitur optimal berjumlah enam yaitu fitur ke : 4, 14, 19, 21, 24, dan 30. Algoritma kelelawar mempunyai kompleksitas <) ia) atau kompleksitas linear. Dalam pengujian didapatkan bahwa algoritma kelelawar membutuhkan waktu proses sebanyak 544 detik atau 9 menit 4 detik untuk mendapatkan hasil akurasi paling optimal.
-
6 DAFTAR PUSTAKA
Ahmed Majid Taha and Alicia Y.C. Tang.“Bat Algorithm for Rough Set Attribute Reduction”. Journal of Theoritical and Applied Information Technology, Vol 51, No.1 May 2013
Cichosz, Pawel.2015.Data Mining Algorithm : Explanation Using.Poland : John Wiley & Sons, Ltd
Chiang, Yi Zhen.Dermatology : A handbook for medical students & junior doctors.Manchester : British Association of Dermatologists
Davar Giveski., Hamid Salimi., Akhavan Bitaraf., “Detection of erythemato-squamous diseases using AR-CatfishBPSO-KVSM”, An
Internation Journal (SIPIJ) Vol.2, No.4, December 2011
Downey, Allen.2013.Think Bayes.United States of America : O’Reilly Media, Inc.
I. Jr. Fister, D. Fister, X.-S Yang. “A hybrid bat algorithm”. Elektrotehniski vestnik, 2013, in press.
N.Badrinath., G.Gopinath., and K.S. Ravichandran., “ Design of Automatic Detection of
Erythemato-squamous Disease Through Threshold-based ABC-FELM Algorithm”, Journal of Aritificial Intelegence 6 (4):245-256, 2013
Pallavi.2013.Bio Inspired Hybrid Bat Algorithm with Naive Bayes Classifier for Feature
Selection.International Journal of
Science and Research (IJSR) ISSN (Online) : 2319 – 7064 Volume 4 Issue 4.
Sunday Olusanya Olatunji and Hossain Arif, “Identification of Erythemato-Squamous Diseases using Extreme Learning Machine and Artificial Neural Network” ICTACT Journal on Soft Computing, October 2013, Volume:04, Issue :01
Taha, Ahmed.2013.Naive Bayes – Guided Bat Algorithm for Feature Selection.The Scientific World
Journal Volume 2013, Article ID 325973, 9 Pages.
X.-S. Yang, A New Metaheuristic Bat-Inspired Algorithm, in: Nature Inspired Cooperative Strategies for Optimization (NISCO 2010) (Eds. J. R. Gonzalez et al.), Studies in Computational Intelligence, Springer Berlin, 284, Springer, 6574 (2010).
Xin-She Yang and Amir H. Gandomi, “Bat Algorithm: A Novel Apporach for Global Engineering Optimization”, Engineering Computatuin, Vol.29, Issue 5, pp.464-483(2012)
Xin-She Yang, Bat algorithm: literature review and applications, Int. J. BioInspired Computation, Vol. 5, No. 3, pp. 141–149 (2013).DOI: 10.1504/IJBIC.2013.055093
Yang, X. S., (2011), Bat Algorithm for Multiobjective Optimization, Int. J. Bio-Inspired Computation, Vol. 3, No. 5, pp.267-274.
Discussion and feedback