PENGEMBANGAN PENGKLASIFIKASI JENIS TANAMAN MENGGUNAKAN PENDEKATAN BACKPROPAGATION DAN NGUYEN-WIDROW
on
Jurnal Ilmiah
Ilmukomputcr
Universitas Udayana
Vol. 7, No.1, April 2014 ISSN 1979-5661
PENGEMBANGAN PENGKLASIFIKASI JENIS TANAMAN
MENGGUNAKAN PENDEKATAN BACKPROPAGATION DAN
NGUYEN-WIDROW
aAgus Muliantara, bNgurah Agus Sanjaya ER
Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Udayana email : amuliantara@cs.unud.ac.id, bagus.sanjaya@cs.unud.ac.id
ABSTRAK
Indonesia adalah salah satu negara yang terletak di daerah katulistiwa dengan iklim tropis yang hangat. Letak Negara Indonesia ini memungkinkan munculnya vegetasi alami yang sangat besar. Oleh karena banyaknya tanaman khas Indonesia khususnya tanaman khas daerah Bali, tentu hal ini perlu dilakukan pendataan terhadap tanaman-tanaman tersebut. Paling tidak dalam hal mengenali/mengklasifikasi jenis tanaman. Sehingga informasi mengenai kegunaan tanaman tersebut tidak hilang akibat punahnya tanaman tersebut di habitat aslinya.
Dalam bidang teknik informatika, permasalahan pengenalan objek dikenal dengan istilah Klasifikasi. Terdapat banyak metode yang dapat diterapkan untuk dapat menyelesaikan permasalahan klasifikasi. Salah satu metode klasifikasi yang sangat popular adalah metode backpropagation. Selain memiliki keunggulan, metode ini juga memiliki kelemahan salah satunya adalah proses konvergensi yang relatif lama. Salah satu penyebabnya adalah teknik inisialisasi awal bobot yang masih menggunakan teknik random konvensional.
Dalam penelitian ini telah dikembangkan suatu aplikasi pengklasifikasian tanaman dengan metode backpropagation. Permasalahan inisialisasi bobot awal telah berhasil diatasi dengan memanfaatkan salah satu teknik randomisasi yaitu metode nguyen widrow. Dari hasil penelitian didapatkan bahwa pemanfaatan nguyen widrow telah berhasil meningkatkan akurasi backpropagation sebanyak 25%. Akurasi klasifikasi dari aplikasi yang telah dikembangkan rata-rata diatas 83%. Hal ini mengindikasikan aplikasi yang telah dibangun dapat menjadi salah satu solusi untuk hal klasifikasi jenis tanaman.
Kata kunci: backpropagation, nguyen widrow, klasifikasi, tanaman
ABSTRACT
Indonesia is a country located in the equatorial region with a warm tropical climate. This layout allows the emergence of the State of Indonesia is very big natural vegetation. Because many plants typical of Indonesia, especially Bali local specialty crops, of course it is necessary to do the survey of the plants. At least in terms of recognizing / classifying types of plants . So that the information regarding the usefulness of these plants are not lost due to the extinction of these plants in their natural habitat.
In the field of information technology, object recognition problem is known as classification. There are many methods that can be applied to solve the problems of classification. One method of classification is very popular back propagation method. Besides having advantages, this method also has disadvantages one of which is a relatively long process of convergence. One reason is the initial weight initialization techniques are still using conventional random techniques.
In this study has developed a classification of plant applications with back propagation method . Initial weight initialization problem has been successfully overcome by using one of the method of randomization techniques nguyen Widrow. The result showed that the use of nguyen Widrow has managed to increase the accuracy of backpropagation as much as 25%. Classification accuracy of the applications that have been developed on average above 83%. This indicates that the application has been built to be one of the solutions for the classification of types of plants. .
Keywords : backpropagation, nguyen widrow, classification, plants
Indonesia adalah salah satu negara yang terletak di daerah katulistiwa dengan iklim tropis
yang hangat. Letak Negara Indonesia ini memungkinkan munculnya vegetasi alami yang sangat besar. Kalimantan, sumatera, Sulawesi, Papua Barat dan pulau-pulau di Indonesia
umumnya memiliki vegetasi khas dari tiap pulau. Seperti misalnya buah kepayang yang merupakan buah khas kalimantan, kita mengenal istilah mabuk kepayang, tetapi tidak tahu kepayang itu seperti apa. Buah kepayang adalah buah yang dapat dikonsumsi setelah melalui proses pengolahan. Karena keenakan mengkonsumsi buah kepayang ini, mengakibatkan sampai lupa pekerjaan lain. Sehingga muncullah istilah mabuk kepayang, yaitu mabuk keenakan karena makan buah kepayang.
Lain dengan buah kepayang yang merupakan tanaman khas Kalimantan, Indonesia juga memiliki tanaman khas lainnya yaitu pohon andalas. Pohon Andalas (Morus macroura) tumbuh tersebar mulai dari India, China bagian selatan, Kamboja, Thailand, dan Indonesia. Di Indonesia tanaman ini hanya bisa ditemukan di Sumatera dan Jawa bagian barat. Habitat pohon Andalas terdapat di hutan-hutan dataran tinggi dengan curah hujan yang cukup banyak pada ketinggian antara 900-2.500 meter dpl. Buah Andalas pun mirip dengan buah murbai. Buahnya berbentuk majemuk, menggerombol berwarna hijau jika masih muda dan menjadi ungu kemerahan bila telah masak. Buahnya berair dan dapat dimakan dengan rasa asam-asam manis.
Untuk daerah bali khususnya, jika kita membaca purana-purana mengenai tanah Bali, maka akan didapatkan gambaran mengenai tanah bali yang asri. Begitu kaya alam bali dengan berbagai jenis tanaman, yang mana tanaman inilah yang digunakan sebagai persembahan dalam ritual keagamaan di Bali. Namun sayangnya tidak semua orang di bali ingat atau tahu akan jenis-jenis tanaman yang merupakan vegetasi alami daerah bali. Berbagai buah import yang murah datang dari luar daerah yang secara tidak langsung menggerus kelangsungan hidup keanekaragaman hayati di bali. Seperti misalnya jeruk bali yang merupakan salah satu tanaman khas bali. Jeruk bali saat ini sudah menghilang dari bali, namun dipelihara baik di daerah sukabumi, jawa barat. Daun jeruk bali yang dicampur dengan cuka dapat digunakan untuk mengobati penyakit reumatik. Atau misalnya tanaman sotong yang selain dapat digunakan sebagai obat diare, juga dapat dijadikan sebagai obat jerawat apabila dicampur dengan ketumbar..
Dalam bidang teknik informatika, permasalahan pengenalan objek dikenal dengan istilah Klasifikasi. Dalam metode klasifikasi ciriciri dari tiap objek tanaman akan digunakan sebagai dasar dalam mengenali objek tersebut. Seperti misalnya warna daun, bentuk daun, ukuran daun dan tekstur. Ciri-ciri ini nantinya akan disebut sebagai fitur (features), yang akan digunakan sebagai input ke dalam suatu metode pengenalan. Feature ini didapatkan dari proses yang disebut sebagai feature extraction. Dimana dari gambar suatu daun akan dihitung secara otomatis oleh komputer ciri-ciri/features yang terdapat padanya.
Berbagai metode yang dapat digunakan dalam proses pengklasifikasi suatu objek antara lain Back Propagation (BP), Support Vector Machine (SVM) , Learn Vector Quantitaion (LVQ) maupun Self Organizing Map. Setiap metode memiliki kelebihan dan kekurangannya masing-masing. Seperti misalnya LVQ dan SVM yang memiliki tingkat keberhasilan tinggi, namun memiliki tingkat kesulitan pemrograman yang tinggi.
Berbeda dengan metode LVQ dan SVM, metode BP mudah untuk diimplementasikan meskipun masih memungkinkan terjadinya local optima (kondisi optimal semu). Local Optima ini disebabkan karena beberapa hal diantaranya adalah
-
a. Pemilihan bobot dan bias awal yang acak
-
b. Penentuan Jumlah Unit tersembunyi
-
c. Penentuan Jumlah Pola Pelatihan
-
d. Lama Iterasi
Dari ke-empat permasalahan utama pada BP akan dicoba dikembangkan metode BP yang menggunakan metode inisialisasi bobot terarah yaitu nguyen widrow, dengan harapan akurasi atau kemampuan mengklasifikasinya semakin meningkatkan [1].
Lebih dari 250.000 – 270.000 spesies tanaman ada di dunia. Untuk itu sangatlah sulit bagi manusia untuk mengenali semua jenis tanaman tersebut. Oleh sebab itu banyak penelitian yang mencoba menawarkan berbagai macam cara/metode yang dapat digunakan untuk mengenali jenis-jenis tanaman. Seperti misalnya Neural Network [2], [3], [4].
Umumnya tanaman memiliki warna hijau pada daunnya. Sehingga jika hanya warna yang digunakan sebagai ciri untuk mengenali daun tentunya tidaklah tepat. Karena tanaman akan sulit untuk dapat dibedakan. Karena akan menimbulkan kesalahan yang sangat besar, maka diperlukan ciriciri lain dari daun yang mampu membedakan jenis tanaman seperti misalnya bentuk, tekstur, tulang daun dan ukuran daun [5].
Fitur yang nantinya akan digunakan dalam penelitian ini adalah fitur warna yang didapatkan menggunakan metode color quantitation sehingga didapatkan 9 fitur warna. Dan fitur H ratio, W ratio, area ratio, roundness value, LMean, AMean, BMean, BW1, BW2 [7].
Algoritma BP merupakan algoritma yang mengadopsi cara kerja jaringan saraf pada mahluk
hidup. Algoritma ini terkenal handal karena proses pembelajaran yang mampu dilakukan secara terarah. Pembelajaran algoritma ini dilakukan dengan peng-update-an bobot balik (backpropagation). Penetapan bobot yang optimal akan berujung pada hasil klasifikasi yang tepat. Adapun arsitektur neural networknya adalah seperti gambar 1.
9.
* target
δk merupakan unit kesalahan yang akan dipakai dalam perubahan bobot layar dibawahnya. Hitung perubahan bobot wkj dengan laju pemahaman α .
10.
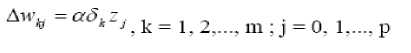
11. Hitung faktor δ unit tersembunyi berdasarkan kesalahan di setiap unit tersembunyi zj (j = 1,
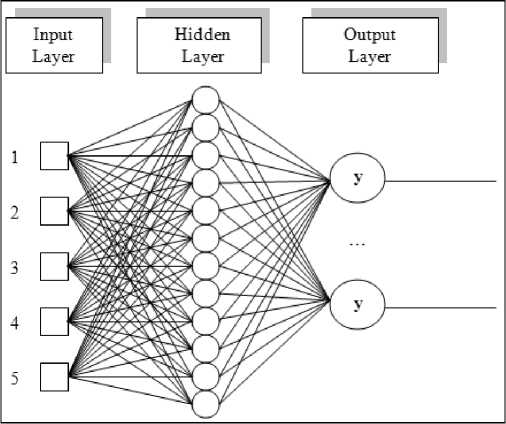
Gambar 1. Contoh Arsitektur BP
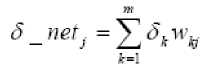
-
12. Faktor δ unit tersembunyi.
<5 j = <5 _ ne^ j f' (.z _ Iietj ) = <5 _ netjZj (1 — zj)
13.
Hitung suku perubahan bobot vji.
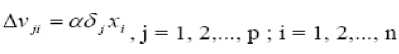
-
14. Hitung semua perubahan bobot. Perubahan bobot garis yang menuju ke unit keluaran, yaitu:
∙∖vlj (baru) = W^ (∕aιua) + Δm⅛ , (k = 1, 2,..., m; j = 0, 1 p).
-
15. Perubahan bobot garis yang menuju ke unit tersembunyi, yaitu:
vjj(baru) = vjj(lama) + Svjl, (j = 1, 2,..., p ; i = 0. 1...., n)
Algoritma yang dijalankan oleh MLP untuk mendapatkan bobot yang optimal adalah sebagai berikut :
-
1. Inisialisasi semua bobot dengan bilangan acak kecil.
-
2. Jika kondisi penghentian belum dipenuhi, lakukan langkah 2-8.
-
3. Untuk setiap pasang data pelatihan, lakukan langkah 3-8.
-
4. Tiap unit masukan menerima sinyal dan meneruskannya ke unit tersembunyi diatasnya.
-
5. Hitung semua keluaran di unit tersembunyi zj (j = 1, 2,..., p).
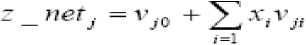
z i = f Qz net ) =---
1 — e - '
-
6. Hitung semua keluaran jaringan di unit keluaran yk (k = 1, 2,...,m).
y - netk =wk0 + ∑zjwl,
■ t 1 _ e~y_^ft
-
8. Hitung faktor δ unit keluaran berdasarkan kesalahan di setiap unit keluaran yk (k = 1, 2,..., m).
Setelah tahapan training untuk penentuan bobot selesai dilakukan, maka tahapan selanjutnya adalah melakukan uji klasifikasi emosi terhadap image testing. Proses testing ini dilakukan sama halnya pada fase training, hanya saja pada fase testing tidak dilakukan pembelajaran karena boot yang digunakan adalah bobot tetap hasil training.
Algoritma utama untuk inisialisasi bobot awal pada BP adalah menggunakan metode acak. Untuk meningkatkan proses konvergensi BP maka digunakanlah Metode Nguyen-Widrow yang menghasilkan bobot awal dan nilai bias untuk setiap layer pada arsitektur BP [1].
Ide utama dari algoritma Nguyen-Widrow adalah mengambil nilai acak kecil sebagai bobot awal jaringan saraf. Kemudian bobot ini akan dimodifikasi sedemikian rupa sehingga region of interest dibagi menjadi interval kecil. Hal ini dapat digunakan untuk mempercepat proses pelatihan dengan menetapkan bobot awal lapisan pertama sehingga setiap node diberikan sendiri Interval pada awal pelatihan.
Sebagai jaringan terlatih, setiap neuron tersembunyi masih memiliki kebebasan untuk menyesuaikan ukuran interval dan lokasi selama pelatihan. Namun, sebagian besar penyesuaian mungkin akan menjadi kecil karena sebagian besar
gerakan berat dihilangkan oleh metode Nguyen-Widrow ini. Artinya penggunaan metode nguyen-widrow dalam inisialisasi bobot awal diharapkan dapat meningkatkan kecepatan tingkat konvergensi dalam proses training pada BP.
Algoritma Inisialiasi Ngyuen Widrow adalah sebagai berikut :
-
• Inisialisasi bobot antara unit input dan unit tersembunyi dengan cara:
-
- menentukan bobot antara unit input dan unit tersembunyi
-
- Vij (lama) = bil acak antara (-ß dan ß)
-
- Menghitung ||Vij||
-
- Menginisialisasi Vij:
β • Vij (lama )
j
Dimana ,
-
n = jumlah unit input
-
p = jumlah unit tersembunyi
-
ß = faktor skala
Menentukan bias antara unit input dan unit tersembunyi dengan bilangan acak antara (-ß dan ß)
Metode Penelitian yang digunakan Penelitian ini adalah sebagai berikut:
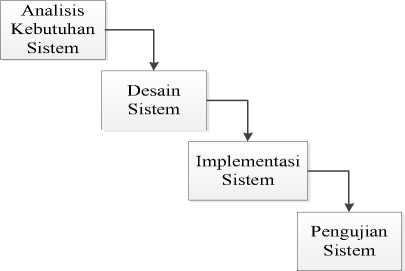
Gambar 2. Metodelogi Penelitian
-
1. Analisis kebutuhan sistem, pada tahapan ini akan dilakukan pencarian kebutuhan awal sistem, seperti ciri-ciri/fitur yang dapat digunakan untuk mengenali suatu jenis tanaman
-
2. data yang dikumpulkan pada tahap analisis akan menjadi masukan dalam desain sistemTahap selanjutnya adalah implementasi dari desain sistem. Implementasi dari sistem menggunakan matlab 2010a.
Di penelitian ini, langkah-langkah yang dilakukan adalah (i) Pengumpulan dataset, (ii) Merancang modul backpropagation, (iii) Mengimplementasikan modul backpropagation, dan (iv) Merancang modul nguyen widrow, (v) mengimplementasikan modul nguyen widrow, (vi) melakukan evaluasi atau ujicoba terhadap sistem yang dibangun. Adapun alur metodologi penelitian dapat dilihat pada Gambar 3.
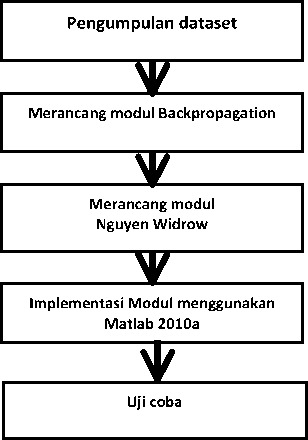
Gambar 3.Alur Desain Sistem
Adapun antarmuka yang dihasilkan dari penelitian ini adalah tampak pada gambar 4. Gambar 4 adalah antarmuka utama yang akan ditemui oleh pengguna saat pertama kali. Antar muka ini mengendung beberapa tombol yang dapat digunakan yaitu Chose Folder, Feature Extraction, Multi layer Perceptron, Clear all data. Tombol Chose Folder digunakan untuk memilih folder dataset yang akan digunakan pada proses training
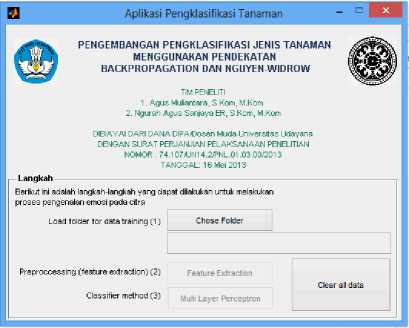
Gambar 4. Antar Muka Utama
untuk melakukan testing, dapat dipilih 2 cara yaitu menguji sekumpulan data atau 1 data saja. Jika dipilih menguji sekumpulan data maka tombol MLP folder testing yang harus ditekan, sehingga memunculkan pilihan folder tempat data uji diletakkan. Seperti tampak pada gambar 5.
Gambar 5. Pemilihan folder testing
Percobaan yang pertama kali dilakukan adalah mencari seberapa banyak node hidden layer yang akan digunakan. Dari beberapa kali percobaan didapatkan hasil seperti tampak pada table 1:
Tabel 1 Pengaruh Node Hidden Layer pada Akurasi
|
Hidden Layer |
Rata-rata Akurasi |
|
10 |
90% |
|
11 |
89% |
|
12 |
89% |
|
13 |
89% |
|
14 |
87% |
Jika ditampilkan dalam bentuk grafik didapatkan hasil seperti tampak pada gambar 6.
Pada table maupun grafik tampak bahwa jumlah hidden layer yang optimal adalah sejumlah 10 buah node hidden layer. Hal ini ditunjukkan dengan nilai akurasi yang paling tinggi yaitu sebesar 90%.
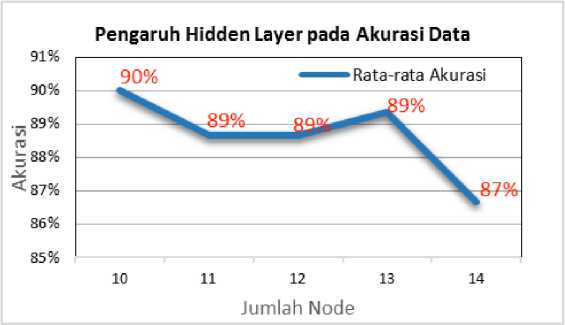
Gambar 6. Grafilk Pengaruh Jumlah Node Hidden Layer
pada Akurasi
Setelah nilai node hidden layer didapatkan maka dilakukan 15 kali percobaan menggunakan 10 node hidden layer. Dari 15 kali percobaan diujikan 7 kali dataset testing yang berbeda-beda sehingga total didapatkan 105 kali uji coba. Data set yang digunakan sengaja divariasikan dengan maksud menguji seberapa handal system dapat mengenali daun yang sebelumnya belum pernah dikenali oleh system. Dari hasil penelitian didapatkan nilai akurasi yang cukup tinggi yaitu rata-rata diatas 83%, nilai akurasi maksimum adalah 100% dan nilai minimum akurasi adalah 73%. Hasil percobaan secara lengkap dapat dilihat pada table 2. Hal ini berbeda dengan nilai akurasi system yang tidak menggunakan Nguyen Widrow sebagai alat bantu inisialisasi awal bobot. Adapun data percobaan yang tidak menggunakan inisialisasi Nguyen Widrow ditampilkan pada table 3.
Tabel 2. Hasil percobaan Backpropagation + Nguyen Widrow
|
percobaa n |
hasil testing | |||||||||
|
a |
b1 |
b2 |
b3 |
b4 |
b5 |
b6 |
c |
rata-rata |
stdev | |
|
1 |
70.83% |
90.91% |
100.00% |
72.73% |
90.91% |
90.91% |
86.36% |
70% |
84% |
11% |
|
2 |
70.83% |
90.91% |
100.00% |
72.73% |
90.91% |
90.91% |
86.36% |
70% |
84% |
11% |
|
3 |
58.33% |
86.36% |
100% |
72.73% |
81.82% |
90.91% |
90.91% |
75% |
82% |
13% |
|
4 |
62.50% |
81.82% |
100% |
72.73% |
81.82% |
81.82% |
90.91% |
70% |
80% |
12% |
|
5 |
62.50% |
86.36% |
100% |
81.82% |
81.82% |
90.91% |
90.91% |
75% |
84% |
11% |
|
6 |
70.83% |
81.82% |
90.91% |
81.82% |
72.73% |
90.91% |
86.36% |
75% |
81% |
8% |
|
7 |
70.83% |
90.91% |
90.91% |
72.73% |
90.91% |
81.82% |
86.36% |
75% |
82% |
9% |
|
8 |
79.17% |
86.36% |
100% |
81.82% |
81.82% |
90.91% |
90.91% |
85% |
87% |
7% |
|
9 |
79.17% |
90.91% |
100% |
81.82% |
90.91% |
90.91% |
86.36% |
85% |
88% |
7% |
|
10 |
70.83% |
90.91% |
90.91% |
72.73% |
90.91% |
81.82% |
86.36% |
80% |
83% |
8% |
|
11 |
75% |
90.91% |
100% |
81.82% |
90.91% |
90.91% |
86.36% |
75% |
86% |
9% |
|
12 |
83.33% |
90.91% |
100% |
81.82% |
81.82% |
90.91% |
90.91% |
85% |
88% |
6% |
|
13 |
64% |
86% |
90.91% |
72.73% |
90.91% |
81.82% |
86.36% |
75% |
81% |
10% |
|
14 |
75% |
86.36% |
90.91% |
72.73% |
90.91% |
72.73% |
86.36% |
75% |
81% |
8% |
|
15 |
62.50% |
81.82% |
90.91% |
72.73% |
81.82% |
81.82% |
86.36% |
75% |
79% |
9% |
Tabel 3. Hasil percobaan Backpropagation tanpa Nguyen Widrow
|
percobaan |
hasil testing | |||||||||
|
a |
b1 |
b2 |
b3 |
b4 |
b5 |
b6 |
c |
rata-rata |
stdev | |
|
1 |
45.83% |
67.91% |
76.00% |
44.73% |
63.91% |
66.91% |
62.36% |
41.00% |
59% |
13% |
|
2 |
45.83% |
67.91% |
76.00% |
44.73% |
63.91% |
66.91% |
62.36% |
41.00% |
59% |
13% |
|
3 |
33.33% |
63.36% |
76.00% |
44.73% |
54.82% |
66.91% |
66.91% |
46.00% |
57% |
14% |
|
4 |
37.50% |
58.82% |
76.00% |
44.73% |
54.82% |
57.82% |
66.91% |
41.00% |
55% |
13% |
|
5 |
37.50% |
63.36% |
76.00% |
53.82% |
54.82% |
66.91% |
66.91% |
46.00% |
58% |
13% |
|
6 |
45.83% |
58.82% |
66.91% |
53.82% |
45.73% |
66.91% |
62.36% |
46.00% |
56% |
9% |
|
7 |
45.83% |
67.91% |
66.91% |
44.73% |
63.91% |
57.82% |
62.36% |
46.00% |
57% |
10% |
|
8 |
54.17% |
63.36% |
76.00% |
53.82% |
54.82% |
66.91% |
66.91% |
56.00% |
61% |
8% |
|
9 |
54.17% |
67.91% |
76.00% |
53.82% |
63.91% |
66.91% |
62.36% |
56.00% |
63% |
8% |
|
10 |
45.83% |
67.91% |
66.91% |
44.73% |
63.91% |
57.82% |
62.36% |
51.00% |
58% |
9% |
|
11 |
50.00% |
67.91% |
76.00% |
53.82% |
63.91% |
66.91% |
62.36% |
46.00% |
61% |
10% |
|
12 |
58.33% |
67.91% |
76.00% |
53.82% |
54.82% |
66.91% |
66.91% |
56.00% |
63% |
8% |
|
13 |
39.00% |
63.00% |
66.91% |
44.73% |
63.91% |
57.82% |
62.36% |
46.00% |
55% |
11% |
|
14 |
50.00% |
63.36% |
66.91% |
44.73% |
63.91% |
48.73% |
62.36% |
46.00% |
56% |
9% |
|
15 |
37.50% |
58.82% |
66.91% |
44.73% |
54.82% |
57.82% |
62.36% |
46.00% |
54% |
10% |
Grafik perbandingan hasil penelitian dapat dilihat pada gambar 13. Dimana pada grafik tampak perbandingan antara system yang menggunakan
Nguyen Widrow dan system yang tidak menggunakan Nguyen Widrow.
Hasil Percobaan

≡ Rata-Rata BP+NW i Rata-rata BP
Gambar 13. Grafik perbandingan system dengan Nguyen Widrow dan tanpa Nguyen Widrow
Tampak dengan jelas bahwa rata-rata akurasi dari system Backpropagation + Nguyen Widrow (batang berwarna biru-ttik) rata-rata lebih tinggi dibandingkan system yang tidak menggunakan Nguyen Widrow (batang berwarna merah-garis). Hal ini menunjukkan bahwa penambahan Nguyen Widrow pada inisialisasi awal Backpropagationsangat membantu meningkatkan akurasi/ketepatan system dalam mengenali objek yang dilatih.
Berdasarkan hasil penelitian yang dilakukan didapatkan bahwa penambahan modul nguyen widrow mampu meningkatkan akurasi system. Hal ini sangat sesuai dengan apa yang menjadi teori dari nguyen widrow. Karena inisialisasi bobot backpropagarion yang pada awalnya random (acak) dibuat mendekati karakteristik dari jaringan backpropagationn yang dibentuk
Berdasarkan hasil penelitian didapatkan beberapa kesimpulan yaitu :
-
1. Backpropagation dan Nguyen Widrow dapat diimplementasikan dalam system pengenalan daun dengan rata-rata akurasi sebesar 83%.
-
2. Penambahan modul Nguyen Widrow dapat meningkatkan akurasi pengenalan system terhadap objek yang diteliti. Dalam hal ini adalah objek daun.
Adapun saran yang dapat diberikan adalah sebagai berikut : Akurasi ini akan bertambah sesuai dengan pertambahan jumlah data training, karena Akurasi terhadap data testing masih bisa dianggap kurang sehingga untuk penelitian kedepan, perlu diadakan perubahan terhadap teknis yang ada pada metode ini
Hong Kong, China, 20-22 October 2004, pp. 165-168.
-
[3] H. Fu, and Z. Chi, “Combined thresholding and neural network approach for vein pattern extraction from leaf images”, in Proceeding of Vision, Image and Signal Processing, Vol. 153, Issue. 6, December 2006, pp. 881-892.
-
[4] H. Fu, and Z. Chi, “A Two-Stage Approach for Leaf Vein Extraction”, in Proceeding on International Conference on Neural Network & Signal Processing, Nanjing, China, 14-17 October 2003, pp. 208-211.
-
[5] Howard Demuth and Mark Beale. Neural Network Toolbox, User’s Guide, Version 4. The MathWorks, Inc., Natick, MA, revised for version 4.0.4 edition, October 2004. http://www.mathworks.com.
-
[6] J. Pan, and Y. He, “Recognition of plant by leaves digital image and neural network”, in Proceeding of International Conference on Computer Science and Software Engineering, Wuhan, Hubei, China, 12-14 December 2008, pp. 906-910.
-
[7] Pornpanomchai, Chomtip, “Leaf and Flower Recognition System (e-Botanist)“, in IACSIT International Journal of Engineering and Technology, Vol.3, No.4, August 2011, pp. 347-351.
-
[1] Derrick Nguyen and Bernard Widrow. Improving the learning speed of 2-layer neural networks by choosing initial values of the adaptive weights. Proceedings of the International Joint Conference on Neural Networks, 3:21–26, 1990.
-
[2] G.J. Zhang, X.F. Wang, D.S. Huang, Z. Chi, Y.M. Cheung, J.X. Du, and Y.Y. Wan, “A Hypershere Method For Plant Leaves Classification”, in Proceeding of the International Symposium on Intelligent, Multimedia, Video and Speech Processing,
Discussion and feedback