Description of Phonology, Characteristics, and Determination of the Origin Language of Waisika
on

e-Journal of Linguistics

Available online at https://ojs.unud.ac.id/index.php/eol/index
Vol. 15, No. 1, January 2021, pages: 25-39
Print ISSN: 2541-5514 Online ISSN: 2442-7586
https://doi.org/10.24843/e-jl.2021.v15.i01.p04
Description of Phonology, Characteristics, and Determination of the Origin Language of Waisika
I Wayan Agus Anggayana1
Akademi Komunitas Manajemen Perhotelan Indonesia, Badung, Indonesia anggayana28@gmail.com
I Nyoman Suparwa2
Denpasar, Indonesia nym_suparwa@unud.ac.id
Ni Made Dhanawaty3
Denpasar, Indonesia md_dhanawaty@unud.ac.id
I Gede Budasi4
Singaraja, Indonesia
Article info
Received Date: 18
September 2020
Accepted Date: 21
September 2020
Published Date: 31 January 2021
Keywords:*
Comparative historical linguistics, Phonology, Language of Waisika
Abstract*
This study aims to describe the Waisika language carried out in the Northeast Alor sub-district based on the observation point, which was the object of research. This research uses quantitative and qualitative approaches. In diachronic research methods, there are two main methods in facilitating the direction of research, namely quantitative methods and qualitative methods. Application of minimal pairing procedures and similar environments, it can be found that all vocoids sound in Waisika is vocal segments /a, i, u, e, o/. Application of minimal pairing procedures and similar environments, it can be found that all contoid sounds are consonant segments [p, b, mb, t, nt, d, k, g, nd, h, s, m, n, Ν, Νk, l, r, w]. Five vowel phonemes, which are found to have complete distribution at the front, central, and back of the morpheme. The phoneme /mb/, /nt/, /d/, /k/, /nd/, /r/, /w/ only exists in the initial and middle position of words. The phonemes /Νk/ are only in the central position of words. The phonemes /Ν/ are only in the central and back positions.
consonant phonemes; likewise, the distribution of phonemes consists of the distribution of vowel and consonant phonemes; and distinguishing characteristics are adjusted to the conditions. This research discusses phonological descriptions, the characteristics of Waisika in the determination of the origin. The primary energy source in terms of language sounds is the presence of air through the lungs. Air is sucked into the lungs and exhaled together at the time of breathing. The air that is exhaled gets a small or complete obstruction in various places, and in multiple ways, it causes the sound of the language. When the air comes out through the lungs, the vocal cords will open so that the air does not happen obstacle when breathing and does not cause language sounds (Pike, 1948: 3-4).
Language sounds can be divided into two, namely segmental sounds and suprasegmental sounds. Segmental sounds are language sounds that can be solved or segmented in one segment or can be said to be sounds that are produced independently and can be separated. In contrast, suprasegmental sounds are the opposite of segmental sounds. Suprasegmental sound elements can be separated into several segments; this element always integrates with segmental sound; its presence is very influential for segmental sound, in the form of pressure, tone, and tempo (O'grady et al., 1989: 14-36). There are four basic requirements for language sounds, namely, the process of air release, phonation, articulation, and oro-nasal processes (Fromkin & Ladefoged, 1981: 2-3). Industries are entirely and highly aware of the importance of language proficiency and they need to have good command (Budasi & Anggayana, 2019). Language is one of the most critical aspects in communication and cannot be separated from our daily activities (Anggayana, Budasi, & Kusuma, 2019). It is also can be beneficial in teaching learning process, because key component in language teaching which is the basis for learners when learning languages (Sudipa, Aryati, Susanta, & Anggayana, 2020).
This research uses quantitative and qualitative approaches. In general, in diachronic research methods, there are two main methods in facilitating the direction of research, namely quantitative methods and qualitative methods. The quantitative method is used for the compilation and classification of the kinship of the Alor Island languages and to find out their kinship rank. Quantitative language kinship data makes it easier to conduct qualitative research, and the findings in quantitative research are a working hypothesis for qualitative research. In determining the evidence for the classification of related languages and their grouping, it is completed in a qualitative method.
Relative languages can be divided into two groups, namely languages that fall into one group (unifying the group) and languages outside the group (group separator). To determine evidence qualitatively. The language data obtained in the field were quantitatively reconstructed, either with a bottom-up approach or through a top-down approach. The bottom-up reconstruction technique yields proto-languages at low rank and proto-languages at the meso-language status (pro-languages at the intermediate level). The top-down reconstruction technique aims to test the reliability of the reconstruction results, both in low-level proto-languages and meso-languages. Evidence achieved by establishing a bottom-up reconstruction, whether in the form of unified evidence or exclusively shared innovation obtained from bottom-up studies after complemented by evidence of mutual innovation exclusively from the top-down reconstruction. It can provide significant evidence for the grouping of languages in the Alor archipelago.
Literature Review
La Ino (2013) and Adhiti (2015) are concerned about the linguistic aspects of the Alor islands. The following is a review of these studies. La Ino (2013) researched "Protobahasa
Modebur, Kaera, and Teiwa, languages of non-Austronesian relatives in Pantar Island, East Nusa Tenggara". The methods used for data analysis are syncomparative and comparative methods. Based on the quantitative evidence in this study, two groups of languages were found, namely the Austronesian and non-Austronesian groups. It classified as non-Austronesian groups are Modebur, Kaera, and Teiwa languages, with quantitative evidence in the form of cognate similarity reaching a mean percentage of 56% and the lower level reaching 71%. The qualitative evidence is in the form of a joint exclusive phonological and lexical innovation. A number of innovative vocabularies were found, both in the Modebur-Kaera-Teiwa language group and the Modebur-Kaera language sub-group. After reconstruction, it was found that the Modebur-Kaera-Teiwa Proto-languages phoneme system. It has the number of segmental phonemes, namely five vowel phonemes with complete distribution and sixteen consonants that are completely distributed, at the beginning and in the middle, as well as in the middle and end of words.
Adhiti's research (2015) examined "the kinship of Kabola language, Hamap language, language and clones on Alor Island". In Adhiti's research, the comparative method is syncomparative and comparative with comparative historical linguistic theory. This study examines the relationship between the three languages in Alor Island based on a comparative historical linguistic theory with quantitative and qualitative studies that are syncomparative and comparative. In lexicostatistics, the highest percentage between Kabola and Hamap is found, namely 53%. The percentage of Hamap and Klon languages reaches 46%. Furthermore, the percentage of Kabola and Klon reached 36%, which is the lowest percentage. Research on language relations in Alor regency is significant to do with sustainability knowing the genealogy of local language Austronesian or Non-Austronesian (Anggayana, Suparwa, Dhanawaty, & Budasi, 2020).
The Waisika phonology study includes (1) an inventory of sounds, (2) identification of sounds, (3) phoneme distribution, and (4) the distinguishing characteristics of Waisika phonemes. Sound inventory includes an inventory of vocoids and contoids. Phoneme identification has the identification of vowel phonemes and consonant phonemes; likewise, the distribution of phonemes consists of the distribution of vowel phonemes and consonant phonemes; and the distinguishing characteristics of the Waisika phonemes based on the Waisika language situation. These four things are presented below.
Inventory of Waisika’s Sounds
The study of the inventory of Waisika sounds includes vocoid, contoid sounds, and then phonemes are identified, which include vocal segments, consonant segments. The following describes the sound classification and identification of the phonemes.
Waisika Vocoid Sound
Here are some data that contain vocoid.
-
1) [al.ma.kaΝ] ‘person’
-
2) [gal.mu.tei] ‘they’
-
3) [ga.bu.ta] ‘back of the body’
-
4) [ku.wi] ‘dog’
-
5) [a.to.yi] ‘bird’
-
6) [lu.wu.ra] ‘leaf’
-
7) [ka.ri:] ‘house’
-
8) [su.mu.wi] ‘wind’
-
9) [i.ye.i] ‘laughs’
-
10) [go.sul] ‘open’
-
11) [ma.lo:] ‘walking’
-
12) [su.pul] ‘spit’
Based on the above data, five vocoid were found in the Waisika language. More details can be seen in the following data.
-
[a] contained in the data [awu.ka] ‘dry’, [i.ya.i] ‘below’, [na] ‘no’
-
[i] contained in the data [il] ‘you’, [sil] ‘we’, [la.mi] ‘male’
-
[u] contained in the data [uh.mi] ‘fruit’, [dum] ‘child’, [sa.fu] ‘fog’
-
[e] contained in the data [eg.lah] ‘left’, [ga.ke.yi] ‘tongue’, [ku.me] ‘snake’
-
[o] contained in the data [o.ho.wi] ‘far’, [go.ne.yi] ‘name’, [go.wu.ko] ‘mother’
Diagram 1. Waisika Vocoid
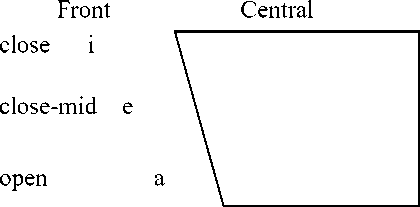
Back
u
o
Waisika Contoid Sounds
Data shows that the contoid in Waisika consist of 21 types, namely [p, b, mb, t, nt, d, k, g, /, nd, h, s, m, n, Ν, Nk, l, r, w, w, y]. The data below shows the sounds of the Waisika contoid.
-
[p] contained in the data [pi.ya] ‘other’
-
[b] contained in the data [ba.ta/ ‘cut’
[mb] contained in the data [mbi.ye.ta] ‘afraid’
-
[t] contained in the data [tit.la] ‘night’
[nt] contained in the data [ntu.i] ‘rat’
-
[d] contained in the data [da.fe] ‘needle’
-
[k] contained in the data [ka.pe] ‘string’
-
[g] contained in the data [ge.la.mi] ‘husband’
[/] contained in the data [ga.to7∖ ‘stomach’
[nd] contained in the data [ndah.ta] ‘black’
-
[h] contained in the data [ga.weh] ‘tooth’
-
[s] contained in the data [su.be] ‘chicken’
-
[m] contained in the data [i.sel.ma] ‘meat’
-
[n] contained in the data [a.man] ‘roof’
-
[Ν] contained in the data [pa.raΝ∖ ‘wet’
[Nk] contained in the data [ su.Nka.bi.ta ∖ ‘ancestor’
-
[l] contained in the data [la.pay] ‘long’
-
[r] contained in the data [ma.ri.ta] ‘sick’
-
[w] contained in the data [wa.tu] ‘day’
[w] contained in the data [go.wu.ko] ‘mother’
[y] contained in the data [go.ne.yi] ‘name’
The contoid segmental elements above can be described in table 1. The following is a Waisika phonetic diagram. This table refers to the IPA symbol proposed by Odden (2013).
Table 1. Waisika Contoid Sounds
|
Bilabial |
Alveolar |
Palatal |
Velar |
Glottal | ||
|
Sound Barrier |
voiceless |
p |
t |
k |
/ | |
|
voice |
b |
d |
g | |||
|
Frikatif |
voiceless |
h | ||||
|
voice |
s | |||||
|
Nasal |
m |
n |
Ν | |||
|
Prenasal |
voiceless |
mb |
nd |
Nk | ||
|
voice |
nt | |||||
|
Lateral |
l | |||||
|
Trill |
r | |||||
|
Semi vocal |
w w |
y | ||||
Identification of Waisika’s Phonemes
In identifying sounds, become phonemes. In general, there are three procedures performed, namely 1) with a minimum pair, 2) similar environment, and 3) complementary distribution. These three procedures are used to determine that the status of the contrasted sounds is a different segment or phoneme.
Waisika’s Vocal Segment
In determining the status of the vocoid sounds above, minimal pairing procedures and similar environments are applied, as in the following data.
|
(1) |
[i] and [u] [la.mi] ‘male’ |
|
[la.mu] ‘wound’ | |
|
(2) |
[i] and [e] [wu.yi.ma.i] ‘coolie’ [wu.yi.ma.e] ‘prisoner of war’ |
|
(3) |
[i] and [a] [nil] ‘us’ [nal] ‘I’ |
|
(4) |
[i] and [o] [sil] ‘we’ [sol] ‘right’ |
|
(5) |
[e] and [a] [ge.la.mi] ‘husband’ [ga.la.mi] ‘he is a man’ |
|
(6) |
[e] and [u] [ke.wi] ‘reed’ [ku.wi] ‘dog’ |
|
(7) |
[e] and [o] [se./ ‘grass’ [so./ ‘basket’ |
|
(8) |
[a] and [u] [ta.wa.yi] ‘sea slug’ |
[ta.wu.yi] ‘bean’
[wa.i] ‘goat’
[wu.i] ‘moon’
Based on the application of minimal pairing procedures and similar environments, it can be found that all vocoids sound in Waisika is vocal segments / a, i, u, e, o /.
Waisika’s Consonant Segment
The following procedure applies the minimum pair and the same environment to identify whether the contoid sounds based on table 1 are phonemic or allophonic segments.
|
(1) |
[p] and [b] [ga.pa.ta] ‘wings’ [ga.ba.ta] ‘land’ |
|
(2) |
[p] and [w] [ga.pa] ‘father’ [ga.wa] ‘mouth’ |
|
(3) |
[n] and [m] [nal] ‘I’ [mal] ‘delicious’ |
|
(4) |
[m] and [p] [a.mi] ‘milk’ [a.pi] ‘cork fish’ |
|
(5) |
[m] and [n] [a.mi] ‘milk’ [a.ni] ‘nipples’ |
|
(6) |
[b] and [mb] [bul] ‘fells’ [mbul] ‘blunted’ |
|
(7) |
[w] and [h] [ta.wan] ‘puzzle’ [ta.han] ‘not yet’ |
|
(8) |
[w] and [l] [wa.i] ‘goat’ [la.i] ‘already’ |
|
(9) |
[t] and [p] [ga.to/] ‘stomach’ [ga.po/] ‘cheek’ |
|
(10) |
[t] and [s] [ba.ta/] ‘cut’ [ba.sa/] ‘noni’ |
|
(11) |
[h] and [t] [to.mo.moh] ‘social gathering’ [to.mo.mot] ‘carry’ |
|
(12) |
[d] and [t] [da.u] ‘petai’ [ta.u] ‘rattan’ |
|
(13) |
[n] and [h] [go.bun] ‘delicer’ [go.buh] ‘reconnaissance’ |
|
(14) |
[nt] and [t] [ge.wa.ntui] ‘calf’ [ge.wa.tui] ‘ankle’ |
|
(15) |
[nd] and [l] [ta.wend] ‘bean’ [ta.wel] ‘flowing’ |
|
(16) |
[l] and [s] [ge.la] ‘base’ [ge.sa] ‘custom’ |
|
(17) |
[s] and [b] [ge.sa] ‘custom’ [ge.ba] ‘sword’ |
|
(18) |
[nd] and [d] [ge.ndol] ‘bay’ [ge.dol] ‘valley’ |
|
(19) |
[p] and [r] [ka.pe] ‘rope’ [ka.re] ‘energy’ |
|
(20) |
[l] and [k] [la.i.ta] ‘shame’ [ka.i.ta] ‘trap’ |
|
(21) |
[k] and [s] [ki.rit] ‘small’ [si.rit] ‘oil’ |
|
(22) |
[g] and [b] [ga.wa.i] ‘ear’ |
[ba.wa.i] ‘onion’
|
(23) |
[Ν] and [k] [i.wa.Νa] ‘swing’ [i.wa.ka] ‘vomit’ |
|
(24) |
[Nk] and [k] [so.Nko] ‘skullcap’ [so.ko] ‘clothing bug’ |
|
(25) |
[h] and [n] [go.buh] ‘reconnaissance’ [go.bun] ‘deliver’ |
|
(26) |
[h] and [w] [ta.han] ‘not yet’ [ta.wan] ‘puzzle’ |
|
Based |
on the application of minimal pairing procedures and similar environments, it can be |
found that all contoid sounds are consonant segments [p, b, mb, t, nt, d, k, g, nd, h, s, m, n, Ν, Nk, l, r, w].
Distribution of Waisika Phonemes
The distribution of phonemes can be divided into two, namely the distribution of vowel phonemes and the distribution of consonant phonemes. The following two distributions are presented.
Distribution of Waisika Vocal Segments
Distribution
Phonemes
|
Front |
Central |
Back | |
|
/a/ |
[awu.ka] ‘dry’ [al.ma.i] ‘warehouse’ [a.we.i] ‘hook’ |
[i.ya.i] ‘below’ [keΝ.na.mut]‘eyebrows [ga.wa.bah] ‘lips’ |
[na] ‘no’ ’ [geΝ.la.bu.ta] ‘eyelashes’ [ga.pu.na] ‘forehead’ |
|
/i/ |
[i.di.ka] ‘sister’ [i.li.goT] ‘porridge’ [i.a.waΝ.i.li] ‘honey’ |
[ go.wo.ha.i/] ‘ shoulder’ [ga.ra.liΝ ‘molars’ [ge.ih] ‘body’ |
[go.toΝ.tu.i] ‘calf [ga.pu.i] ‘male genitalia’ [ge.ta.i] ‘thigh’ |
|
/u/ |
[u.was] ‘yam’ [u.ku.wa] ‘dove’ [u.wet] ‘monitor lizard’ |
[ga.ua.mut] ‘beard’ [ga.buΝ.ta] ‘shoulders’ [ga.taΝ.bu/ ‘elbow’ |
[su] ‘mines’ [ ka.waΝpu ] ‘turmeric’ [da.u] ‘petai’ |
|
/e/ |
[e.go.wu.kan] ‘punish’ [e.ma] ‘segment’ [eg.lah] ‘left’ |
[ge.ko.raΝ] ‘chest’ [ga.taΝ.la.e.sa/ ‘thumb’ [ga.te.a/ ‘armpit’ |
[pa.e.ka.pe] ‘clothesline’ [da.pe] ‘needle’ [pe.e] ‘pig’ |
|
/o/ |
[o.saΝpa/ ‘cottage’ [pa.noΝ.kaΝ] ‘cool’ [oh] ‘shrimp’ The data above can be |
[boΝ] ‘wood’ [i.li.ta.ko] ‘river estuary’ [o.Νap] ‘chisel’ [si.ra.go] ‘beach’ [mo.ko/ ‘stupid’ [ga.miΝ.go] ‘edge’ seen that the five vowel phonemes, which are found to have | |
complete distribution at the front, central, and back of the morpheme.
Distribution of Waisika Consonant Segments
Based on the number of consonant phonemes found, the following is a description of the distribution of the Waisika consonant phonemes.
Distribution
Phonemes
Front
/p/ [pa.cul] ‘hoe’
Central
[ga.po/ ‘cheek’
Back
[o.Νap] ‘chisel’
|
[pa.e.ka.pe ] 'clothesline'[o.sαΝpα/]‘heirloom’ [ su.nup ] ‘cricket’ | |
|
[pa.liΝ] [pa.liΝ.po∕∖ [ ga.pa.ra.i.ga.ne.up ] ‘ax’ ‘star fruit’ ‘moist’ | |
|
/b/ |
[bit] ‘mat’ [we.ba.i] ‘flood’ [beb] ‘lava’ [ba.ru∕ [ge.la.bu.ta∕ ‘pants’ ‘pubic hair’ [boh.go.ba] ‘sin’ [ti.loh.bu∕ ‘sideburns’ |
|
/mb/ |
[mba] ‘cage’ [ge.mbah] ‘skin’ [mbos.la∕ ‘mattress’ [te.Νa.mbah] ‘eye patch’ [mbi.li∕] [ga.mbuk.mag] ‘frying spoon’ ‘ceiling’ |
|
/t/ |
[ta.suk.siΝ] ‘sweat’ [ga.taΝ.le.i] ‘finger’ [ga.ua.mut] ‘beard’ [ta.ge.ti.loh.bu∕ [ga.taΝ.tu.i∕ [ gewe.it ] ‘esophagus’ ‘arm’ ‘place’ [teΝ.ba.na.ta] [ge.ti.loh.bu∕] [woΝ.tam.si.ge.we.it] ‘cheek’ ‘lungs’ ‘kitchen’ |
|
/nt/ |
[nta.sak.sel] ‘hips’ [ne.na.nteh] ‘son-in-law’ [ntek.bu∕ ‘limbs’ [tawoΝ.nta.pan] ‘gave birth’ [nta.mu.kuΝ] ‘village head’ [wu.ntiΝ] ‘pole’ |
|
/d/ |
[de.hiΝ] ‘furnace’ [man.de.ge.sa] ‘traditional leader’ [ta.wend] ‘bean’ [di.si.pun] ‘community service’ [ku.wi.dum] ‘puppy’ [ da.pe ] ‘needle’ [a.riΝ.da] ‘insect’ |
|
/k/ |
[ka.ma.ra.mi] ‘room’ [ta.suk.siΝ] ‘sweat’ [ka.u.pa.i.be] ‘buffalo enclosure’ [sak.ba.i] ‘adult’ [ku.ra.ba] ‘horse stable’ [boh.ka.taΝ] ‘feast’ |
|
/g/ |
[ga.wa.bu∕] [ta.u.gol] [ga.mbuk.mag] ‘chin’ ‘which one’ ‘ceiling’ [ga.we.ha.mo] [al.ma.ge.tek.ba∕] [ke.ig] ‘gum’ ‘engaged’ ‘mistaken’ [ga.i.pe.i] [ak.ma.ge.sut] [lu.bug] ‘female genitals’ ‘scoop’ ‘chopsticks’ |
|
/nd/ |
[nda.waΝ] ‘medicine’ [ge.ndol] ‘bay’ [ndok.si.ge] ‘calm down’ [handu.ki.riΝ] ‘shawl’ [nde.me.i] ‘earrings’ [tak.ndi] ‘lay’ |
|
/h/ |
[ho.u.ko.gen] [leh.mah] [ga.wa.bah] ‘my mom’ ‘hanging’ ‘lips’ [handu.ki.riΝ] [ ta.keh.tawal ] [ge.mbah] ‘shawl’ ‘cross-legged’ ‘skin’ [ ha.ri.ma.o ] [ da.wa.i.ma.ha ] [te.Νa.mbah] ‘tiger’ ‘gall’ ‘eye patch’ |
|
/s/ |
[si.muh] [ga.sa∕] [u.was] ‘we’ ‘waist’ ‘yam’ [ni.niΝ.su∕] [ga.se.iΝ] [a.li.as] ‘three of us’ ‘ribs’ ‘deflated’ [sak.ba.i] [ge.suΝ] [ge.las] ‘adult’ ‘grandchildren’ ‘glass’ |
|
/m/ |
[ma.de.ge.sa] ‘traditional leader’ |
[buΝ.mo.i] ‘papaya’ |
[ne nah ge rum] ‘older brother’ |
|
/n/ |
[meg.pa.eΝ] ‘bury’ [mo] ‘bow’ [nu.a.ga.lil.na] |
[sug.ma.li] ‘green snake’ [geΝ.mi.bu.ta.ra] ‘dizzy’ [tah.na.na] |
[ne.kah.ge.dum] ‘sister child’ [ni.tam] ‘grandma’ [ne.gen] |
|
/Ν/ /Νk/ /l/ |
‘wasteful’ [nu.a.ge.kaΝ] ‘smart’ [nu.a.lo.ta/] ‘poor’ [la.mug] |
‘easy’ ‘drink’ [ge.i.nek.mal] [ton] ‘soundly’ ‘jackfruit’ [bok.na] [to.on] ‘hit’ ‘bamboo’ [keΝ.na.mut] [boh.ka.taΝ] ‘eyebrows’ ‘feast’ [go.toΝ.tu.i] [nta.mu.kuΝ] ‘calf’ ‘traditional leader’ [geΝ.la.bu.ta] [sa.me.i.boΝ] ‘eyelashes’ ‘banyan’ [su.Νka.bi.ta] ‘ancestor’ [a.ni.Νku.wi] ‘termite’ [pu.o.Νka.Ν] ‘beautiful’ [pe.liΝ] [ge.kul] | |
|
/r/ /w/ |
‘swallow’ [let.lag] ‘kick’ [la.i] ‘already’ [ri.bu.we.i.siΝ] ‘five thousand’ [ri.bu.no/] ‘one thousand’ [ra.mi.lu.te.i] ‘youth’ [wu.yi.ma.e] ‘prisoner of war’ [wa.i] ‘goat’ [wa.te.ge.pa.sa] ‘coconut pulp’ The data above can |
‘pickaxe’ ‘skin’ [te.u.wi.la.paΝ] [geΝ.pul] ‘log bean’ ‘butt’ [po.lil] [nta.sak.sel] ‘hand bracelets’ ‘hips’ [ga.ra.liΝ] ‘molars’ [ke.ri.go.wu.ko] ‘side porches’ [ge.re.i] ‘down’ [ge.ku.we.i] ‘anal’ [wu.to.i.wu.ra] ‘vegetable’ [su.rat.wu.ra] ‘paper’ be seen that the consonants phonemes, which are found to have | |
complete distribution at the front, central, and back of the morpheme. However, based on the data captured, the phoneme /mb/, /nt/, /d/, /k/, /nd/, /r/, /w/ only exists in the initial and middle position of words. The phonemes /Νk/ are only in the central position of words. The phonemes /Ν/ are only in the central and back positions.
The canonical pattern of the Waisika language
The canonical pattern of the Waisika language is based on twelve data. The origin of this morpheme can form the following pattern.
|
1) |
Pattern V ([+sil]) data: /a/ [a] |
‘this’ |
|
2) |
Pattern CV ([-sil] [+sil]) data: /ba/ [ba] |
‘fence’ |
|
Pattern V-V ([+sil]-[+sil]) data: /au/[awu] |
‘deer’ | |
|
3) |
Pattern V-CV ([+sil]-[-sil] [+sil]) data: /awi/ [a.wi] |
‘fishing line’ |
|
4) |
Pattern CV-V ([-sil] [+sil]-[+sil]) data: /dau/ [da.u] |
‘petai’ |
|
5) |
Pattern CV-CV ([-sil] [+sil]-[-sil] [+sil]) data: /geli/ [ge.li] |
‘veins’ |
6) Pattern CV-V-V ([-sil] [+sil]-[+sil]-[+sil]) data: /buei/ [bu.we.i] ‘flies’
-
7) Pattern CV-CV-CV ([-sil] [+sil]-[-sil] [+sil]-[-sil] [+sil]) data: /kabuba/ [ka.bu.ba] ‘warm’
-
8) Pattern CV-V-CV ([-sil] [+sil]-[+sil]-[-sil] [+sil]) data: /weili/ [we.i.li] ‘rear’
-
9) Pattern CV-CV-V ([-sil] [+sil]-[-sil] [+sil]-[+sil]) data: /kanui/ [ka.nu.wi] ‘flute’
-
10) Pattern V-CV-CV ([+sil]-[-sil] [+sil]-[-sil] [+sil]) data: /atowi/ [a.to.wi] ‘grouse’
-
11) Pattern VV-CV ([+sil] [+sil]-[-sil] [+sil]) data: /auka/ [awu.ka] ‘dry’
Based on the data above, the canonical pattern of the Waisika language can be found as follows.
-
1) Single-canonical pattern:
-
a. V
-
b. CV
-
2) A canonical pattern of two tribes:
-
a. V-V
-
b. V-CV
-
c. CV-V
-
d. CV-CV
-
e. VV-CV
-
3) A canonic pattern of three tribes:
-
a. CV-V-V
-
b. CV-CV-CV
-
c. CV-V-CV
-
d. CV-CV-V
-
e. V-CV-CV
Thus, the canonical pattern of the Waisika language can be assessed as follows (V(C)V)(V(C)V)(V(C)V). So, in Waisika, the first syllable can be structured V, CV. Similarly, the same structure can be repeated in the second and third syllables.
Characteristics in Distinguishing Segments of Waisika Language
Explain segment characteristics by distinguishing features. There are six groups and nineteen distinguishing features. The six groups are: 1) the characteristics of the main group, 2) the features of the place of articulation, 3) the way of articulation, 4) the characteristics of the tongue, 5) additional features, and 6) the characteristics of prosody (Schane, 1992: 26-34). The following are the distinguishing features of the Waisika language segment.
-
1) The characteristics of the main group
-
(1) [+silabis]: vowels /a, i, u, e, o/
[-silabis]: explosive inhibiting phonemes /p, b, t, d, k, g, //; nasal pre-obstruction /mb, nd, nt, Nk/; frivative /s, h/; nasal /m, n, Ν/; likuida /l, r/; and semi vocal /w/.
-
(2) [+consonant]: explosive inhibiting phonemes /p, b, t, d, k, g/; nasal pre-obstruction
/mb, nd, nt, Νk/; fricative /s, h/; nasal /m, n, Ν/; likuida /l, r/
[-consonant]: vowels /a, i, u, e, o/; semi vocal /w/; glottal ///
-
(3) [+sonoran]: includes vowel phonemes /a, i, u, e, o/; semi vocal phonemes /w/; nasal
/m, n, Ν/; and likuida /l, r/.
[-sonoran]: includes explosive inhibiting phonemes /p, b, t, d, k, g, //; fricative /s, h/; and glottal ///.
-
2) The features of the place of articulation
-
(1) [+malar]: includes fricative /s, h/; likuida /l, r/; and semi vocal /w/.
[-malar]: includes explosive inhibiting phonemes /p, b, t, d, k, g, //; nasal pre-obstruction /mb, nd, Νk/; and nasal /m, n, Ν/.
-
(2) [-pts (indirect release)]: includes explosive inhibiting phonemes /p, b, t, d, k, g, //;
nasal pre-obstruction /mb, nd, Νk/; and nasal /m, n, Ν/.
-
(3) [+nasal]: includes nasal phonemes /m, n, Ν/ and nasal pre-obstruction /mb, nd, Nk/.
[-nasal]: includes explosive inhibiting phonemes /p, b, t, d, k, g, //; fricative /s, h/; likuida /l, r/; semi vocal /w/.
-
(4) [+nasal pre-obstruction]: includes nasal pre-obstruction /mb, nd, Nk/.
-
(5) [-implosive]: includes nasal pre-obstruction /mb, nd/.
-
(6) [+lateral]: includes the lateral phonemes /l/.
[-lateral]: includes fonem getar /r/.
-
(7) [+strident]: includes fricative phonemes /s/.
[-strident]: includes explosive inhibiting phonemes /p, b, t, d, k, g, //; nasal pre-obstruction /mb, nd, Νk/; nasal /m, n, Ν/; likuida /l, r/; fricative /h/.
-
3) The way of articulation
-
(1) [+anterior]: includes explosive inhibiting phonemes /p, b, t, d/; nasal pre-obstruction
/mb, nd, Νk, nt/; frikative /s/; nasal /m, n/; likuida /l, r/.
[-anterior]: includes explosively inhibiting phonemes /k, g, //; frikative /h/; nasal /N/; and semi vocal /w/.
-
(2) [+coronal]: includes explosive inhibiting phonemes /t, d/; nasal pre-obstruction /nd,
nt/; fricative /s/; nasal /n/; likuida /l, r/.
[-coronal]: includes explosive inhibiting phonemes /p, b, k, g, //; nasal pre-obstruction /mb/; fricative /h/; nasal /m, Ν/; and semi vocal /w/.
-
4) The characteristics of the tongue
-
(1) [+high]: includes vowel phonemes /i, u/; /; explosive inhibiting phonemes /k, g/; nasal /Ν/; semi vocal /w/.
[-high]: includes vowel phonemes /e, o, a/; explosive inhibiting phonemes /p, b, t, d/;
nasal pre-obstruction /mb, nd, nt/; fricative /s/; nasal /m, n/; likuida /l, r/.
-
(2) [+low]: includes vowel phonemes /a/; faringal /h/; glottal ///
[-low]: includes vowel phonemes /i, u, e, o/; explosive inhibiting phonemes /p, b, t, d, k, g/; nasal pre-obstruction /mb, nd, nt/; fricative /s/; nasal /m, n, Ν/; likuida /l, r/; and semi vocal /w/.
-
(3) [+round]: includes vowel phonemes /u, o/; semi vocal /w/.
[-round]: includes vowel phonemes /i, e, a/; explosive inhibiting phonemes /p, b, t, d, k, g, //; nasal pre-obstruction /mb, nd, nt/; fricative /s, h/; nasal /m, n, Ν/; likuida /l, r/.
-
(4) [+back]: includes vowel phonemes /u, o/; explosive inhibiting phonemes /k, g/; nasal /Ν/; semi vocal /w/.
[-back]: includes vowel phonemes /i, e, a/; explosive inhibiting phonemes /p, b, t, d/; nasal pre-obstruction /mb, nd, nt/; fricative /s, h/; nasal /m, n/; likuida /l, r/; faringal /h/; and glottal ///.
-
5) Additional features
-
(1) [+voice]: includes vowel phonemes /a, i, u, e, o/; voice inhibiting /b, d, g/; nasal /m,
-
n, Ν/; liquid /l, r; semi vocal /w/.
[-voice]: includes phoneme voiceless inhibiting /p, t, k, //; fricative /s, h/.
-
(2) [+tense]: includes tense vocal phonemes /a, i, u, e, o/
-
6) The characteristics of prosody
-
(1) [-stress] includes unstressed vowel phonemes /a, i, u, e, o/
To obtain a complete and clear picture of the Waisika phonemes with its distinguishing features are presented in the following table.
|
Feature |
p |
b |
m |
mb |
t |
d |
n |
nd |
nt |
s |
r |
l |
k |
g |
Ν |
Nk |
/ |
h |
y |
w |
i |
u |
e |
o |
a |
|
cont |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
- |
- |
- |
- |
- |
- |
- |
|
sil |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
+ |
+ |
+ |
+ |
|
son |
- |
- |
+ |
- |
- |
- |
+ |
- |
- |
- |
+ |
+ |
- |
- |
+ |
- |
- |
- |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
|
nas |
- |
- |
+ |
+ |
- |
- |
+ |
+ |
- |
- |
- |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
|
ant |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
|
cor |
- |
- |
- |
- |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
|
high |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
+ |
+ |
- |
- |
- |
+ |
+ |
+ |
+ |
- |
- |
- |
|
low |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
+ |
- |
- |
- |
- |
- |
- |
+ |
|
back |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
+ |
+ |
- |
- |
- |
- |
+ |
- |
+ |
- |
+ |
+ |
|
roun |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
- |
+ |
- |
+ |
- |
|
strid |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
|
voic |
- |
+ |
+ |
- |
+ |
+ |
- |
- |
- |
+ |
+ |
- |
+ |
+ |
- |
- |
- |
+ |
+ |
+ |
+ |
+ |
+ |
+ | |
|
lat |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
|
nas pre-ob |
- |
- |
- |
+ |
- |
- |
- |
+ |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
|
impl |
- |
- |
- |
+ |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
+ |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
Table 2. Characteristics by distinguishing features of Waisika Language
Linguists assume that all languages forming a family were once one language (Poedjosoedarmo, 1978). Some speakers of language moved to another place, and the language of that group of speakers changed in different ways. Based on this theory, and in line with the historical development of Alor, mainly, which includes the Lipang, Langkuru, and Waisika languages, it is proven. However, this theory needs to be reexamined by the position of the Lipang language, Langkuru language, and Waisika language, which are the languages spoken by the Alor people who live side by side with other languages. Until now, these languages have survived. It requires further research on society, Lipang culture, Langkuru, Waisika.
Five vocoids were found in the Waisika language, namely [a, i, u, e, o]. Contoid in Waisika consists of 21 types, namely [p, b, mb, t, nt, d, k, g, /, nd, h, s, m, n, Ν, Nk, l, r, w, w, y]. Based on the application of minimal pairing procedures and similar environments, it can be found that all vocoids sound in Waisika is vocal segments / a, i, u, e, o /. Based on the application of minimal pairing procedures and similar environments, it can be found that all contoid sounds are consonant segments [p, b, mb, t, nt, d, k, g, nd, h, s, m, n, Ν, Nk, l, r, w]. Five vowel phonemes, which are found to have complete distribution at the front, central, and back of the morpheme. However, based on the data captured, the phoneme /mb/, /nt/, /d/, /k/, /nd/, /r/, /w/ only exists in the initial and middle position of words. The phonemes /Nk/ are only in the central position of words.
The phonemes /Ν/ are only in the central and back positions. The canonical pattern of the Waisika language can be assessed as follows (V(C)V)(V(C)V)(V(C)V). So, in Waisika, the first syllable can be structured V, CV. Similarly, the same structure can be repeated in the second and third syllables. There are six groups and nineteen distinguishing features. The six groups are: 1) the characteristics of the main group, 2) the features of the place of articulation, 3) the way of articulation, 4) the characteristics of the tongue, 5) additional features, and 6) the characteristics of prosody.
References
Adhiti, I. A. I. (2015). Kekerabatan Bahasa Kabola, Bahasa Hamap, Bahasa Klon di Pulau Alor Nusa Tenggara Timur. Disertasi: Universitas Udayana.
Anggayana, I. A., Budasi, I. G., & Kusuma, I. W. (2019). Social Dialectology Study of Phonology in Knowing English Student Speaking Ability. The Asian EFL Journal, 25(5.2), 225-244.
Anggayana, I. A., Suparwa, I. N., Dhanawaty, N. M., & Budasi, I. G. (2020). Lipang, Langkuru, Waisika Language Kinship: Lexicostatistics Study in Alor Island. International Journal of Psychosocial Rehabilitation, 24(4), 301-319.
doi:https://doi.org/10.37200/IJPR/V24I4/PR201010
Budasi, I. G., & Anggayana, I. A. (2019). Developing English for Housekeeping Materials for Students of Sun Lingua College Singaraja-Bali. The Asian EFL Journal, 23(6.2), 164-179.
Fromkin, V & Ladefoged, P (1981). Early views of Distinctive Features. Towards a history of phonetics, eds. R.A. Asher and E.J. Henderson, 3-8. Edinburgh: Edinburgh University Press.
La Ino. (2013). Protobahasa Modebur, Kaera, dan Teiwa Bahasa kerabat Non-Austronesia di Pulau Pantar Nusa Tenggara Timur. Disertasi: Universitas Udayana.
O’Grady, William, Michael Dobrovolsky, And Mark Aronoff, Eds. (1989) Contemporary Linguistics. St, Martin’s Press New York.
Odden, D. (2013). Introducing Phonology. United States of America, New York: Cambridge University Press.
Pike, K. L. (1948). Tone languages. University of Michigan Publications in Linguistics, 4. Ann Arbor: University of Michigan Press.
Poedjosoedarmo, S. (1978). Interferensi dan Integrasi dalam Situasi Keanekabahasaan, Jakarta : Pusat Pembinaan dan Pengembangan Bahasa.
Schane, Sanford A. (1992). Fonologi Generatif. Jakarta: Summer Institute of Linguistics.
Sudipa, I. N., Aryati, K. F., Susanta, I. P. A. E., & Anggayana, I. W. A. (2020). The Development of Syllabus and Lesson Plan Based on English for Occupational Purposes. International Journal of Psychosocial Rehabilitation, 24(4), 290–300.
https://doi.org/10.37200/IJPR/V24I4/PR201009
Biography of Authors
|
'*3c∙⅜ |
I Wayan Agus Anggayana, S.Pd., M.Pd. was born in Denpasar on July 28th, 1993. He is a lecturer in Akademi Komunitas Manajemen Perhotelan Indonesia. SINTA ID: 6088465, NIDN: 0828079301, Ph. +62 856-3855-763. He graduated with his bachelor's degree in the Faculty of Languages and Arts, Ganesha University in 2014. He finished his master's degree in the postgraduate program, magister program, English Language Studies, Ganesha University in 2016. He continued his study in Doctoral Degree in 2017. Currently, he is completing his dissertation at Udayana University. Email: anggayana28@gmail.com Scopus ID: 57213141209 / https://www.scopus.com/authid/detail.uri?authorId=57213141209 | |
|
Orcid ID: https://orcid.org/0000-0001-7509-5196 | ||
|
Prof. Dr. I Nyoman Suparwa, M. Hum. is professor in Udayana University, Faculty of Art, Denpasar, Indonesia, SINTA ID: 5980001 Ph. +62 817-354-717 Email: nym_suparwa@unud.ac.id Scopus ID: 57194424523 / https://www.scopus.com/authid/detail.uri?authorId=57194424523 Orcid ID: https://orcid.org/0000-0003-1544-933X | ||
|
Dr. Ni Made Dhanawaty, M.S. is an associate professor in Udayana University, Faculty of Art, Denpasar, Indonesia, SINTA ID: 5988335 Ph. +62 813-3849-3565 Email: md_dhanawaty@unud.ac.id Scopus ID: 57215424327 / https://www.scopus.com/authid/detail.uri?authorId=57215424327 | ||
|
^b | ||
|
Itl |
Dr. I Gede Budasi, M.Ed. is an associate professor in Ganesha University, Faculty of Languages and Arts, Denpasar, Indonesia, SINTA ID: 6037785 Ph. +62 813-3890-3491 Email: yaysurya8@yahoo.com Scopus ID: 57213150398 / https://www.scopus.com/authid/detail.uri?authorId=57213150398 | |
|
_ |
Orcid ID: https://orcid.org/0000-0001-7653-7734 |
Discussion and feedback